






一:Spark使用过程中需注意的点
1.最重要的就是架构的理解
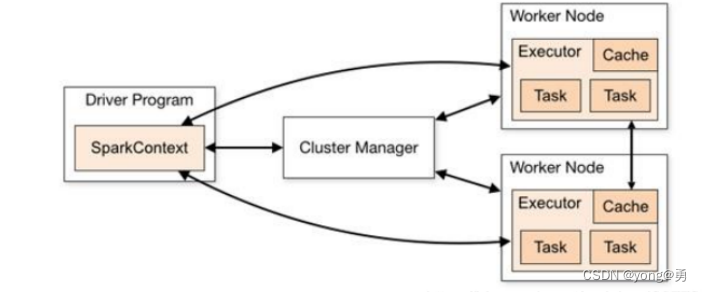
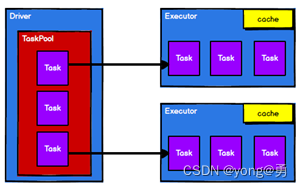
spark框架的核心是一个计算引擎,整体来说,它采用了标准的master——slave的结构。如图所示,它展示了一个 Spark 执行时的基本结构。图形中的 Driver 表示 master,负责管理整个集群中的作业任务调度。图形中的 Executor 则是 slave,负责实际执行任务
2.接着就是rdd的理解与应用
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,形式上它一个不可变、可分区、里面的元素可并行计算的集合。
RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度
3.RDD的执行原理
Spark框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计算。最后得到计算结果。RDD是Spark框架中用于数据处理的核心模型,以在Yarn环境下为例,RDD的工作原理包括:
1、启动Yarn进群环境
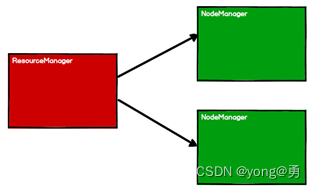
2.Spark通过申请资源创建调度节点和计算节点
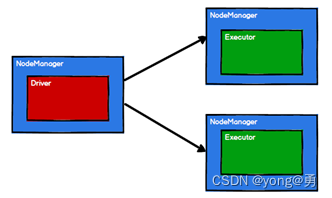
3、Spark框架根据不同的需求将计算逻辑划分成不同的任务
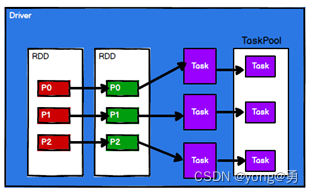
4、调度节点将任务根据节点状态发送到对应的计算节点机型计算
RDD的主要作用就是进行逻辑的封装,然后生成Task分发到各个Executor上进行计算。
3.RDD的算子
RDD中的所有转换都是延迟加载的,也就是说,它们并不会直接计算结果。相反的,它们只是记住这些应用到基础数据集(例如一个文件)上的转换动作(tansformation)。只有当发生一个要求返回结果给Driver的动作(Action)时,这些转换才会真正运行。这种设计让Spark更加有效率地运行。
4.RDD创建方式
RDD的创建主要有两种方式:一种是根据已有的Scala集合(parallelize、makeRDD)进行创建,另一种时由外部存储的数据文件(textFile)创建,包括本地文件系统还有所有Hadoop支持的数据形式,如HDFS、HBase等,从其他的RDD进行创建。
5.RDD的转换与操作
◆ 对于RDD可以有两种计算方式:转换(返回值还是一个RDD)与操作(返回值不是一个RDD)。
◆ 转换(Transformations) (如:map, filter, groupBy, join等),Transformations操作是Lazy的,也就是说从一个RDD转换生成另一个RDD的操作不是马上执行,Spark在遇到Transformations操作时只会记录需要这样的操作,并不会去执行,需要等到有Actions操作的时候才会真正启动计算过程进行计算。
◆ 操作(Actions) (如:count, collect, save等),Actions操作会返回结果或把RDD数据写到存储系统中。Actions是触发Spark启动计算的动因。
二:针对Worker、Executor的资源分配注意点
1.如何分配资源
首先要了解你的机子的资源,多大的内存,多少个cpu core,就根据这个实际情况去设置,能使用多少资源,就尽量去调节到最大的大小(executor的数量,几十个到上百个不等;executor内存;executor cpu core)。一个cpu对应2-3task合理
Standalone 模式
如果每台机器可用内存是4G,2个cpu core,20台机器,
那可以设置:20个executor,每个executor4G内存,2个cpu core(资源最大化利用)。
yarn 模式下
根据spark要提交的资源队列资源来考虑,如果所在队列资源为500G内存,100个cpu core。
可以设置50个executor;每个executor10G内存2个cpu
调节资源后,SparkContext,DAGScheduler,TaskScheduler,会将我们的算子,切割成大量的task,提交到Application的executor上面去执行。
分配资源策略
给application分配资源选择worker(executor),现在有两种策略:
尽量的打散,即一个Application尽可能多的分配到不同的节点。这个可以通过设置spark.deploy.spreadOut来实现。默认值为true,即尽量的打散。(默认)
尽量的集中,即一个Application尽量分配到尽可能少的节点
2.Excutor资源分配原理分析
运行一个作业都会一定会有SparkContext,这里我们要明确,在SparkContext启动过程中,会首先创建DAGScheduler和TaskSechduler两个调度器,还有schedulerBackend用于分配当前可用的资源。
1.DAGScheduler
DAGScheduler主要负责将用户的应用的DAG划分为不同的Stage,其中每个Stage由可以并发执行的一组Task构成, 这些Task的执行逻辑完全相同,只是作用于不同的数据。
2.TaskSechduler
负责具体任务的调度执行,从DAGScheduler接收不同Stage的任务,按照调度算法,分配给应用程序的资源Executor上执行相关任务,并为执行特别慢的任务启动备份任务。 TaskSchedulerImpl创建时创建SchedulableBuilder,SchedulableBuilder根据类型分为FIFOSchedulableBuilder和FairSchedulableBuilder两类,。调度器的区别我会在以后的文章中说明,这里先记住有这个概念就行。
3.SchedulerBackend
分配当前可用的资源, 具体就是向当前等待分配计算资源的Task分配计算资源(即Executor) , 并且在分配的Executor上启动Task, 完成计算的调度过程。 它使用reviveOffers完成上述的任务调度















 1407
1407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









