






一、元组 # 列表可以修改内容,元组可以不被修改 # 在程序内封装数据,不希望数据被篡改,所以使用元组 # 语法: 不限制类型 # 定于元组的字面量: (元素,元素,元素.....) # 定义元组变量 变量名称 = (元素, 元素,元素......) # 定义空元组 1、变量名称 = () 2、变量名称 = tuple() # 注意:元组用的是小括号,列表用的是方括号 # 定义元组 t1 = (1, 2, "haying", "hello", True) t2 = () t3 = tuple() # t2和t3都属于空元组 print(f"t1的类型是:{type(t1)},内容是{t1}") print(f"t2的类型是:{type(t2)},内容是{t2}") print(f"t3的类型是:{type(t3)},内容是{t3}") # 注意,元组只有一个数据,该数据后要有逗号,否则不是元组类型 t4 = ("hello",) print(f"t4的类型是:{type(t4)},内容是{t4}") # 元组的嵌套 t5 = (1, 2, 3, "hello", t4) print(f"t5的类型是:{type(t5)},内容是{t5}") # 通过下标索引去取出内容 num = t5[4][0] print(f"从嵌套元组中,取出的数据是: {num}") # 元组的操作 # index() 查找某个数据,如果数据存在,则返回下标,否则出错 # count() 统计某个数据在当前元组出现次数 # len(元组)统计元组内的元素个数 index = t5.index(3) print(f"查找3的下标: {index}") t6 = (1, 2, 3, 2, 3, "hello", t4) num =t6.count(2) print(f"2的个数为: {num}") t7 = (1, 2, 3, 2, 3, "hello", t4) num = len(t7) print(f"T7的元素个数为:{num}") # 元组的遍历:while index = 0 while index <len(t7): print(f"元组的元素有: {t7[index]}") index +=1 # 元组的遍历:for for i in t7: print(f"2元组的元素有: {i}") # # 示范修改元素 # t7 = (1, 2, 3, 2, 3, "hello", t4) # t7[0] = 2 # # 报错 # 尝试修改元组内容,通过嵌套list t8 = (1, 2, ["itheima", "itcast"]) print(f"t8的内容是:{t8}") t8[2][0] = "黑马程序员" t8[2][1] = "船只教育" print(f"t8修改的内容是:{t8}") # list没有变,变的是llist的内容
课后练习
# 课后练习
message = ('周杰', 11, ['footbal', 'music'])
num = message.index(11)
print(f"年龄的下标是: {num}")
name = message[0]
print(f"查找名字: {name}")
del message[2][0]
print(f"删除内容: {message}")
message[2].insert(0, "coding")
print(f"新的message: {message}")
二、字符串
字符串也是数据容器,可以存储数据,长度任意(取决于内存),支持下标索引,允许字符串存在,不可以修改,支持for循环
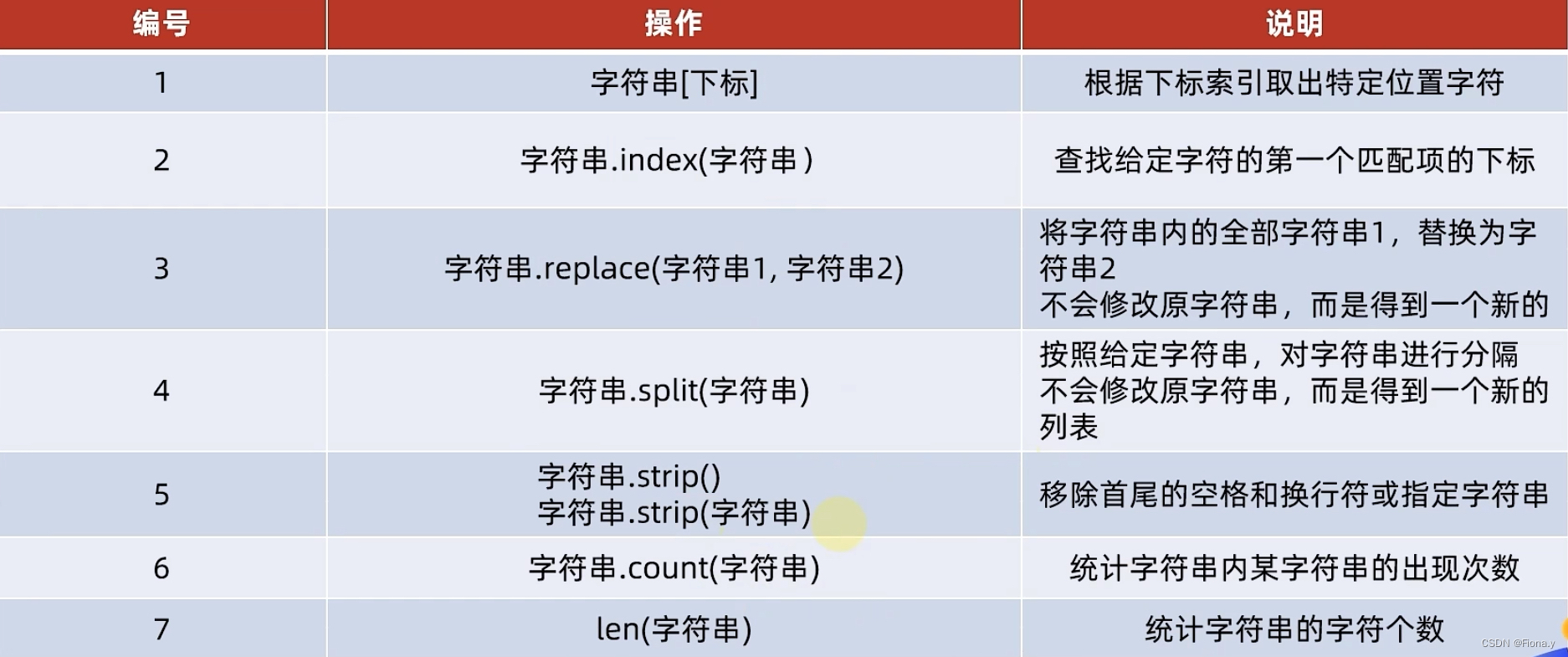
# 字符串的相关操作 my_str = "itheima and itcast" value = my_str[2] value2 = my_str[-16] print(f"{value},{value2}") # my_str[2] = 'H' # print(my_str) 因为字符串不可以修改 # 查找特定字符串的索引值 num = my_str.index("and") print(f"查找的and起始下标为 :{num}") # 字符串的替换 # 语法:字符串.replace(字符串1,字符串2) # 注意修改的不是字符串本身,而是得到一个新的字符串 new_my_str = my_str.replace("and", "happy") print(f"得到的新的字符串为: {new_my_str}") # 字符串的分隔 # 语法: 字符串.split(分隔符字符串) # 字符串本身没有变,得到一个新的列表对象 new_my_str = "itheima happy itcast" n_my_str = new_my_str.split(" ") print(f"{n_my_str}") # 字符串规整操作(去前后空格) # 语法:字符串,strip() my_str = " itheima and itcast" my_str.strip() print(my_str.strip()) # 去除前后指定字符串 # 语法:字符串,strip(字符串) my_str = "12itheima and itcast21" print(my_str.strip("12")) # 12 是1 和2 # 统计出现次数 new_my_str = "itheima happy itcast" count = new_my_str.count("a") print(f"{count}") # 统计字符串元素 num = len(new_my_str) print(f"{num}") # 字符串的遍历:while new_my_str = "itheima happy itcast" index = 0 while index < len(new_my_str): print(new_my_str[index]) index += 1 # 字符串的遍历: for new_my_str = "itheima happy itcast" for i in new_my_str: print(i)
# 课后练习
t = "itheima itcast boxuegu"
count = t.count("it")
print(f"{count}")
n_t = t.replace(" ", "|")
print(f"{n_t}")
nn_t = n_t.split("|")
print(f"{nn_t}")
三、数据切片
# 序列:内容连续、有序、可以使用下标索引的一类数据容器 # 列表、元组、字符串、均可以视作序列 # 序列支持切片,所谓切片,指的是,从一个序列中,取出一个子序列 # 不会影响序列本身,只会得到一个新的序列 # 语法: 序列 [起始下标:结束下标:步长] # 对列表进行切片 my_list= [0, 1, 2, 3, 4, 5, 6] result1 = my_list[1: 5] # 步长默认是1 print(f" 结果1 :{result1}") # 对tuple进行切片,从头开始,,到最后结束,步长为1 my_list = (0, 1, 2, 3, 4, 5, 6) result2 = my_list[:] # 都省略了 print(f" 结果2 :{result2}") # 对str进行切片,从头开始,到尾开始,步长为2 str = "0123456" result3 = str[: : 2] print(f" 结果3 :{result3}") # 对str进行切片,从尾开始,到头开始,步长为-1 str = "0123456" result4 =str [: : -1] print(f" 结果4 :{result4}") # 注意:省略结束下标就会包含最后一个元素,不省略就不会包含最后一个元素 # 课后练习 str = "万过薪月, 员序程马黑来,nohtyp学" result5 = str[5:11: 1] print(f"结果5是: {result5}") result6 = result5[: : -1] print(f"结果6是: {result6}") # 法二 str = "万过薪月,员序程马黑来,nohtyp学" N_str = str.split(", ")[1].replace("来"," ")[: : -1] print(f"{N_str}")















 1166
1166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









