






基于python flask的招聘信息数据可视化系统【007】
【功能说明】
1.用户登录注册
2.系统首页功能,展示系统汇总结果数据
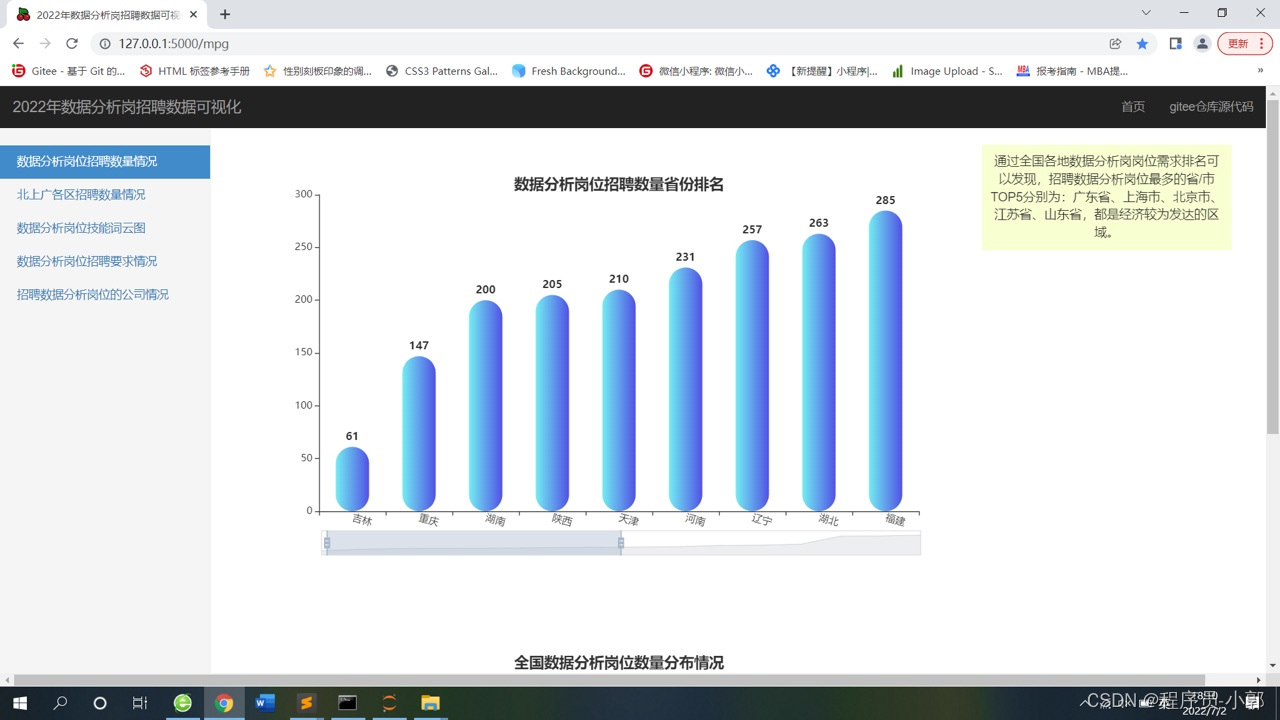
3.数据分析岗位招聘数量情况
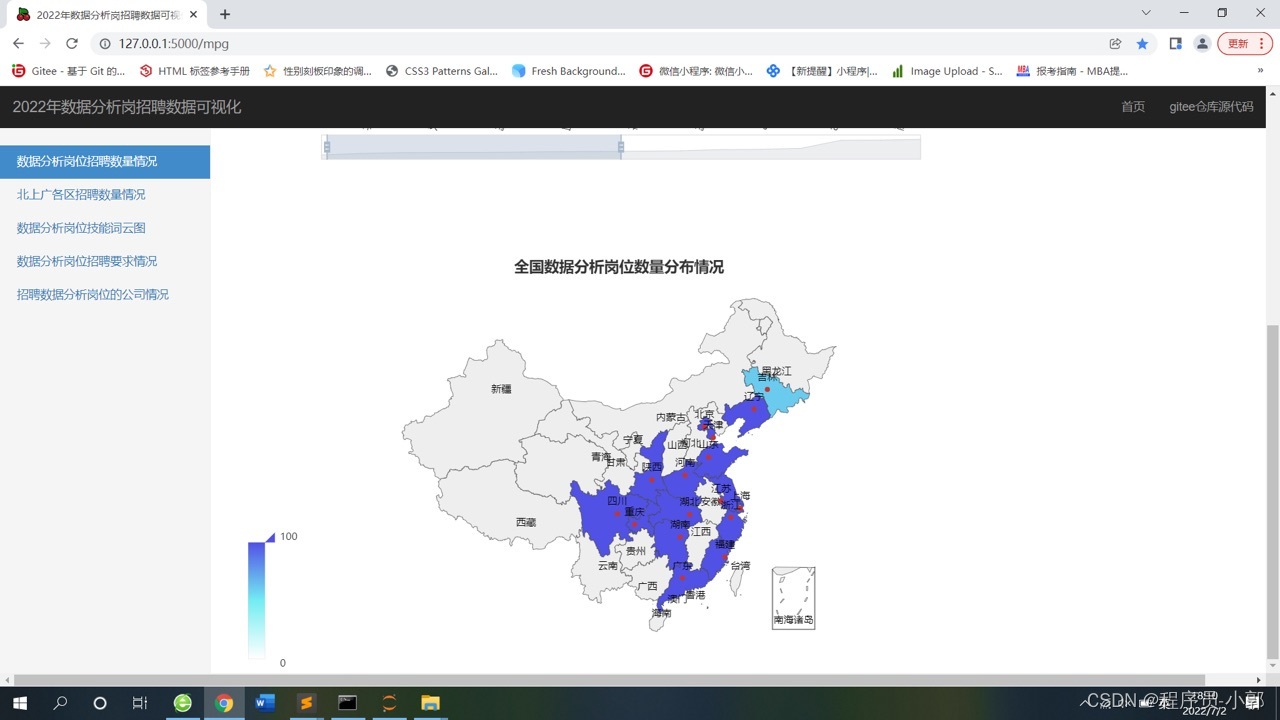
4.全国数据分析岗位分布地图
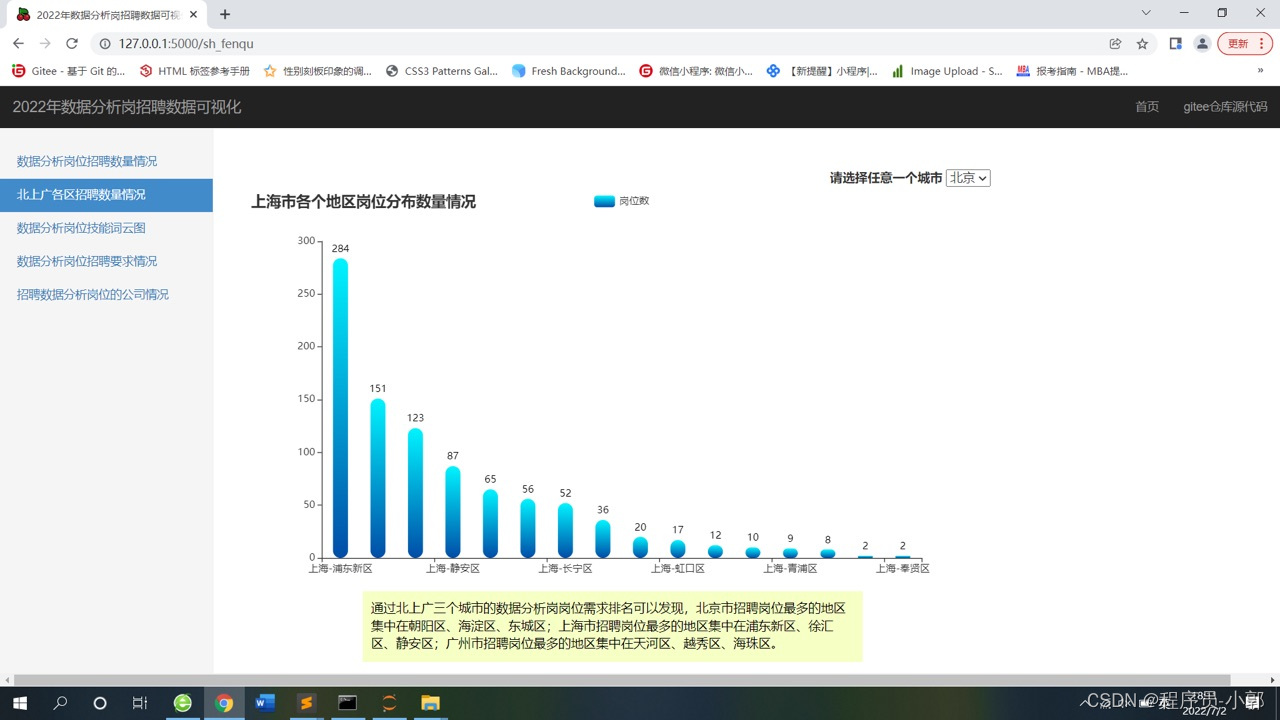
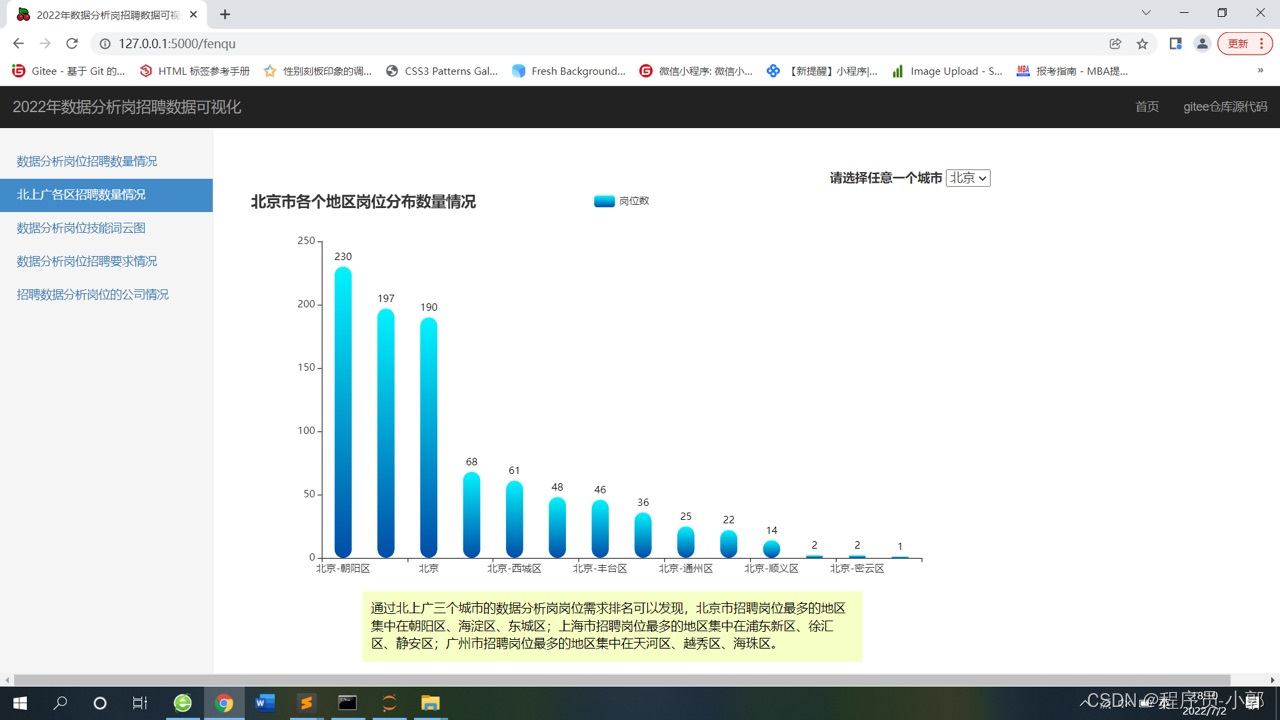
5.北上广各地区岗位分布情况柱状图
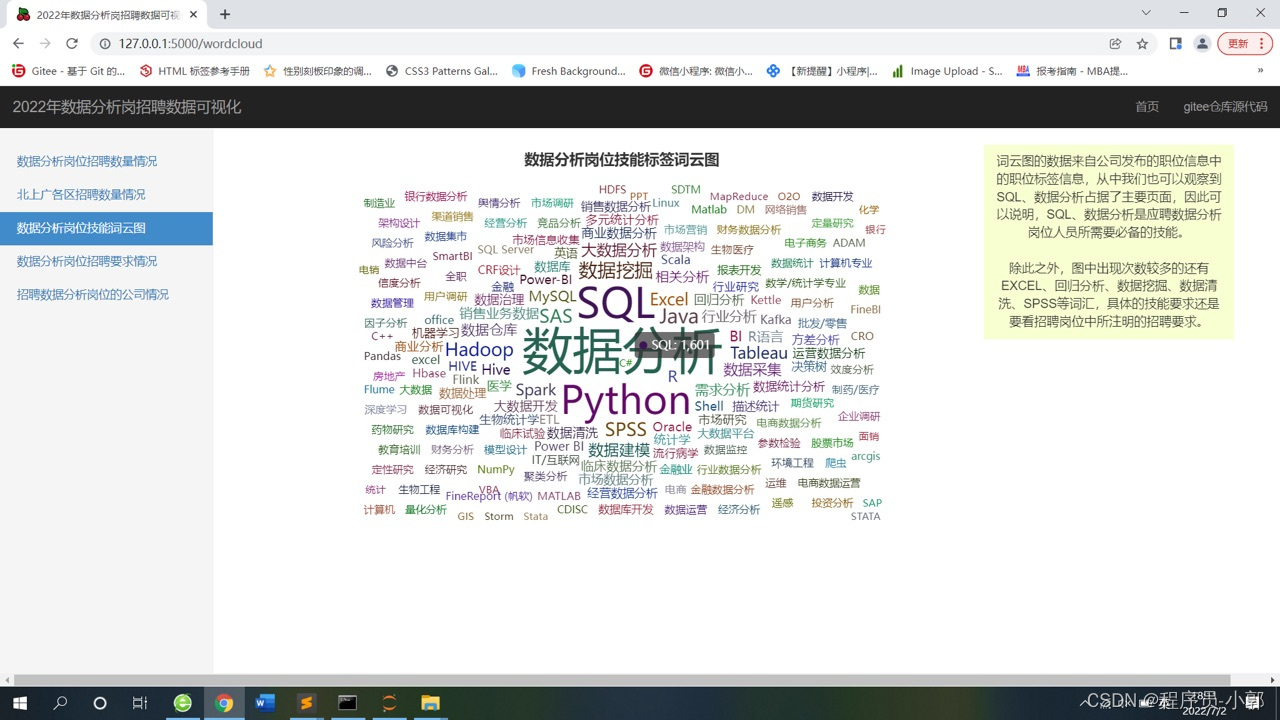
6.数据分析岗位技能词云图
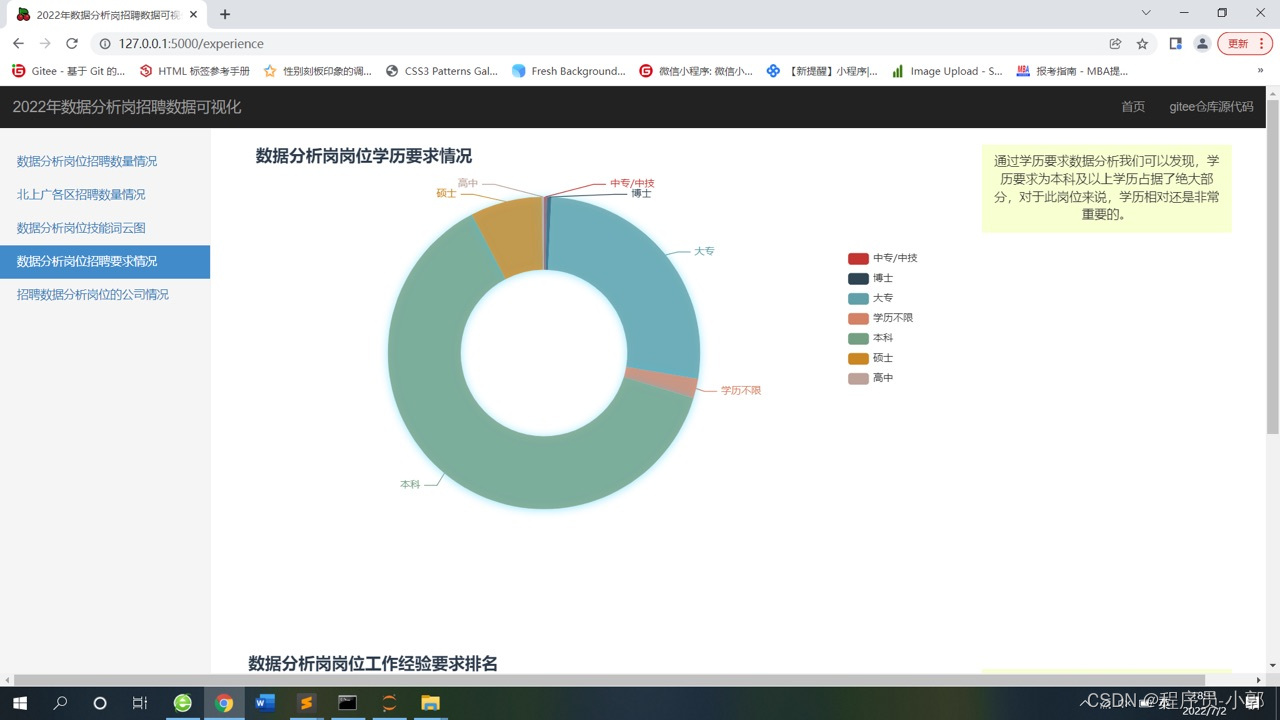
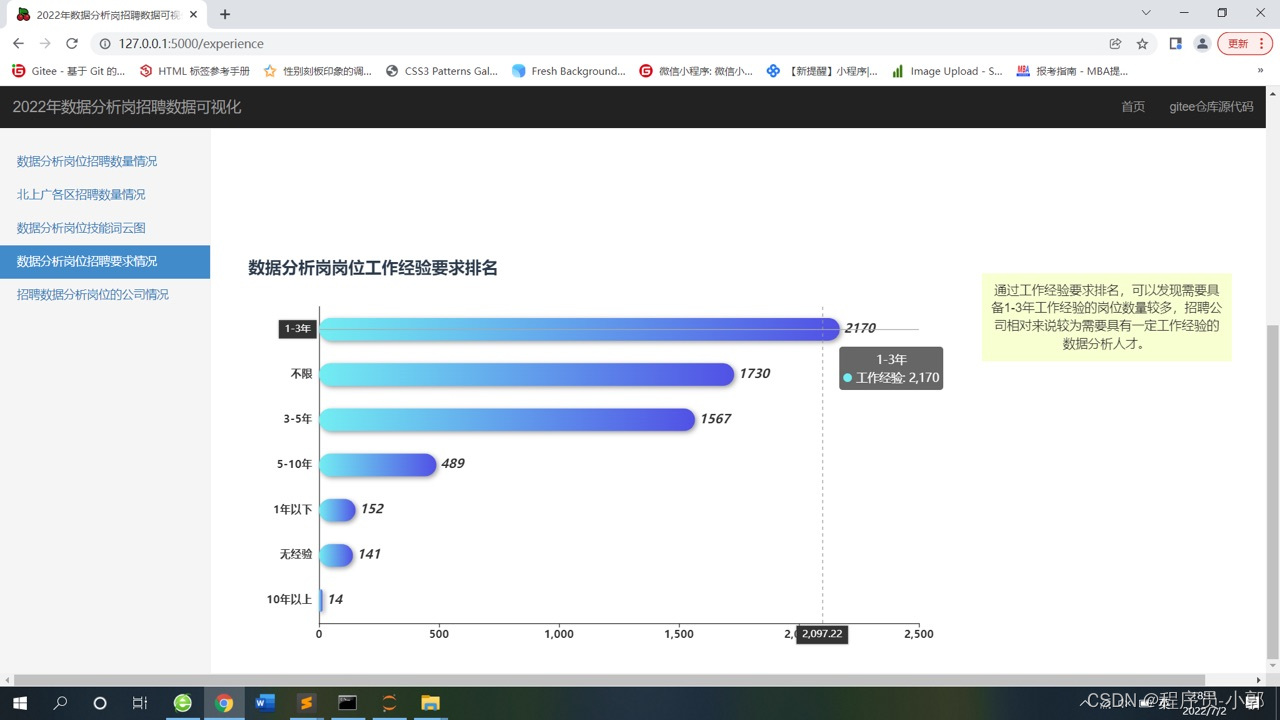
7.数据分析岗位学历占比圆环图、工作经验要求排名条形图
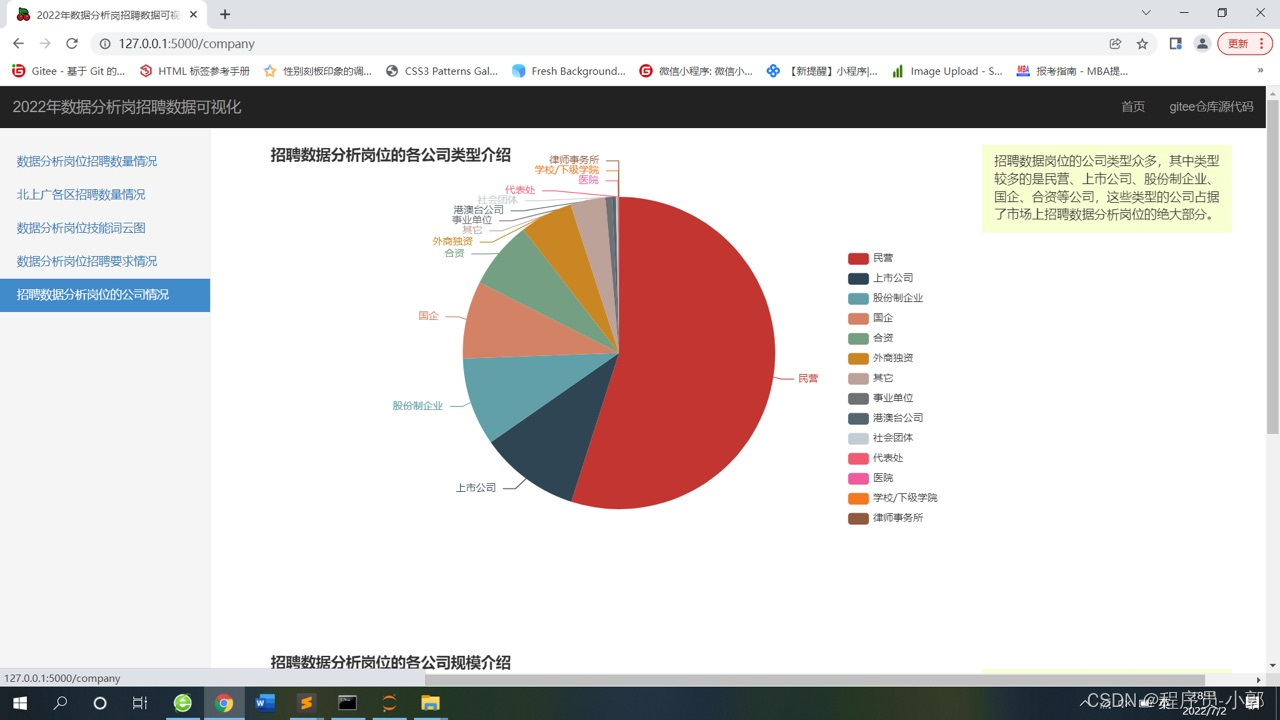
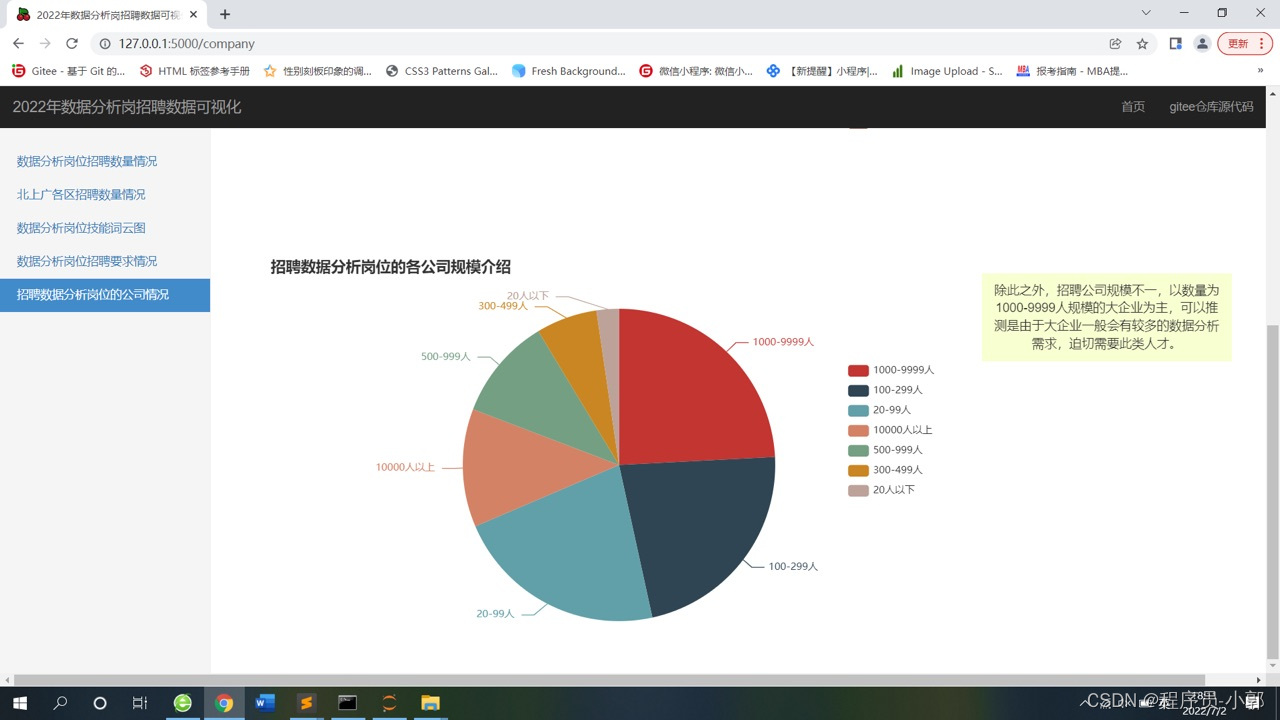
8.数据分析岗位各公司类型占比、各公司规模占比
(1)各个详细功能具体可看运行效果截图
(2)网站均可使用django-admin构建超级管理员管理后台
(3)代码结构清晰简单,可二次开发、可定制功能
源码资料获取:公众号【匠心程序定制】
代码都是亲自运行且完整的,可提供二次修改以及优化功能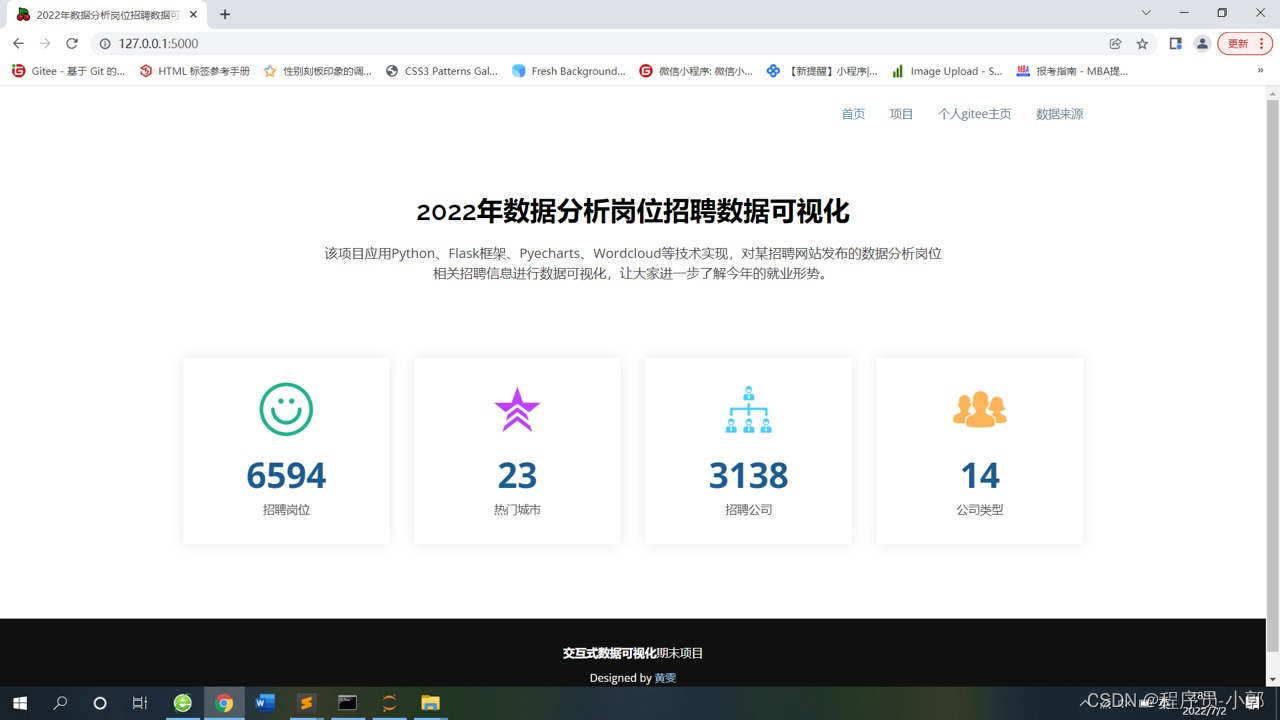















 2339
2339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









