






先声明:此爬虫项目纯属娱乐,爬虫水很深,切勿随便爬取网站信息!!!
闲来无事回看了一下之前自己的一个爬虫小demo,是爬取斗鱼主播的直播数据的,包括id人数封面等,写个小教程教大家玩一下这个爬虫。
先介绍一下,后面会出现一些东西你可能不知道是啥,我不是爬虫专业人士,简单说一下我个人的一些理解,有错见谅,不想看的也可以到分割线下面直接实操。
XHR:一种浏览器内置的 API,用于在不重新加载整个页面的情况下与服务器交换数据,也就是向服务器发出请求,然后服务器回复,你翻页刷新网页的时候,需要加载的新信息就是一个请求和回复的过程。
URL:指该 HTTP 请求的完整 URL 地址,显示了向服务器发送请求的目标链接。通过这个 URL 来进行数据抓取。
requests库:通过里面的GET请求,就能访问网页,获得响应。使用 里面的urlretrieve 函数还可以将封面图片下载到本地
json:一种比较通用的数据流格式。可以简单理解为它就是一个表格,第一列是姓名第二列是班级第三列是学号类似这样。只不过是用字符表示的而已,代码上也可以理解为一个多维数组,直接用中括号访问即可
-------------------------------------------------分割线---------------------------------------------------------
1.首先需要了解网页的基本布局,我们进入斗鱼直播网页,找一个你喜欢的板块。
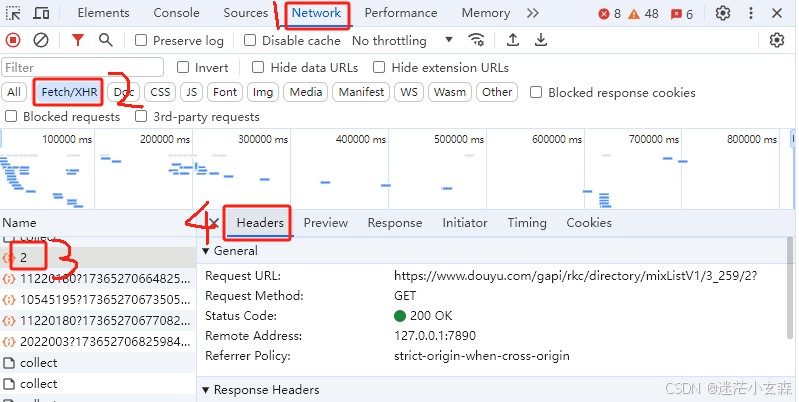
2.按F12进入调试,最上面那行选择Network,然后第四行筛选Fetch/XHR。
3.保持F12不要关闭,在斗鱼界面滚轮动一动,或者去到你喜欢板块的第二页,目的是发出请求request,这样子才能爬到他返回的信息,多点点,直到你在开发者界面(也就是你按F12右侧弹出来的那个东西)左边的name那栏看到出现了“2”这一项。
4.点击这个“2”,选中它之后看右边的preview,在下面的代码代码中依次点击data、rl,然后就能看见所有主播的信息了,我们先随机选择一位主播查看它的具体信息,通过与展示页的对比,我们发现nn对应的是主播名字,ol对应的是在线人数,rid对应的是房间id,rs1对应封面,这样就找到了我们要找的信息的所在位置。
5.然后我们需要地址抓包,点击header里面的general,复制URL链接,这样就找完了网页上我们需要的信息了。
打开你的pycharm,复制下面代码运行。这里有几点要说明的:
1.确保你的python版本在3.7以上,urllib3 和 OpenSSL 的版本依赖关系要是有问题还是挺麻烦的,要不你就安装新版本的python,要不就降级urllib3 版本。(可以用conda虚拟环境,本人conda python 3.9实测没问题)
2.安装好代码需要的库(其实就只有requests),终端pip install一下就行,记得用镜像源,另外安装时记得把你vpn关了,我经常忘关然后安装失败,甚至还被清华源屏蔽了一段时间。
3.确保你的项目同级目录下有douyu.txt和“douyu”文件夹这两个东西,没有就自己新建,当然你也可以换成别的名字,相应的更改一下下面的代码就行。
import requests
from urllib import request
#下面的url可换成你想爬取网页的url,获取方法见上
url="https://www.douyu.com/gapi/rkc/directory/mixList/0_0/2"
mjson = requests.get(url).json()
#print(mjson["data"]["rl"])
# 提取主播名字和封面
for i in mjson["data"]["rl"]:
print(i["nn"], i["rs1"])
request.urlretrieve(i["rs1"],"douyu/"+i["nn"]+".jpg") #记得新建douyu文件夹
mfile = open("douyu.txt", "w", encoding = "utf-8") #记得新建douyu.txt
split_str = "+++"
mfile.write("主播名字"+split_str+"在线人数"+split_str+"房间id"+split_str+"封面\n")
mcount = 1
for i in mjson["data"]["rl"]:
print(i["nn"]+split_str+str(i["ol"])+split_str+str(i["rid"])+split_str+i["rs1"])
print(f"已写入{mcount}行数据")
mcount += 1
mfile.close()
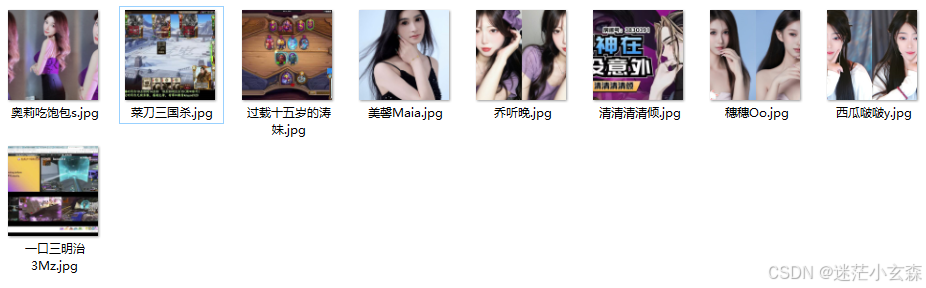
右键运行即可,爬取过程还是需要点时间的,我这里就跑了几个试一试,就不跑完了

文章对你有帮助的话,动动小手给我点个赞,谢谢啦!


















 1029
1029

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









