







- 论文:https://aclanthology.org/2024.acl-long.769.pdf
- 代码:https://github.com/tianyi-lab/Superfiltering
- 机构:马里兰大学 & 平安科技
- 领域: llm 数据筛选
- 发表:ACL2024
作者总结:https://zhuanlan.zhihu.com/p/718119728

研究背景
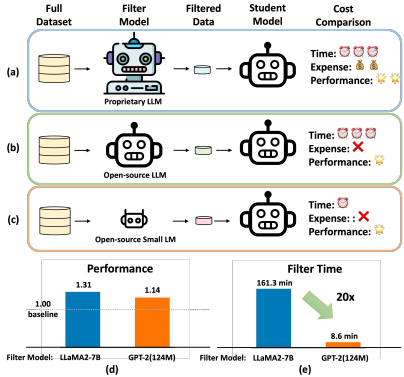
- 研究问题:这篇文章要解决的问题是如何在指令调优过程中减少数据过滤的成本。具体来说,研究能否使用一个更小、更弱的模型来选择数据,以便用这些数据来微调一个更大、更强的模型。
- 研究难点:该问题的研究难点包括:弱语言模型和强语言模型在感知指令难度和数据选择结果上的一致性;如何在保证数据质量的前提下,显著加快数据过滤的速度。
- 相关工作:早期的指令调优工作主要依赖于大规模、多样化和高质量的数据集,但这些数据集的制作成本高昂。最近的研究提出了利用强大的教师LLM生成数据的方法,但这些方法的质量难以控制。此外,现有的数据过滤方法通常需要使用与ChatGPT相当的模型,导致计算成本高且延迟大。
研究方法
这篇论文提出了Superfiltering方法,用于解决指令调优中的数据过滤成本高的问题。具体来说,
- 数据过滤指标:首先,论文提出使用两个主要的指标来评估数据的质量:困惑度(Perplexity)和指令跟随难度(IFD)分数。困惑度是衡量模型生成响应的容易程度的指标,而IFD分数则比较了在有和无指令上下文的情况下,模型生成响应的损失或困惑度,衡量指令对生成响应的帮助程度。
- 弱到强一致性:研究发现,尽管弱语言模型和强语言模型在预训练阶段的内在能力差异很大,但它们在感知指令难度方面具有一致性。这种一致性体现在不同模型对同一数据集的排序上,通过计算Spearman等级相关系数来验证。
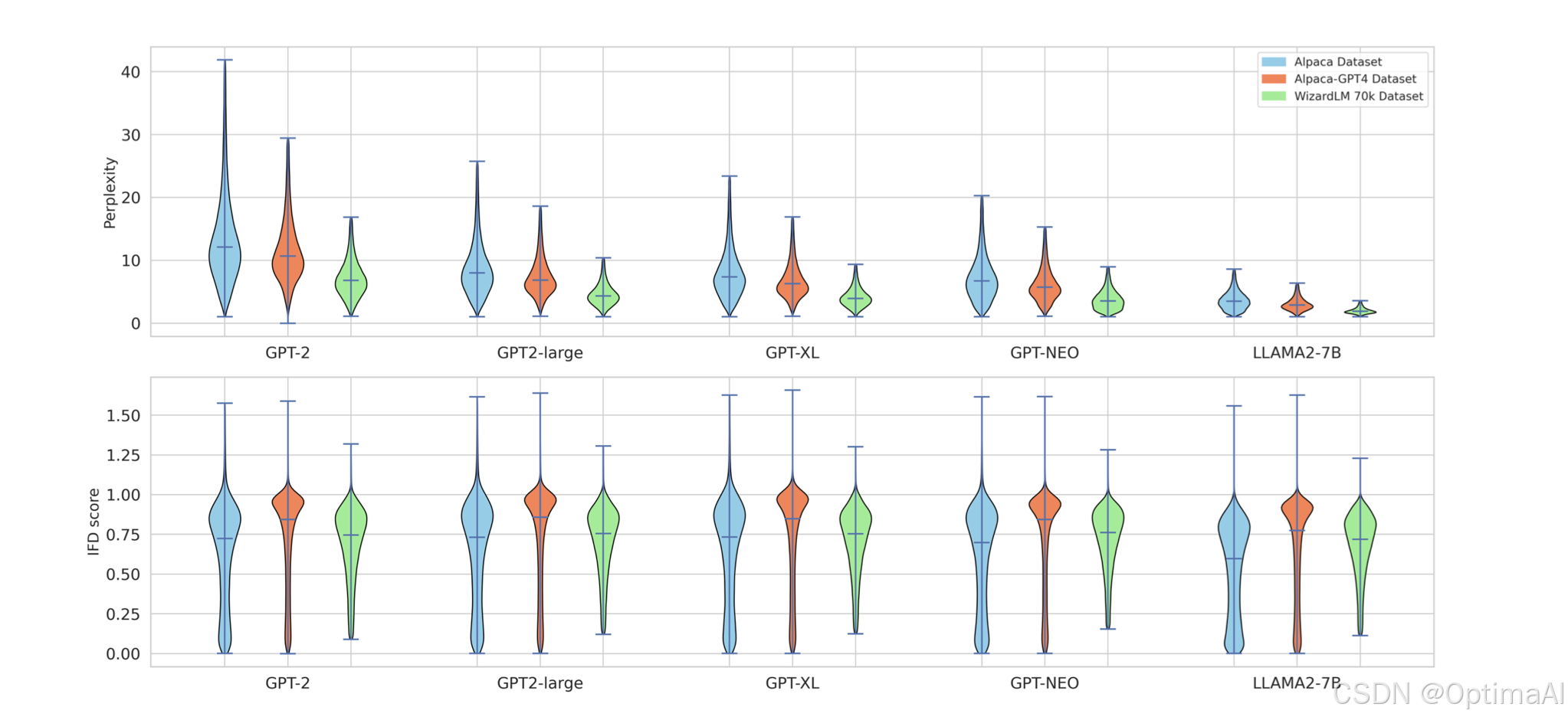
五种模型(从左到右:从弱到强)在三个指令调整数据集上计算出的困惑度(顶部)和 IFD 分数(底部)的分布。观察结果:
(1)不同模型的困惑度规模差异很大,表明它们的生成能力存在差异;
(2)不同模型的 IFD 分数规模一致,表明它们在衡量难度方面是一致的。
- Superfiltering方法:基于上述发现,论文提出了Superfiltering方法,即利用一个较小的模型(如GPT-2)来计算每个样本的IFD分数,并选择IFD分数最高的前k%样本进行调优。这种方法显著加快了数据过滤的速度,同时保证了调优后的LLM在标准基准测试中的性能。
实验设计
- 数据集:实验使用了两个数据集:Alpaca和Alpaca-GPT4。Alpaca数据集由斯坦福大学开发,包含52,000个指令跟随样本,使用self-instruct范式生成。Alpaca-GPT4数据集包含GPT4生成的响应。
- 实现细节:实验使用了Vicuna和flash attention作为提示和代码基础,整体训练参数与常见配置一致。Adam优化器用于训练,学习率分别为2×10^-5(LLaMA2-7B)和1×10^-5(LLaMA2-13B),批量大小为128,训练三个epoch,最大长度为2048,预热率为0.03。
- 评估指标:自动评估包括成对比较、Huggingface Open LLM排行榜和AlpacaEval排行榜。人类评估随机抽取100个WizardLM测试集中的指令,由3个人类参与者根据帮助性、相关性、准确性和细节水平进行比较,最终结果由多数投票决定。
结果与分析
-
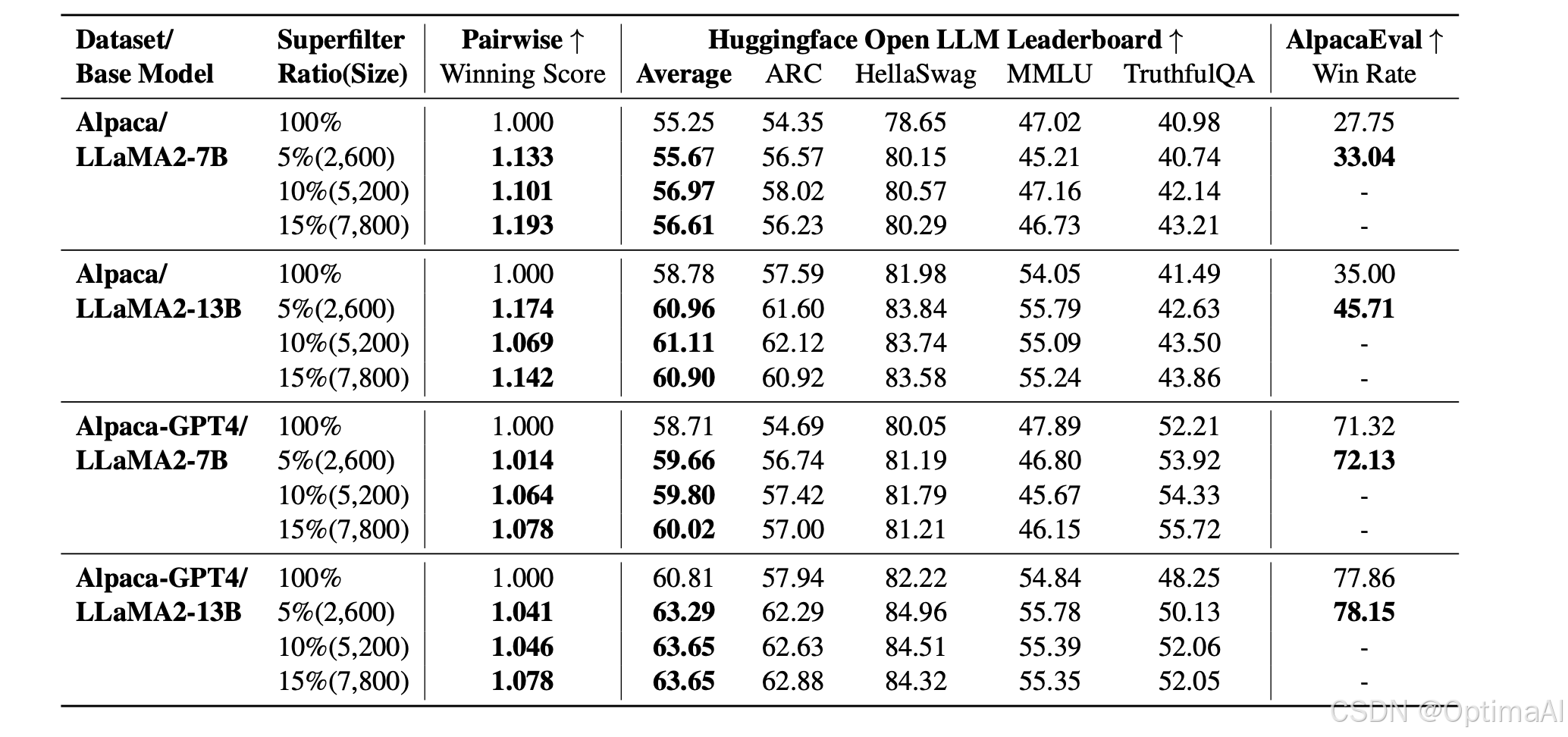
主要结果:Superfiltering方法在使用5%数据的情况下,调优后的LLM在成对比较、Huggingface Open LLM排行榜和AlpacaEval排行榜上的表现均优于或等同于使用全量数据进行调优的模型。这表明Superfiltering方法在减少计算开销的同时,保持了甚至提高了LLM的调优性能。
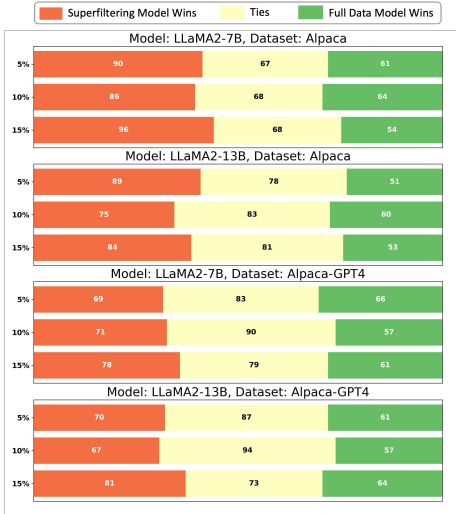
-
对比其他方法:与ChatGPT评分和奖励模型评分相比,Superfiltering方法在成对比较中的胜率高且过滤效率高。与直接计算IFD分数的方法相比,Superfiltering方法的过滤时间减少了20倍,且过滤时间小于后续的训练时间,使其在实际应用中可行。
-
消融研究:通过消融实验验证了不同数据选择策略和过滤器模型的有效性。结果表明,Superfiltering方法在各种策略和模型下的表现均优于全量数据调优模型。
总体结论
这篇论文揭示了弱语言模型和强语言模型在感知指令难度方面的一致性,并提出了Superfiltering方法,通过有效利用较弱模型作为代理来评估指令数据,显著提高了指令调优的效率。实验结果证实了该方法在减少计算开销的同时,保持了甚至提高了LLM的调优性能。Superfiltering方法为AI技术的发展提供了一个可扩展、资源高效且有效的策略。
论文评价
优点与创新
- 弱到强的数据过滤一致性:论文揭示了弱语言模型和强语言模型在感知指令难度方面的一致性,这一发现为利用弱模型作为强模型的代理提供了理论基础。
- 高效的超过滤策略:提出了第一个利用小模型(如GPT-2)进行数据选择的超过滤方法,显著加快了LLM微调管道的速度。
- 广泛的实验验证:在多个广泛使用的指令数据集上进行了广泛的实验,验证了所提出方法的有效性和效率。
- 无需额外训练:超过滤方法不需要对弱语言模型进行进一步训练,也不需要额外的保留集,简化了数据选择过程。
- 数据集评估的新方法:发现基于困惑度的指标在不同语言模型之间具有一致性,提供了一种高效且通用的数据集评估方法。
不足与反思
- 数据多样性:超过滤主要利用IFD分数选择数据,关注指令难度,未来应包括数据多样性等其他维度。
- 数据集和模型范围:目前涉及3个数据集和2个LLaMA2基础模型,建议进一步研究其在更广泛的LLM和数据集上的有效性。
关键问题及回答
问题1:Superfiltering方法是如何利用弱语言模型(如GPT-2)来提高指令调优的数据过滤效率的?
Superfiltering方法通过利用弱语言模型(如GPT-2)来计算每个样本的指令跟随难度(IFD)分数,从而选择出高质量的数据进行调优。具体步骤如下:
- 计算IFD分数:利用GPT-2模型计算每个数据样本的IFD分数。IFD分数通过比较有指令和无指令情况下的模型困惑度来衡量,值越高表示指令对生成响应的帮助越大。
- 选择高质量数据:选择IFD分数最高的前k%样本进行调优。这些样本被认为是最具挑战性和信息量的,能够显著提高调优后模型的性能。
- 加速数据过滤:由于GPT-2模型较小,计算速度快,能够在短时间内完成大量数据样本的IFD分数计算,从而显著加快数据过滤的速度。
问题2:Superfiltering方法在不同数据集上的表现如何?与其他数据过滤方法相比有何优势?
Superfiltering方法在多个数据集上进行了实验,包括Alpaca和Alpaca-GPT4数据集。实验结果表明,Superfiltering方法在使用5%数据的情况下,调优后的模型在成对比较、Huggingface Open LLM排行榜和AlpacaEval排行榜上的表现均优于或等同于使用全量数据的模型。
与其他数据过滤方法相比,Superfiltering方法具有以下优势:
- 更高的过滤效率:Superfiltering方法利用GPT-2模型快速计算IFD分数,过滤时间减少了20倍,显著提高了数据过滤的速度。
- 更好的模型性能:尽管使用较少的数据,Superfiltering方法调优后的模型性能不仅没有下降,反而在某些情况下优于使用全量数据的模型。
- 资源高效:Superfiltering方法仅使用较小的GPT-2模型,不需要大型工业级GPU,可以在普通消费者级别的GPU上实现,降低了计算资源的消耗。
问题3:Superfiltering方法在不同评估指标上的表现如何?人类评估的结果如何?
Superfiltering方法在不同评估指标上均表现出色。自动评估使用了成对比较、Huggingface Open LLM排行榜和AlpacaEval排行榜三种指标,结果显示Superfiltering方法在使用5%数据的情况下,模型在这些指标上的表现均优于或等同于使用全量数据的模型。
人类评估方面,研究随机抽取了100个WizardLM测试集中的指令,由3个人类参与者根据帮助性、相关性、准确性和细节水平进行评分。结果显示,Superfiltering方法调优后的模型在人类评估中也表现优异,进一步验证了其有效性。具体来说,在Alpaca数据集上,Superfiltering方法调优的模型在5%数据情况下的人类评估获胜率为50/100,平局率为18/100,失败率为32/100;在Alpaca-GPT4数据集上,获胜率为49/100,平局率为5/100,失败率为46/100。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











