






基于python flask的爬虫影响水稻收成因素数据分析平台【008】
代码代写程序代做代编网页爬虫脚本自动化安装调试
【功能说明】
1.用户登录注册
2.数据展示
3.数据可视化图表
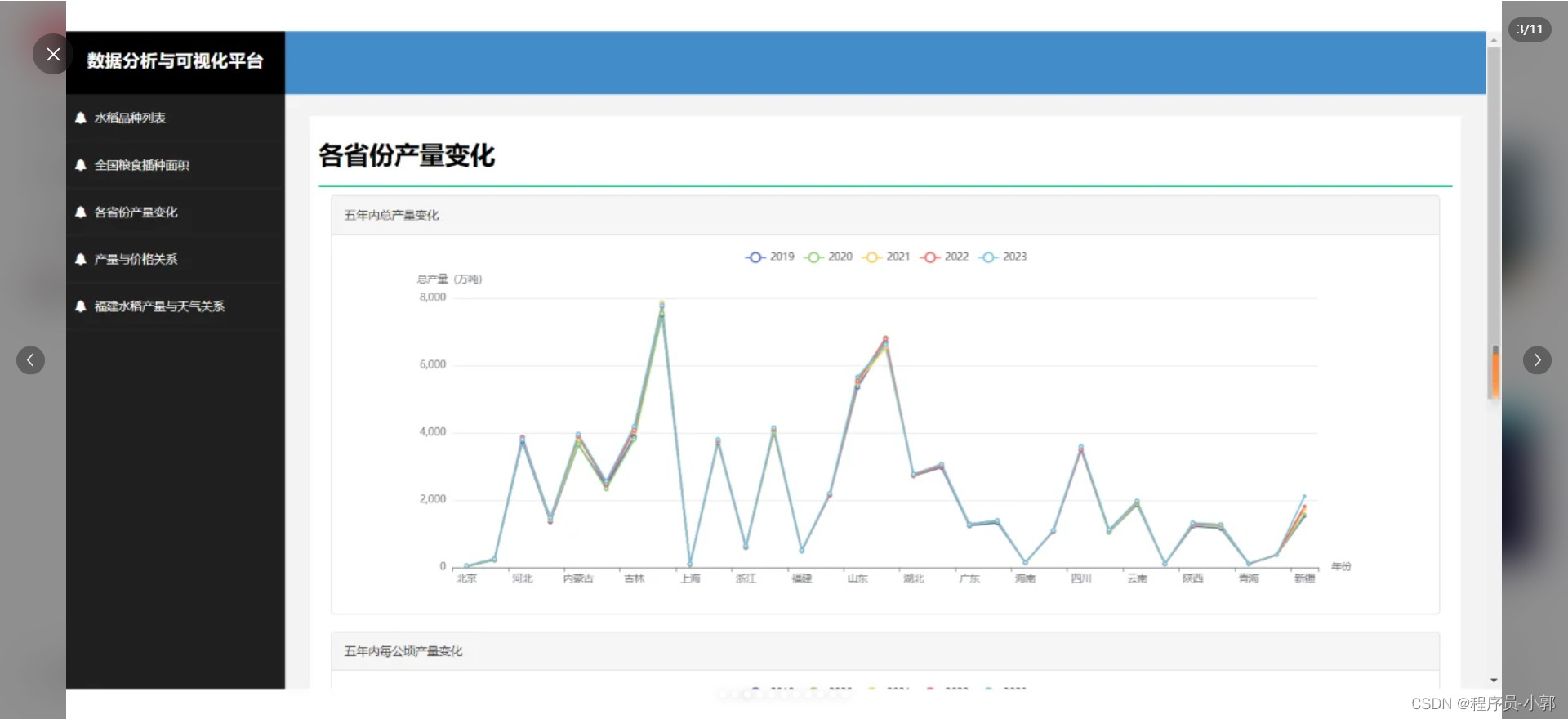
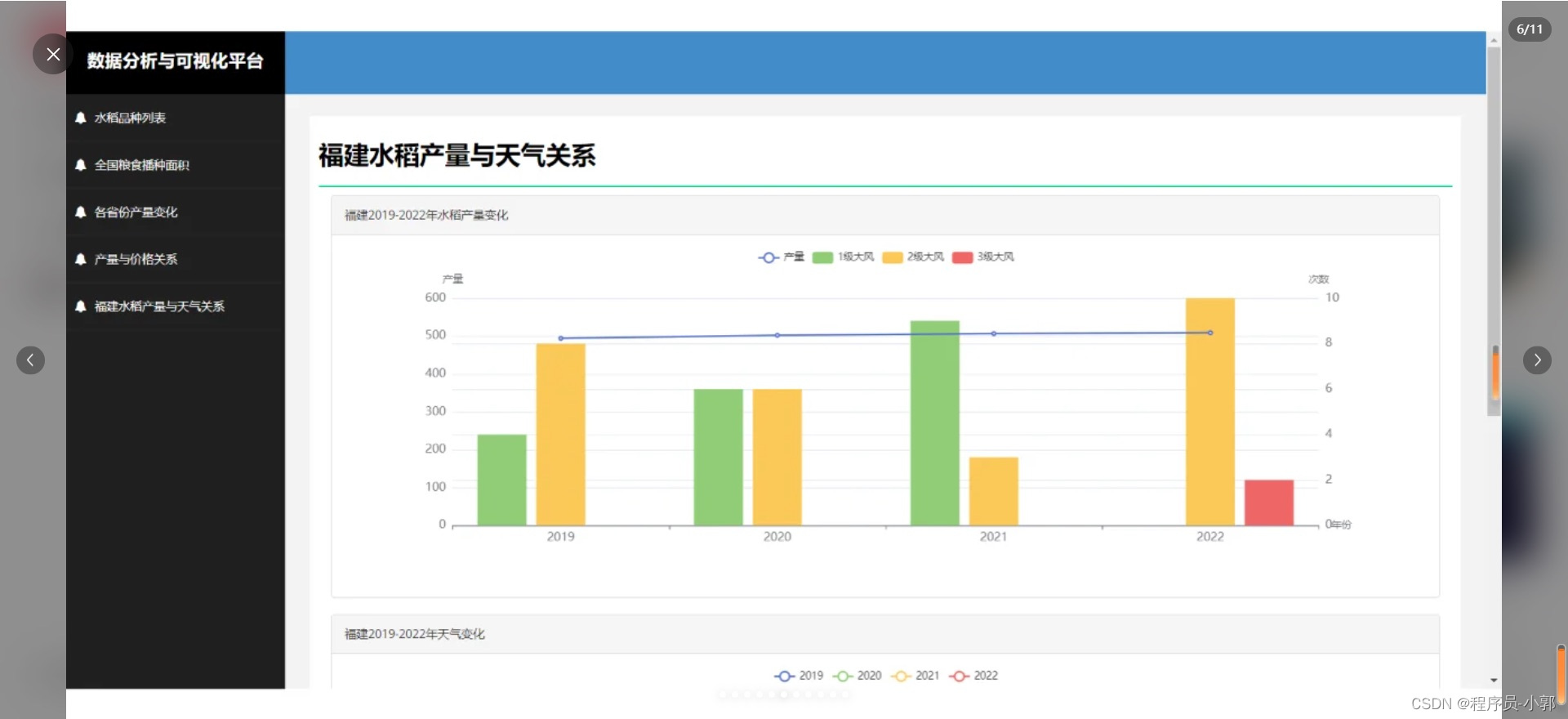
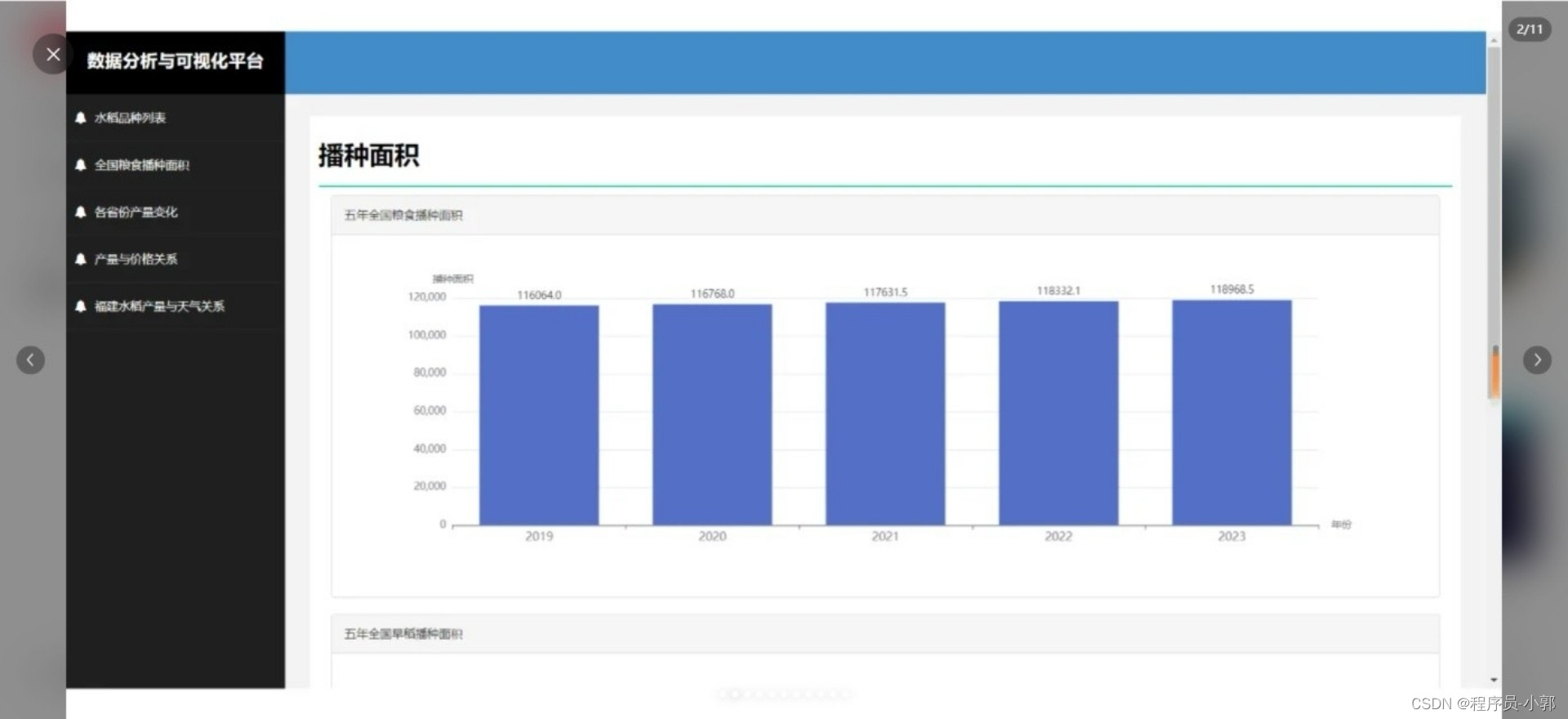
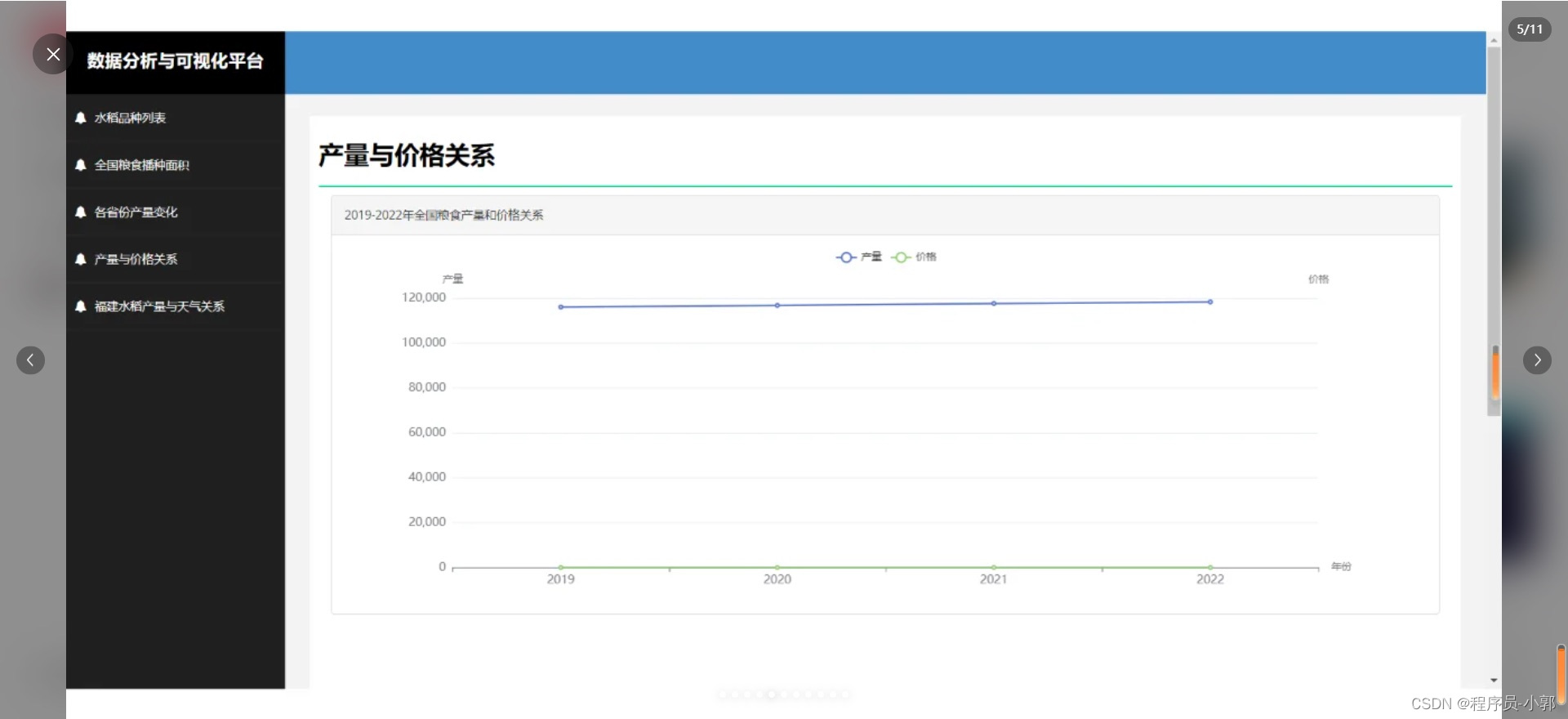
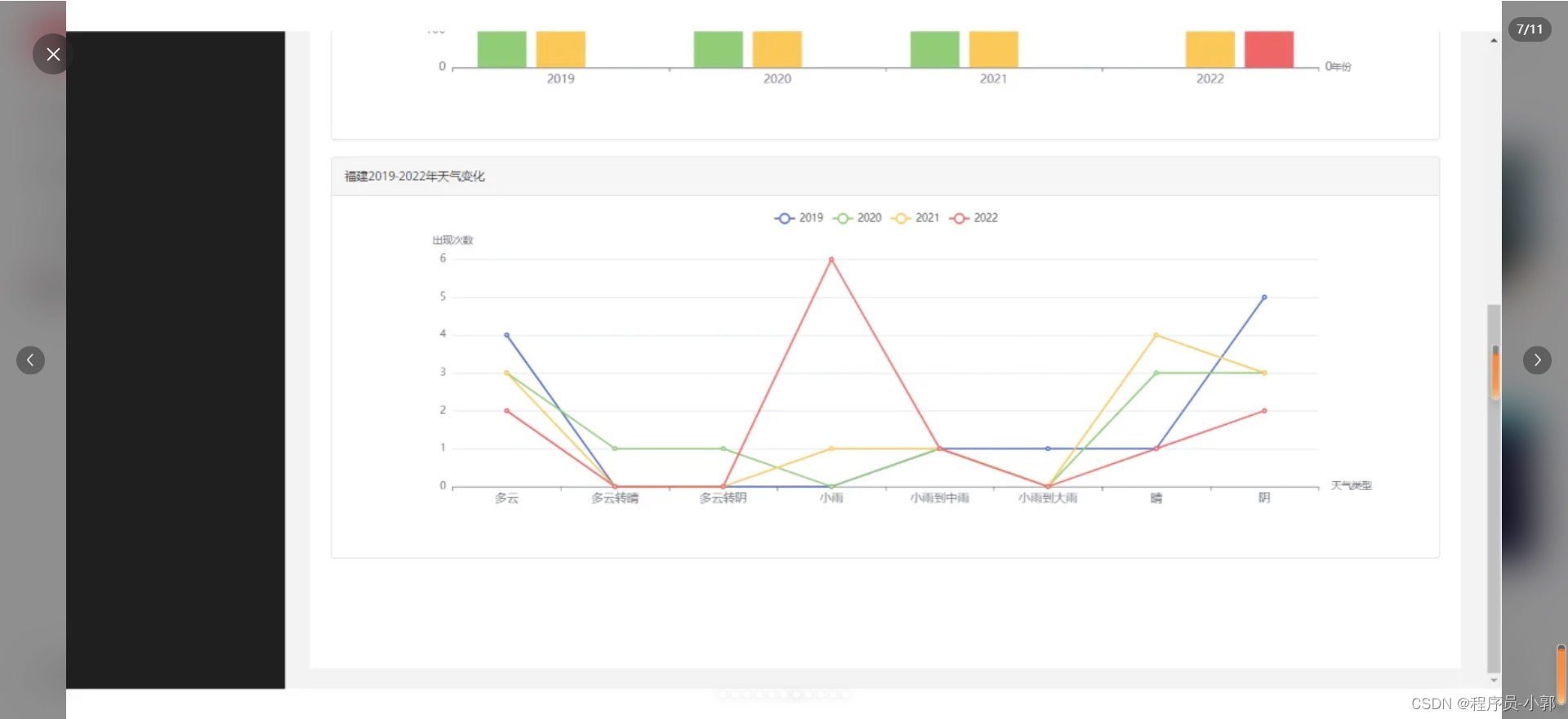
本系统主要使用爬虫采集了某水稻收成数据,存储到mysql中,并且对数据进行各种维度的统计,然后可视化图表展示。
(1)各个详细功能具体可看运行效果截图
(3)代码结构清晰简单,可二次开发、可定制功能
源码资料获取:gongzhong 【匠心程序定制】
代码都是亲自运行且完整的,可提供二次修改以及优化功能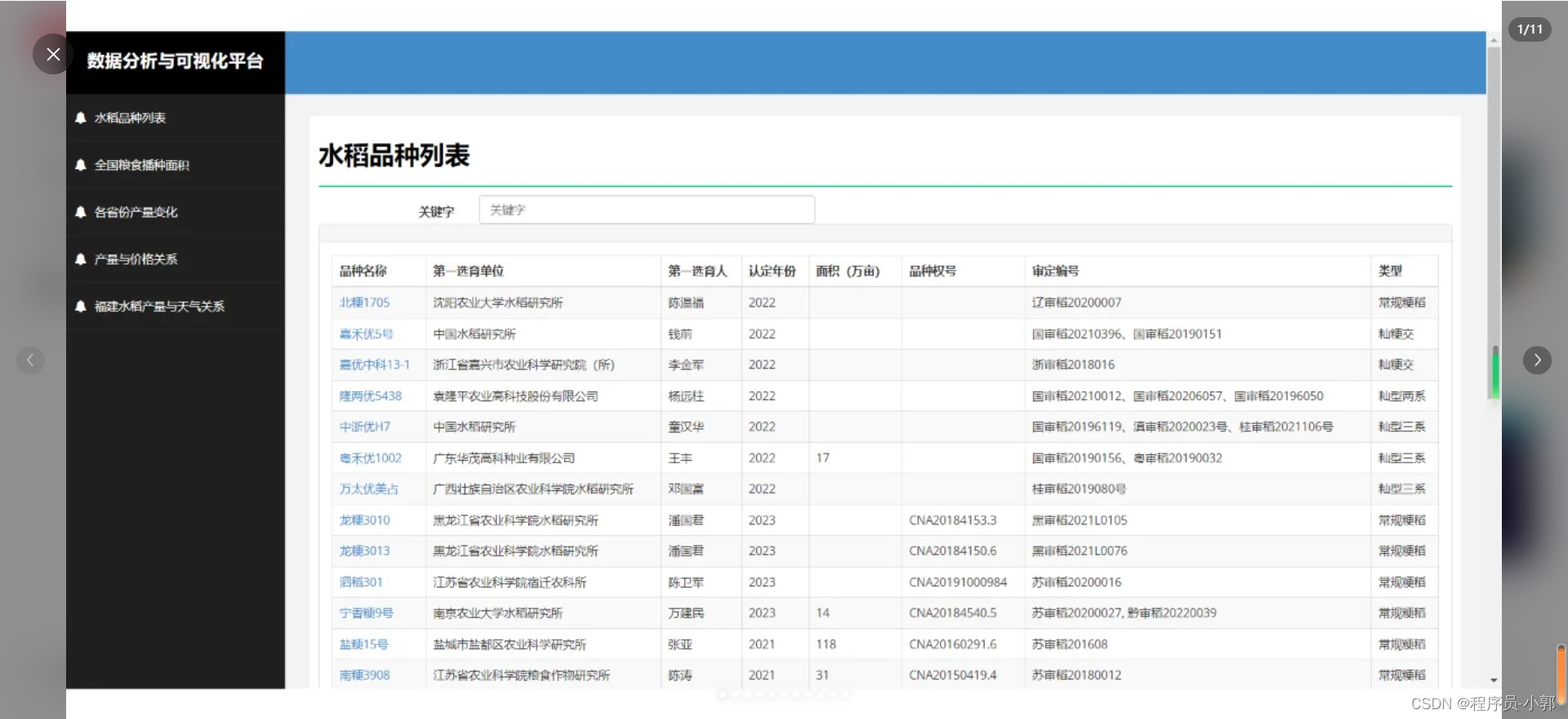















 8731
8731

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









