







今天阅读这篇2022年ICLR会议上发表的论文,主要是为了学习MobileViT模型,用于YOLO模型主干改造。
一、文献概述

- 作者:Sachin Mehta 和 Mohammad Rastegari。
- 地点:作者所属机构是 Apple。
- 内容简述:
- 提出了一种名为MobileViT的视觉变换器,它是为移动设备设计的轻量级、通用目的的卷积神经网络(CNN)。
- MobileViT旨在结合CNN和ViTs的优势,旨在构建一个轻量级和低延迟的移动视觉任务网络。
- 论文中提到,MobileViT在不同任务和数据集上显著优于CNN和ViT基础的网络架构,比如在ImageNet数据集上,MobileViT的准确率比MobileNetV3(基于CNN)高出3.2%和6.2%。
- 该论文还提到,对于MS-COCO数据集的对象检测任务,MobileViT比MobileNetV3(基于CNN)准确率高5.7%。
- 论文的源代码是开源的,可在GitHub上找到。
二、Introduction部分

讨论了在视觉任务中使用CNNs和ViTs的对比和潜在的改进。
- 文档引用了多位研究人员和他们的工作,例如 Dosovitskiy et al., 2021; Vaswani et al., 2017; Touvron et al., 2021a; Howard et al., 2019; Raffel et al., 2021; Xiao et al., 2021; Wang et al., 2021; Devlin et al., 2018等。
- 内容简述:
- 讨论了自注意力模型,特别是视觉变换器(ViTs),作为卷积神经网络(CNNs)的替代方案来学习视觉表示。
- 指出ViTs使用多头自注意力来学习表示,而CNNs则具有空间归纳偏差,允许它们学习具有少量参数的表示。
- 提到ViTs在某些任务上的性能比轻量级CNNs差,特别是在参数数量受限时。
- 强调了设计轻量级ViT模型的重要性,因为即使对于需要快速反应的任务,ViTs的模型大小和执行速度也是关键因素。
- 讨论了尽管轻量级CNNs在许多移动视觉任务上表现出色,但ViT基于网络在与任务相关的网络集成方面仍然沉重。
- 引述了对混合方法的需求,这种方法结合了CNNs和变换器的优势,以解决ViT模型中的参数数量问题。
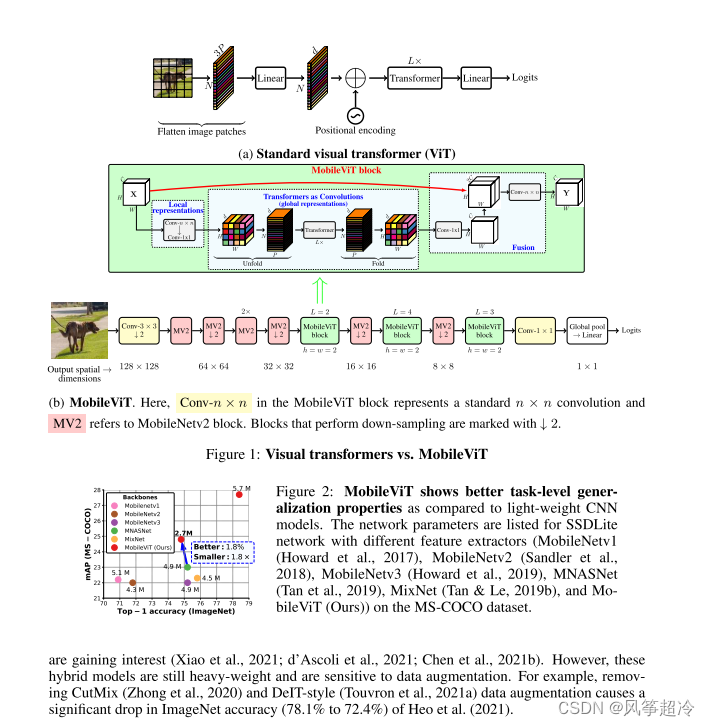
-
图示:
- (a) 显示了标准视觉变换器(ViT)的结构图。过程开始于将图像分割成小块,然后通过线性层,接着是位置编码和变换器层,最后通过另一个线性层生成Logits。
- (b) 展示了MobileViT的结构,其中Conv-n×n表示标准的n×n卷积,MV2代表MobileNetV2块。图中用箭头标记了执行下采样的块。
-
图表:
- 图1(Figure 1)标题为“Visual transformers vs. MobileViT”,对标准视觉变换器和MobileViT进行对比。
- 图2(Figure 2)展示了MobileViT与轻量级CNN后端(如MobileNetV1,MobileNetV2,MobileNetV3,MNASNet和MobileViT)相比,在任务级泛化性能方面的优势。图表显示了不同模型在MS-COCO数据集上的性能比较,MobileViT在这里显示了更好的性能。
-
文本内容:
- 简要讨论了视觉变换器(ViTs)和卷积神经网络(CNNs)的混合模型。指出这些混合模型虽然受到关注,但仍然较重,并且对数据增强敏感。例如,去除CutMix数据增强导致ImageNet准确率显著下降。
图片主要展示了MobileViT的设计和优势,以及它与传统CNNs和其他ViTs的性能比较。这些信息用于解释MobileViT如何提高效率,以及它在机器学习和计算机视觉领域的应用。

- 内容简述:
- 讨论了将CNNs和变换器的优势结合起来构建适用于移动视觉任务的模型的问题,强调了在移动设备上实现低延迟至关重要。
- 指出FLOPs(浮点运算次数)不足以表示移动设备上的延迟,因为它忽略了内存访问、并行度和平台特性等推理相关因素。
- 强调优化FLOPs而不是其他因素可能不足以实现低延迟的移动设备性能。
- 本文不是优化FLOPs,而是着重设计轻量级(第3.3节)、通用目的(第4.1节和第4.2节)和低延迟(第4.3节)的移动视觉任务网络。
- 提到MobileViT块结合了CNNs和ViTs的优点,如空间归纳偏见和对数据增强的敏感性较低,能够在张量中有效编码局部和全局信息。
- 描述了MobileViT块如何通过使用变换器替代卷积中的局部处理来实现全局处理,这有助于MobileViT获得类似CNN和ViT的属性。
- 论文还提到,MobileViT在参数数量和简单的训练方法方面都有改进,显示了在移动设备上使用MobileViT作为特征提取器时的性能增益。
这部分内容强调了MobileViT在实现移动视觉任务方面的潜在优势,尤其是在处理速度和计算效率方面。
三、Related Work 部分

这张图片是一篇科学论文的一部分,主要内容包括:
-
内容简述:
- 讨论了轻量级CNNs的基本构建层,是一种标准的卷积层,提到了多种方法来制作轻量级CNNs。
- 引用了多个研究来支持轻量级CNNs在移动视觉任务中的应用,例如MobileNets、ShuffleNet、MNASNet等。
- 提及了视觉变换器(ViTs),它们是2017年由Dosovitskiy等人提出的,用于大规模图像识别,并且能够在极其大的数据集上达到CNN级别的准确性。
- 细节介绍了ViTs的一些改进,如使用卷积替代线性投影,以及如何通过在ViTs中使用卷积来增加其稳定性和性能。
- 讨论了MobileViT模型的优点,特别是在给定参数预算下的性能表现。
-
图3(Figure 3):展示了MobileViT模型的三个变体(MobileViT-XXS、MobileViT-XS和MobileViT-S)在训练和验证过程中的表现。
- (a) 训练误差(Training error)
- (b) 验证误差(Validation error)
- (c) 验证准确性(Validation accuracy)
- (d) 参数分布(Parameter distribution)
-
图表和图示:
- 图3a和图3b展示了不同规模的MobileViT模型在训练和验证过程中的误差曲线,可以看出,随着训练的进行,误差在减少。
- 图3c比较了MobileViT模型与其他模型在验证准确性上的表现,显示MobileViT在给定的参数预算下取得了
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









