






由于我训练的时候没有直接使用tensorboard,所以需要在保存的text文件中提取epoch、loss、IoU等值,然后在tensorboard中画出来。
一、text中提取数据(re.findall()函数)
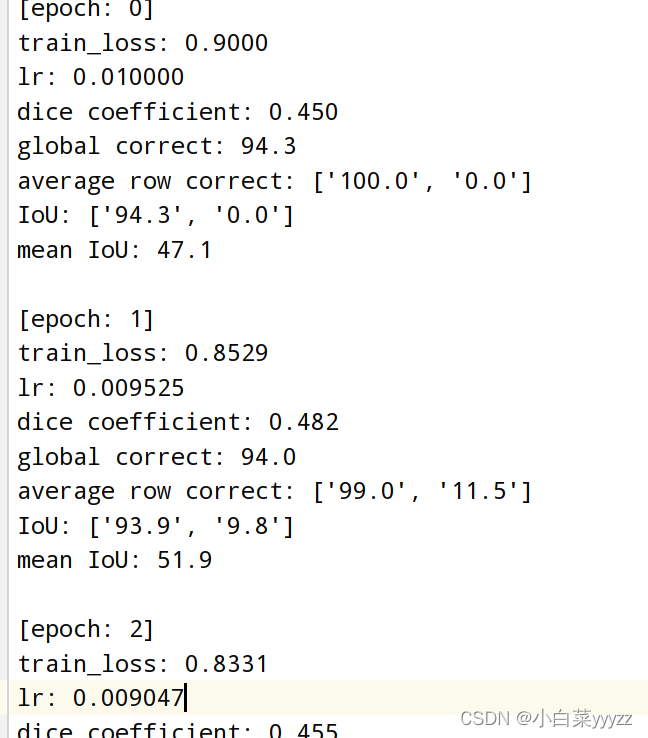
如左下图所示,为我保存的训练数据(跟着霹雳啪啦源码修改滴,感谢霹雳啪啦!)
首先,我读取了txt文件,然后根据我想得到的数据,设置了正则化表达式(经过测试,text是全部内容,pattern里写文件里目标数据左右的构成,就能定位数据)。右图为findall()函数返回所有匹配的数字组成的列表(来自参考1)。

然后是我的提取程序:因为loss等是浮点格式,\d的话提取的是int的,所以我用的\S+提取,提取完又转化成了float形式(注意提取出来的是列表list),然后又转换了array形式;还有就是我理解的是:\d+,“+”的含义就是不定义提取几个数字,“\d{2}”这种的话就是确定2个;
with open('results20240417-212620.txt', 'r') as file:
content = file.read()
text = content
pattern = r'epoch:\s+(\d+)+]'
patternn = r'train_loss:\s+(\S+)'
patternnn = r'global\s+correct:\s+(\S+)'
IOU = r'mean\s+IoU:\s+(\S+)'
# epoch = np.fromiter(list(map(int,re.findall(pattern,text))),dtype=int)
epoch = list(map(int, re.findall(pattern, text)))
train_loss = np.fromiter(list(map(float,re.findall(patternn,text))),dtype=float)
global_correct = np.fromiter(list(map(float,re.findall(patternnn,text))),dtype=float)
mean_IOU = np.fromiter(list(map(float,re.findall(IOU,text))),dtype=float)二、数据放到tensorboard里
首先别忘了前面的这个:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(log_dir="U-net", comment="Loss(U-net)")第一部分里,我后来把提取出来的列表→数字→array形式就是因为 writer.add_scalar() 一直报错。而且scalar() 按照我的理解还得是一个一个进(因为我直接用数组它还报错0维),于是我就改成了下面这样:
for i in range(20):
writer.add_scalar("U-net/loss", train_loss[i], i)
writer.add_scalar("U-net/correct",global_correct[i] , i)
writer.add_scalar("U-net/mIoU",mean_IOU[i], i)
writer.close()
终端(在虚拟环境下哟)输入:
tensorboard --logdir=D:\Program\pythonProject\unet\unet\U-net --port=6007
#绝对路径感觉比文件夹名称好用,顺便改了一个端口(因为看别人都改,从众心理)
最后展示一下结果:(因为用cpu训练,就跑了20轮效果一般哈)
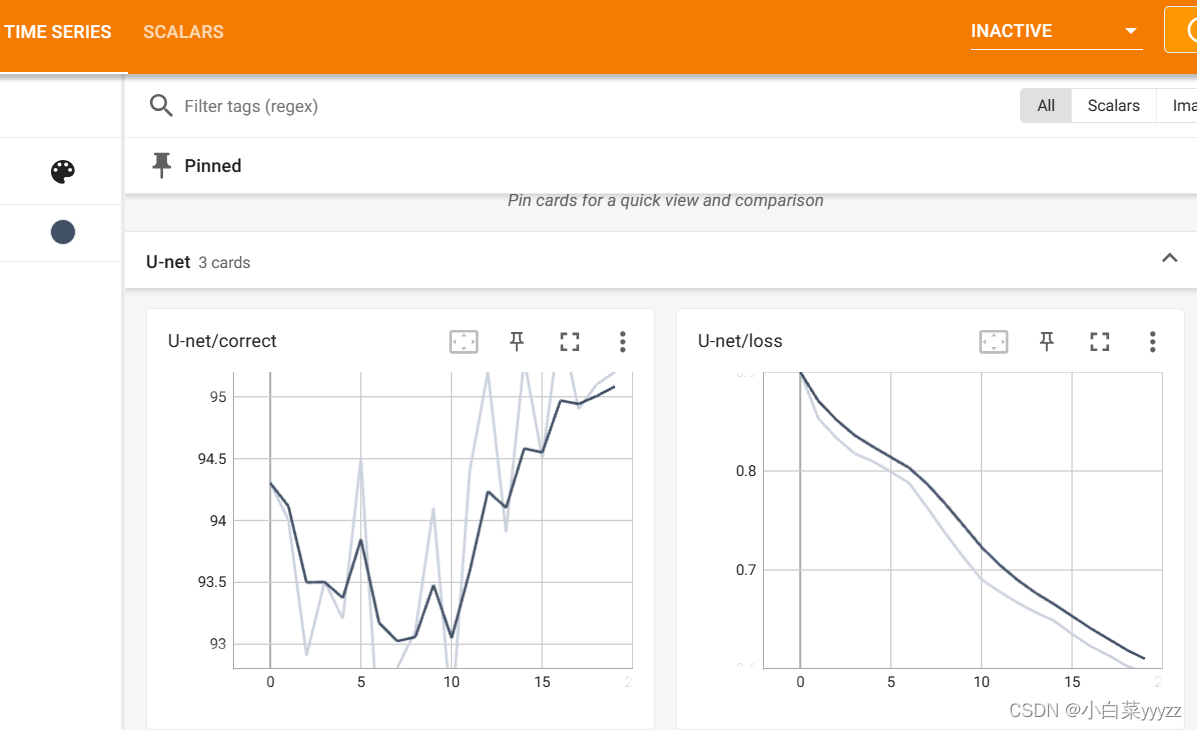
引用
[1]Python中的findall神器:从入门到精通 (baidu.com)
最后PS:文章仅代表个人意见,本人只是一个自动化专业的初步接触这方面的小菜鸟(自动化还是大二后来转的呢开始是材料的...) 不准确处望海涵+请批评指出~
















 1995
1995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











