







目录
链表
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
头指针:
指向链表中第一个结点(头结点或无头结点时的开始结点)的指针。
头结点:在开始结点之前附加的一个结点。
开始结点:在链表中,存储第一个数据元素(a1)的结点。
链表的结构非常多样,有单链表和双链表,带头结点的和不带头结点的,还有循环链表和非循环链表。
p->data表示p指向结点的数据域中的值
p->next表示p指向结点的指针域中的内容,即下一个结点的指针。
数据域:存放数据元素信息的域;
指针域:存放其后继元素地址的域。
这边用C 语言实现无头单向非循环链表和带头双向循环链表。
无头单向非循环链表:
结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。
带头双向循环链表:
结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势。
单向非循环链表
结点中只含一个指针域的链表叫单链表。
结点的定义:

单链表的每个结点由一个数据域和一个指针域组成:
单链表的存取必须从头指针开始。意思只给你个头指针,然后其他啥也不给,就对这个表进行增删查改操作。
结点的定义:

单链表的基本操作:


创建结点初始化并返回地址
LNODE* NewLNode(LinkListDataType x)
{
LNODE* p = (LNODE*)malloc(sizeof(LNODE));
assert(p);
p->data = x;
p->next = NULL;
return p;
}
打印链表
void LinkListPrint(LNODE* L)
{
if (!L)
{
printf("\n");
return;
}
LNODE* p = L;
while (p != NULL)
{
printf("%d->", p->data);
p = p->next;
}
printf("\n");
}
单链表的尾插
void LinkListPushBack(LNODE** L, LinkListDataType x)
{
LNODE* p = *L;
if (p == NULL)
{
*L = NewLNode(x);
return;
}
if (p->next == NULL)
{
p->next = NewLNode(x);
}
else
{
while (p->next != NULL)
{
p = p->next;
}
p->next = NewLNode(x);
}
}
单链表的头插
void LinkListPushFront(LNODE** pplist, LinkListDataType x)
{
LNODE* p = *pplist;
if (!p)
{
p = NewLNode(x);
return;
}
else
{
*pplist = NewLNode(x);
(*pplist)->next = p;
}
}
单链表的尾删
void LinkListPopBack(LNODE** pplist)
{
LNODE* p = *pplist;
if (!p)
{
return;
}
if (!p->next)
{
free(p);
*pplist = NULL;
return;
}
if (p->next != NULL)
{
LNODE* wei = *pplist;
p = p->next;
while (p->next)
{
p = p->next;
wei = wei->next;
}
free(p);
wei->next = NULL;
}
}
单链表的头删
void ListListPopFront(LNODE** pplist)
{
if (!(*pplist))
return;
LNODE* p = (*pplist)->next;
free(*pplist);
*pplist = p;
}
单链表查找
LNODE* LinkListFind(LNODE* plist, LinkListDataType x)
{
if (!plist)
return NULL;
LNODE* findx = plist;
if (findx->data == x)
{
return findx;
}
while (findx->next)
{
if (findx->data == x)
{
return findx;
}
findx = findx->next;
if (findx->data == x)
{
return findx;
}
}
return NULL;
}
在pos位置之后插入x
void LinkListInsertAfter(LNODE* pos, LinkListDataType x)
{
//这边得到的是一个结点的地址
assert(pos);
LNODE* newN = pos->next;
pos->next = NewLNode(x);
pos->next->next = newN;
}
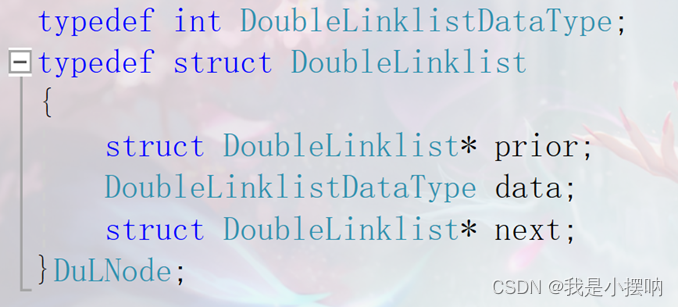
双向带头循环链表
因为单链表具有单向性的缺点,不能方位其上一个结点,双向列表可以解决这个问题,双向链表和单向不同的是结点里面多了一个指针域指向它的上一个结点。
结构定义
基本操作


初始化&申请新结点

打印链表
void DoubleLinkLListPrint(DuLNode* plist)
{
assert(plist);
if (plist->next == plist)
{
printf("NULL\n");
return;
}
DuLNode* p = plist->next;
while(p!=plist)
{
printf("%d ", p->data);
p = p->next;
}
printf("\n");
}
在一个结点的后面插入一个新结点
void DoubleLinkListInsert(DuLNode* pos, DoubleLinklistDataType x)
{
DuLNode* newnode = NewDulNode(x);
assert(newnode);
DuLNode* next = pos->next;
pos->next = newnode;
newnode->prior = pos;
newnode->next = next;
next->prior = newnode;
}
任意位置的删除
void DoubleLinkListErase(DuLNode* pos)
{
if (pos->next == pos)
{
printf("无法删除此位置,该位置为头结点");
return;
}
DuLNode* prve = pos->prior;
DuLNode* next = pos->next;
free(pos);
prve->next = next;
next->prior = prve;
}
双向链表-尾插,头插,尾删,头删。
因为已经实现了任意位置的删除和插入,那么,头尾插删久就直接调用这个函数就好啦~




双向链表查找
DuLNode* ListFind(DuLNode* plist, DoubleLinklistDataType x)
{
DuLNode* find = plist->next;
while (find != plist)
{
if (find->data == x)
{
return find;
}
find = find->next;
}
return NULL;
}
存储密度
指结点数据本身所占的存储空间和整个结点结构所占的存储空间之比。
存储密度d=点数据占的存储位/整个结点实际分配的存储位
所以:顺序表的存储密度等于1,而链表的存储密度小于1。
由此可见:顺序表的存储密度等于1,而链表的存储密度小于1。
总结
- 线性表是一种最简单的数据结构,数据元素之间存在着一对一的关系。其存储方法通常采用顺序存储和链式存储。
- 线性表的链式存储是通过结点之间的链接而得到的。根据链接方式又可以分为:单链表、双链表和循环链表等。
- 单链表有一个数据域(data)和一个指针域(next)组成,数据域用来存放结点的信息;指针域指出表中下一个结点的地址。在单链表中,只能从某个结点出发找它的后继结点。单链表最大的优点是表的扩充容易、插入和删除操作方便,而缺点是存储空间比较浪费。
- 双链表有一个数据域(data)和两个指针域(prior和next)组成,它的优点是既能找到结点的前趋,又能找到结点的后继。
- 循环链表使最后一个结点的指针指向头结点(或开始结点)的地址,形成一个首尾链接的环。利用循环链表将使某些运算比单链表更方便。
顺序表和链表的区别和联系:
顺序表:
空间连续、支持随机访问。
中间或前面部分的插入删除时间复杂度O(N)。
增容的代价比较大。
链表:
以节点为单位存储,不支持随机访问。
意位置插入删除时间复杂度为O(1)。
没有增容问题,插入一个开辟一个空间。















 2458
2458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









