










欢迎来到雲闪世界。大型语言模型 (LLM) 无疑席卷了科技行业。它们的迅速崛起得益于来自维基百科、网页、书籍、大量研究论文以及我们喜爱的社交媒体平台的用户内容的大量数据。数据和计算密集型模型一直在狂热地整合来自音频和视频库的多模态数据,并且数月来一直使用数万个Nvidia GPU 来训练最先进的 (SOTA) 模型。所有这些都让我们怀疑这种指数级增长能否持续。
希望得到专家们的一些建议,但让我们在这里仅探讨其中的一些内容。
- 成本和可扩展性:大型模型的训练和服务成本可能高达数千万美元,这成为日常应用采用该模型的障碍。
- 训练数据饱和:公开可用的数据集很快就会耗尽,可能需要依赖缓慢生成的用户内容。只有拥有稳定新内容来源的公司和机构才能实现改进。
- 幻觉:生成虚假和未经证实的信息的模型将对用户产生威慑作用,因为用户在将其用于敏感应用程序之前会期望得到权威来源的验证。
- 探索未知领域:现在的应用范围已经超出了其最初的意图。例如,法学硕士在游戏、科学发现和气候建模方面表现出了强大的能力。我们需要新的方法来解决这些复杂的情况。
在我们开始过于担心未来之前,让我们先来看看人工智能研究人员是如何不知疲倦地研究如何确保持续进步的。混合专家 (MoE) 和混合代理 (MoA) 创新表明,希望就在眼前。
专家混合技术于 2017 年首次推出,该技术表明,多个专家和一个可以挑选稀疏专家集的门控网络可以产生显著改善的结果,同时降低计算成本。门控决策允许关闭网络的大部分部分,从而实现条件计算,而专业化可以提高语言建模和机器翻译任务的性能。
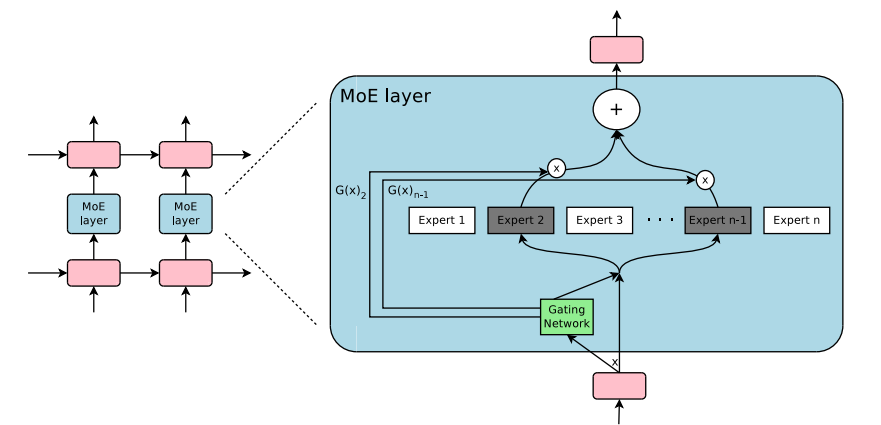
上图显示了混合专家层被纳入循环神经网络。门控层只激活两个专家来完成任务,然后合并他们的输出。
虽然这已在选定的基准上得到证明,但条件计算开辟了一条途径,可以在不依赖不断增长的模型规模的情况下实现持续改进。
受 MOE 的启发,混合代理技术利用多个 LLM 来改善结果。问题通过多个 LLM(即代理)进行路由,这些代理在每个阶段都会增强结果,作者已经证明,与较大的 SOTA 模型相比,较小的模型可以产生更好的结果。
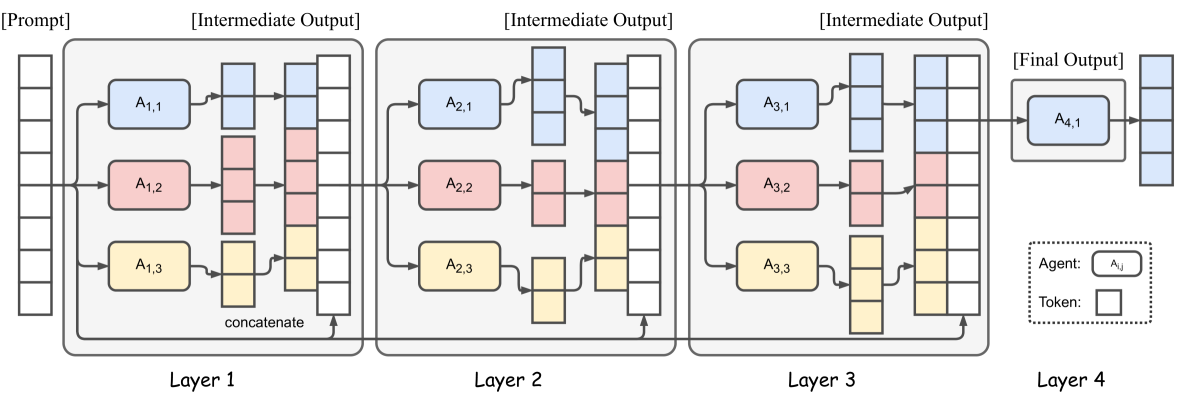
该图显示了 4 个混合代理层,每层有 3 个代理。为每层选择合适的 LLM 对于确保适当的协作和产生高质量的响应非常重要。
MOA 依赖于这样一个事实:LLM 协作可以产生更好的输出,因为它们可以组合来自其他模型的响应。LLM 的角色分为生成不同输出的提议者和可以组合它们以产生高质量响应的聚合器。多阶段方法可能会增加首次令牌时间 (TTFT),因此需要开发缓解方法以使其适用于广泛的应用。
MOE 和 MOA 具有相似的根本要素,但行为方式不同。MOE 的理念是挑选一组专家来完成一项工作,而门控网络的任务是挑选合适的专家。MOA 的理念是让团队在之前团队的工作基础上继续发展,并在每个阶段改进成果。
MOE 和 MOA 的创新开辟了一条创新之路,其中专门的组件或模型的组合、协作和交换信息可以继续提供更好的结果,即使模型参数和训练数据集的线性缩放不再简单。
虽然我们只有事后才知道法学硕士的创新是否能持续下去,但我一直在关注该领域的研究以寻求见解。看到大学和研究机构的成果,我对接下来的发展非常乐观。我确实觉得我们只是在为即将改变我们生活的新功能和应用程序的冲击做准备。我们不知道它们是什么,但我们可以相当肯定,未来的日子一定会让我们感到惊讶。
“我们倾向于高估一项技术的短期效应,而低估其长期效应。”——阿玛拉定律
感谢关注雲闪世界(亚马逊云AWS和谷歌云GCP协助)
订阅频道(https://t.me/awsgoogvps_Host)
TG交流群(t.me/awsgoogvpsHost)















 1028
1028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









