






又是一个毕业季,又是到了各位代码小白紧张刺激的找工作环节。面对大数据的面试。你是不是也表现得很忐忑。担心自己不会答怎么办。没关系。你们的勇勇带着自己面试中被问到的一些问题来了。本期让我们一起来看一下面试中被问到的知识点——HADOOP
1.什么是hadoop?
Hadoop是一个分布式系统基础架构。Hadoop的核心是YARN,HDFS和MapReduce。Hadoop可以用来搭建大型数据仓库,
对海量数据进行存储、分析、处理和统计等业务
HDFS是分布式文件存储系统,用于存储海量数据;
MapReduce是并行处理框架,实现任务分解和调度。
YARN是Hadoop中的资源管理系统,它的基本设计思想是将MRv1中的JobTracker拆分成了两个独立的服务:
一个全局的资源管理器ResourceManager和每个应用程序特有的ApplicationMaster。其中ResourceManager负责整个系统的资源管理
和分配,而ApplicationMaster负责单个应用程序的管理
2.namenode和datanode的作用
namenode管理元数据,处理客户端读写请求
datanode存储实际的数据块,执行数据块的读/写操作
3.NameNode与SecondaryNameNode 的区别与联系?
NameNode职责是管理元数据信息,DataNode的职责是负责存储实际数据
SecondaryNameNode主要用于定期合并Fsimage 和Edits,简单来讲就是保存了一份namenode的镜像
SecondaryNameNode中保存了一份和Namenode一致的Fsimage 和Edits 。在Namenode发生故障时,可以从SecondaryNameNode恢复数据
Edits 日志文件存放的是HDFS所有的更改操作日志。
Fsimage 有最新的元数据和HDFS的文件和目录信息,但不包含文件块位置信息,文件块位置信息只存储在内存中。
namenode宕机怎么解决
1,如果MR造成系统宕机。此时要控制Yarn同时运行的任务数,和每个任务申请的最大内存。调整参数:yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物理内存量,默认是8192MB)
2,如果写入文件过快造成NameNode宕机。那么调高Kafka的存储大小,控制从Kafka到HDFS的写入速度。例如,可以调整Flume每批次拉取数据量的大小参数batchsize。
4.HDFS读写流程
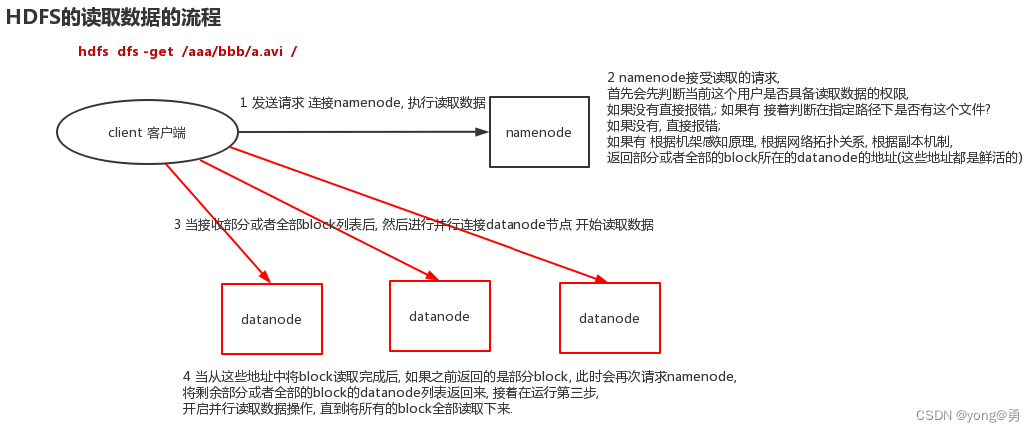
读:
1.客户端向 NameNode 请求下载文件,NameNode 通过查询元数据,找到文件块所在的 DataNode 地址。
2.挑选一台 DataNode(就近原则,然后随机)服务器,请求读取数据。
3.DataNode 开始传输数据给客户端。(从磁盘里面读取数据输入流)
4.客户端以 Packet 为单位接收,先在本地缓存,然后写入目标文件。
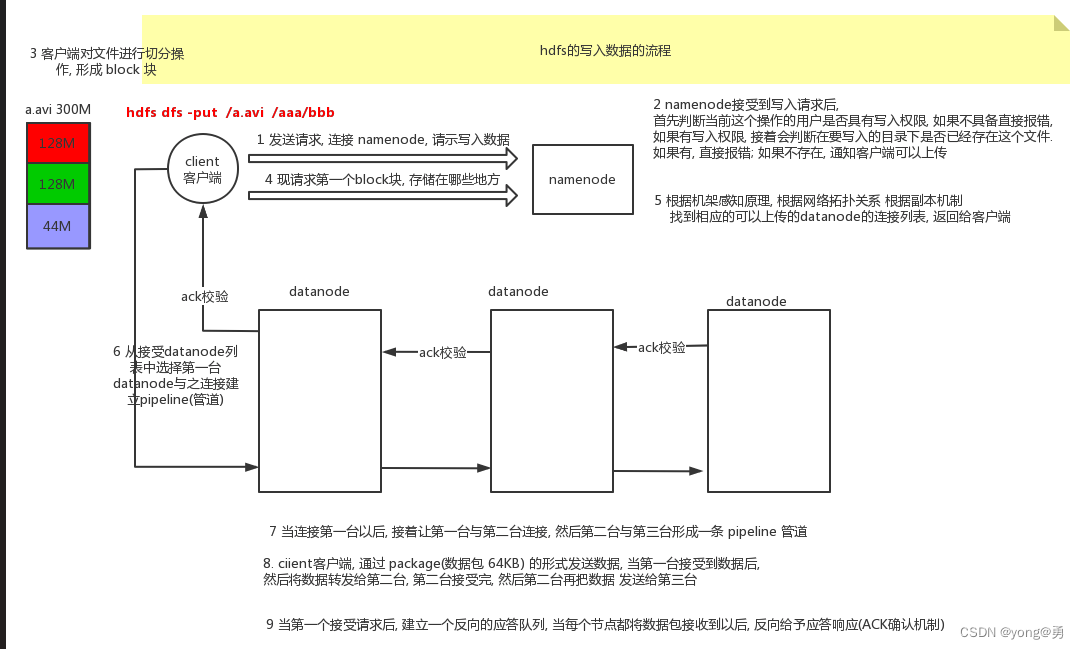
写:
1. 客户端向NameNode节点发送上传文件请求
2.NameNode响应请求,返回可以上传文件
3.客户端将文件进行切片,发送要上传第一个Block(0-128MB)的请求
4.NameNode响应请求,返回存储数据的DataNode的节点信息
5.往DataNode节点发送建立Block传输通道的请求
6.DataNode节点应答成功
7.客户端开始向DataNode节点传输数据
8.当向所有的DataNode节点的数据传输完成之后,客户端就会给NameNode节点反馈传输数据完成。
5.Hadoop 三种运行模式
1.本地模式
2.伪分布式模式
1.只有单台机器
2.使用HDFS、Yarn、MapReduce
3.分布式模式
1.多台服务器
2.集群模式,包含整个Hadoop组件
6.mapreduce流程
Job和task的区别
一个mapreduce程序就是一个Job,而一个job里面可以有一个或多个task,task分为map task和reduce task
Input ——inputformat——map——shuffle——reduce——outputformat——output
(1)Inputformat阶段
会经过分片和格式化操作。
分片操作:指的是将源文件划分为大小相等的小数据块(Hadoop2.x中默认128M),也就是分片(split),Hadoop会为每一个分片构
建一个Map任务,并由该任务运行自定义的map()函数,从而处理分片里的每一条记录;
格式化操作:将划分好的分片(split)格式化为键值对<key,value>形式的数据,其中,key代表偏移量,value代表每一行内容。
(2)Map阶段
每个Map任务都有一个内存缓冲区(缓冲区大小100M),输入的分片(split)数据经过Map任务处理后的中间结果,会写入内存缓
冲区中。如果写入的数据达到内存缓冲的阀值(80M),会启动一个线程将内存中的溢出数据写入磁盘,同时不影响map中间结果
继续写入缓冲区。
在溢写过程中,MapReduce框架会对Key进行排序,如果中间结果比较大,会形成多个溢写文件,最后的缓冲区数据也会全部溢写入
磁盘形成一个溢写文件,如果是多个溢写文件,则最后合并所有的溢写文件为一个文件。
(3)shuffle阶段
MapReduce工作过程中,map阶段处理的数据如何传递给Reduce阶段,这是MapReduce框架中关键的一个过程,这个过程叫做Shuffle。
Shuffle会将MapTask输出的处理结果数据,分发给ReduceTask,并在分发的过程中,对数据按key进行分区和排序。
(4)reduce阶段
输入ReduceTask的数据流是<key,{value list}>形式,用户可以自定义reduce()方法进行逻辑处理,最终以<key,value>的形式输出
(5)outputformat
MapReduce框架会自动把ReduceTask生成的<key,value>传入OutputFormat的write方法,实现文件的写入操作。

7.mapreduce的shuffle阶段
(1)Map端shuffle
每个map读取原数据的一部分(inputSplit),执行Mapper操作。
从Mapper端输出的键值对数据进入到环形缓冲区(100M)
环形缓冲区容量达到80%产生溢写,写入到磁盘缓冲区。
在磁盘缓冲区中分区(partitioner), 排序(sort),合并(combiner)
(2)Reduce端shuffle
由reducetask向maptask拉取数据,进行分组排序(归并算法)
把数据组合成(key,序列)发送到Reducer类中执行
在Reducer类中处理数据,把结果写到文件中
8.YARN框任务提交流程:
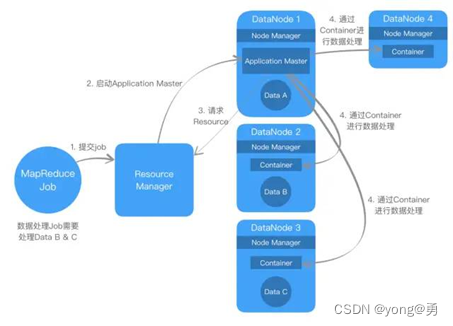
client向ResourceManager提交一个MapReduce应用,和启动指定应用的ApplicationMaster所需要的信息。
ResourceManager 会为ApplicationMaster分派一个Container,并且启动Application
ApplicationMaster启动,接着向ResourceManager注册自己,允许调用client直接与ApplicationMaster交互
ApplicatoinMaster为客户端应用分配资源
ApplicationMaster为application启动Container
在执行期间,clients向Applicationaster提交application状态和进度
apllication执行完成,ApplicationMaster向ResouceManager撤销掉自己的注册信息,然后关机,将自己所持有的Container归还给资源池。















 688
688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









