







插入数据优化
1. insert优化
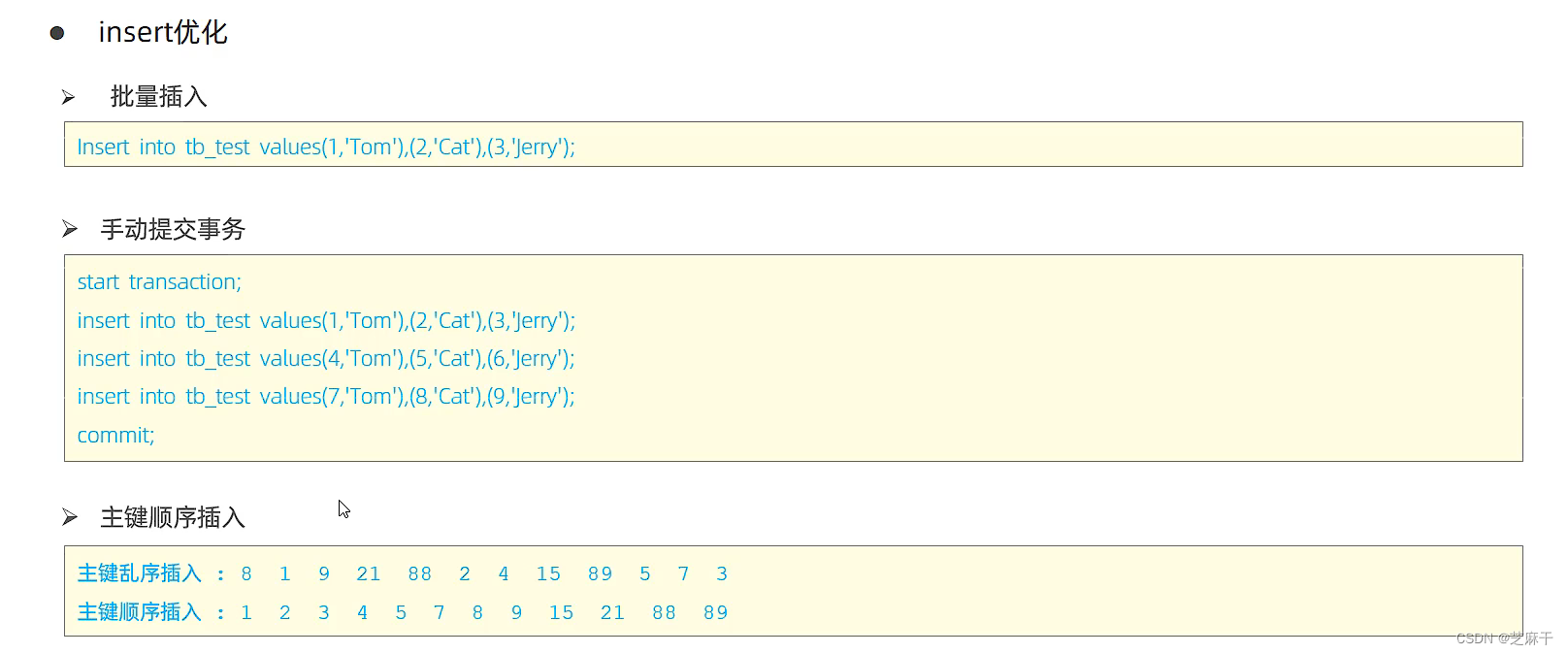
2. 大批量插入数据
如果一次性要插入大批量的数据,使用insert性能较低,此时可以使用数据库的load指令进行插入。
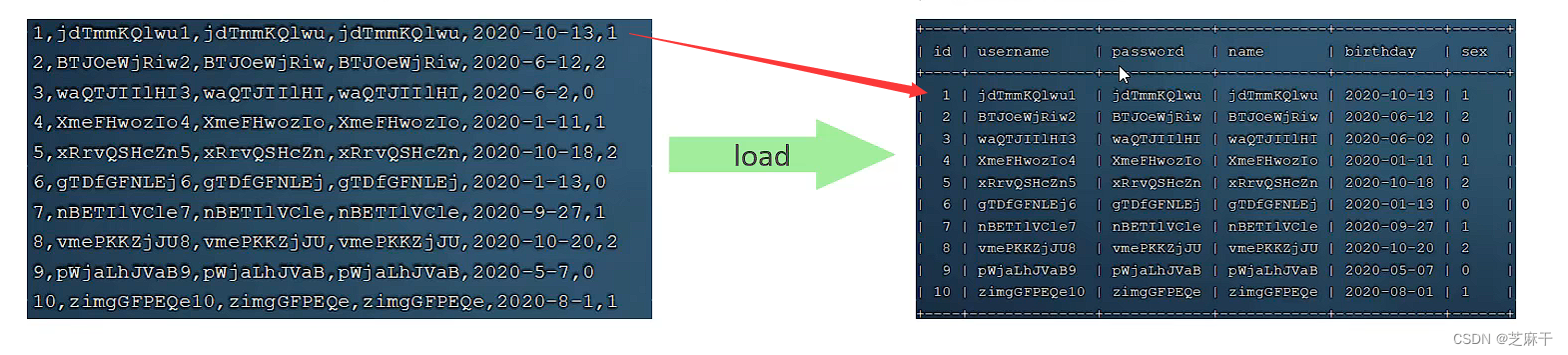
三步操作
1. 客户端连接服务端时,加上参数 --local-infile
2. 设置全局参数 local_infile为1,开启本地加载文件导入数据的开关
3. 执行load指令将准备好的数据,加载到表结构中
load data local infile '文件路径' into table `表名` fields terminated by ',' lines terminated by '\n'
主键优化
主键设计原则
1. 满足业务需求的情况下,尽量降低主键的长度
2. 插入数据时,主键顺序插入,尽量选择自增主键
3. 尽量不要使用UUID做主键或者是其他自然主键,如身份证号
4. 业务操作时,尽量避免对主键的修改
order by 优化
1. Using filesort :通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫FileSort 排序。
2. Using index :通过有序索引顺序扫描直接返回有序数据,这种情况即为using index,不需要额外排序,操作效率高。
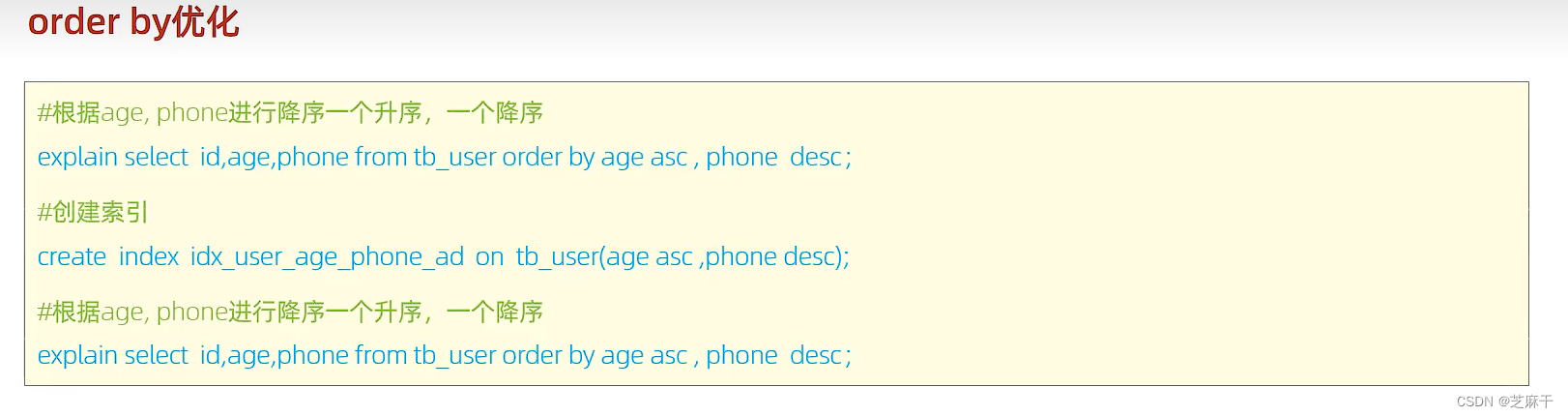
没有创建索引是,走的都是Using filesort,创建索引后,如果都是升序排列或者都是降序排列,会走Using index,此时性能较高。

如果没有同时进行升序排序或者降序排序,而是一个升序一个降序,仍然回事Using filesort ,此时需要建立准确的排序索引才会变回Using index
索引列表里,该列就是显示的排序方式,此时依照该索引的排序方式进行order by 排序,性能更高。
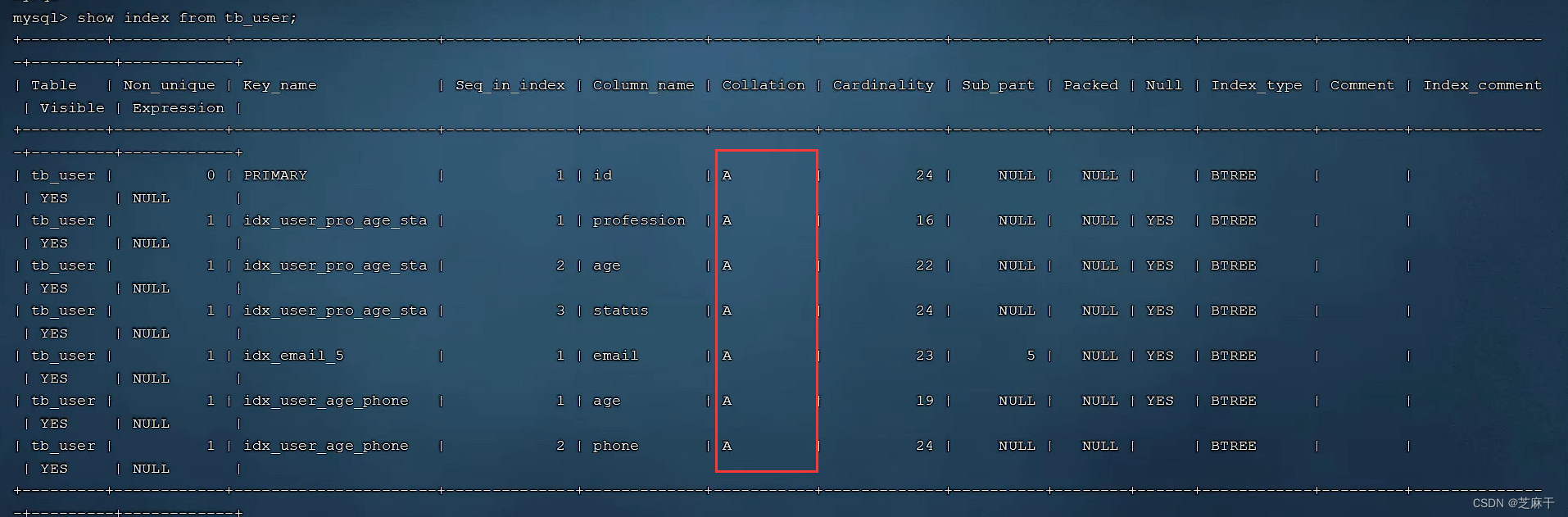
总结,order优化主要有以下四点:

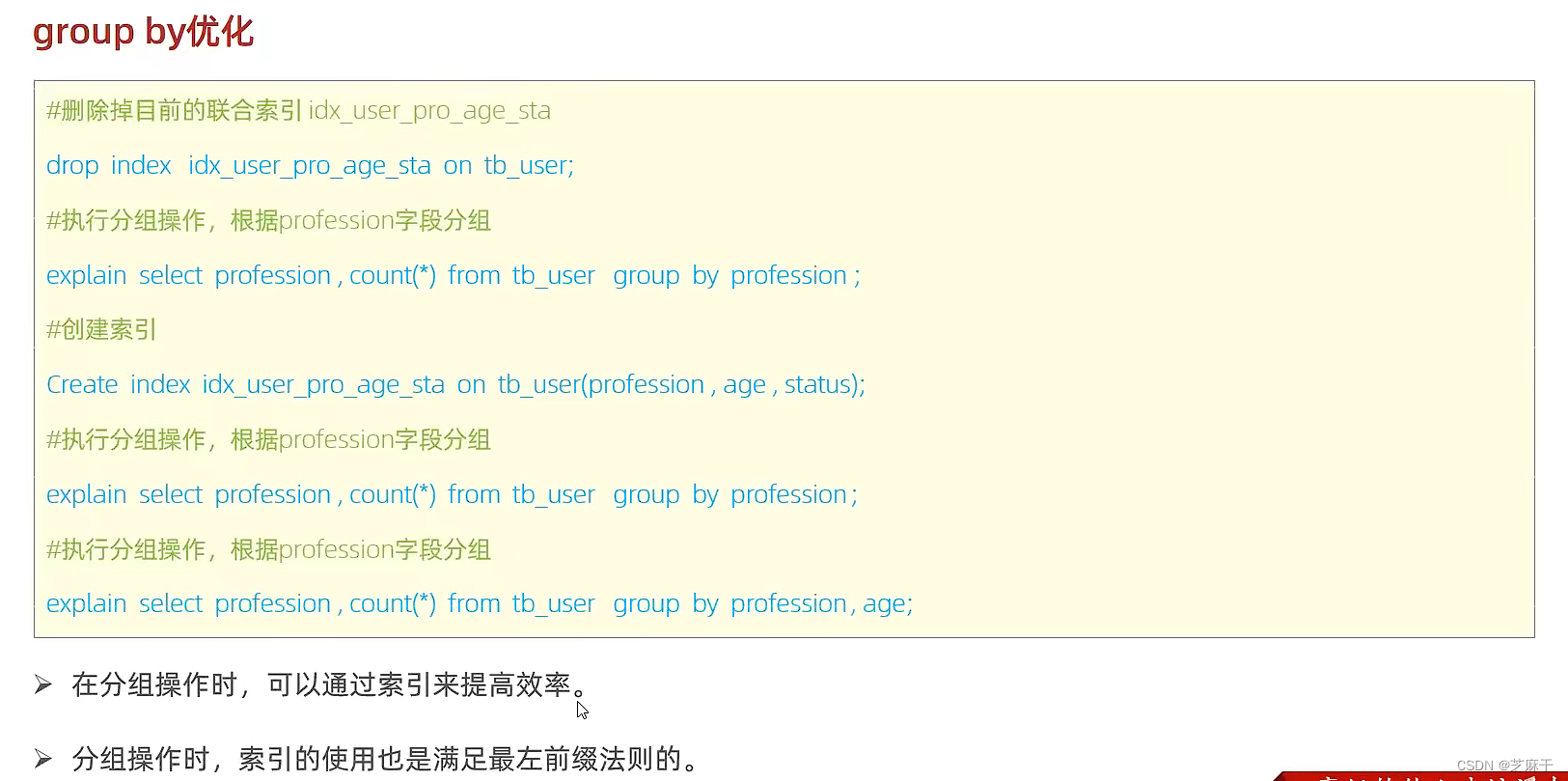
group by优化
主要就是要创建分组字段的索引,依照最左前缀法则
 limit优化
limit优化
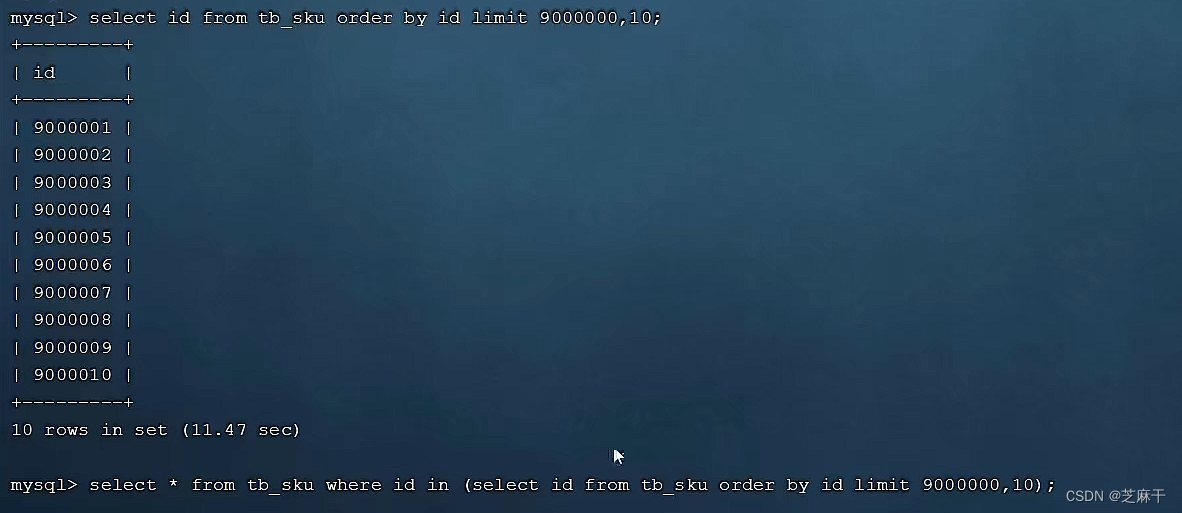
一个常见又非常头疼的问题就是limit 2000000,10 ,此时需要MySQL排序前2000010记录,仅仅返回 2000000 - 2000010这10条纪录,查询排序的代价非常之大。
此时可以这样进行操作,先根据主键字段进行手动排序,并拿到id值(这次前面的排序走了索引,速度会快很多),在根据id查询对应的十条记录。
count 优化

 按照效率的话 count(字段)< count(主键)< count(1)= count(*)
按照效率的话 count(字段)< count(主键)< count(1)= count(*)
update 优化
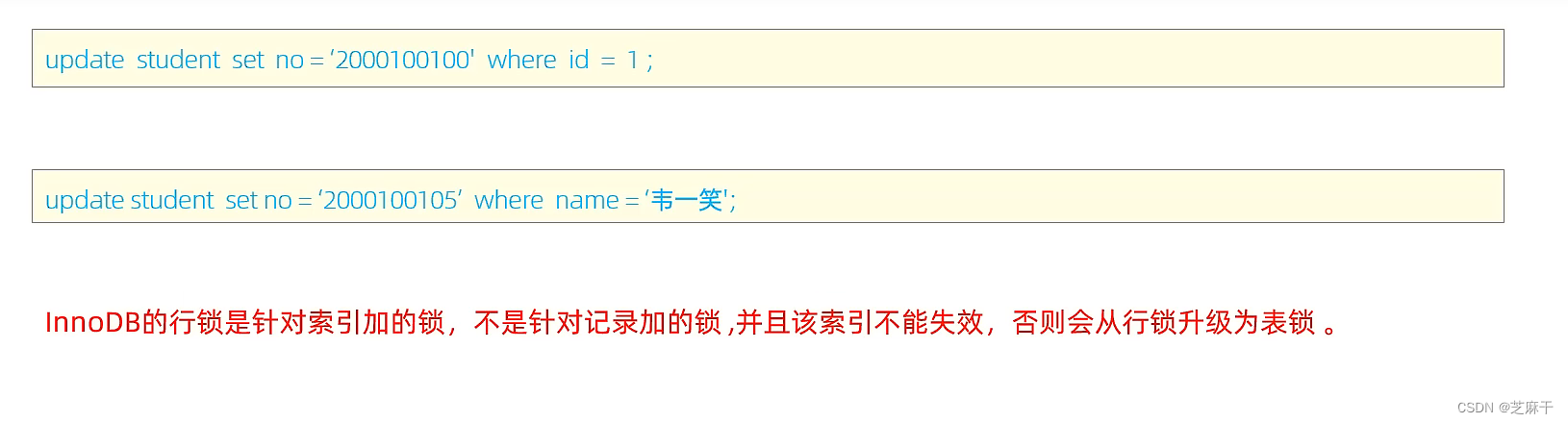
执行update的话,需要注意的坑就是where条件要用带有索引的字段,否则行级锁会升级成表锁,并发性能大大降低。
















 42万+
42万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











