






1. 数据的插入(INSERT)
使用INSERT语句可以向表中插入数据(行),原则上,INSERT语句每次执行一行数据的插入。
1.1 准备工作
首先创建一个名为base_category0的表
-- 建表语句
DROP TABLE IF EXISTS `base_category0`;
CREATE TABLE `base_category0` (
`id` bigint(20) NOT NULL ,
`name` varchar(10) NOT NULL ,
PRIMARY KEY (`id`)
)
该语句只是建立新表,并未插入数据。
1.2 INSERT语句的基本语法
-- 基本语法
INSERT INTO <表名> (列1,列2,列3,……) VALUES (值1,值2,值3,……);
– (列1,列2,列3,……) 被称为列清单; (值1,值2,值3,……)被称为值清单
向表中base_category0中插入一行数据:
INSERT INTO base_category0 ( id , name ) VALUES (1,"图书、音像、电子书刊");

图1 插入结果
插入的列名与值数量与数据类型都应该对应,否则会插入失败。
此外,原则上执行一次INSERT语句会插入一行数据,因此,插入多行时通常需要循环执行相应次数的INSERT语句
1.3 多行INSERT
原则上运行一次INSERT语句只能插入一条数据,所以插入多条数据时语句如下:
INSERT INTO base_category0 (id , name) VALUES (1,"图书、音像、电子书刊");
INSERT INTO base_category0 (id , name) VALUES (2,"手机");
INSERT INTO base_category0 (id , name) VALUES (3,"家用电器");
INSERT INTO base_category0 (id , name) VALUES (4,"数码");
INSERT INTO base_category0 (id , name) VALUES (5,"家居家装");
为了减少语句的书写数量,可以将代码写成如下形式:
INSERT INTO base_category0 (id , name) VALUES (1,"图书、音像、电子书刊"),(2,"手机"),(3,"家用电器"),(4,"数码"),(5,"家居家装");
但是要注意:
1.要注意语句书写内容和插入的顺序是否正确,如果出错很难找到错误所在
2.多行INSERT的语法并不适用于所有RDBMS(不适用于Oracle)
1.4 列清单的省略
对一张表进行全列INSERT(插入所有列)时,可以省略表名后的列清单。
INSERT INTO base_category0 (id , name) VALUES (1,"图书、音像、电子书刊"),(2,"手机"),(3,"家用电器"),(4,"数码"),(5,"家居家装");
该语句可以改写成
INSERT INTO base_category0 VALUES (1,"图书、音像、电子书刊"),(2,"手机"),(3,"家用电器"),(4,"数码"),(5,"家居家装");
1.5 插入NULL
当想使用INSERT给某一列赋NULL值时,可以直接在值清单中写入NULL,但需要注意该列一定不能设置NOT NULL约束,否则会报错,插入失败(仅仅是当前希望通过INSERT插入的数据无法正常插入到表中,但之前已经插入的数据不会被破坏)。
1.6 插入默认值
我们还可以向表中插入默认值(初始值),可以通过在创建表的CREATE TABLE语句中设置DEFAULT约束来设定默认值。
DROP TABLE IF EXISTS `base_category0`;
CREATE TABLE `base_category0` (
`id` bigint(20) NOT NULL ,
`name` varchar(10) NOT NULL DEFAULT 0,
PRIMARY KEY (`id`)
);
如果在创建表的同时设定了默认值,就可以在INSERT语句中自动为列赋值了,默认值的使用方法通常有显式和隐式两种。
1.6.1 通过显示方法插入默认值
在VALUE子句中指定DEFAULT关键字。
INSERT INTO base_category0 (id , name) VALUES (1 , DEFAULT);
1.6.2 通过隐式方法插入默认值
在列清单与值清单中省略设定了默认值的列。
INSERT INTO base_category0 (id) VALUES (1);
-- 省略了列清单中的name与值清单中的对应值
通常建议使用显式方法赋默认值,因为这样可以一目了然地知道哪一列使用了默认值
如果省略了没有设定默认值的列,那么该列的值就会被设为NULL,如果该列被设置了NOT NULL约束,那么该INSERT语句就会出错。
1.7 从其他表复制数据
插入数据的方法除了使用VALUES子句指定具体数据之外,还可以从其他表中复制数据。
在base_category1中有如下数据:
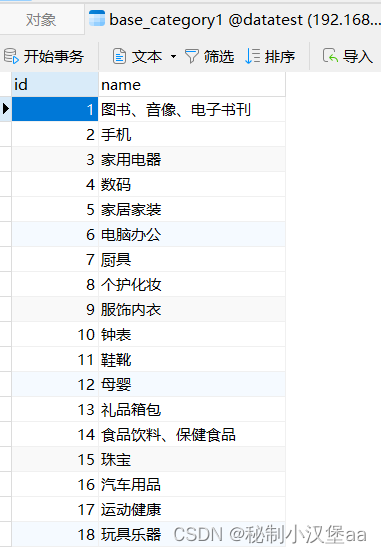
图2 base_category1表数据
INSERT INTO base_category0 (id ,`name`)
SELECT *
FROM base_category1;

图3 运行成功结果
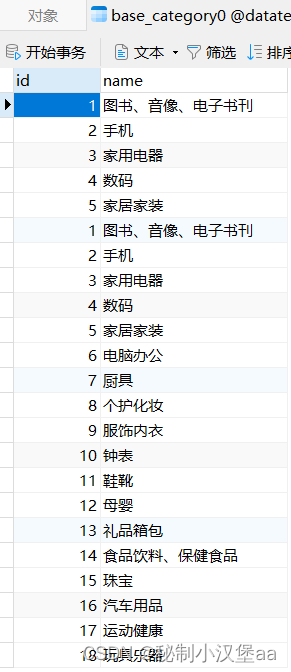
图4 插入内容展示
base_category1表中数据不会改变,所以该功能可以在需要进行数据备份时使用。
从其他表中复制数据使用的SELECT语句也可以使用WHERE条件以子句及GROUP BY子句等任何SQL语法,但使用ORDER BY子句不会产生任何效果。
2. 数据的删除
数据的删除方法大体可以分为以下三种
1.DROP TABLE语句可以将表完全删除
2.TRUNCATE TABLE语句可以将表中数据清空但保留表结构
3.DELETE语句可以删除表中数据
2.1 DROP TABLE语句
DROP TABLE语句是完全删除整张表,因此删除之后再想插入数据就必须使用CREATE TABLE语句重新创建一张表。
DROP TABLE base_category0;
2.2 TRUNCATE TABLE语句
TRUNCATE TABLE语句是将表中数据清空,仅仅删除表的所有记录,表的结构、索引、触发器、约束等将被保留,后续仍然可以使用该表。
TRUNCATE TABLE base_category0;
2.3 DELETE语句
2.3.1 基本语法:
-- 保留数据表,仅删除全部数据行
DELETE FROM base_category0;
如果语句中忘了写FROM,或者写了多余的列名都会出错。
DELETE删除的对象是行,并非列或者表,所以"DELETE * FROM <表名>;" 这种写法也是错误的。
2.3.2 指定删除对象的delete语句(搜索型DELETE)
想要删除部分数据行时,使用DELETE语句可以像SELECT一样,利用WHERE语句指定删除条件(搜索型DELETE)。
-- 基本语法
DELETE FROM <表名>
WHERE <条件> ;
删除order_info表中所有消费金额在5000以下的用户:
DELETE FROM order_info
WHERE final_total_amount < 5000 ;
与SELECT语句不同的是,DELETE语句不能使用GROUP BY、HAVING和ORDER BY三类子句,只能使用WHERE子句。原因很简单,GORUP BY和HAVING是用于从表中选取数据时用来改变抽取数据形式的,而ORDER BY是用来改变指定取得结果顺序的,因此这三类子句在删除表中数据时起不到什么作用。
注:TRUNCATE不能用于条件筛选删除,只能清空表中数据。
3. 数据的更新(UPDATE)
3.1 UPDATE语句的基本用法
使用INSERT语句向表中插入数据后,需要更改数据时,不需要将之前的数据删除后再重新插入,此时使用UPDATE语句就可以改变表中数据了。
和INSERT语句。DELETE语句一样,UPDATE语句也属于DML语句,通过执行该语句可以改变表中的数据。
-- 基本语法
UPDATE <表名>
SET <列名> = <表达式> ;
例:将activity_info表中的activity_type全部修改成’0518’
UPDATE activity_info
SET activity_type = '0518' ;

图5 修改前

图6 修改后
3.2 指定条件的UPDATE语句(搜索型UPDATE)
更新数据也可以像SELECT语句一样用WHERE子句指定更新对象,这种UPDATE语句被称为搜索型UPDATE。
-- 基本语法
UPDATE <表名>
SET <列名> = <表达式>
WHERE <条件> ;
例:将order_info表中总消费金额小于5000的用户的消费金额变为原来的2倍。
UPDATE order_info
SET final_total_amount = final_total_amount * 2
WHERE final_total_amount < 5000 ;
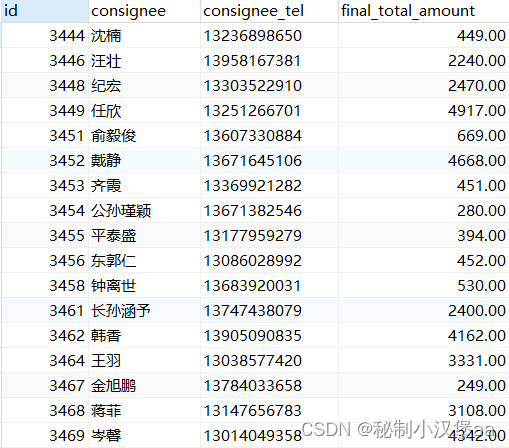
图7 修改前
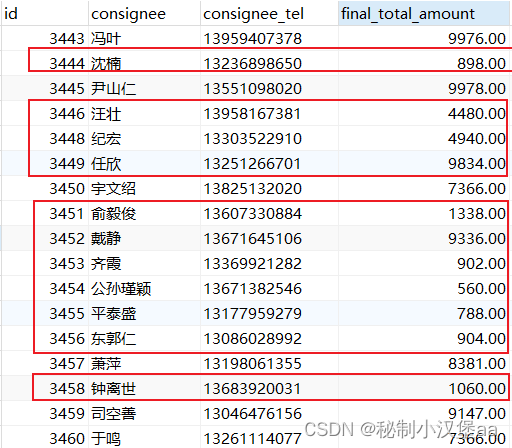
图8 修改后
SET子句中赋值表达式的右边不仅可以是单纯的值,还可以是包含列的表达式
3.3 使用NULL进行更新
使用UPDATE也可以将列更新为NULL(俗称为NULL清空)
例:将order_info表中总消费金额在30000以上的用户消费金额设置为NULL
UPDATE order_info
SET final_total_amount = NULL
WHERE final_total_amount > 30000 ;
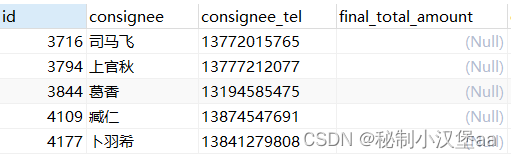
图9 赋空值后结果
只有未设置NOT NULL约束和主键约束的列才可以请空为NULL,否则就会出错。
3.4 多列更新
UPDATE的SET子句支持同时将多个列作为更新对象,如果想将order_info表中总消费金额小于5000的用户的消费金额变为原来的2倍的同时,将这些用户的地址设为空值,此时可以将需求拆分成两个语句执行:
UPDATE order_info
SET final_total_amount = final_total_amount * 2
WHERE final_total_amount < 5000 ;
UPDATE order_info
SET delivery_address = NULL
WHERE final_total_amount < 5000 ;
虽然这样也能正确更新数据,但执行两次语句增加了SQL语句的书写量,同时浪费了资源。其实可以将语句合并成一条语句处理,如:
-- 方法一:使用逗号对列进行分隔排列
UPDATE order_info
SET final_total_amount = final_total_amount * 2 ,
delivery_address = NULL
WHERE final_total_amount < 5000 ;
-- 方法二:将列用()括起来写成清单形式
UPDATE order_info
SET (final_total_amount , delivery_address) = (final_total_amount * 2 , NULL)
WHERE final_total_amount < 5000 ;
实际应用中通常会使用方法一。
当然SET子句中的列还可以是三列或更多。
4.事务
在RDBMS中,事务是对表中数据进行更新的单位,简单来讲,事务就是需要在同一个处理单元中执行的一系列更新处理的集合。
4.1 事务的重要性
现在需要把华为Mate60 Pro的价格上调200元,还需要将运动鞋的价格提高50元,此时只需要使用UPDATE来更新即可,如果只处理了Mate60 Pro的价格而未处理运动鞋的价格,数据就会与想要的结果不一致。
此时就需要将两个物品的价格改动作为一个处理单元去执行,一定要用一个事务来处理。
4.2 创建事务
-- 事务的语法:
事务开始语句;
DML语句1;
DML语句2;
DML语句3;
事务结束语句(COMMIT或者ROLLBACK)
使用事务开始语句和事物结束语句将一系列DML语句(INSERT/UPDATE/DELETE语句)括起来,就实现了一个事务处理。
此时需要特别注意的是事务的开始语句。实际上标准的SQL并没有定义事务的开始语句,而是由各个DBMS自己定义的。
MySQL:START TRANSACTION
SQL Server、PostgreSQL:BEGIN TRANSACTION
-- 以MySQL举例:把华为Mate60 Pro的价格上调200元,还需要将运动鞋的价格提高50元
BEGIN TRANSACTION;
-- 把华为Mate60 Pro的价格上调200元
UPDATE Product
SET sale_price = sale_price + 200
WHERE product_name = "华为Mate60 Pro" ;
-- 将运动鞋的价格提高50元
UPDATE Product
SET sale_price = sale_price + 50
WHERE product_name = "运动鞋" ;
COMMIT;
Oracle和DB2并没有定义特定的开始语句。
4.3 事物的区分方法
其实标准SQL中规定了一种悄悄开始事务处理的方法,上面提到各个DBMS都有各自的事务开始语句,但实际上,几乎所有数据库的事务都无需开始指令。这是因为大部分情况下,事务在数据库连接建立时就已经悄悄开始了,并不需要用户发出明确的事务开始指令。
通常区分各个事务有两种方式:
1.每条SQL语句都是一个事务。(自动提交模式)
2.用户发出commit或rollback指令才算一个事务。(非自动模式)
4.4 结束事务的指令
4.4.1 COMMIT——提交处理
COMMIT是提交事务包含的全部更新处理的结束指令,相当于文件处理中的覆盖保存,一旦提交就无法恢复到事务开始前的状态了。因此在提交之前一定要确认好是否真的需要这些更新。
COMMIT流程是直线进行的:
事务开始语句 → 执行更新语句(DML) → 执行COMMIT
为了防止造成数据无法恢复的严重后果,在业务中一般建议进行数据备份之后再进行更新操作(尤其是在执行DELETE语句的COMMIT时)。
4.4.2 ROLLBACK——取消处理
ROLLBACK是取消事务包含的全部更新处理的结束指令。相当于文件处理中的放弃保存。一旦回滚,数据就会恢复到事务开始前的状态。通常情况下回滚不会像提交那样造成大规模的数据损失。
ROLLBACK流程是掉头回到起点
事务开始语句 → 执行更新语句(DML) → 执行ROLLBACK
结束后的状态和事务开始语句执行前相同。
4.5 ACID特性
DBMS的事务都遵循四种特性,四种特性的英文首字母组合起来即ACID特性。
4.5.1 原子性(Atomicity)
原子性是指在事务结束时,其中所包含的更新处理要么全部执行,要么完全不执行。如之前的例子:把华为Mate60 Pro的价格上调200元,同时将运动鞋的价格提高50元,绝对不可能出现华为Mate60 Pro价格变动但运动鞋价格不变的情况。该事物的结束状态,要么是两者都执行了(COMMIT),要么是两者都未执行(ROLLBACK)。
4.5.2 一致性(Consistency)
一致性又称完整性,指的是事务一旦执行要么回滚要么保存。
例如正常操作的事务满足数据库提前设置的约束,如主键约束与NOT NULL约束等,这些事务会成功执行并保存修改后的数据。
某些不符合这些约束的事务将执行失败并回滚到事务执行之前的状态。
4.5.3 隔离性(Isolation)
隔离性是为了保证事物之间互不干扰的特性。该特性保证了事务之间不会交叉执行,不会嵌套。
此外,在某个事务中进行的更改在该事务结束之前对其他事务而言是不可见的。
因此即便某个事务向表中添加了记录,在没有提交之前,其他事务也是看不到新加的记录的。
4.5.4 持久性(Durability)
持久性又被称为耐久性,指的是事务结束后(不论是提交还是回滚),DBMS能够保证该时间点的数据状态会被保存的特性。即使由于系统故障导致数据丢失,数据库也一定能通过某种手段进行恢复。
如果不能保持持久性,即使是正常提交结束的事务,一旦发生了系统故障,也会导致数据丢失,一切都需要从头再来。
保证持久性的方法根据实现的不同而不同,其中最常见的就是将事务的执行记录保存到硬盘等存储介质中(该执行记录被称为日志)。当发生故障时可以通过日志恢复到故障发生前的状态。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









