







论文:http://arxiv.org/pdf/2405.13792v1
代码地址:https://github.com/McGill-NLP/llm2vec
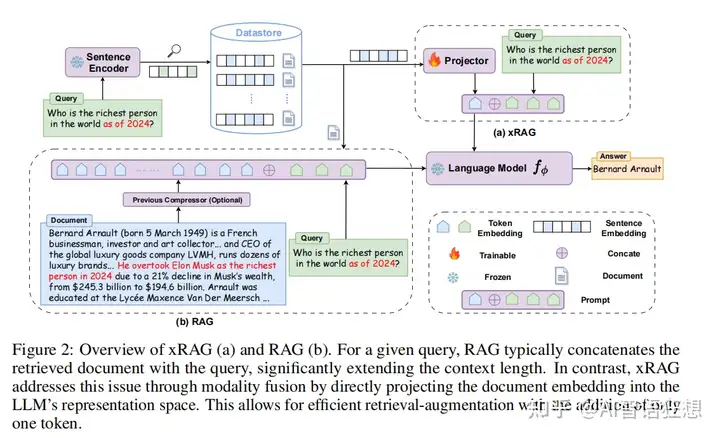
微软和北大团队提出xRAG,这是一种为检索增强型生成任务量身定制的上下文压缩方法。xRAG通过重新解释在密集检索中使用的文档嵌入,将它们作为检索模态的特征,并运用模态融合方法将这些嵌入无缝集成到语言模型的表示空间中。这种方法有效地消除了对文本对应项的需求,并实现了极端的压缩率。在xRAG中,唯一可训练的组件是模态桥接器,而检索器和语言模型保持不变。这种设计选择允许重用离线构建的文档嵌入,并保持了检索增强的即插即用特性。
实验结果表明,xRAG在六个知识密集型任务上平均提高了超过10%的性能,适用于从密集的7B模型到8x7B专家混合配置的各种语言模型。xRAG不仅显著优于以前的上下文压缩方法,而且在几个数据集上与未压缩模型的性能相匹
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











