






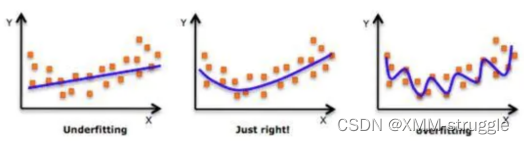
在设计机器学习算法时不仅要求在训练集上误差⼩,⽽且希望在新样本上 的泛化能⼒强。许多机器学习算法都采⽤相关的策略来减⼩测试误差,这 些策略被统称为正则化。因为神经⽹络的强⼤的表示能⼒经常遇到过拟 合,所以需要使⽤不同形式的正则化策略。
正则化通过对算法的修改来减少泛化误差,⽬前在深度学习中使⽤较多的 策略有参数范数惩罚,提前终⽌,DropOut等,接下来我们对其进⾏详细 的介绍。
L1与L2正则化
L1和L2是最常⻅的正则化⽅法。它们在损失函数(cost function)中增加 ⼀个正则项,由于添加了这个正则化项,权重矩阵的值减⼩,因为它假定 具有更⼩权重矩阵的神经⽹络导致更简单的模型。 因此,它也会在⼀定 程度上减少过拟合。然⽽,这个正则化项在L1和L2中是不同的。
L1正则化
![]()
这⾥,我们惩罚权重矩阵的绝对值。其中,λ 为正则化参数,是超参数, 不同于L2,权重值可能被减少到0.因此,L1对于压缩模型很有⽤。其它情 况下,⼀般选择优先选择L2正则化。
L2正则化
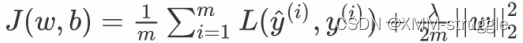
这⾥的λ是正则化参数,它是⼀个需要优化的超参数。L2正则化⼜称为权 重衰减,因为其导致权重趋向于0(但不全是0)
在tf.keras中实现使⽤的⽅法是:
L1正则化
tf.keras.regularizers.L1(l1=0.01)
L2正则化
tf.keras.regularizers.L2(l2=0.01)
L1L2正则化
tf.keras.regularizers.L1L2(
l1=0.0, l2=0.0
)我们直接在某⼀层的layers中指明正则化类型和超参数即可:
# L1与L2正则化,优先选L2
#正则化通过对算法的修改来减少泛化误差,缓解过拟合
# 导⼊相应的⼯具包
import tensorflow as tf
from tensorflow.keras import regularizers
# 创建模型
model = tf.keras.models.Sequential()
# L2正则化,lambda为0.01
model.add(tf.keras.layers.Dense(16, kernel_regularizer=regularizers.l2(0.001),
activation='relu', input_shape=(10,)))
# L1正则化,lambda为0.01
model.add(tf.keras.layers.Dense(16, kernel_regularizer=regularizers.l1(0.001),
activation='relu'))
# L1L2正则化,lambda1为0.01,lambda2为0.01
model.add(tf.keras.layers.Dense(16, kernel_regularizer=regularizers.L1L2(0.001),
activation='relu'))Dropout正则化
dropout是在深度学习领域最常⽤的正则化技术。Dropout的原理很简单: 假设我们的神经⽹络结构如下所示,在每个迭代过程中,随机选择某些节 点,并且删除前向和后向连接。
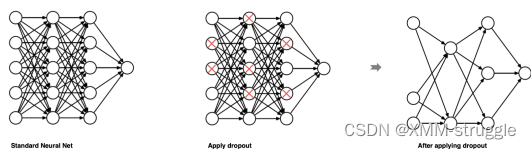
因此,每个迭代过程都会有不同的节点组合,从⽽导致不同的输出,这可 以看成机器学习中的集成⽅法(ensemble technique)。集成模型⼀般优 于单⼀模型,因为它们可以捕获更多的随机性。相似地,dropout使得神 经⽹络模型优于正常的模型。
在tf.keras中实现使⽤的⽅法是dropout:
tf.keras.layers.Dropout(rate)
参数:
rate: 每⼀个神经元被丢弃的概率
例⼦:
#Dropout正则化
#在每个迭代过程中,随机选择某些节点,并且删除前向和后向连接((失活,掉去)的为0)。
# 导⼊相应的库
import numpy as np
import tensorflow as tf
# 定义dropout层,每⼀个神经元有0.2的概率被失活,未被失活的输⼊将按(1 /(1-0.2))倍放大,前面有两个神经元每个神经元输入一个结果
layer = tf.keras.layers.Dropout(0.2,input_shape=(2,))
# 定义五个批次的数据
data = np.arange(1,11).reshape(5, 2).astype(np.float32)
# 原始数据进⾏打印
print(data)
# 进⾏随机失活:在training模式中,返回应⽤dropout后的输出;或者在⾮
outputs = layer(data,training=True)
# 打印失活后的结果
print(outputs)
[[ 1. 2.]
[ 3. 4.]
[ 5. 6.]
[ 7. 8.]
[ 9. 10.]]
tf.Tensor(
[[ 1.25 2.5 ]
[ 3.75 0. ]
[ 6.25 7.5 ]
[ 8.75 10. ]
[11.25 0. ]], shape=(5, 2), dtype=float32)提前停⽌
提前停⽌(early stopping)是将⼀部分训练集作为验证集(validation set)。 当验证集的性能越来越差时或者性能不再提升,则⽴即停⽌对该 模型的训练。 这被称为提前停⽌。
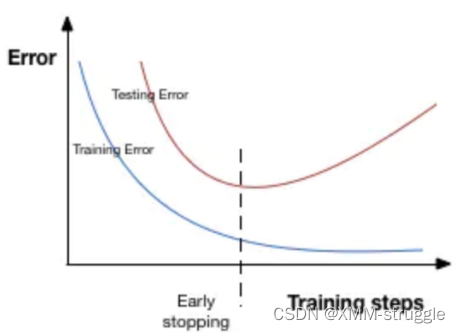
在上图中,在虚线处停⽌模型的训练,此时模型开始在训练数据上过拟合。
在tf.keras中,我们可以使⽤callbacks函数实现早期停⽌:
tf.keras.callbacks.EarlyStopping(
monitor='val_loss', patience=5
)
上⾯,monitor参数表示监测量,这⾥val_loss表示验证集损失。⽽ patience参数epochs数量,当在这个过程性能⽆提升时会停⽌训练。为了 更好地理解,让我们再看看上⾯的图⽚。 在虚线之后,每个epoch都会导致更⾼的验证集误差。 因此,虚线后patience个epoch,模型将停⽌训 练,因为没有进⼀步的改善。
#提前停⽌
#提前停⽌(early stopping)是将⼀部分训练集作为验证集(validationset)。 当验证集的性能越来越差时或者性能不再提升,则⽴即停⽌对该模型的训练。 这被称为提前停⽌。
#模型开始在训练数据上过拟合使⽤callbacks函数实现早期停⽌
# 导⼊相应的⼯具包
import tensorflow as tf
import numpy as np
# 当连续3个epoch loss不下降则停⽌训练
callback = tf.keras.callbacks.EarlyStopping(monitor='loss',patience =3)
# 定义只有⼀层的神经⽹络
model = tf.keras.models.Sequential([tf.keras.layers.Dense(10)])
# 设置损失函数和梯度下降算法
model.compile(tf.keras.optimizers.SGD(), loss='mse')
# 模型训练
history = model.fit(np.arange(100).reshape(5, 20), np.array([0,1,2,1,2]),
epochs=10, batch_size=1, callbacks=[callback],verbose=1)
# 打印运⾏的epoch
len(history.history['loss'])批标准化
批标准化(BN层,Batch Normalization)是2015年提出的⼀种⽅法,在进⾏ 深度⽹络训练时,⼤多会采取这种算法,与全连接层⼀样,BN层也是属 于⽹络中的⼀层。
BN层是针对单个神经元进⾏,利⽤⽹络训练时⼀个 mini-batch 的数据来 计算该神经元xi 的均值和⽅差,归⼀化后并重构,因⽽称为 Batch Normalization。在每⼀层输⼊之前,将数据进⾏BN,然后再送⼊后续⽹ 络中进⾏学习:
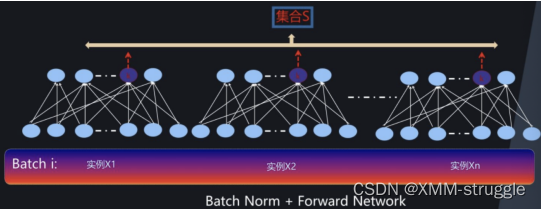
⾸先我们对某⼀批次的数据的神经元的输出进⾏标准化
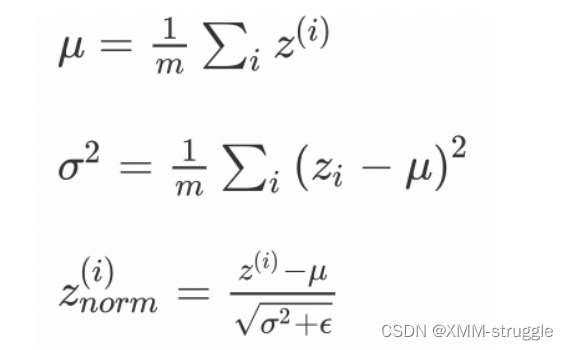
然后在使⽤变换重构,引⼊了可学习参数γ、β,如果各隐藏层的输⼊均值 在靠近0的区域,即处于激活函数的线性区域,不利于训练⾮线性神经⽹ 络,从⽽得到效果较差的模型。因此,需要⽤ γ 和 β 对标准化后的结果做 进⼀步处理:

这就是BN层最后的结果。整体流程如下图所示:
在tf.keras中实现使⽤:
#批标准化
#批标准化(BN层,Batch Normalization)在进⾏深度⽹络训练时,⼤多会采取这种算法,与全连接层⼀样,BN层也是属于⽹络中的⼀层。BN层是针对单个神经元进⾏,利⽤⽹络训练时⼀个 mini-batch 的数据来计算该神经元xi 的均值和⽅差,归⼀化后并重构,因⽽称为 BatchNormalization。在每⼀层输⼊之前,将数据进⾏BN,然后再送⼊后续⽹络中进⾏学习:
# 直接将其放⼊构建神经⽹络的结构中即可
tf.keras.layers.BatchNormalization(epsilon=0.001,
center=True,
scale=True,
beta_initializer='zeros',
gamma_initializer='ones',
)

















 382
382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











