








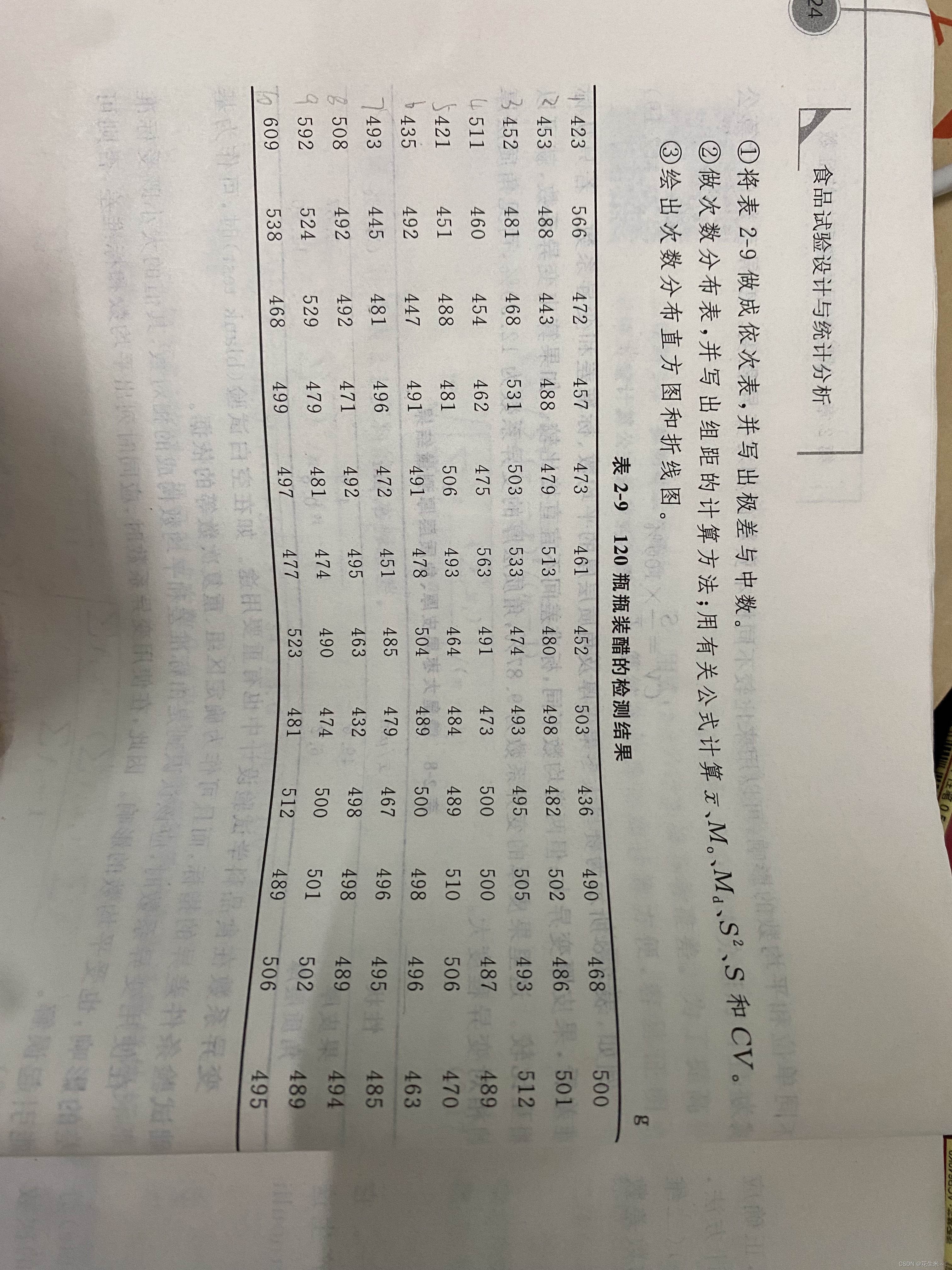
MATLAB,代码:
首先可以用QQ识别出我们的表格中的数据,将其复制到Excel中,然后将其命名为pingzhuangcu.xlsx 并放入matlab文件夹中,我这里分的是10组,从411.5开始。
%%
%导入数据
clc;clear all %清除所有
data = xlsread('pingzhuangcu.xlsx');
%%
%第一题
DATA=data(:)%整理为一列数据
A=sort(DATA(:, 1));%排序
yicibiao=reshape(A,10,12)%按照10*12做依次表
jicha=range(A)%计算极差
zhongweishu=median(A)%计算中数
%%
%第二题
B={};jizhongzhi=[];zuxiaxian=[];
zuju=jicha/10;
%组距=极差(全距)/分组数(查表2-2样本含量与分组数,可得分组数10)
zuju=round(zuju);%将组距取整
B{1,11}=[];%创建元胞组
zu=1;%设定初始值,即第1组
ki=zu-1;%方便表示以下循环的下限
while zu<=11%共11组
ki=zu-1;
B{1,zu}=find(A>=(411.5+zuju*ki)&A<(411.5+zuju*zu));%找出元素个数
B{1,zu}=A(B{1,zu});%分类整理
B(cellfun('isempty',B)) = {0};jizhongzhi(:,zu)=(max(B{1,zu})+min(B{1,zu}))/2;
zuxiaxian(zu,:)=411.5+zuju*ki;
zu=zu+1;
end
i=1;n=[];
while i<=11
B{i}
n(1,i)=length(ans)
i=i+1
end
cishu=n(:);
jizhongzhi2=jizhongzhi(:);
cishufenbubiao=[zuxiaxian,jizhongzhi2,cishu]%次数分布表
average=mean(A)%平均值x拔
%Mo—众数
[max66,xiabiao]=max(cishu);
l=cishufenbubiao(xiabiao,1)%第一列内找次数最多组的下限
f1=sum(cishu(1:(xiabiao-1),:));
f2=sum(cishu(1:(xiabiao+1),:));
Mo=l+(f1/(f1+f2))*zuju;
%S^2—样本方差
Spingfang=var(A,0);
%S—标准差
Sbiaozhun=std(A,0);
%CV-变异系数
CV=Sbiaozhun/average*100;
%%
%第三题
%绘图1直方图
figure(1);
b=411.5:19:650.5
%[r,t]=hist(A,b);
edges = [411.5:19:650.5];
h = histogram(A,edges);
x1 = h.BinEdges; % 横坐标值
y1 = h.Values; % 纵坐标值
x = (x1(2:end) + x1(1:end-1))/2 - 1.5;
y = y1 + 1.5;
for i = 1:length(y)
text(x(i),y(i),num2str(y1(i)));
end
axis([410 620 0 56])%设定显示范围,高度
grid on;
title('120瓶醋单听质量直方图');
xlabel('组限'),ylabel('次数') ;
%绘图2折线图
figure(2);
zhexianjizhong=jizhongzhi;
x=zhexianjizhong;
y=n;
plot(x,y,'b-*','LineWidth',1.5);
xlabel('组中值','FontSize', 11);
ylabel('次数','FontSize', 11);
title('120瓶醋单听质量折线图');
labels = string(y); % 将数值转换为字符串
x_offset = 0; % x方向偏移量
y_offset = 2; % y方向偏移量
text(x+x_offset, y+y_offset,num2str([x;y].','(%.1f,%.0f)'),'Color','black','FontSize',11);
grid on;运行后得到结果
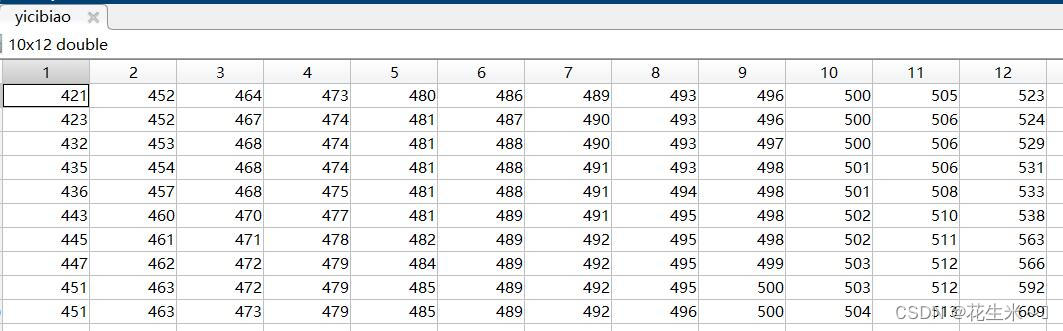
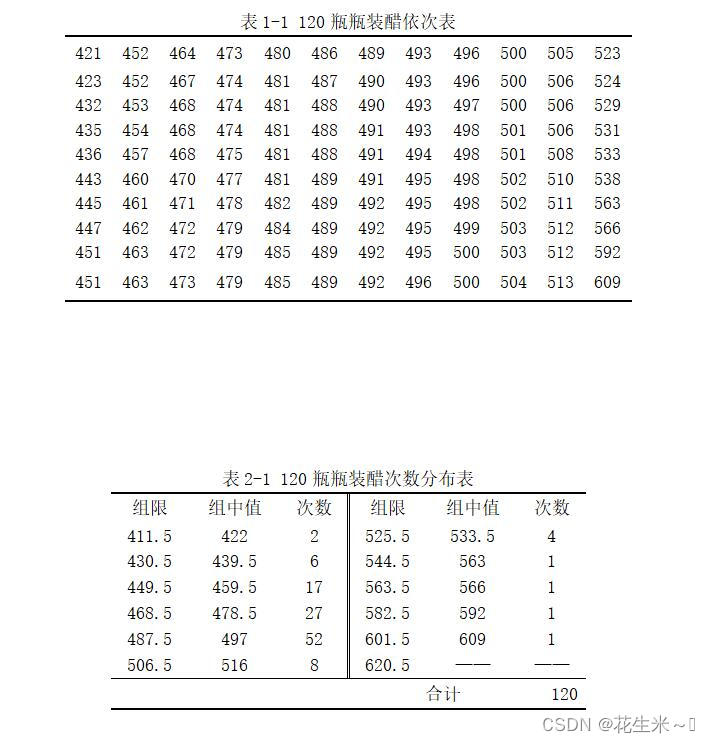
依次表:
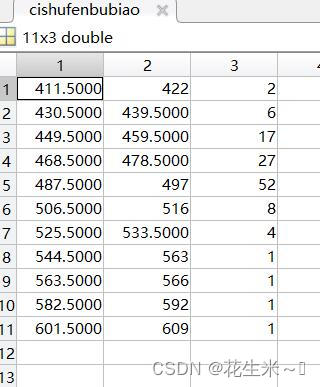
次数分布表以及第二题部分所算数据(还差个Md):
整理依次表和次数分布表可以更美观:
第三题:直方图

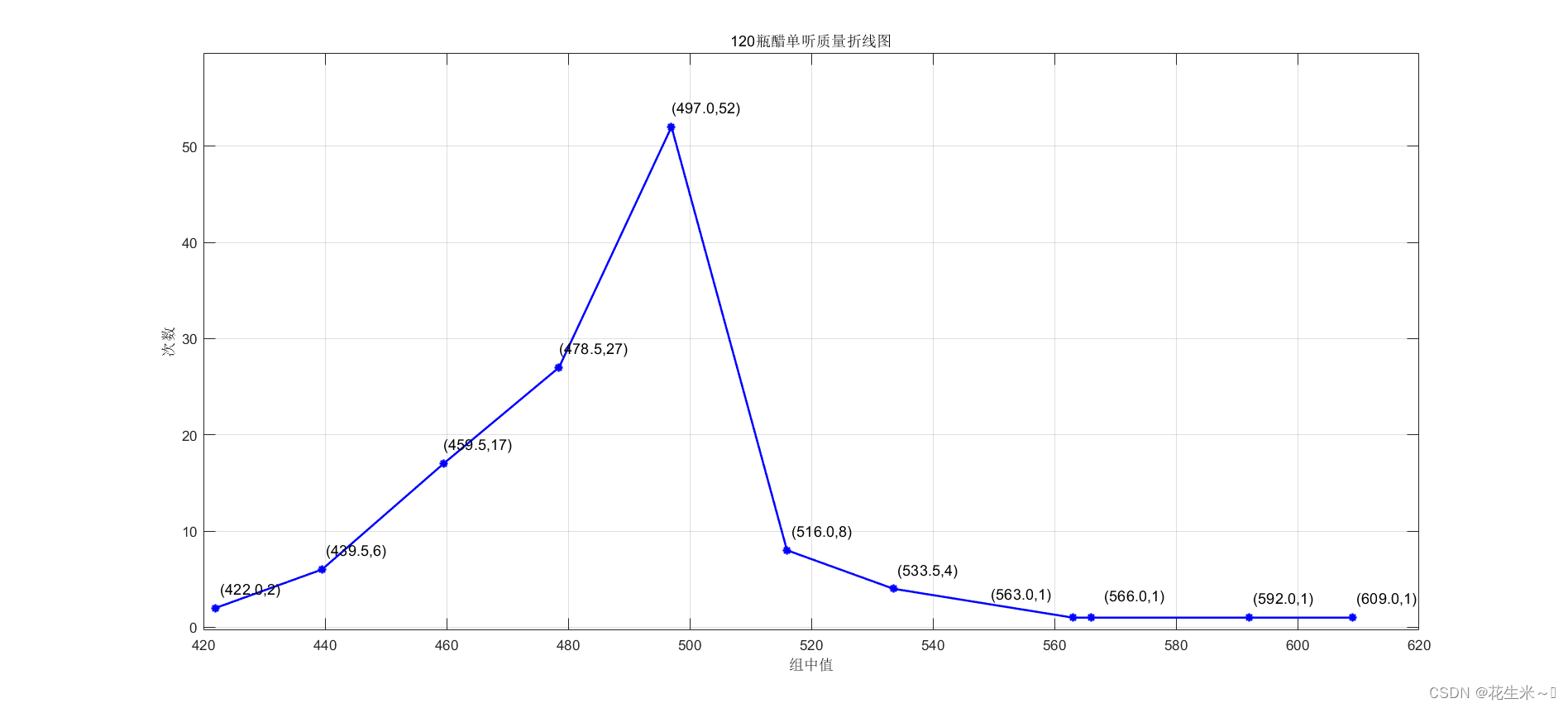
第三题:折线图


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









