







ELK简介
ELK是三个开源软件的缩写(Elasticsearch、Logstash、Kibana),它是一个轻量级的日志收集处理。ELK近实时日志分析搜索系统。
Elasticsearch是用Java语言编写,基于Lucene全文检索引擎框架,是一个开源分布式搜索引擎,提供收集、分析、存储数据三大功能。
特点是:分布式、零配置、自动发现、索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash是一个完全开源的工具,主要用来对日志进行收集、分析、过滤的,支持大量的数据获取方式。一般工作方式是C/S架构,client端安装在需要收集日志的主机上,server端负责将收到的各个节点日志进行过滤、修改操作在一并发往elasticsearchss上。
Kibana 是一个开源、免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供日志分析的 Web 界面,可以汇总、分析和搜索重要数据日志。
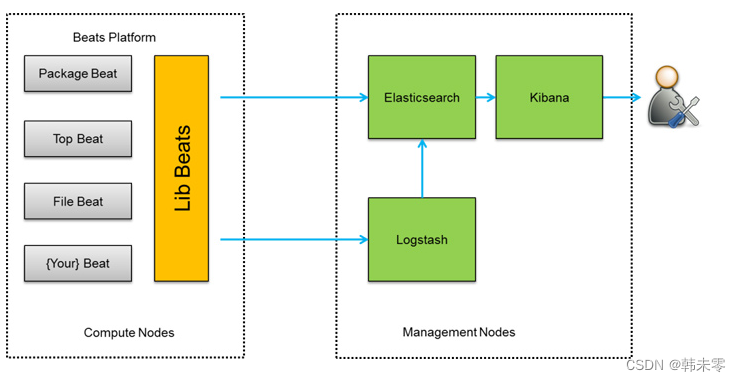
早期的ELK架构中使用的是Logstash进行收集、解析和过滤日志,但是Logstash对CPU、内存、IO等资源的消耗过高,相比于Logstash,Beats所占用的CPU和内存几乎可以忽略。
FileBeat属于Beats,是一个轻量型的日志采集器。目前Beats包括:Packagebeat(搜索网络流量数据)、Topbeat(搜集系统、进程和文件系统级别的CPU和内存使用情况等数据)、Filebeat(搜集文件数据)、Winlogbeat(搜集Windows事件日志数据)。
应用场景
大规模的日志进行搜索,进行分析。
假设前端nginx代理集群有5台,这上面都分布了nginx日志。突然当前时间点用户反馈网站访问不了,那我们就要去查看过滤出nginx日志http状态码为404,4xx,5xx的日志。
如果使用grep、awk进行操作,那就需要登录到5台机器上进行操作,然后对结果进行一个合并。这种情况就不适用于命令行工具去做分析和搜索,这种方法比较麻烦,效率低,日志量大,搜索慢。
对于这种情况,我们的日志就要进行集中化管理,集中化分析。
ELK提供了一整套的解决方案,并且都是开源的软件,软件之间相互配合使用,高效的满足了很多场合的使用。当前主流的一种日志系统。
收集:能够采集多种来源的日志数据
传输:能够稳定的把日志数据传输到中央系统
存储:如何存储日志数据
分析:可以至此UI分析
警告:能够提供错误报告,监控机制
ELK官方网站:https://www.elastic.co/cn/elastic-stack/

ELK架构

首先由Logstash分布于各个节点上搜集相关日志、数据,并经过分析、过滤后发送给远端服务器上的Elasticsearch进行存储。
Elasticsearch将数据以分片的形式压缩存储并提供多种API供用户查询,操作。用户亦可以更直观的通过配置Kibana Web方便的对日志查询,并根据数据生成报表。
架构二
加入了消息队列机制。位于各个节点上的Logstash Agent首先将数据/日志传输给Kafka(或者Redis)。
然后将队列中消息或数据间接传递给Logstash,Logstash过滤分析之后将数据传输给Elasticsearch进行存储。
最后再由Kibana将日志和数据呈现给用户。
优点:引入了Kafka(或redis),使得远端的Logstash server因为故障停止运行之后,数据会先被存储下来,从而避免数据的丢失。
















 2135
2135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











