







你是一个开发者,假如现在给出这样的一个需求:调用 ChatGPT 的 API 接口,通过程序与 ChatGPT 对话,你第一时间想到啥?我——或者说两个月前的我,想到的是 Python。
我目前只是程序员群体中一个初出茅庐的菜鸟,对技术的把握和理解不深,只是直观感觉,AI 开发似乎和 Python 绑定得很深——TensorFlow、PyTorch、MXNet、Keras、PaddlePaddle、MindSpore……就连大模型接口的调用似乎 Python 也是主流。
然而作为未来的 Java 从业者,又想“专情”一点,不想一遇到 AI 的业务就换语言,咋办?
这时候,Spring AI 扛着音响登场了! 它说:“Spring AI 的成立相信下一波生成式人工智能应用程序不仅适用于 Python 开发人员,而且将在许多编程语言中普遍存在。”
所以,卷卷?卷卷!
初始化一个 Spring AI 应用
Spring AI 是一个相对较新的项目,目前的版本是 0.8.1,0.8.0 版本的最早更新时间,是 2023 年 12 月 1 日,我觉得现在学肯定不是 49 年参国军(狗头保命)。 第一步,先初始化一个 Spring AI 应用的项目。我们在国内用 IDEA 的 Spring Initializer,用的可能是阿里云的镜像,这个镜像目前是还不支持直接初始化 Spring AI 模块。
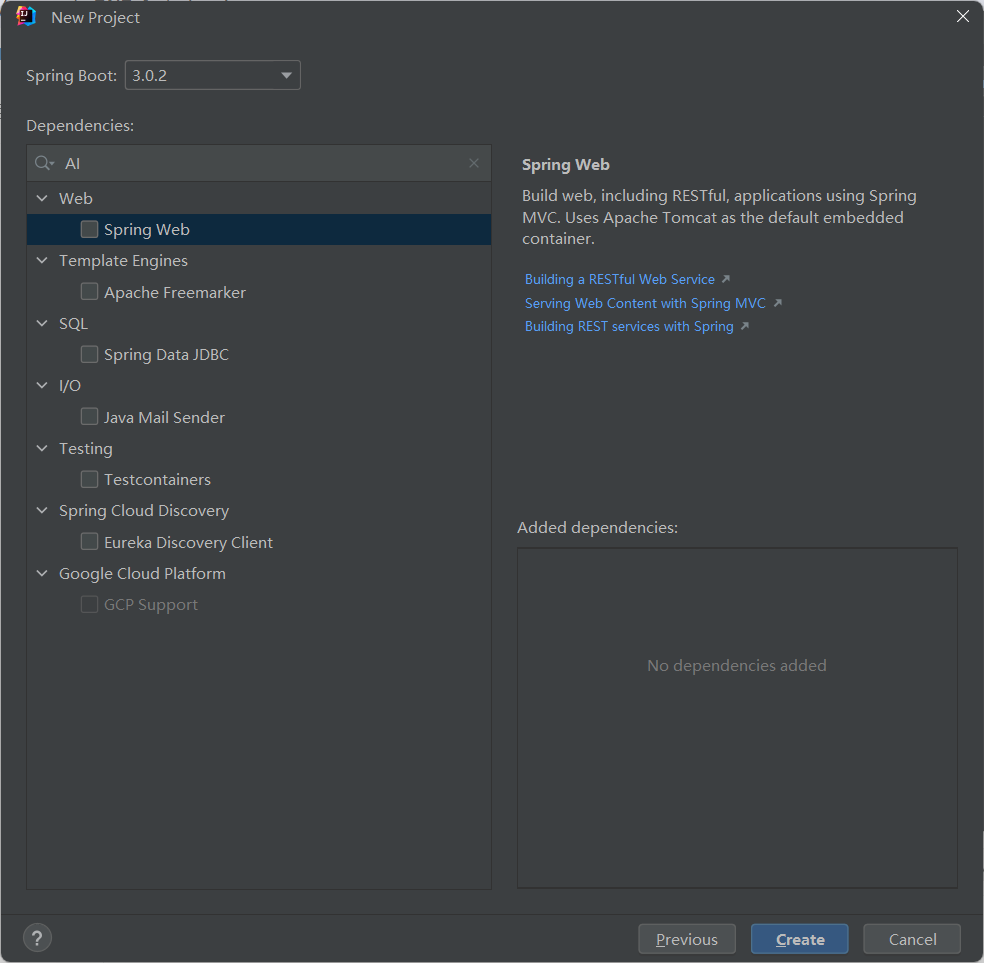
两种方式:
-
直接到 Spring Boot 官方的 Initializer 选择要的依赖,打包下载:https://start.spring.io/
-
问题不大,先初始化,然后手动引入😂
只需要注意的是,Java 版本选择 17 以上,Spring Boot 选择 3.x 版本。 <a name="Rsvfi"></a>
Milestone 和 Snapshot 存储库
假如是构建之后手动引入的话,先要在pom.xml中引入 Milestone 或 Snapshot 存储库,两个都引入或引入一个。
Maven 引入方式:
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>Gradle 引入方式:
repositories {
mavenCentral()
maven { url 'https://repo.spring.io/milestone' }
maven { url 'https://repo.spring.io/snapshot' }
}依赖管理
官方的建议是,在 pom 中通过dependencyManagement 元素添加一个 Spring AI 的 BOM (Bill of Bill of Materials)依赖管理,这样可以集中管理所有依赖的版本号。添加代码:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>0.8.1-SNAPSHOT</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>📓小知识:在Maven管理的
pom.xml中,dependencyManagement元素主要用于集中管理项目中所有依赖(dependencies)的版本号。它的核心价值在于提供一种方式来统一控制项目和其子模块中依赖的版本,从而确保整个项目中各个模块使用依赖的一致性,避免了因依赖版本不一致而导致的编译或运行时错误。 具体来说,dependencyManagement具有以下作用:
版本控制:允许在父
pom.xml中定义依赖的版本号,子模块在声明依赖时不需指定版本号,Maven会自动使用dependencyManagement中定义的版本。这样,当需要更新某个依赖的版本时,只需在一个地方修改,提高了维护效率。简化子模块
**pom.xml**:子模块的pom.xml可以更加简洁,不需要重复声明每个依赖的版本信息,使得 pom 文件更易于阅读和管理。一致性保证:确保整个多模块项目中所有模块使用相同版本的依赖,有助于避免由于不同模块依赖不同版本库而引发的兼容性问题。
可选性:在子模块中声明依赖时,使用
dependencyManagement中定义的版本是可选的,子模块仍然可以覆盖并声明自己的版本号,但这种做法通常只在特殊情况下才推荐。
添加完上述的存储库和依赖管理器之后,依赖环境基本就搞定了,之后用到哪个模块再添加即可。
把 Knife4j 接进来
对没错,Knife4j 也是初始化的一部分。没有前端也可以在浏览器里调试,多香😁
官网:Knife4j · 集Swagger2及OpenAPI3为一体的增强解决方案. | Knife4j 实战指南:1.3 Spring Boot 框架集成Knife4j | Knife4j
首先引入依赖:
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-openapi3-jakarta-spring-boot-starter</artifactId>
<version>4.4.0</version>
</dependency>
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-dependencies</artifactId>
<!--在引用时请在maven中央仓库搜索2.X最新版本号-->
<version>2.0.9</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/com.github.xiaoymin/knife4j-spring-boot-starter -->
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-spring-boot-starter</artifactId>
<version>3.0.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/io.springfox/springfox-swagger2 -->
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>3.0.0</version>
</dependency>然后配置一下yml属性:
# knife4j
knife4j:
enable: true
setting:
language: zh-CN然后写一个配置类:
@Configuration
@EnableSwagger2
@Profile({"dev", "prod"})
public class Knife4jConfig {
@Bean(value = "defaultApi2")
public Docket defaultApi2(){
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo())
.select()
.apis(RequestHandlerSelectors.basePackage("com.liangshou.controller"))
.paths(PathSelectors.any())
.build();
}
/**
* 自定义接口文档信息
*/
private ApiInfo apiInfo(){
return new ApiInfoBuilder()
// 接口文档的标题
.title("Spring AI 实践项目")
// 接口文档的描述信息
.description("spring-ai-project")
.contact(new Contact("liangshou", "github.com/LiangshouX", "3177065496@qq.com"))
.version("1.0")
.build();
}
}最后写一个简单的 Controller,测试一下,这里就用官网的示例:
@Api(tags = "首页模块")
@RestController
public class IndexController {
@ApiImplicitParam(name = "name",value = "姓名",required = true)
@ApiOperation(value = "向客人问好")
@GetMapping("/sayHi")
public ResponseEntity<String> sayHi(@RequestParam(value = "name")String name){
return ResponseEntity.ok("Hi:"+name);
}
}
打开本地的服务端口,能正常打开即可:
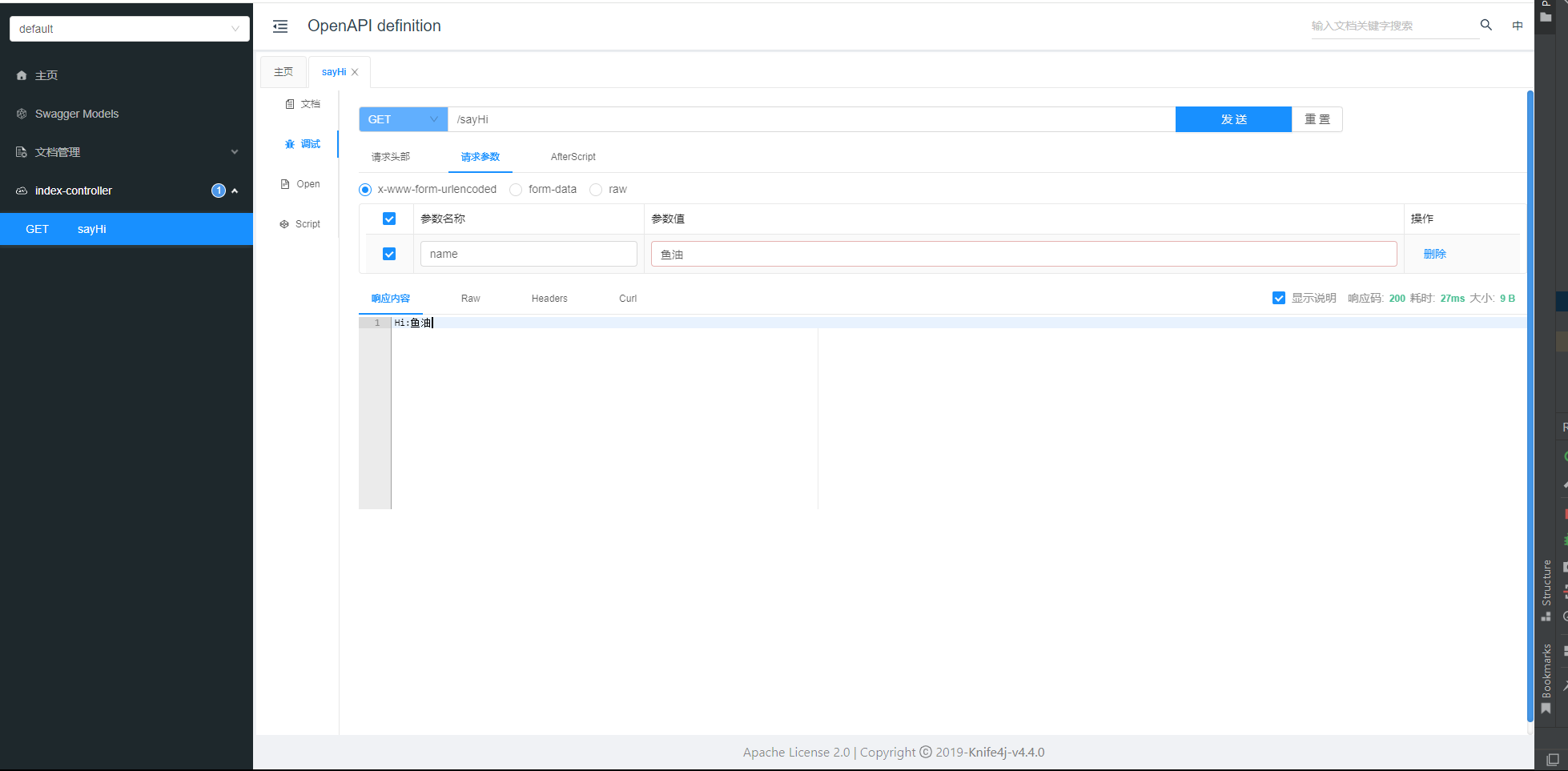
一个简单的对话服务
现在,前期的初始化配置就完成了。接下来写一个简单的与 ChatGPT 对话的服务类。 Spring AI 中与大模型对话需要借助 Chat Completion API,更具体来说需要一个 ChatClient。 而 Spring AI 支持的大模型基本都是提供了相应的 ChatClient 的,只需要实例化就行。
这里先以 ChatGPT 为例。要构建一个 CHatClient 的客户端,我们需要进行一些配置,比如 API key、模型、温度(Temperature)等等。ChatGPT 提供了自动配置和手动配置的方式,之后将依次介绍。首先把依赖先引进来:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>自动配置
自动配置比较简单,在配置文件application.yml中直接写就好。具体的配置选项参考官网的 Chat Properties:OpenAI Chat :: Spring AI Reference 先配置最简单的选项:
spring:
ai:
openai:
api-key: # 填写相应的 API key
chat:
options:
model: gpt-3.5-turbo
temperature: 0.7单次对话
这些配置基本就能保证基本的对话了。接下来写一个基础的对话服务类,先实现简单的单次对话:
/**
* 提供与 ChatGPT 对话的服务
*/
@Service
public class GptCompletionService {
// 这是 Spring AI框架下调用 ChatGPT 对话自带的对话客户端
private final OpenAiChatClient chatClient;
// 多轮对话用的,见后文
private final List<Message> messageList = new ArrayList<>();
private final Logger logger = LoggerFactory.getLogger(getClass());
public GptCompletionService(OpenAiChatClient chatClient) {
this.chatClient = chatClient;
}
/**
* 单次对话的方法
* @param message 发送给大模型的消息
*/
public Map<String, String> singleCompletion (String message) {
Message messageObj = new UserMessage(message);
Prompt prompt = new Prompt(messageObj);
String response = chatClient.call(prompt).getResult().getOutput().getContent();
return Map.of(
"AI RESPONSE", response
);
}
}然后编写一个 Controller:
@RestController
@RequestMapping("/api")
@Slf4j
public class GptCompletionController {
private final GptCompletionService completionService;
public GptCompletionController(GptCompletionService completionService) {
this.completionService = completionService;
}
@GetMapping("/gpt/singleCompletion")
public Map<String, String> singleCompletion (@RequestParam(defaultValue = "你会不会唱跳Rap打篮球?") String message) {
return completionService.singleCompletion(message);
}
}在后端接口中测试,可以看到如下的响应输出:
{
"AI RESPONSE": "抱歉,我是一个语言模型AI,没有身体能力,所以无法唱跳Rap打篮球。但是我可以和你一起分享一些关于这些话题的信息或者歌词。有什么问题或者需要帮助的吗?"
}多次对话
然后再尝试多次对话,在 GptCompletionService 中编写多次对话的方法:
/**
* 多轮对话的方法
*/
public Map<String, String> multiCompletion (String message) {
if (messageList.size() >= 10) {
messageList.remove(0);
}
messageList.add(new SystemMessage(message));
Prompt prompt = new Prompt(messageList);
String response = chatClient.call(prompt).getResult().getOutput().getContent();
// 为了更直观,在控制台打印
System.out.println("AI RESPONSE:\t" + response);
return Map.of(
"AI RESPONSE", response
);
}同理编写 Controller,不再赘述,直接看响应输出(他好像急了?强调自己是个文本助手):
ME: 你会不会唱跳Rap打篮球?
AI RESPONSE: 很抱歉,我是一个虚拟助手,没有实体身体,无法唱歌、跳舞、Rap或打篮球。但是我可以为您提供关于这些主题的信息和指导,有任何问题都可以随时问我哦!
ME: 你能不能学习唱跳Rap打篮球?
AI RESPONSE: 抱歉,我是一个文本AI助手,无法唱歌、跳舞、Rap或打篮球。不过,我可以帮你了解关于这些领域的知识和技巧,或者提供一些相关的信息。如果你有任何问题,欢迎向我咨询!
ME: 我问你的第一个问题是什么?
AI RESPONSE: 你问我会不会唱跳Rap打篮球。以上通过call方法实现了一个简单的调用。OpenAiChatClient 内提供的关于调用大模型接口的除了 call方法,还有一种 stream方法,返回值是 Flux<ChatResponse>类型,属于响应式编程的用法。先看一下他的定义:
@Override
public Flux<ChatResponse> stream(Prompt prompt) {
ChatCompletionRequest request = createRequest(prompt, true);
return this.retryTemplate.execute(ctx -> {
Flux<OpenAiApi.ChatCompletionChunk> completionChunks = this.openAiApi.chatCompletionStream(request);
// For chunked responses, only the first chunk contains the choice role.
// The rest of the chunks with same ID share the same role.
ConcurrentHashMap<String, String> roleMap = new ConcurrentHashMap<>();
// Convert the ChatCompletionChunk into a ChatCompletion to be able to reuse
// the function call handling logic.
return completionChunks.map(chunk -> chunkToChatCompletion(chunk)).map(chatCompletion -> {
try {
chatCompletion = handleFunctionCallOrReturn(request, ResponseEntity.of(Optional.of(chatCompletion)))
.getBody();
@SuppressWarnings("null")
String id = chatCompletion.id();
List<Generation> generations = chatCompletion.choices().stream().map(choice -> {
if (choice.message().role() != null) {
roleMap.putIfAbsent(id, choice.message().role().name());
}
String finish = (choice.finishReason() != null ? choice.finishReason().name() : "");
var generation = new Generation(choice.message().content(),
Map.of("id", id, "role", roleMap.get(id), "finishReason", finish));
if (choice.finishReason() != null) {
generation = generation.withGenerationMetadata(
ChatGenerationMetadata.from(choice.finishReason().name(), null));
}
return generation;
}).toList();
return new ChatResponse(generations);
}
catch (Exception e) {
logger.error("Error processing chat completion", e);
return new ChatResponse(List.of());
}
});
});
}好叭,看不太懂😂 调用 stream 方法主要是在响应时间比较久之类的情况,比如 Prompt 很长,需要等较长时间之类的。而且它是一点一点生成的,假如我们是要用它做一个自己的 AI 问答助手的话,就比较适合调用这种方式。下面是一个使用方法的示例:
/**
* 流式接口调用的方法
*/
public String streamCompletion (Prompt prompt) {
StringBuilder outputBuilder = new StringBuilder();
chatClient.stream(prompt)
.doOnNext(chatResponse -> {
synchronized (outputBuilder) {
var result = chatResponse.getResult();
// 流式接口调用可能会出现一些 NULL 的情况,要进行判断
if (result != null) {
var output = result.getOutput();
if (output != null) {
String content = output.getContent();
if (content != null) {
outputBuilder.append(content);
}
else {
logger.warn("Content is null in ChatOutput.");
}
}
else {
logger.warn("Output is null in ChatResult.");
}
}
else {
logger.warn("Result is null in ChatResponse.");
}
}
})
.doOnComplete(() -> {
// 流完成后的处理逻辑,此时outputBuilder已经包含了所有内容
logger.info("All responses processed. OutputBuilder content length: {}", outputBuilder.length());
})
.doOnError(error -> {
logger.error("An error occurred: {}", error.getMessage());
})
// 阻塞,直到最后一个生成完成
.blockLast();
logger.info("Stream Completion at {}", Instant.now());
return outputBuilder.toString();
}上面的示例是把线程阻塞掉,直到最后一个响应输出生成完成,然后再前面调用 call方法的地方换成这里定义的streamCompletion,效果是一样的。 PS: 调 stream 方法来获得响应就很灵活,玩法还有很多,等我补一下响应式编程的知识再探索😂。
手动配置
上述的自动配置方法是只需在 application.yml 配置文件中填大模型的配置选项即可。那另外有些场景,比如我们开发了一个 AI 应用提供给用户,需要用户配置自己的 API key、自己选择模型、参数之类的,似乎用业务代码改application.yml不是那么靠谱?Spring AI 提供了手动配置的选项,似乎可以实现上述的需求?元芳你怎么看?
不管了,先干了再说😏
为了避免方法的参数列表过长,先定义一个数据类,用来存放大模型的 ChatOptions,其中的字段根据需要设置:
public record ChatOptionsBean (String chatModel,
Float temperature,
Integer maxTokens,
String stopSeq) {
}然后写一个方法,用来接收 ChatOptionsBean 对象,构建并返回 OpenAiChatOptions 对象:
public OpenAiChatOptions createChatOptions (ChatOptionsBean chatOptionsBean) {
try {
return OpenAiChatOptions.builder()
.withModel(chatOptionsBean.chatModel())
.withTemperature(chatOptionsBean.temperature())
.withMaxTokens(chatOptionsBean.maxTokens())
.build();
} catch (Exception e) {
logger.error("参数配置出错!", e);
return null;
}
}然后再来一个构建 对话客户端的方法:
public void createChatClient (OpenAiApi api, OpenAiChatOptions chatOptions) {
try {
this.chatClient = new OpenAiChatClient(api, chatOptions);
logger.info("ChatClient已被成功篡改");
} catch (Exception e) {
logger.error("构建ChatClient失败", e);
}
}最后来编写一个 Controller:
@GetMapping("/gpt/manual")
public void manualConfigDemo (@RequestParam String api,
@RequestParam(defaultValue = "gpt-4") String chatModel,
@RequestParam(defaultValue = "0.7") String temperature,
@RequestParam(defaultValue = "10") String maxTokens) {
OpenAiApi openAiApi = new OpenAiApi(api);
Float temp = Float.parseFloat(temperature);
Integer maxToken = Integer.parseInt(maxTokens);
ChatOptionsBean optionsBean = new ChatOptionsBean(chatModel, temp, maxToken);
OpenAiChatOptions chatOptions = completionService.createChatOptions(optionsBean);
completionService.createChatClient(openAiApi, chatOptions);
}然后看调用后的日志:
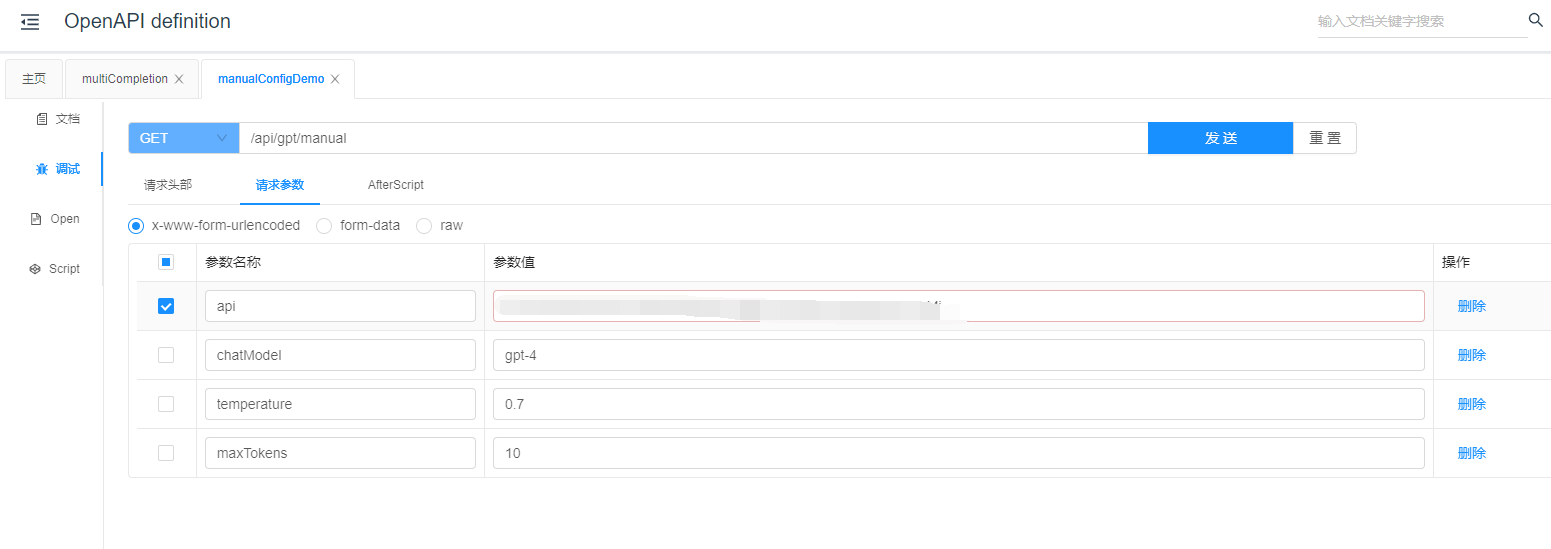

小结
本文通过一个简单的示例演示了使用 Spring AI 调用 ChatGPT 接口,实现了快速搭建一个 Spring AI 应用,包括 call 方法和 stream 方法的调用方式、单次调用和多轮对话的方法等,演示了 OpenAICHatClient 的自动配置与手动配置。更进一步的开发实验,随缘更新。














 528
528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









