







- 论文:https://arxiv.org/pdf/2410.21252
- 代码:https://github.com/THUDM/LongReward
- 机构:清华大学 & 中科院 & 智谱
- 领域:长上下文LLM
- 发表:arxiv

研究背景
- 研究问题:这篇文章要解决的问题是如何在长上下文场景下,利用AI反馈来提高大型语言模型(LLMs)的性能。具体来说,现有的长上下文LLMs在监督微调(SFT)过程中合成的数据质量较差,影响了模型的长上下文性能。
- 研究难点:该问题的研究难点包括:如何在长上下文中获取可靠的奖励信号,以及如何将长上下文RL算法与SFT结合以提高模型性能。
- 相关工作:该问题的研究相关工作有:设计高效的注意力机制或结构化状态空间模型来扩展上下文窗口,使用自动合成的SFT数据进行模型训练,以及利用AI反馈来优化模型的无害性和真实性。
研究方法

这篇论文提出了LongReward方法,用于解决长上下文LLMs的奖励信号获取问题。具体来说,
-
多维度评分:LongReward利用一个现成的大型语言模型(LLM)从四个人类价值维度对长上下文模型响应进行评分:有用性、逻辑性、忠实性和完整性。每个维度的评分范围为0到10,最终奖励为这四个评分的平均值。
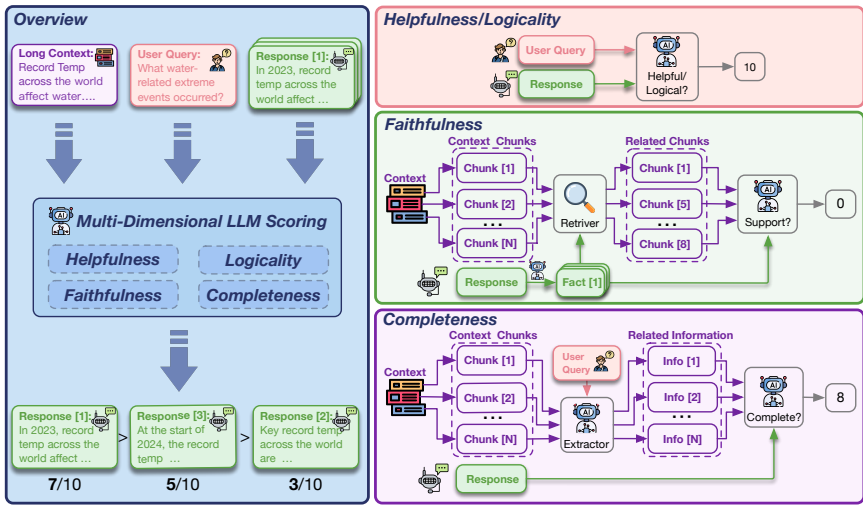
-
有用性评分:对于有用性,LLM根据查询和响应内容直接评分。引入Chain-of-Thought(CoT),要求LLM在提供最终评分前生成分析,以增强评分的可靠性和互操作性。
-
逻辑性评分:对于逻辑性,LLM检测响应中的逻辑错误,这些错误通常由于LLMs的生成方式导致。同样采用CoT来增强评分的可靠性。
-
忠实性评分:对于忠实性,LLM将响应分解为一组事实陈述,并判断每个陈述是否由检索到的上下文支持。为了适应长上下文场景,改进了事实分解和评估方法。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











