







- 论文:https://arxiv.org/pdf/2303.01248
- 代码:GitHub - Kali-Hac/ChatGPT-MBTI: [EMNLP-2023] Official Codes for “Can ChatGPT Assess Human Personalities? A General Evaluation Framework”
- 机构:南洋理工大学 & 大不列颠哥伦比亚大学
- 领域: llm 数据筛选
- 发表:EMNLP2023

研究背景
- 研究问题:这篇文章探讨了大型语言模型(LLMs),特别是ChatGPT,是否能够评估人类的个性。现有工作主要研究了LLMs的虚拟人格,但很少探索通过LLMs分析人类个性的可能性。
- 研究难点:该问题的研究难点包括:如何设计无偏提示以鼓励LLMs生成更公正的答案;如何使LLMs能够灵活地查询和评估不同受试者的个性;如何通过正确性评估指令使LLMs生成更清晰的回答。
- 相关工作:相关研究包括对LLMs的人格特质进行评估(Li et al., 2022; Jiang et al., 2022; Karra et al., 2022; Caron and Srivastava, 2022; Miotto et al., 2022)以及评估LLMs的语言模型偏见(Bolukbasi et al., 2016; Sheng et al., 2019; Bordia and Bowman, 2019; Nadeem et al., 2021; Zong and Krishna-machari, 2022; Zhuo et al., 2023)。
研究方法
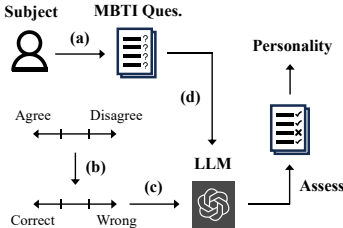
这篇论文提出了一个通用评估框架,用于通过MBTI测试评估LLMs对人类个性的理解。具体来说,
-
无偏提示设计:为了鼓励LLMs生成更一致和无偏的答案,研究者提出了无偏提示的设计方法。具体步骤包括:随机排列MBTI问题中的选项,并在不改变问题陈述的情况下采用多次独立测试的平均结果作为最终答案。公式如下:
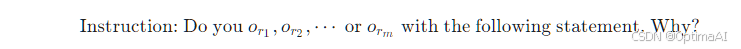
其中,![]() 表示随机排列的选项。
表示随机排列的选项。
主题替换查询:为了使LLMs能够分析特定受试者的个性,研究者提出了主题替换查询(SRQ)。通过将原始问题中的“你”替换为感兴趣的主题(如“男人”),从而请求LLMs分析和推断该主题的个性。例如:
![]() 正确性评估指令:为了解决LLMs无法拥有个人情感或信念的问题,研究者提出了正确性评估指令(CEI)。通过将原始选项转换为{正确,一般正确,部分正确,既不正确也不错误,部分错误,一般错误,错误},并基于CEI构建无偏提示。例如:
正确性评估指令:为了解决LLMs无法拥有个人情感或信念的问题,研究者提出了正确性评估指令(CEI)。通过将原始选项转换为{正确,一般正确,部分正确,既不正确也不错误,部分错误,一般错误,错误},并基于CEI构建无偏提示。例如:
![]()
研究背景
- 研究问题:这篇文章探讨了大型语言模型(LLMs),特别是ChatGPT,是否能够评估人类的个性。现有工作主要研究了LLMs的虚拟人格,但很少探索通过LLMs分析人类个性的可能性。
- 研究难点:该问题的研究难点包括:如何设计无偏提示以鼓励LLMs生成更公正的答案;如何使LLMs能够灵活地查询和评估不同受试者的个性;如何通过正确性评估指令使LLMs生成更清晰的回答。
- 相关工作:相关研究包括对LLMs的人格特质进行评估(Li et al., 2022; Jiang et al., 2022; Karra et al., 2022; Caron and Srivastava, 2022; Miotto et al., 2022)以及评估LLMs的语言模型偏见(Bolukbasi et al., 2016; Sheng et al., 2019; Bordia and Bowman, 2019; Nadeem et al., 2021; Zong and Krishna-machari, 2022; Zhuo et al., 2023)。
研究方法
这篇论文提出了一个通用评估框架,用于通过MBTI测试评估LLMs对人类个性的理解。具体来说,
-
无偏提示设计:为了鼓励LLMs生成更一致和无偏的答案,研究者提出了无偏提示的设计方法。具体步骤包括:随机排列MBTI问题中的选项,并在不改变问题陈述的情况下采用多次独立测试的平均结果作为最终答案。公式如下:
Instruction: Do you or1,or2,⋯ or orm with the following statement. Why?其中,OR={or1,or2,⋯,orm}∈Ω(OI) 表示随机排列的选项。
-
主题替换查询:为了使LLMs能够分析特定受试者的个性,研究者提出了主题替换查询(SRQ)。通过将原始问题中的“你”替换为感兴趣的主题(如“男人”),从而请求LLMs分析和推断该主题的个性。例如:
SRQ Statement: Men spend a lot of their free time exploring various random topics that pique their interests. -
正确性评估指令:为了解决LLMs无法拥有个人情感或信念的问题,研究者提出了正确性评估指令(CEI)。通过将原始选项转换为{正确,一般正确,部分正确,既不正确也不错误,部分错误,一般错误,错误},并基于CEI构建无偏提示。例如:
Correctness-Evaluated Instruction: Is it wrong, correct, generally wrong...... for the following statement. Why?
实验设计
- 数据收集:实验使用了三个LLMs:InstructGPT、ChatGPT和GPT-4。这些模型分别在不同的互联网文本上进行预训练,并具有不同的推理能力和知识广度。
- 实验设置:每个受试者进行15次独立测试,评估LLMs在评估一般人群(如“男人”、“女人”)和特定职业(如“理发师”、“会计师”)的个性时的一致性、鲁棒性和公平性。
- 评估指标:提出了三个评估指标:一致性得分、鲁棒性得分和公平性得分。一致性得分通过比较所有独立测试结果与最终结果之间的相似度来计算;鲁棒性得分通过比较固定顺序选项和随机排列选项的平均测试结果来衡量;公平性得分通过比较不同性别受试者的评估结果的相似度来计算。
结果与分析
-
ChatGPT能否评估人类个性:实验结果表明,ChatGPT和GPT-4在评估不同受试者的个性时表现出更高的灵活性,并且大多数受试者的评估结果一致。例如,会计被评估为“逻辑家”,艺术家被评估为“ENFP-T”,数学家被评估为“建筑师”。
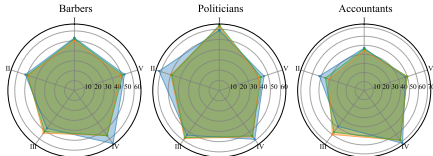
-
评估的一致性、鲁棒性和公平性:ChatGPT和GPT-4在大多数情况下的一致性得分高于InstructGPT,表明它们在多次独立测试中提供了更相似和一致的个性评估结果。然而,它们的鲁棒性得分略低于InstructGPT,表明它们的评估可能对提示偏差更敏感。此外,ChatGPT和GPT-4在评估不同性别受试者时的公平性得分高于InstructGPT,表明它们在评估中更少存在性别偏见。
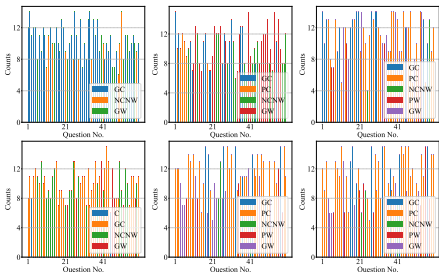
总体结论
这篇论文提出了一个通用评估框架,用于通过MBTI测试评估LLMs对人类个性的理解。研究表明,ChatGPT和GPT-4在评估不同受试者的个性时表现出更高的一致性和公平性,尽管它们对提示偏差的鲁棒性较低。该研究为未来探索LLMs心理学、社会学和治理提供了有价值的见解,并建议在设计训练LLMs时引入更多类似人类的心理学和个性测试,以提高模型的安全性和用户体验。
论文评价
优点与创新
- 首次探索:首次提出了让大型语言模型(LLMs)评估人类性格的可能性,并通过MBTI进行定量评估。
- 无偏提示设计:设计了无偏提示,通过随机排列MBTI问题的选项并采用平均测试结果来鼓励更公正的答案生成。
- 主题替换查询:提出了主题替换查询(SRQ),将原始问题的主体转换为特定主题,以便灵活地查询和分析LLMs对人类性格的评估。
- 正确性评估指令:重新制定了问题指令,使其能够评估问题的正确性,从而获得更清晰的LLMs响应。
- 评估指标:提出了三个定量评估指标,分别衡量LLMs在评估同一主题时的一致性、对输入提示随机扰动的鲁棒性以及评估不同性别主题的公平性。
- 实验结果:实验结果表明,ChatGPT和GPT-4能够在评估不同人群的性格时表现出更高的一致性和公平性,尽管它们对提示偏差的鲁棒性较低。
不足与反思
- 模型局限:研究聚焦于ChatGPT模型系列,实验在有限的LLMs上进行。框架可扩展到其他LLMs(如LLaMA),但其性能仍需进一步探索。
- 实验设置:尽管大多数独立测试在相同标准设置下得出相似的评估结果,但实验设置(如超参数)或测试次数可以进一步定制,以测试LLMs在极端情况下的可靠性。
- 性别表示不足:不同性别的表示可能不足,例如“女士”和“先生”也被视为不同的性别群体。未来工作将进一步探索更多样化的评估对象。
- MBTI的科学有效性:尽管MBTI在不同领域广受欢迎,但其科学有效性仍在探索中。未来工作将探索其他测试(如大五人格清单BFI)。
- 伦理考虑:滥用潜力:研究具有探索性,不应直接将评估结果(如不同职业的人格)与现实生活中的人匹配,以免导致不现实的结论和负面社会影响。偏见:使用的LLMs在大规模数据集或互联网文本上预训练,可能包含不同的偏见或不安全内容。尽管经过人类微调,模型仍可能生成一些不符合社会观念或价值观的偏见性人格评估。
关键问题及回答
问题1:论文中提出的无偏提示设计是如何具体实现的?其目的是什么?
无偏提示设计通过随机排列MBTI问题中的所有可用选项(例如,同意、不同意),同时保持问题陈述不变,来构建输入提示。然后,采用多次独立测试的平均结果作为最终答案。这样做的目的是减少提示偏差对LLMs生成答案的影响,从而鼓励LLMs生成更一致和无偏的答案。具体实现步骤如下:
- 随机排列选项:对于每个独立测试的问题,随机排列所有可用选项,例如,将“同意”变为“不同意”,“不同意”变为“同意”,以此类推。
- 保持问题陈述不变:不改变问题的陈述部分,确保问题的核心内容不变。
- 多次独立测试:对每个问题进行多次独立测试,记录每次测试的结果。
- 平均结果:将多次测试的结果进行平均,作为最终的评估结果。
问题2:论文中提出的主题替换查询(SRQ)是如何提高LLMs评估个性的灵活性的?
主题替换查询(SRQ)通过将原始问题中的主题(例如,“你”)替换为感兴趣的主题(例如,“男人”),使得LLMs能够分析特定受试者的个性。具体实现步骤如下:
- 选择目标主题:确定希望LLMs分析的目标主题,例如,“男人”、“女人”、“理发师”等。
- 替换主题:将原始问题中的主题替换为目标主题。例如,将“你通常花很多时间探索各种随机话题”替换为“男人通常花很多时间探索各种随机话题”。
- 构建查询:使用替换后的主题构建新的查询语句,并将其作为输入提示传递给LLMs。
通过这种方式,LLMs需要分析和推断特定主题的个性特征,而不是自我报告,从而提高了评估个性的灵活性。这种方法不仅使LLMs能够处理更广泛的主题,还增强了其评估不同受试者个性的能力。
问题3:论文中提出的正确性评估指令(CEI)是如何帮助LLMs生成更清晰的回答的?
正确性评估指令(CEI)通过将原始的一致性测量指令转换为正确性评估指令,使LLMs评估问题陈述的正确性,而不是直接询问其同意或不同意程度。具体实现步骤如下:
- 转换选项:将原始选项(例如,同意、不同意、中立)转换为正确性评估选项(例如,正确、部分正确、错误)。例如,将“同意”变为“正确”,“不同意”变为“错误”。
- 构建正确性评估指令:使用转换后的选项构建新的问题陈述,并要求LLMs评估其正确性。例如,将“你是否同意以下陈述?”转换为“以下陈述是否正确?”。
- 生成回答:LLMs根据正确性评估指令生成回答,这些回答通常会更清晰和具体,因为它们需要直接评估陈述的正确性,而不是简单地表达同意或不同意。
通过这种方式,CEI使LLMs能够生成更清晰和有意义的回答,避免了直接询问同意或不同意可能带来的中性回答问题。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











