







目录
一、什么是序列?
在python当中序列就是一组按顺序排列的值(数据集合)。
优点:支持索引(下标)和切片的操作。
特点: 第一个元素的索引为0,表示从左向右编号。第一索引为负数表示从右向左编号。
二、什么是切片?
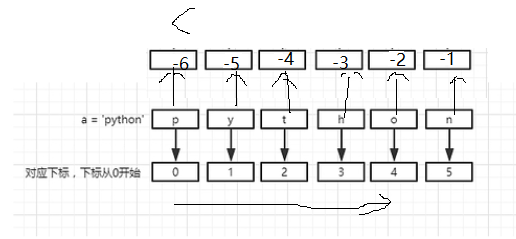
切片可以根据下标截取序列中的任意部分数据
语法结构: [start:end:step]
说明:
*截取的数据不包括end下标所指的数据(左闭右开),用法类似于range( )函数。
*默认从第0个元素下标开始、步长为1。如果step为负数,则表示从右向左倒序读取序列中的每个元素。
*下标会越界而切片不会越界。
*只有字符串、列表、元组支持切片操作,字典因为不支持下标索引所以不支持切片操作。
案例:
三、操作字符串str
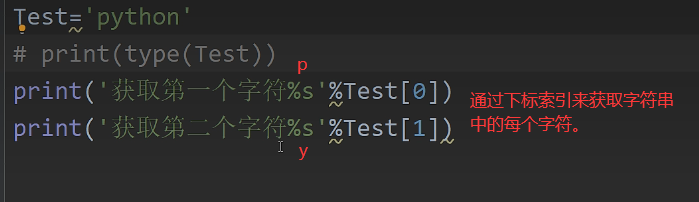
通过下标索引获取字符串中的某个字符:
字符串相关函数方法:
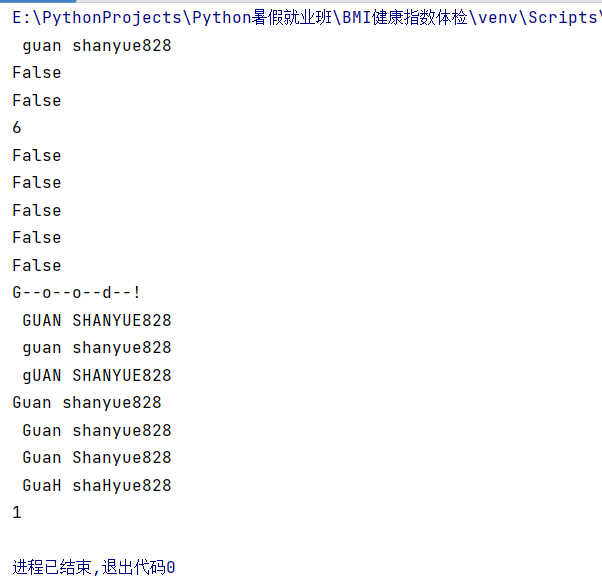
str="Guanshanyue828"
print(str.capitalize()) #将字符串的首字母变大写
print(str.endswith('yue')) #判断字符串是否以某个子串结束.是返回True,否则返回False
print(str.startswith("guan")) #判断字符串是否以某个子串开始
print(str.find("shanyue")) #判断某字符串是否是原字符串的子串。如果是返回字串首字符其在源字符中的下标,否则返回-1
#print(str.index("shanyue")) #在原字符串中查找字串。用法和find()函数相同。如果不是原字符串的字串会报错。
print(str.isalnum()) #判断字符串是否只有数字、字符或者数字+字符串组成。是返回true,否则返回False
print(str.isalpha()) #判断字符串是否只有字母组成。是返回True,否则返回False
print(str.isdigit()) #判断字符串是否只有数字组成。是返回True,否则发回False
print(str.islower()) #判断哪字符串中的英文字母是否为小写字母。是返回True,否则返回False
print(str.isupper()) #判断字符串中的字母是否都为大写。是返回True,否则返回False
print('--'.join("Good!")) #以指定字符串作为分割符,来连接join()括号内所指的字符串、列表、元组、子典等元素。
print(str.upper()) #将字符串中的小写字母转化为大写字母
print(str.lower()) #将字符串中的大写字母转化为小写字母
print(str.swapcase()) #将字符串中的大写字母转化为小写字母、小写字母转化为大写字母
print(str.strip()) #去掉字符串首和尾部的空格。lstrip()函数只去掉字符串左侧的空格。rstrip()函数去掉字符串右侧空格
print(str.split('&',2)[0]) #以指定分割符来拆分字符串。第一个参数:表示以什么字符串作为分割符,第二个参数2:表示获取前2个分割符分隔的前后字符串、返回值为列表,
#第三个参数[下标],指获取返回列表中的那个元素
print(str.title()) #将字符串中每个单词首字母变为大写
print(str.replace('n','H',2)) #替换字符串。将原字符串中的某个字符串替换为另个指定字符串,2表示要替换的字符串整体个数。
print(str.count('shan')) #统计指定字符串在原字符串中出现的次数
运行结果:
四、操作列表list
定义:
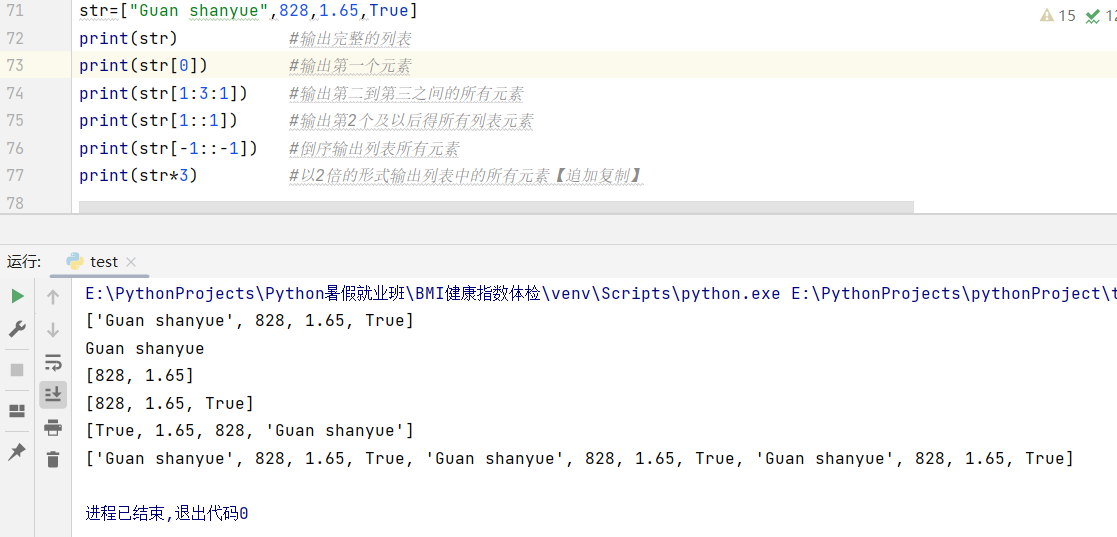
list=[ ] #定义一个空列表
print(type(list))
li=[1,2,3,"你好!"]
print(len(li)) #len()函数用于统计字符串、列表等序列元素的个数。
查找:

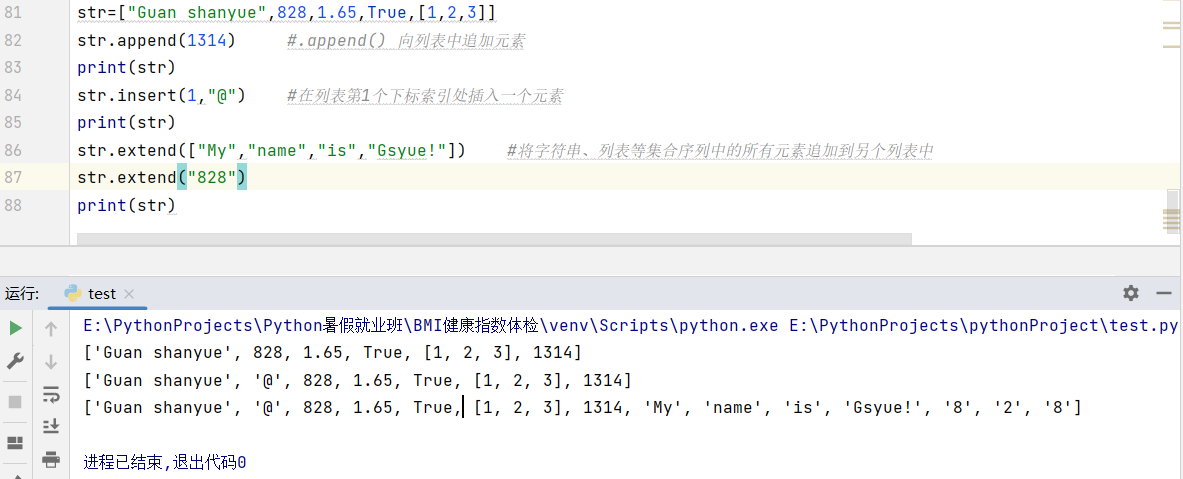
增加:
liebiao=list(range(10)) #使用range( )函数产生0~9的整形序列数字,并将其强转为列表类型赋值给liebiao变量。
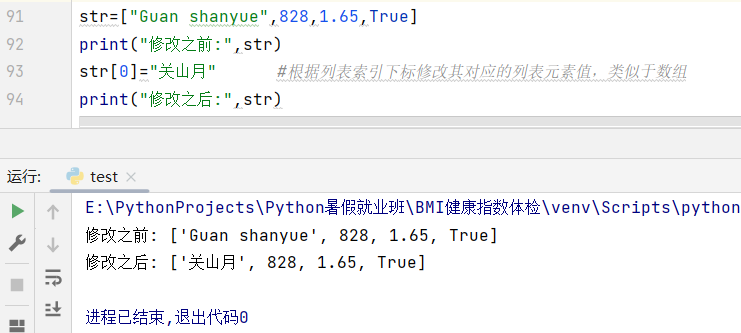
修改:
删除:
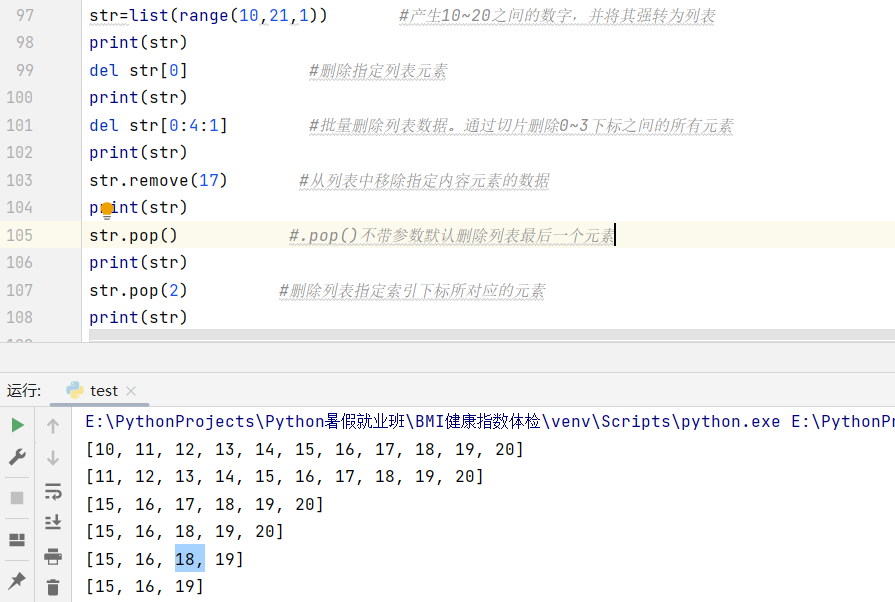
五、操作元组tuple
元组是一种不可变的序列, 在创建之后不能对里面的元素进行任何修改。
特点:
1、只读、内容不可变,但元组里面欠套的列表等其它序列类型可以修改。
2、用( )创建元组类型,数据项用逗号分隔; 也可以省略括(),用逗号分隔元素直接创建元组如:tupleA=1,2,3,4。
3、可以是任意类型的数据元素。
4、元组只有一个元素时需在其后加上逗号,不然解释器会当做括号运算符。
5、支持切片操作。
tupleA=(28,1.65,"comrade",28,False,[1,28,3]) #元组一旦创建则不能修改元素值
#tupleA[0]=12 #无法修改
tupleA[-1][1]=12 #可以修改元组中的列表等数据类型
print(tupleA)
#查:
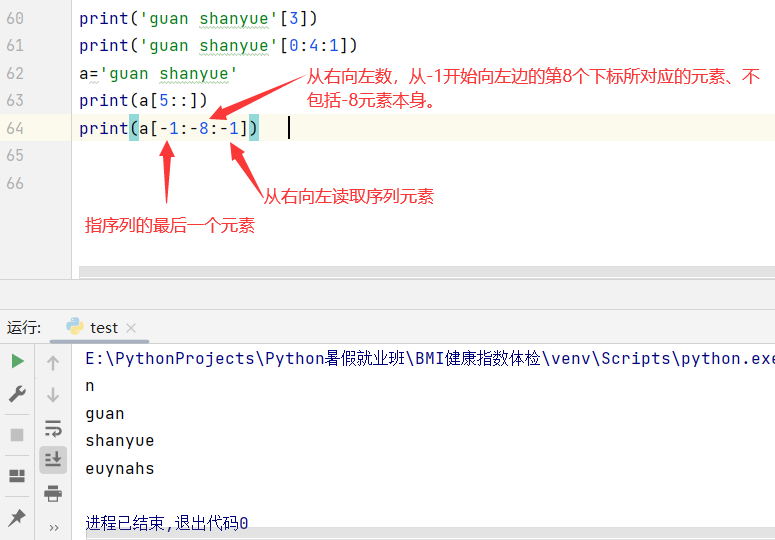
print(tupleA[1:4:1]) #从左向右,从第1个下标取到第3个元素下标处
print(tupleA[-1:-4:-1]) #倒着从右向左,从-1取到-4、不包含-4下标所指元素本身
print(tupleA[-3:-1:]) #从左向右(隐藏的第三个切片参数是1),从-3所指元素取到-1所指元素、不包含-1所指元素本身
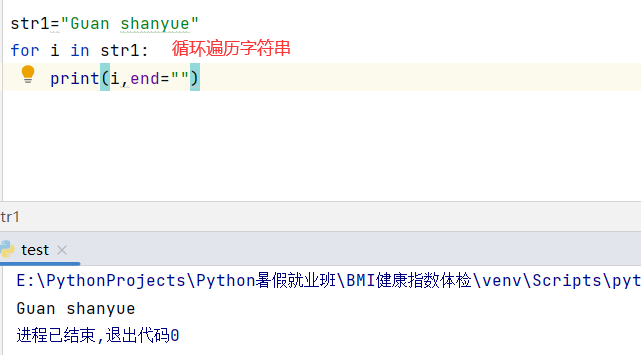
for item in tupleA: #循环遍历元组中的元素
print(item,end="")
#元组方法
print(tupleA.count(28)) #统计元素在元组中的使用次数
print(tupleA.index("comrade")) #寻找元素值所在的元组下标索引
六、操作字典dict
字典是由键值对组成的数据集合、通过使用键来访问所对应的元素数据、和list一样支持增删改查。
特点:
1、子典没有下标的概念、不是序列数据类型,而是一个无序的数据集合、是python中高级的数据类型。
2、{ }大括号表示子典对象,每个键值对用逗号分隔。
3、键必须是不可变的数据类型【整型、浮点型、字符串、元组】,键所对应的值可以是任意数据类型。
4、子典的键必须是唯一的如果有重复的键,后者会覆盖前者。
5、如果在使用”变量名['键'] = 值 “,修改子典中的某项数据时,如果这个键在字典中不存在,那么就会新增这个元素。
dictA={'name':'关山月','ages':'23','numb':'36'} #创键并初始化子典:keys:values
dictA['ages']='18' #修改字典中‘ages'键所对应的值
dictA['addr']='河南鹿邑县' #子典中没有'addr'所对应的键值,则自动创建此键值
print(len(dictA)) #获取集合数据类型的元素个数
#子典使用方法
print(dictA.values()) #获取子典中所有的values值,返回类型为列表
print(dictA.keys()) #获取字典中所有的键,返回类型为列表
print(dictA.items()) #以列表,元组元素的形式获取字典中的键值对
dictA.update({'name':'关荣业'}) #修改子典中的键值对、如果没有则创建此键值对
print(dictA)
#循环遍历字典中的键值对
for keys,values in dictA.items(): #循环遍历.items()返回的列表中的每个元组元素,并将每个元组中的第一个元素赋值给keys变量,第二个赋值给values
print("%s:%s"%(keys,values))
pass
#子典排序----根据字典键的字符编码顺序进行排序(只有相同数据类型的数据才能排序)
#sorted()函数对序列进行排序,返回值为list。
#第一个参数是:要排序的序列对象。
#第二个参数key:以哪个作为参考对象进行排序。
#第三个参数是升序、还是降序
print(dictA)
print(sorted(dictA.items(),key=lambda tupleA:tupleA[0]))
#首先sorted()函数会对.items()返回的列表序列中的所有元素(元组)进行排序
#过程:逐一遍历列表中的每个元组元素,并将其赋值给lambda函数中的tupleA参数;
#然后以传递给tupleA参数中、元组的[0]下标的元素作为比较参考依据对序列进行排序
#删除键值对
del dictA['name']#根据子典中的键来删除字典中的元素
dictA.pop('ages')#根据键来删除字典中的元素
print(dictA)
七、操作集合set
什么是集合?
将不同类型的数据以“{ }”的方式组合到一起所形成的一组数据就称为集合。
定义:
set1={"1", 2, 3.45, (2,4,6)}
特点:
1、不重复: 集合中的元素是不能重复的。
2、无序: 集合不支持下标索引和切片,每个元素的位置不固定。
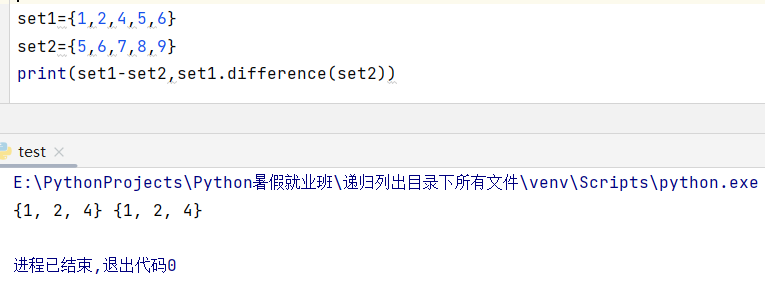
1、差集(a-b): 去掉a集合中和b集合相同的元素后,a集合所剩下的元素即为差集。
集合1.difference(集合2)-------求差集
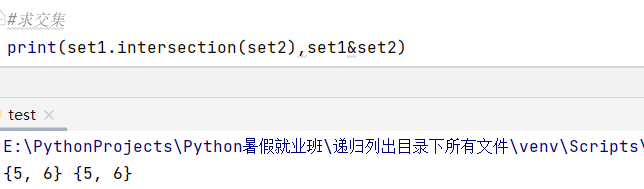
2、交集(a&b): a和b集合共同的元素
集合1.intersection(集合2)------求交集
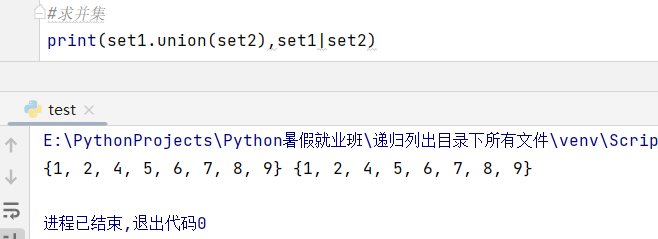
3、并集(a|b): a和b集合全部的、非重复的元素
集合1.union(集合2)-----求并集
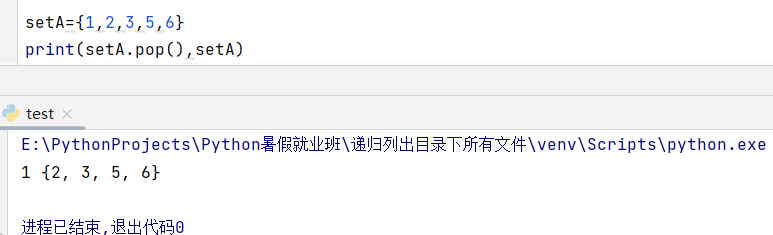
4、集合.pop( )-----随机返回集合中的某个元素并将其删除。
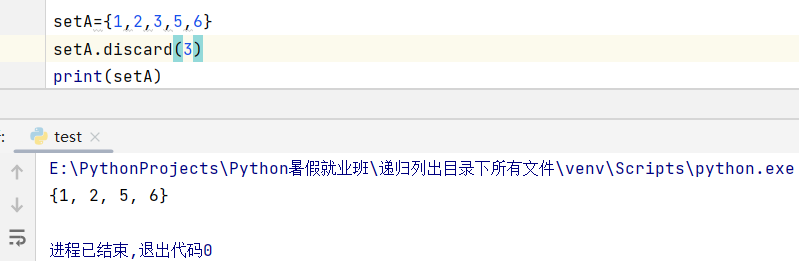
5、集合.discard(集合元素)------删除集合中指定的元素。
集合.clear()------清空集合中所有元素
6、集合.update(预添加元素集合)------向原集合中添加新的元素,集合重复元素不会添加。
集合.add(元素)------向集合中追加元素

八、共有操作(字符串、列表、元组、字典)
①"+":将两个序列对象相加
②"*":将序列对象自增几倍
③“arg1 in arg2”:判断arg1是否在arg2集合序列里面
str1="Mynameis"
str2="Guanshanyue"
list1=list(range(10))
list2=list(range(10,21,1))
dictA={'name':'shanyue','gender':'man'}
dictB={'addr':"河南"}
#"+":将两个序列对象相加
print(str1+str2) #序列变量1+序列变量2:将序列变量2追加到序列变量1的后面,可以是字符串、列表{}、元组()。
print(list1+list2)
#"*":将序列对象自增几倍
print(str1*3) #将字符串序列对象自增3倍,可以是字符串、列表、元组
print(list1*3) #将列表序列对象自增3倍
#“arg1 in arg2”:判断arg1是否在arg2里面
print("shanyue"in str2) #判断“shanyue”字符串是否在str2里面(子串)
print(9 in list1) #判断9是否在list1中
print('gender' in dictA) #判断dictA子典中是否包含‘gender’键值
输出结果:
E:\PythonProjects\Python暑假就业班\BMI健康指数体检\venv\Scripts\python.exe E:\PythonProjects\pythonProject\test.py
My name is Guan shanyue
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]
My name is My name is My name is
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
True
True
True
注意: 在python中容器(列表、元组、子典、集合)内的所有元素本质上保存的都是数据所占用的一块内存的地址。
@声明:“山月润无声”博主知识水平有限,以上文章如有不妥之处,欢迎广大IT爱好者指正,小弟定当虚心受教!
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











