









Prometheus监控docker容器
Prometheus简介
说起当下很火的云原生,就不得不提docker和k8s,docker也是现在很多企业都要求会的技术,那么多docker容器怎么知道出没出问题呢?怎么对他们进行监控呢?Prometheus可以较好的解决这些问题,为什么不用zabbix或者其他监控系统呢?至于为什么请往下看
Prometheus是一款开源的监控系统,他的诞生的灵感来自于Google的监控系统Brogmon,这里也说一下我们熟悉的kubernetes(k8s)也是从Google的Brog系统演变而来,早在2012年开始Google就在Soundcloud以开源软件的形式进行研发了,并在2015年对外发布早期版本,在2016年的5月继kubernetes之后第二个加入CNCF基金会的项目,在同年六月发布了1.0版本
Prometheus特点及组件
Prometheus特点
- 多维度数据模型(基于时间序列的key、value键值对)
- 灵活的查询和聚合语言promQL
- 可以直接在本地存储,不依赖其他的分布式存储
- 通过http的pull模型采集时间序列数据
- 可以通过pushgateway(Prometheus的可选中间件)实现push模式
- 可通过动态服务发现或静态配置发现目标服务器
- 支持多种图表和仪表盘,结合grafana
- 可以做高可用,对数据做异地备份。
Prometheus的组件
- Prometheus server,负责拉取、存储时间序列数据,简单来说就是搜集数据的
- client library(客户端库),检测应用程序代码,当Prometheus抓取实列的http端点时,客户端库会将所有跟踪的metrics指标的当前状态发送到Prometheus server端。
metric数据指的是从服务端上获取到的指标数据的统称。metrics指标为时间序列数据,这些数据按相同的时序,以时间维度来存储连续数据的集合。
metric的时序数据分为gauge(仪表盘),counter(计数器),histogram(直方图)。
- push gateway(推送网关),各个目标主机可以上报数据到push gateway,然后Prometheus server统一从push gateway拉取数据。支持短暂的任务(Prometheus主动获取数据)
- alertmanager 处理报警的报警组件,从Prometheus server端收到alerts后,会进行去重,分组,并路由到相应接收方,发出报警,常用的接收方式有:微信,钉钉,slack,邮件等。
- adhoc 用于数据的查询
- exporter(常用) 暴露指标让任务抓取,通过exporter可以采集metrics数据,然后发送到Prometheus server端,所有向Prometheus server提供监控数据的程序都可以被称为exporter。
Prometheus架构
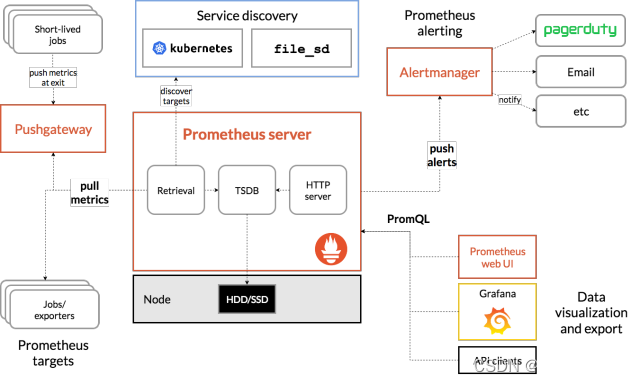
说一下下图的主要组件:
- retrieval负责在活跃的target主机上抓取监控指标数据
- storage存储主要是把采集到的数据存储到磁盘中
- promQL是Prometheus提供的查询语言模块
Prometheus工作流程
- Prometheus server可定期从活跃的目标主机上(target)拉取监控指标数据,目标主机的监控数据可通过配置静态job或者服务发现的方式被Prometheus server采集到,这种方式默认的pull返回时拉取指标; 也可以通过push gateway把采集的数据上报到Prometheus server中;还可以通过一些组件自带的exporter采集相应组件的数据;
- Prometheus server把采集到的监控指标数据保存到本地磁盘或者数据库;
- Prometheus 采集的监控指标数据按时间序列存储,通过配置报警规则,把触发的报警发送到Alertmanager
- Alertmanager通过配置报警接收方,发送报警到邮件,微信或者钉钉等
- Prometheus自带的web ui界面提供promQL查询语言,可查询监控数据
- grafana可接入Prometheus数据源,把监控数据以图形化形式展示出来
Prometheus为什么适合监控容器
首先Prometheus的可扩展性很强,从上面的架构图也可以看出来,Prometheus拥有很多的组件,而Prometheus的原理是通过HTTP协议进行周期性抓取被监控组件的状态,这样就表示只要组件提供HTTP接口就可以接入监控系统,其次Prometheus是pull模型采集的也就是Prometheus服务端主动取拉取数据,各个被监控的源只需要将自身指标暴露在本地http端口即可,这样就可以通过访问接口来采集指标。
Prometheus部署
环境说明:
系统:centos7
[root@prometheus ~]# mkdir /prometheus/
[root@prometheus ~]# docker run -d --name test -p 9090:9090 prom/prometheus
[root@prometheus ~]# docker cp test:/etc/prometheus/prometheus.yml /prometheus
[root@prometheus ~]# docker stop test
[root@prometheus ~]# docker rm test
// 输入IP:9090,看到如下页面说明成功,因为没有添加监控项所以这里没有内容
部署docker
// 所有主机都要部署
[root@prometheus ~]# yum -y install yum-utils
[root@prometheus ~]# yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
[root@prometheus ~]# sed -i 's+download.docker.com+mirrors.aliyun.com/docker-ce+' /etc/yum.repos.d/docker-ce.repo
[root@prometheus ~]# yum -y install docker-ce
[root@prometheus ~]# systemctl enable --now docker.service
部署node-exporter用于搜集硬件和系统信息
// 全部主机都要做
docker run -d -p 9100:9100 -v /proc:/host/proc -v /sys:/host/sys -v /:/rootfs --net=host prom/node-exporter --path.procfs /host/proc --path.sysfs /host/sys --collector.filesystem.ignored-mount-points "^/(sys|proc|dev|host|etc)($|/)"
--web.listen-address 9100 //默认使用9100端口号
--path.rootfs:node-exporter使用/host前缀访问主机文件系统
--collector.filesystem.ignored-mount-points:忽略访问的文件
--net=host:代替端口映射,如容器有80,需要访问的话就需要加-p选项,不想的话加--net=host就可以直接访问80
浏览器IP:9100/metrics
部署cAdvisor,用于搜集容器节点信息
// 所有主机都要做
docker run -v /:/rootfs:ro -v /var/run:/var/run/:rw -v /sys:/sys:ro -v /var/lib/docker:/var/lib/docker:ro -p 8080:8080 --detach=true --name=cadvisor --net=host google/cadvisor
--detach=true 是否在后台运行容器true为后台运行,false反之
浏览器IP:8080/containers

配置Prometheus服务
[root@prometheus prometheus]# tail -9 prometheus.yml
- targets: ["localhost:9090","localhost:9100","localhost:8080"]
- job_name: "node1"
static_configs:
- targets: ["192.168.182.131:9100","192.168.182.131:8080"]
- job_name: "node2"
static_configs:
- targets: ["192.168.182.132:9100","192.168.182.132:8080"]
// 重启服务
[root@prometheus prometheus]# docker restart Prometheus
浏览器IP:9090
// 看到如下界面说明监控成功

部署grafana服务,对Prometheus做优化
[root@prometheus ~]# mkdir /grafana/
[root@prometheus ~]# chmod 777 -R /grafana/ //这一步很重要
docker run -d -p 3000:3000 --name grafana -v /grafana/:/var/lib/grafana -e "GF_SECURITY_ADMIN_PASSWORD=passwd" grafana/grafana
在docker-monitor目录下新增grafana目录,在里面创建文件config.monitoring,内容如下
GF_SECURITY_ADMIN_PASSWORD=admin #grafana管理界面的登录用户密码,用户名是admin
GF_USERS_ALLOW_SIGN_UP=false #grafana管理界面是否允许注册,默认不允许
浏览器IP:3000,用户名admin,密码passwd
// 添加数据源
// 点击添加
// 选择Prometheus数据源
// 连接Prometheus
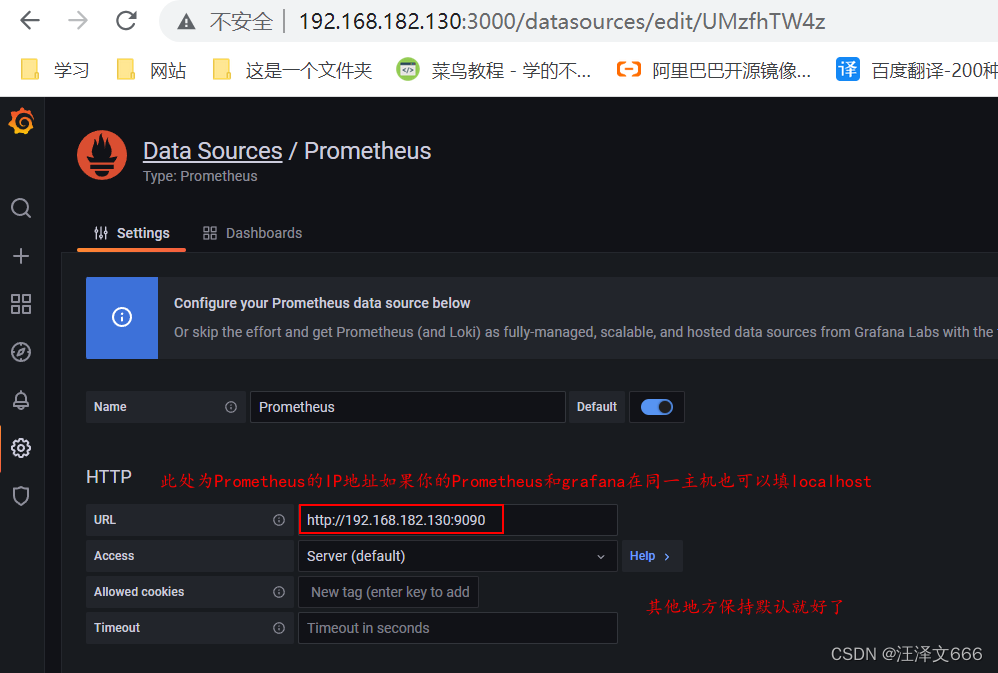
// 点击save&test,出现绿色的勾说明添加成功
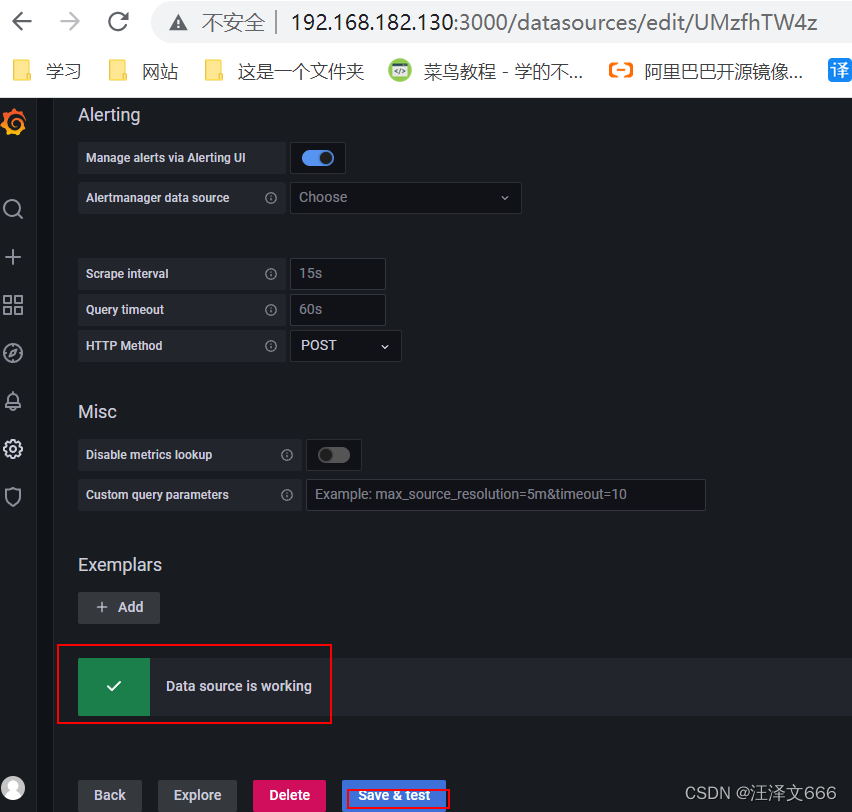
// 使用grafana提供的模板来进行优化界面
模板下载地址
可通过下面两种方式获得模板
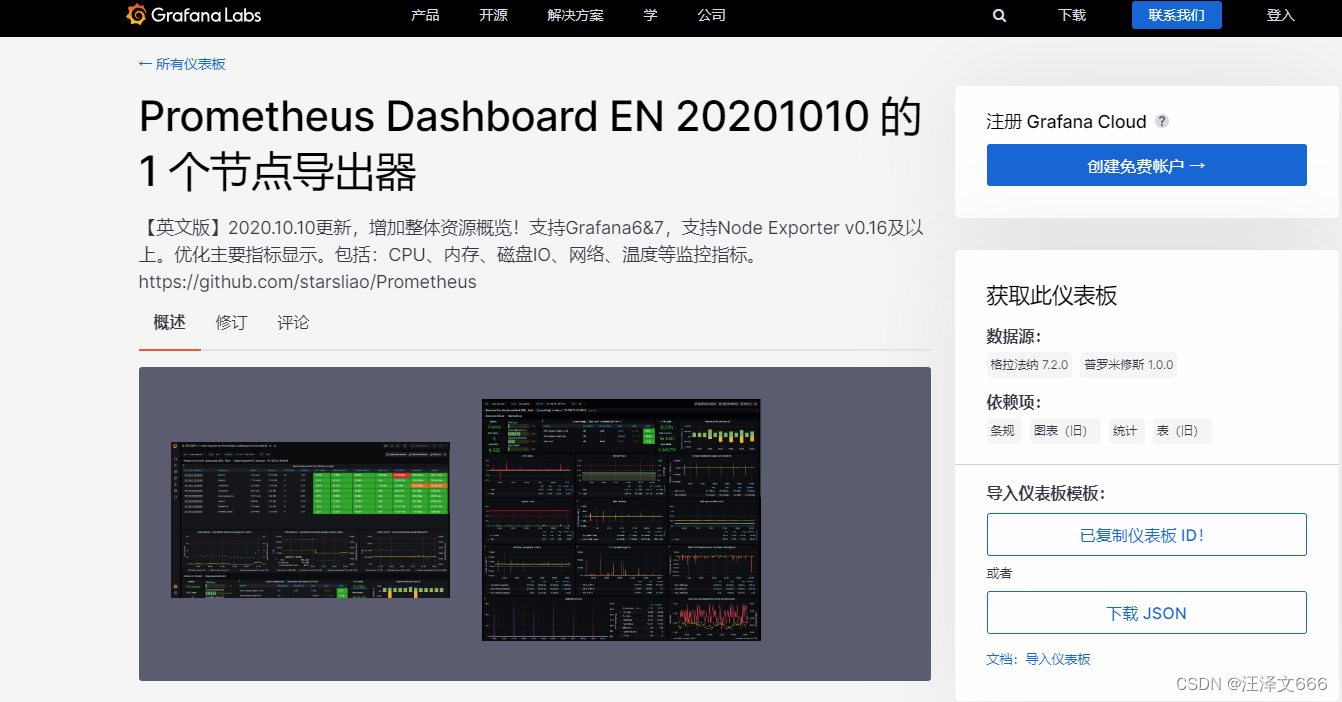
有两种方式使用模板
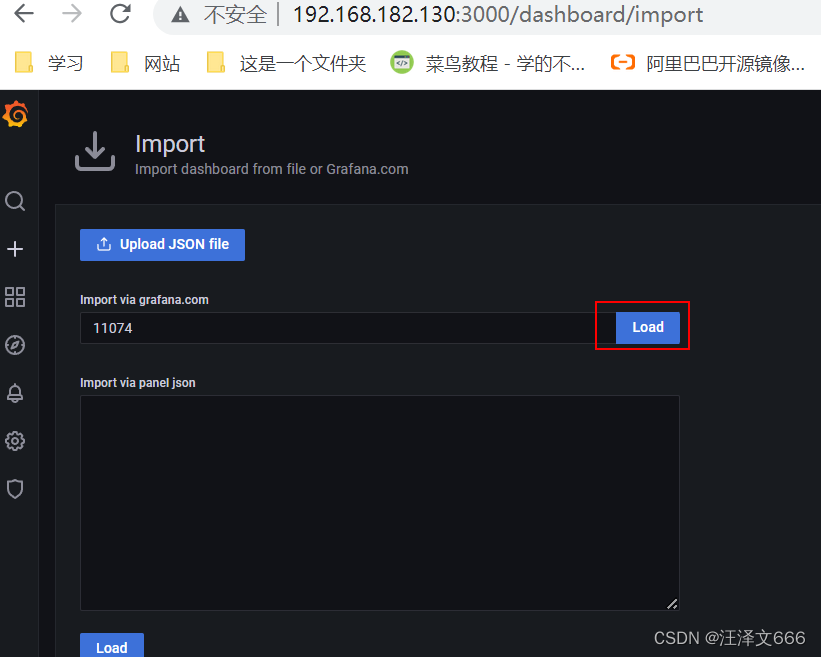
1 通过模板的id号进行导入
2将模板下载到本地再进行导入
// 导入模板
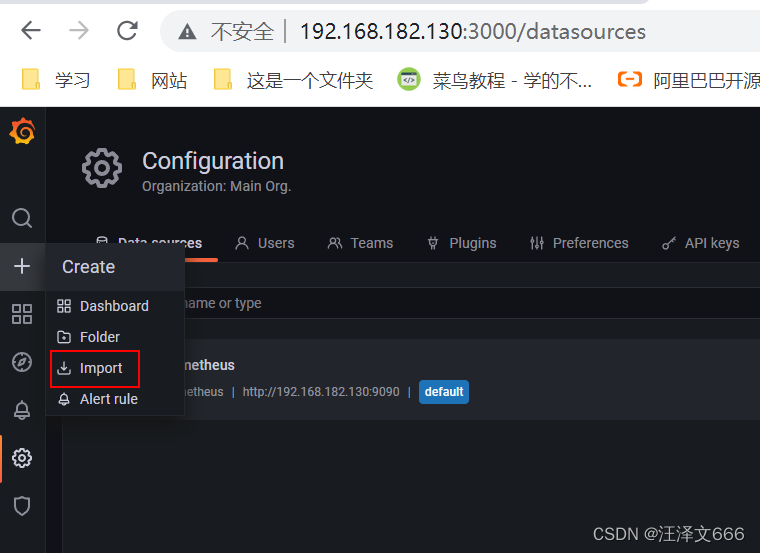

// 通过id添加模板,点击load
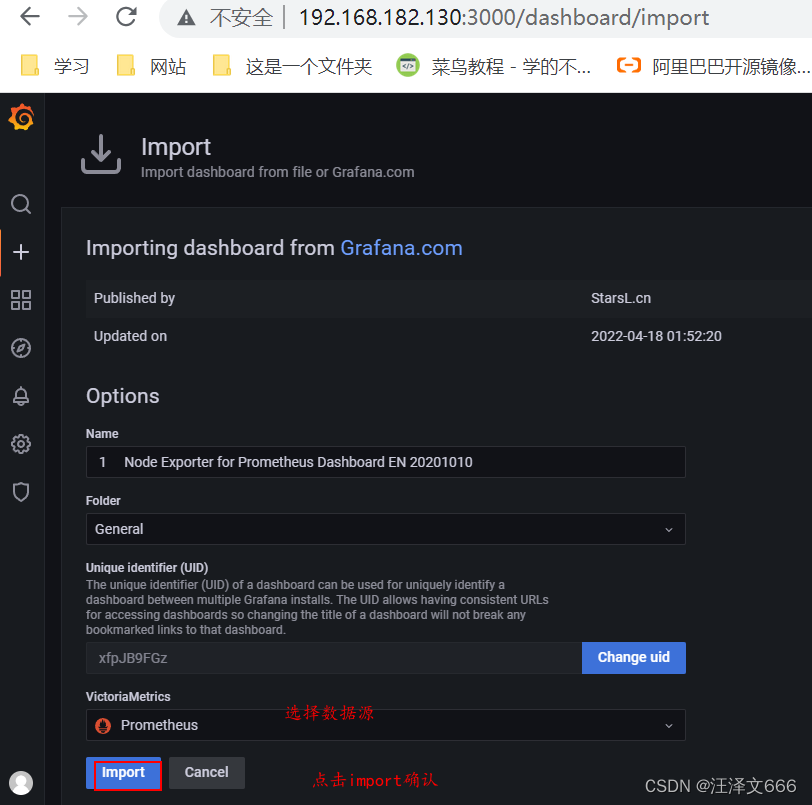
// 最后呈现的效果
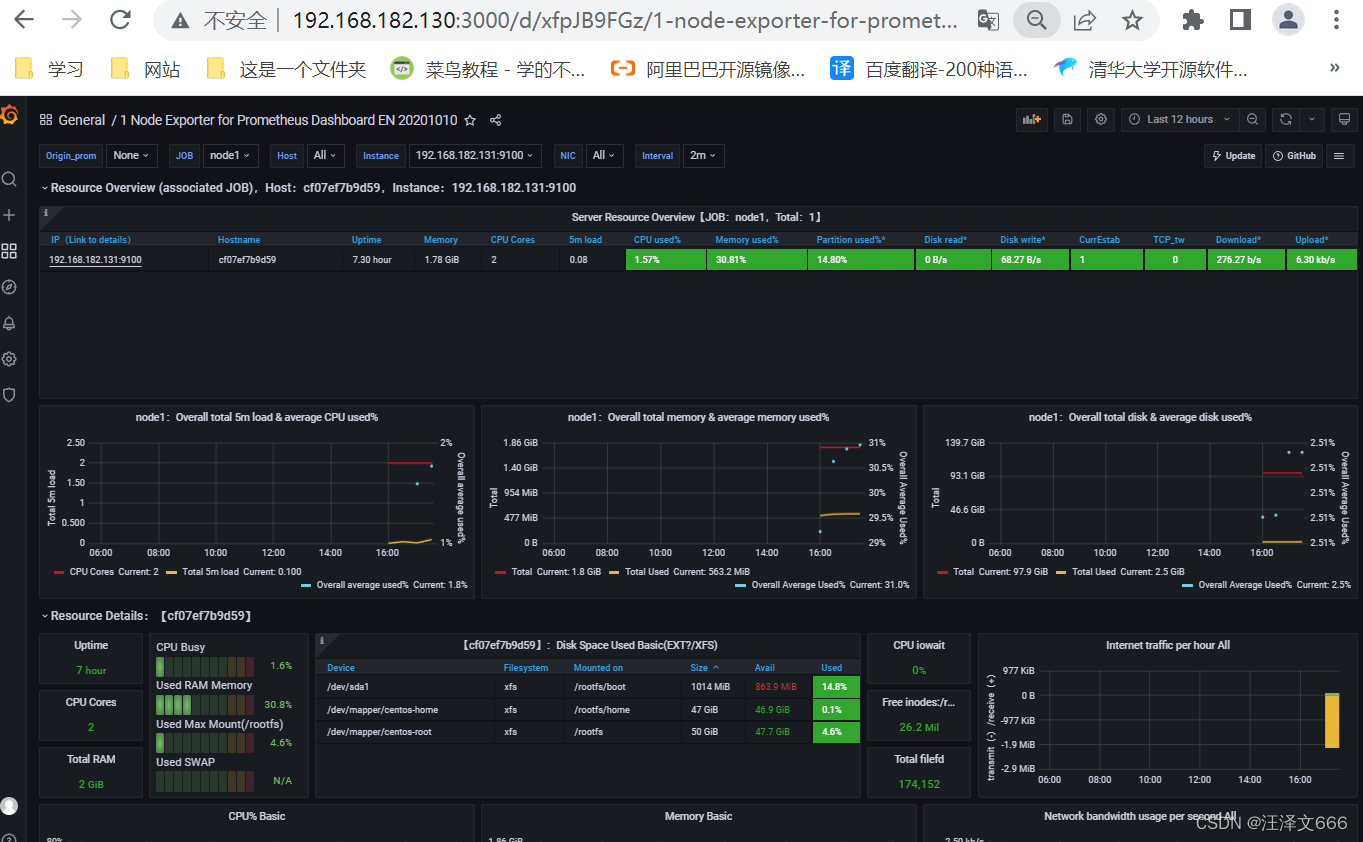
// 因为我们要看的是容器的信息,所以找一个和容器相关的模板导入。
//通过关键字搜索相关模板
// 可以看到这里有两个容器的运行状态
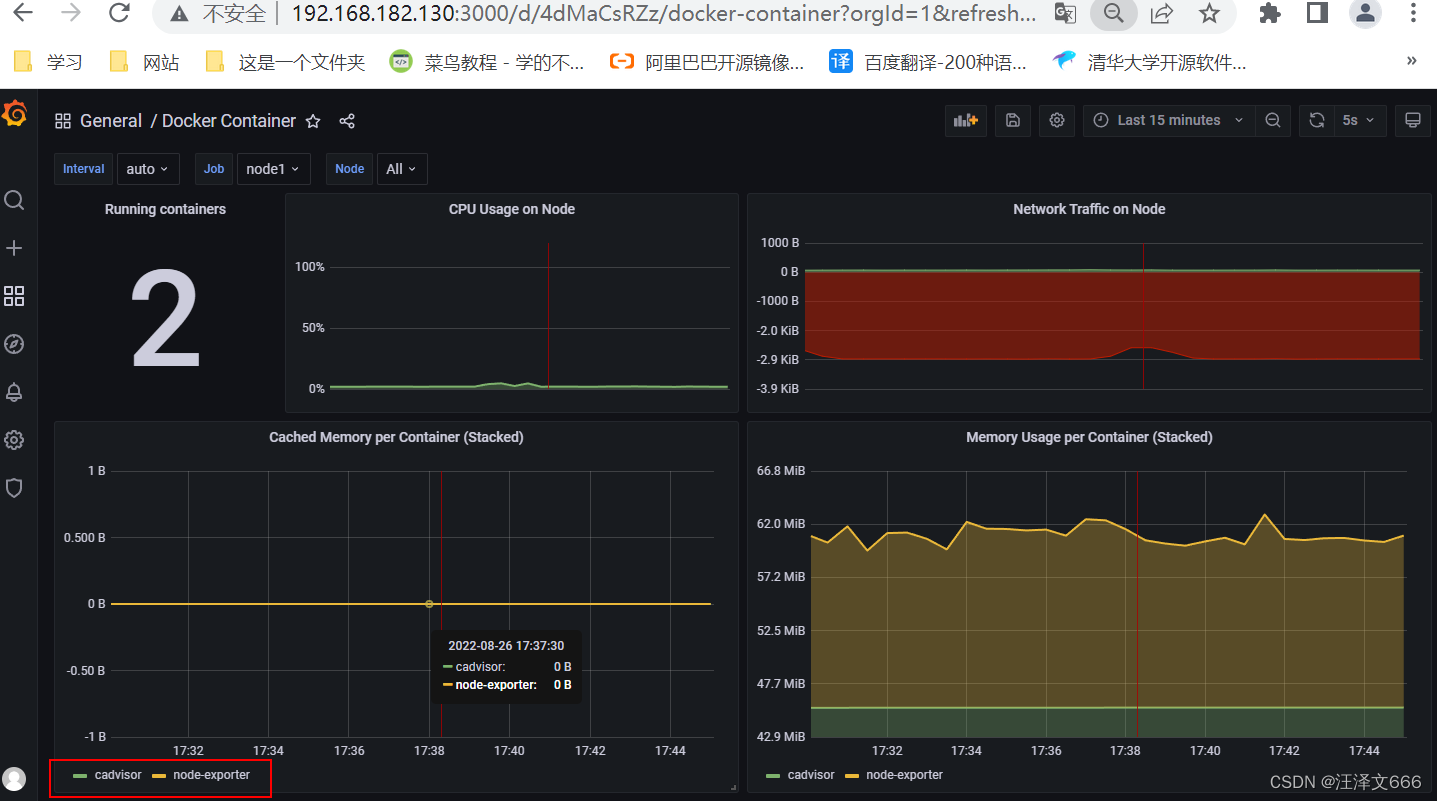
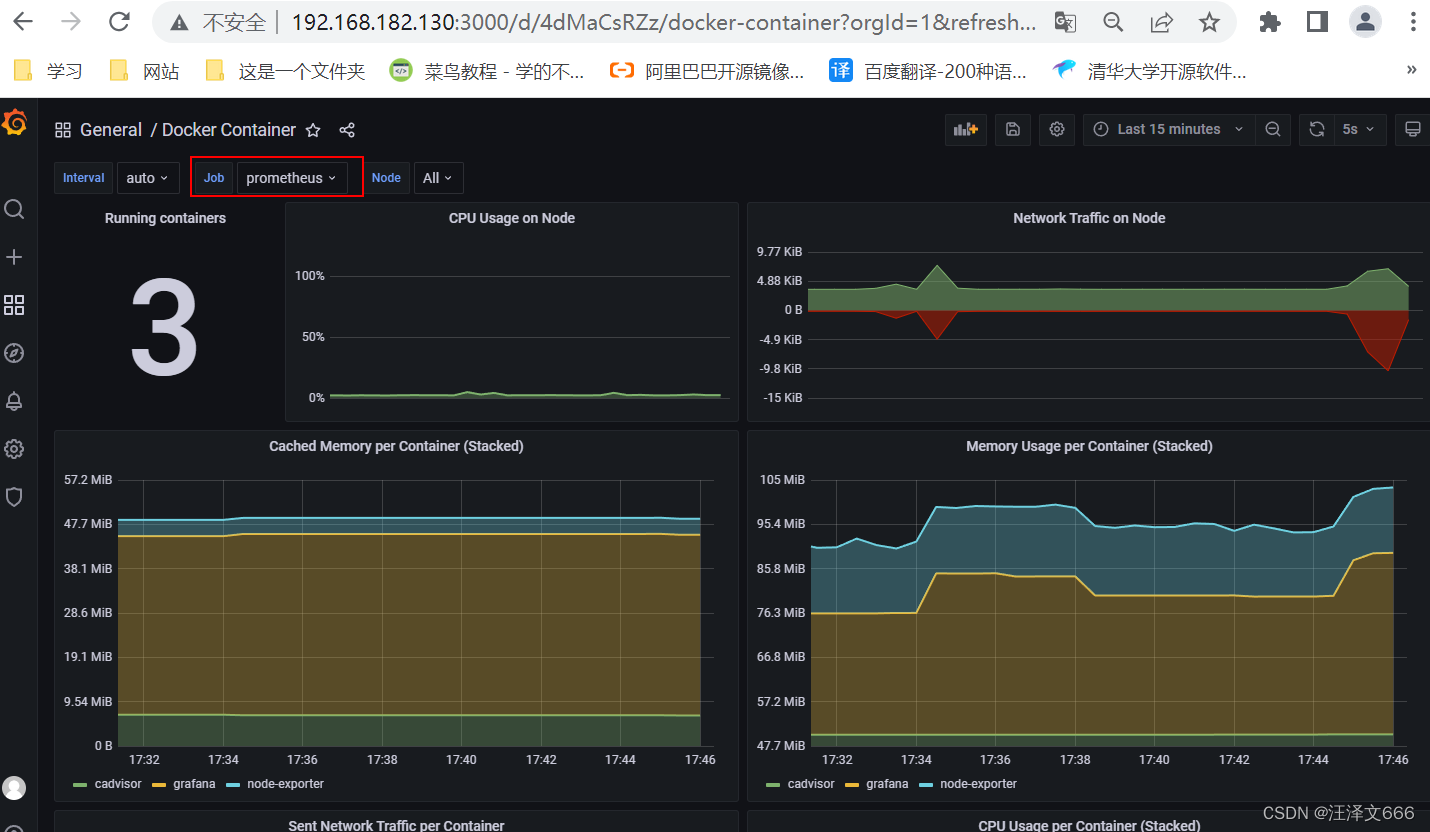
// 可以选择查看不同节点上的容器,上图是node1节点上的容器,下图是Prometheus上的容器
配置Alertmanager报警
启动AlerManager来接受Prometheus发送的报警信息,并执行各种方式报警。
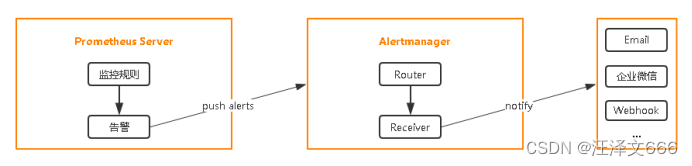
流程如下:
- Prometheus收集到检测的信息
- 根据Prometheus.yml文件定义的rules文件,rules里包括了告警信息
- Prometheus把报警信息push给alertmanager,通过alertmanager配置文件里面定义收件人和发件人
- alertmanager发送文件给邮箱或微信
告警等级
- Inactive:什么都没发生。
- pending:触发了阈值,但是未满足告警持续时间,也就是for字段
- firing:已触发阈值且满足告警持续时间。警报发送给接收者
[root@prometheus ~]# mkdir /alertmanager //创建一个数据目录
[root@prometheus ~]# docker run -d --name test -p 9093:9093 prom/alertmanager //创建容器用来获得alertmanager.yml配置文件
[root@prometheus ~]# docker cp test:/etc/alertmanager/alertmanager.yml /alertmanager/
// 浏览器IP:9093,看到下面的页面表示成功,但是因为没有设置任何报警信息所以没有数据
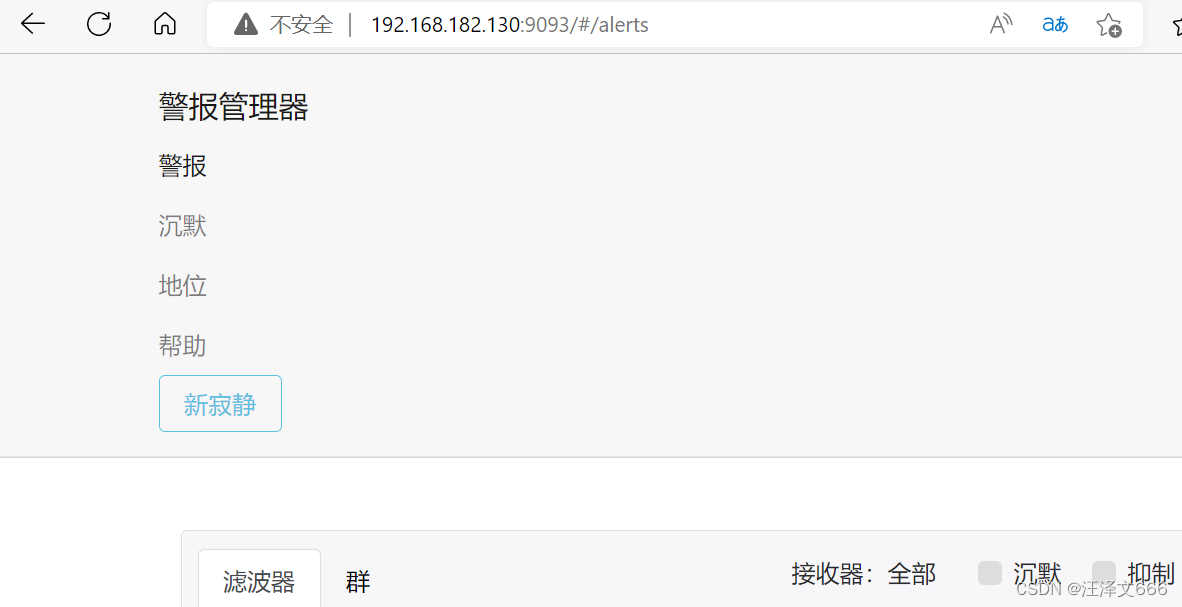
这里说一下配置文件中几个重要的参数
- global:全局配置,包括报警解决后的超时时间、SMTP相关配置、各种渠道通知的API地址等
- route:用来设置报警的分发策略,它是一个树状结构,按照深度优先从左向右的顺序进行匹配。
- receivers:配置告警消息接受者信息,例如常用的email、wechat、slack、webhook等消息通知方式
- inhibit_rules:抑制规则配置,当存在与另一组匹配的警报(源)时,抑制规则将禁用与一组匹配的报警(目标)。
配置邮箱报警

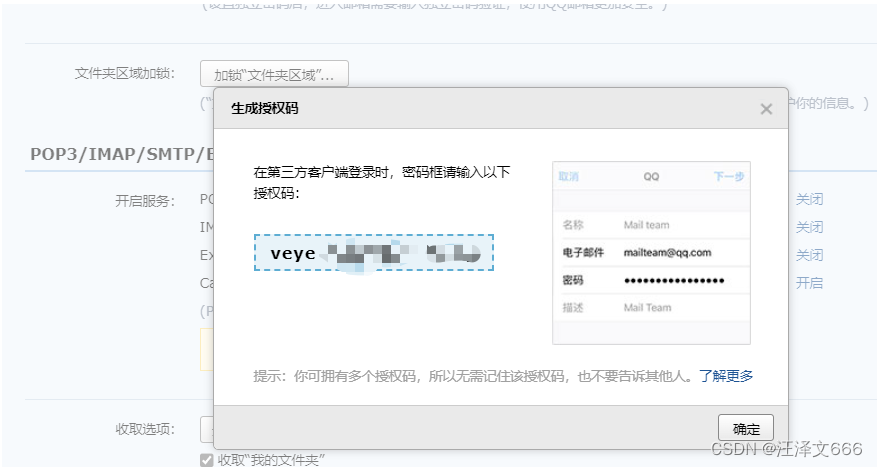
// 开启POP3/SMTP服务并生成授权码

// 生成授权码
配置alertmanager.yml文件
[root@prometheus ~]# docker stop test
[root@prometheus ~]# docker rm test
[root@prometheus ~]# docker run -d -p 9093:9093 --name alertmanager -v /alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml prom/alertmanager
// alertmanager.yml文件内容

配置Prometheus部分
修改Prometheus.yml的alerting部分,让alertmanager能与Prometheus通信
[root@prometheus rules]# pwd
/prometheus/rules
[root@prometheus rules]# ls
node-up.rules
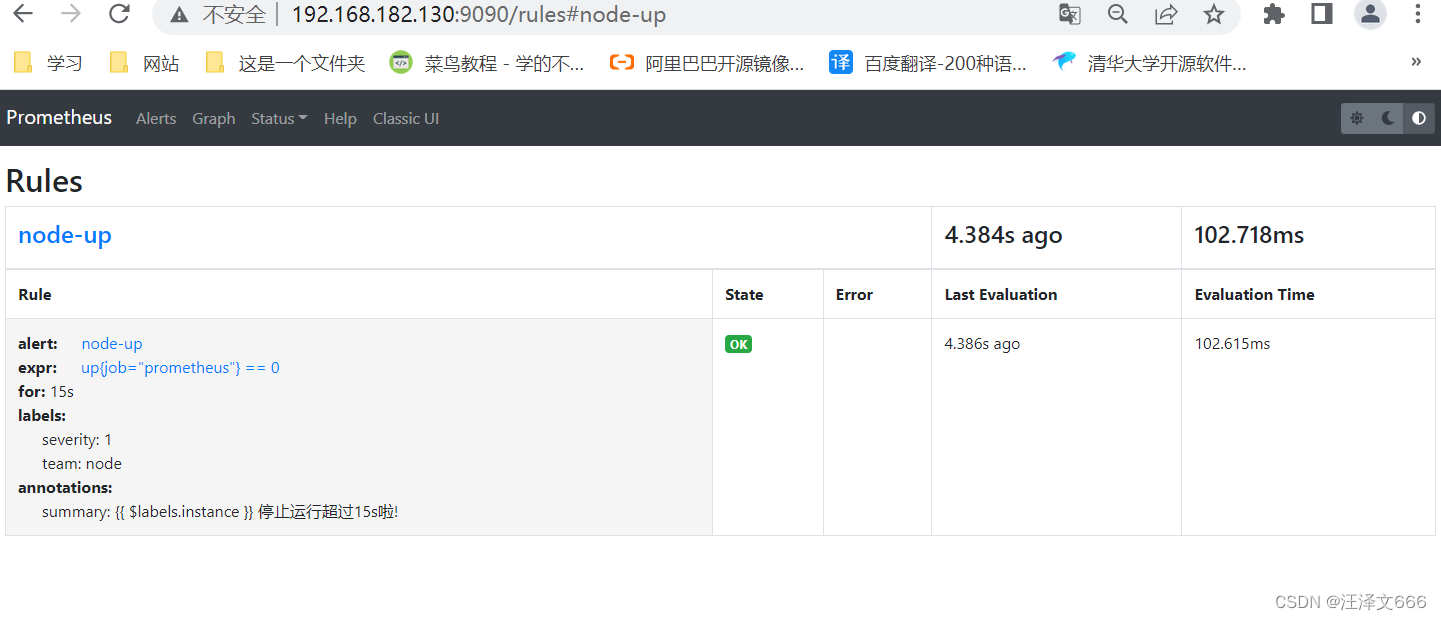
[root@prometheus rules]# vim node-up.rules
groups:
- name: node-up
rules:
- alert: node-up
expr: up{job="prometheus"} == 0 //这个是在Prometheus.yml里面设置的job_name
for: 15s
labels:
severity: 1
team: node
annotations:
summary: "{{ $labels.instance }} 停止运行超过15s啦!"
[root@prometheus prometheus]# pwd
/prometheus
[root@prometheus prometheus]# ls
prometheus.yml rules
[root@prometheus prometheus]# head -17 prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.182.130:9093
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "/usr/local/prometheus/rules/*.rules"
rule_files为容器内路径,需要将本地node-up.rules文件挂载到容器指定的路径。
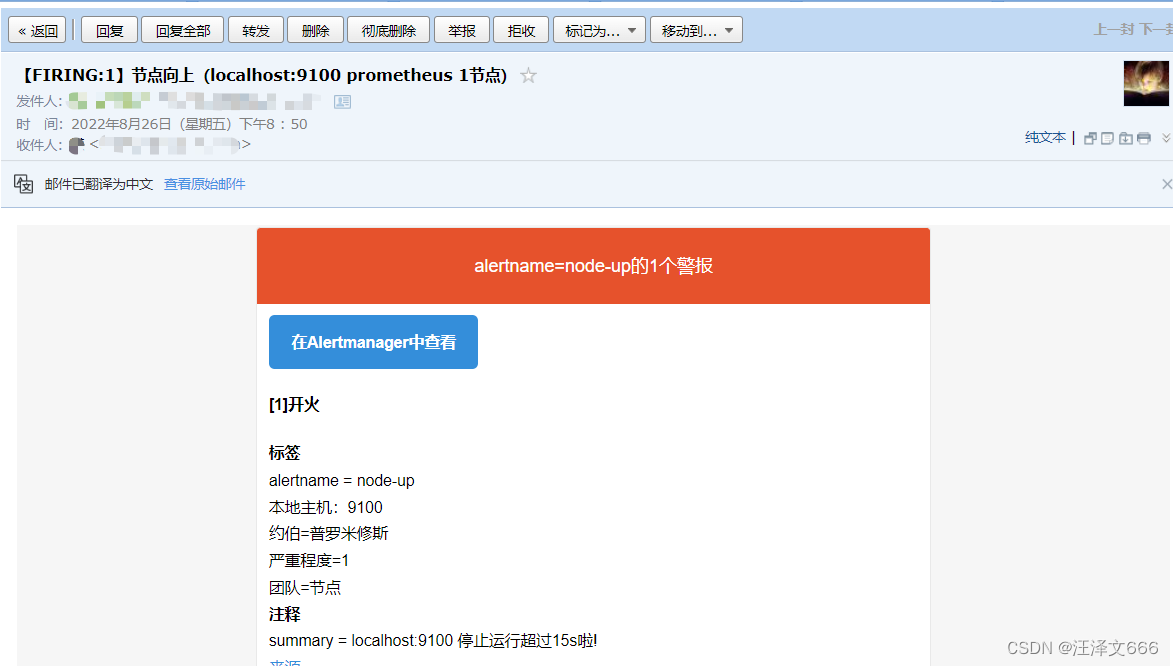
// 随便关闭一个服务模拟故障
[root@prometheus prometheus]# docker stop node-exporter
node-exporter
Alertmanager自定义邮件报警
创建alertmanager的模板文件
[root@prometheus alertmanager]# pwd
/alertmanager
[root@prometheus alertmanager]# mkdir template
[root@prometheus alertmanager]# cd template/
[root@prometheus template]# vim email.tmpl
{{ define "email.from" }}572635840@qq.com{{ end }}
{{ define "email.to" }}572635840@qq.com{{ end }}
{{ define "email.to.html" }}
{{ range .Alerts }}
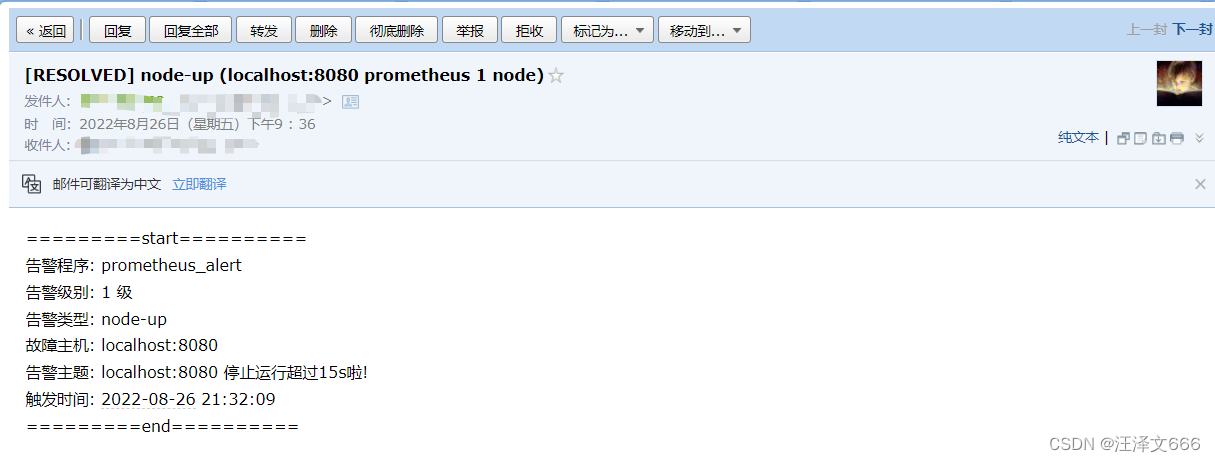
=========start==========<br>
告警程序: prometheus_alert<br>
告警级别: {{ .Labels.severity }} 级<br>
告警类型: {{ .Labels.alertname }}<br>
故障主机: {{ .Labels.instance }}<br>
告警主题: {{ .Annotations.summary }}<br>
触发时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>
=========end==========<br>
{{ end }}
{{ end }}
// 修改alertmanager文件

[root@prometheus alertmanager]# docker stop alertmanager
[root@prometheus alertmanager]# docker rm alertmanager
[root@prometheus alertmanager]# docker run -d --name alertmanager -p 9093:9093 -v /alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml -v /alertmanager/template:/etc/alertmanager-tmpl prom/alertmanager
// 重启测试alertmanager
[root@prometheus alertmanager]# docker restart alertmanager















 229
229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









