







常见的序列化协议以及Kryo自制序列化器
1. 序列化与反序列化
如果我们需要持久化 Java 对象比如将 Java 对象保存在文件中,或者在网络传输 Java 对象,这些场景都需要用到序列化。
- 序列化: 将数据结构或对象转换成二进制字节流的过程
- 反序列化:将在序列化过程中所生成的二进制字节流转换成数据结构或者对象的过程
2. 常见序列化协议有哪些?
JDK 自带的序列化方式一般不会用 ,因为序列化效率低并且存在安全问题。比较常用的序列化协议有 Hessian、Kryo、Protobuf、ProtoStuff,这些都是基于二进制的序列化协议。
像 JSON 和 XML 这种属于文本类序列化方式。虽然可读性比较好,但是性能较差,一般不会选择。
2.1 JDK 自带的序列化方式
JDK 自带的序列化,只需实现 java.io.Serializable接口即可
@AllArgsConstructor
@NoArgsConstructor
@Getter
@Builder
@ToStringpublic
class RpcRequest implements Serializable {
private static final long serialVersionUID = 1905122041950251207L;
private String requestId;
private String interfaceName;
private String methodName;
private Object[] parameters;
private Class<?>[] paramTypes;
private RpcMessageTypeEnum rpcMessageTypeEnum;
}
serialVersionUID 有什么作用?
序列化号 serialVersionUID 属于版本控制的作用。反序列化时,会检查 serialVersionUID 是否和当前类的 serialVersionUID 一致。如果 serialVersionUID 不一致则会抛出 InvalidClassException 异常。强烈推荐每个序列化类都手动指定其 serialVersionUID,如果不手动指定,那么编译器会动态生成默认的 serialVersionUID。
serialVersionUID 不是被 static 变量修饰了吗?
为什么还会被“序列化”?static 修饰的变量是静态变量,位于方法区,本身是不会被序列化的。 static 变量是属于类的而不是对象。你反序列之后,static 变量的值就像是默认赋予给了对象一样,看着就像是 static 变量被序列化,实际只是假象罢了。
如果有些字段不想进行序列化怎么办?
对于不想进行序列化的变量,可以使用 transient 关键字修饰。
transient 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。
关于 transient 还有几点注意:
- transient 只能修饰变量,不能修饰类和方法。
- transient 修饰的变量,在反序列化后变量值将会被置成类型的默认值。例如,如果是修饰 int 类型,那么反序列后结果就是 0。
- static 变量因为不属于任何对象(Object),所以无论有没有 transient 关键字修饰,均不会被序列化。
为什么不推荐使用 JDK 自带的序列化?
我们很少或者说几乎不会直接使用 JDK 自带的序列化方式,主要原因有下面这些原因:
- 不支持跨语言调用 : 如果调用的是其他语言开发的服务的时候就不支持了。
- 性能差 :相比于其他序列化框架性能更低,主要原因是序列化之后的字节数组体积较大,导致传输成本加大。
- 存在安全问题 :序列化和反序列化本身并不存在问题。但当输入的反序列化的数据可被用户控制,那么攻击者即可通过构造恶意输入,让反序列化产生非预期的对象,在此过程中执行构造的任意代码。
相关阅读:应用安全:JAVA反序列化漏洞之殇 - Cryin 、Java反序列化安全漏洞怎么回事? - Monica。
2.2 Kryo
Kryo是一个快速高效的Java 二进制对象图序列化框架。该项目的目标是高速、小尺寸和易于使用的 API。该项目在需要持久化对象的任何时候都很有用,无论是文件、数据库还是通过网络。
另外,Kryo 已经是一种非常成熟的序列化实现了,已经在 Twitter、Groupon、Yahoo 以及多个著名开源项目(如 Hive、Storm)中广泛的使用。
Kryo的优点
- 高性能:Kryo 的设计目标是提供极快的序列化和反序列化速度。相比于一些传统的序列化框架,如 Java 的默认序列化机制,Kryo 在性能方面通常表现出更好的效果。它采用了高度优化的序列化算法和数据结构,以提高序列化和反序列化的速度。
- 紧凑的序列化格式:Kryo 生成的序列化字节流通常非常紧凑,这意味着它所占用的存储空间相对较小。较小的序列化大小可以减少网络传输的带宽占用,并降低存储成本。
- 支持多种数据类型:Kryo 能够序列化和反序列化各种数据类型,包括原始类型(如整数、浮点数)、集合(如列表、映射)、自定义对象等。它还提供了对复杂对象图的支持,能够处理对象之间的引用关系。
- 注册机制:Kryo 支持注册机制,可以显式注册类以提高序列化和反序列化的性能。通过注册类,Kryo 可以在序列化过程中使用类的编号而不是类的全限定名,从而减少序列化字节流的大小。
- 跨平台兼容性:Kryo 是一个纯 Java 实现的序列化框架,因此在不同的 Java 平台上具有良好的兼容性。它可以与许多主流的 Java 框架和库无缝集成,如 Apache Spark、Hadoop、Akka 等。
首先我们先引入依赖(这里我们是通过maven的方式):
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>5.5.0</version>
</dependency>
官网里也写了其他引用方式,感兴趣的可以直接到github下面看
测试代码示例:
public class HelloKryo {
static public void main(String[] args) throws Exception {
//1,使用kryo,我们要先创建一个kryo的对象,这里和普通序列化有些不同
Kryo kryo = new Kryo();
//2,将我们需要序列化的实体类注册进去。
//当 Kryo 去编写一个对象的实例时,首先它可能需要编写一些标识对象类的东西。默认情况下,Kryo将读取或写入的所有类都必须事先注册。注册提供 int 类 ID、用于类的序列化程序以及用于创建类实例的对象实例化程序
kryo.register(KryoBean.class);
//3,创建一个上面注册过的实体类对象。
KryoBean object = new KryoBean();
//4,给对象赋值。
object.value = "Hello Kryo!";
//5,创建输出流。
Output output = new Output(new FileOutputStream("file.text"));
//6,将数据写到指定文件,这里使用的kryo自带的方法,对象在写入文件的时候会进行序列化
/*序列化程序通常不应直接使用其他序列化程序,而应使用 Kryo 读写方法。这允许 Kryo 编排序列化并处理引用和 null 对象等功能。有时,序列化程序知道要对嵌套对象使用哪个序列化程序。
在这种情况下,它应该使用 Kryo 接受序列化程序的读写方法。*/
kryo.writeObject(output, object);
//7,关闭输出流。
output.close();
//5,创建输入流。
Input input = new Input(new FileInputStream("file.text"));
//6,通过kryo对象读取文件中的对象,并进行反序列化。
KryoBean object2 = kryo.readObject(input, KryoBean.class);
//7,关闭输入流。
input.close();
System.out.println(object2.value);
}
static public class KryoBean {
String value;
}
}
结果显示:

🆗那我们简单上手之后,就可以开发属于我们自己的序列化工具
序列化工具的接口
/**
* 序列化工具(程序调用该接口来实现obj<->byte[]之间的序列化/反序列化)
* @author eguid
*
*/
public interface Serializer{
/**
* 序列化
* @param t
* @param bytes
*/
public void serialize(Object t,byte[] bytes);
/**
* 序列化
* @param obj
* @param bytes
* @param offset
* @param count
*/
public void serialize(Object obj, byte[] bytes, int offset, int count);
/**
* 反序列化
* @param bytes -字节数组
* @return T<T>
*/
public <T>T deserialize(byte[] bytes);
/**
* 反序列化
* @param bytes
* @param offset
* @param count
* @return
*/
public <T>T deserialize(byte[] bytes, int offset, int count);
}
序列化工具的实现类
/**
* 基于kyro的序列化/反序列化工具
*
* @author eguid
*
*/
public class kryoSerializer implements Serializer {
// 由于kryo不是线程安全的,所以每个线程都使用独立的kryo
final ThreadLocal<Kryo> kryoLocal = new ThreadLocal<Kryo>() {
@Override
protected Kryo initialValue() {
Kryo kryo = new Kryo();
kryo.register(ct, new BeanSerializer<>(kryo, ct));
return kryo;
}
};
final ThreadLocal<Output> outputLocal = new ThreadLocal<Output>();
final ThreadLocal<Input> inputLocal = new ThreadLocal<Input>();
private Class<?> ct = null;
public kryoSerializer(Class<?> ct) {
this.ct = ct;
}
public Class<?> getCt() {
return ct;
}
public void setCt(Class<?> ct) {
this.ct = ct;
}
@Override
public void serialize(Object obj, byte[] bytes) {
Kryo kryo = getKryo();
Output output = getOutput(bytes);
kryo.writeObjectOrNull(output, obj, obj.getClass());
output.flush();
}
@Override
public void serialize(Object obj, byte[] bytes, int offset, int count) {
Kryo kryo = getKryo();
Output output = getOutput(bytes, offset, count);
kryo.writeObjectOrNull(output, obj, obj.getClass());
output.flush();
}
/**
* 获取kryo
*
* @param t
* @return
*/
private Kryo getKryo() {
return kryoLocal.get();
}
/**
* 获取Output并设置初始数组
*
* @param bytes
* @return
*/
private Output getOutput(byte[] bytes) {
Output output = null;
if ((output = outputLocal.get()) == null) {
output = new Output();
outputLocal.set(output);
}
if (bytes != null) {
output.setBuffer(bytes);
}
return output;
}
/**
* 获取Output
*
* @param bytes
* @return
*/
private Output getOutput(byte[] bytes, int offset, int count) {
Output output = null;
if ((output = outputLocal.get()) == null) {
output = new Output();
outputLocal.set(output);
}
if (bytes != null) {
output.writeBytes(bytes, offset, count);
}
return output;
}
/**
* 获取Input
*
* @param bytes
* @param offset
* @param count
* @return
*/
private Input getInput(byte[] bytes, int offset, int count) {
Input input = null;
if ((input = inputLocal.get()) == null) {
input = new Input();
inputLocal.set(input);
}
if (bytes != null) {
input.setBuffer(bytes, offset, count);
}
return input;
}
@SuppressWarnings("unchecked")
@Override
public <T> T deserialize(byte[] bytes, int offset, int count) {
Kryo kryo = getKryo();
Input input = getInput(bytes, offset, count);
return (T) kryo.readObjectOrNull(input, ct);
}
@Override
public <T> T deserialize(byte[] bytes) {
return deserialize(bytes, 0, bytes.length);
}
测试类:
@Test
void test2(){
Serializer ser = new kryoSerializer(Msg.class);
for (int i = 0; i < 10; i++) {
Msg msg = new Msg();
msg.setVersion_flag(new byte[] { 1, 2, 3 });
msg.setCrc_code((short) 1);
msg.setMsg_body(new byte[] { 123, 123, 123, 43, 42, 1, 12, 45, 57, 98 });
byte[] bytes = new byte[300];
long start = System.nanoTime();
ser.serialize(msg, bytes);
System.err.println("序列化耗时:" + (System.nanoTime() - start));
System.out.println(msg);
System.out.println(Arrays.toString(bytes));
Msg newmsg = null;
start = System.nanoTime();
newmsg = ser.deserialize(bytes);
System.err.println("反序列化耗时:" + (System.nanoTime() - start));
System.out.println(newmsg);
}
}
@Setter
public static class Msg{
private byte[] version_flag;
private short crc_code;
private byte[] msg_body;
}
我们查看结果:
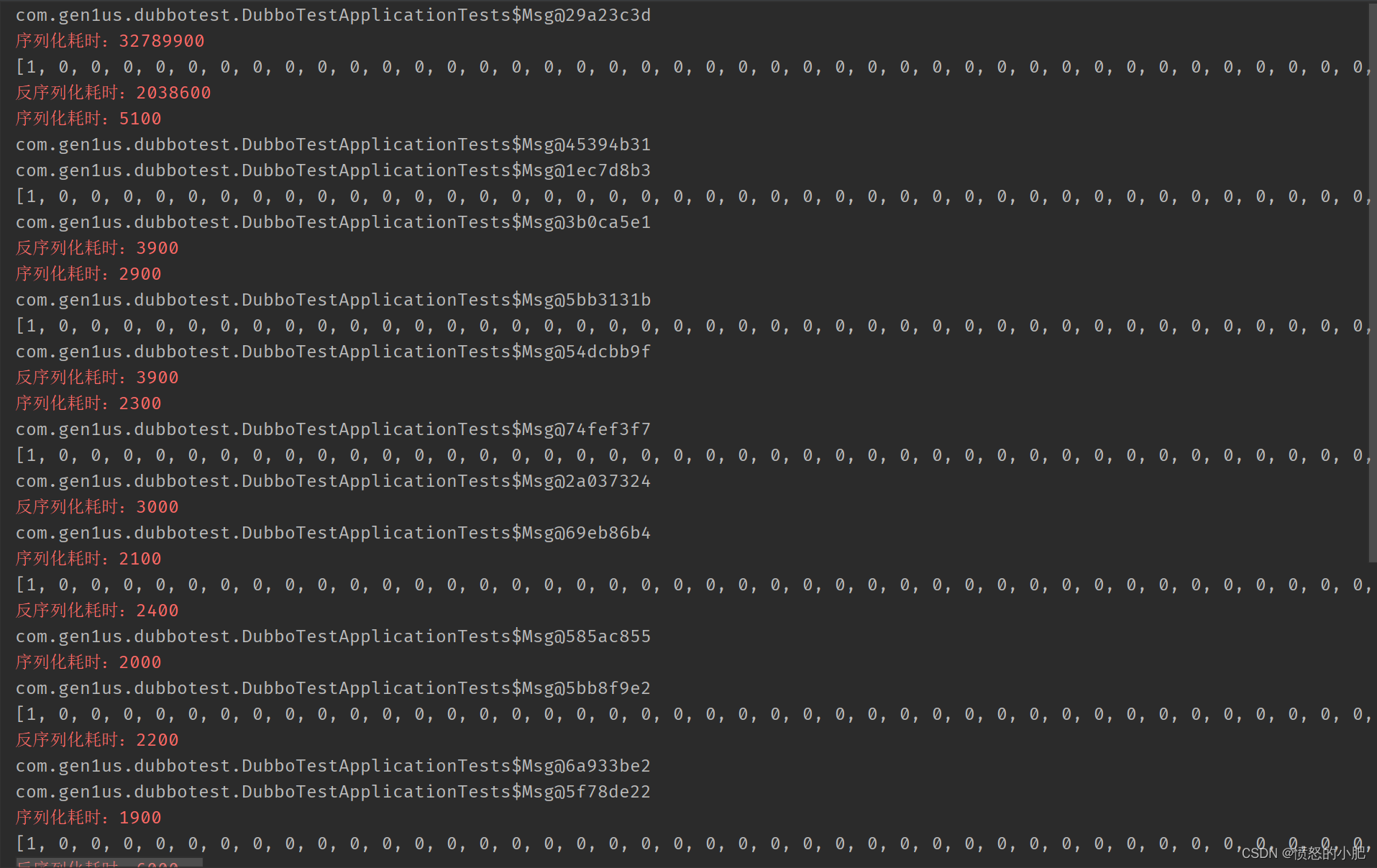
可以看到这里速度也是非常快
为什么使用纳秒,而不用毫秒?
与java原生的序列化反序列化要耗时几毫秒不同,kryo序列化和反序列化太快了,单个对象的序列化反序列化速度都在0.0x毫秒左右(1 毫秒=1000000 纳秒)
所以我们可以看出kryo序列化的性能是非常快的,也可以拿原生的序列化速度做对比,这里就不再赘述了。
接下来我们顺便简单介绍一下其他的序列化协议
2.3 Protobuf
Protobuf 出自于 Google,性能还比较优秀,也支持多种语言,同时还是跨平台的。就是在使用中过于繁琐,因为你需要自己定义 IDL 文件和生成对应的序列化代码。这样虽然不灵活,但是,另一方面导致 protobuf 没有序列化漏洞的风险。
Protobuf 包含序列化格式的定义、各种语言的库以及一个 IDL 编译器。正常情况下你需要定义 proto 文件,然后使用 IDL 编译器编译成你需要的语言
一个简单的 proto 文件如下:
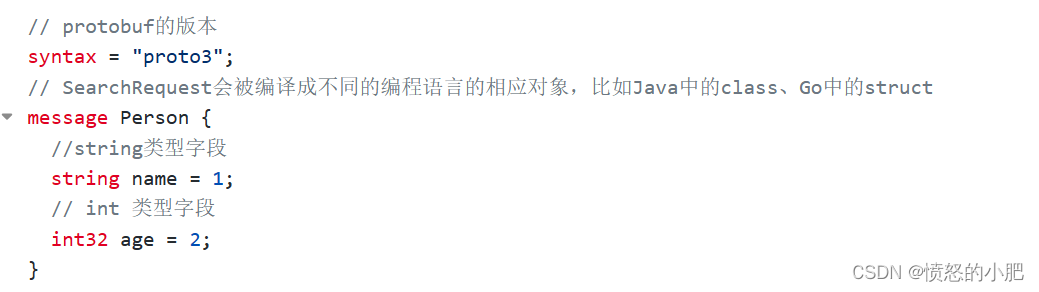
Github 地址:https://github.com/protocolbuffers/protobuf
2.4 Hessian
Hessian 是一个轻量级的,自定义描述的二进制 RPC 协议。Hessian 是一个比较老的序列化实现了,并且同样也是跨语言的

值得一提的是,Dubbo2.x 默认启用的序列化方式是 Hessian2
hession官网 :http://hessian.caucho.com/doc/hessian-overview.xtp















 419
419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









