






期刊:
软件学报 2023年八月 链接:基于模型后门的联邦学习水印![]() https://jos.org.cn/jos/article/abstract/Lp009
https://jos.org.cn/jos/article/abstract/Lp009
提出背景:
据IDC统计,2020年全球产生了64.2ZB的数据,这些海量的数据赋能深度学习模型能极大的提升智能化的程度,但是由于个人数据高度敏感,将本地数据毫无保留的发送给中心服务器进行模型训练会增大隐私泄露的风险,因此提出了联邦学习的训练框架。
尽管提出的联邦学习框架能够一定程度的保护用户的数据隐私,但是难以抵制自私用户恶意出售自己的模型等情况。因此为了能够更好的保护数据隐私,设计有效的联邦学习模型知识产权保护的方法,通过验证用户对于联邦学习模型的所有权来维护数据安全。
本文贡献:
·设计基于模型后门的联邦学习水印方案(FLWB):通过用户本地训练私有后门模型,让本地模型在保证主任务的高精度下而在后门触发集的训练任务上出现误分类,使得服务器端在聚合过程中能够将各用户的私有后门水印融入到全局模型之中,实现私有水印到全局模型的映射。
·设计分步训练方法:缓解各个本地模型水印之间的冲突。
·对FLWB方案抵御攻击的安全性进行理论证明:验证FLWB方案的可行性以及分步训练的有效性。
前序知识准备:
联邦语义描述 :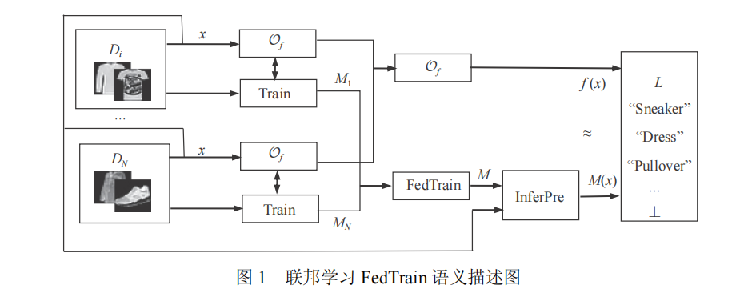
图一针对深度学习中的问题,将联邦学习分为两个步骤:联合训练过程(FedTrain)和推理预测过程(InferPre)。
FedTrain步骤:本地用户训练私有数据集,使得聚合模型拟合的函数f’具有和真实分类函数f相似的能力,并且允许inferPre能够在未训练的数据集中分类正确。
InferPre步骤:能够利用用户本地未进行训练的数据集进行全局模型M的输出。
联邦后门描述:
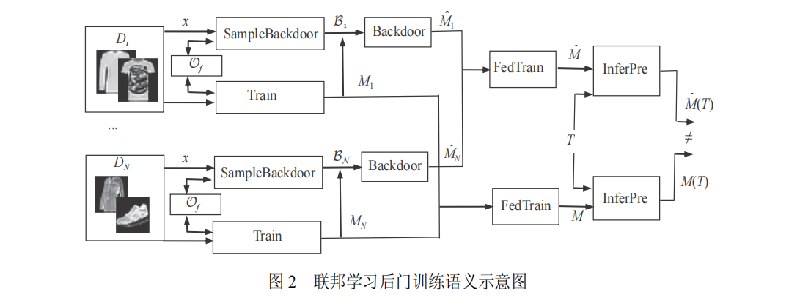
SampleBackdoor是触发集生成算法。对于一个后门B,后门算法Backdoor(O,B,M)是一个概率多项式时间算法,能够在模型输入时输出一个在触发集上有高概率错误分类的模型M.若M能够对触发集T中以高概率输出指定标签,而在正常样本集D\T中也表现良好,则M称为被后门任务所标记,即:
简单来说就是包含触发器的样本在利用预测机预测的时候会被分类为攻击者指定的类型,而正常样本进行预测时,会预测正确分类。即保证正常样本的正确分类,同时让包含后门的错误分类。
方案设计:
方案划分:
本文方案主要分为三个模块:联邦密钥生成算法:给定安全参数p,用户i输出密钥对(mk,vk)并且密钥对私有存储;联邦标记算法:用户i给定输入模型M’和标记密钥mk,输出后门水印模型M;验证算法:对输入的密钥对集(MK,VK)中的每一组用户mk,vk进行验证,输出的比特信息中1表示含有水印,0表示不包含水印。
方案整体流程:

利用预言机训练数据得到模型,调用联邦密钥生成算法生成各个用户的密钥对。各地用户利用自己的模型和密钥训练本地模型,得到上述输出,上传给中心服务器。
方案实现:

Bi表示的是后门数据集(触发集数据、后门标签),SampleBackdoor是触发集生成算法 承诺方案是允许发送方(sender,S)将一个秘密x锁定,并交给接收者(receiver,R),R在没有S的条件下是没办法打开秘密x的 Com(x,r)表示给定x属于S和比特串r,输出比特串c,用来生成验证密钥。
各个用户利用后门算法SampleBackdoor生成自己独有的后门模式,并且随机生成比特串和承诺Com,保存下用户的标记密钥和验证密钥。

用户收到全局模型M,利用自己的后门以及全局模型训练得到自己的本地模型,并且重复训练直到本地模型训练完成,之后上传给中心服务器。
 Open与前面的Com相互绑定,属于承诺方案,Open(ci,Ti,ri)表示给定触发集数据以及用户随机生成的比特串ri和生成的承诺ci,输出0或者1 (表示是否打开秘密) 调用InferPre,利用本地的全局模型M’进行训练输出ti与标签数据Ti进行比对验证。
Open与前面的Com相互绑定,属于承诺方案,Open(ci,Ti,ri)表示给定触发集数据以及用户随机生成的比特串ri和生成的承诺ci,输出0或者1 (表示是否打开秘密) 调用InferPre,利用本地的全局模型M’进行训练输出ti与标签数据Ti进行比对验证。
这种方式巧妙的利用后门攻击对于特定样本的错误分类,对于正常样本无影响的特性,将本地用户各自的后门模式设计为水印进行授权,保证了全局模型聚合过程中的安全。
结果分析:
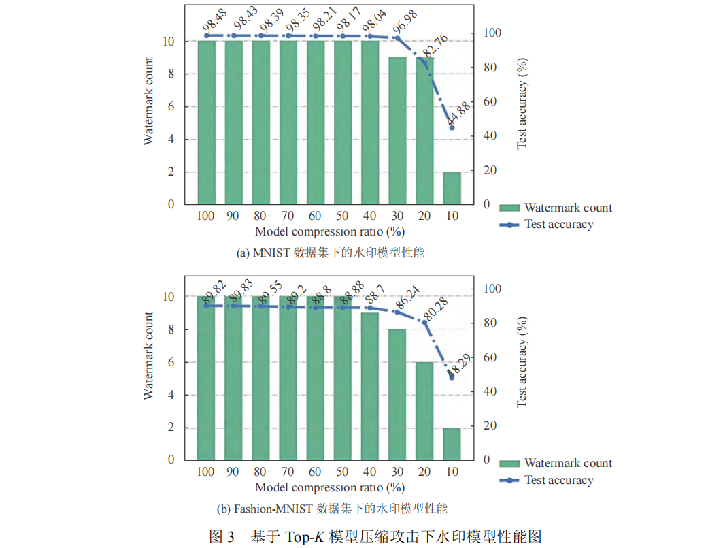
为了验证鲁棒性,在已经嵌入水印的模型中尝试去除水印,查看模型性能的变化。 这里测试利用TOP-K的参数选择方法(选择前K个最好的)进行,数据集为FL-baseline-MNIST和FL-baseline-fMNIST。
通过图像能够看到当模型从100%(无压缩)到30%(高压缩),准确率基本维持稳定,当压缩到10%则明显下降,并且嵌入的谁饮水量也只能达到2个。整体来看模型压缩率对水印嵌入的成功影响较小,但对模型的测试准确率有显著影响,表明在设计水印嵌入策略时需要权衡模型压缩与性能保持。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









