







 超级会员免费看
超级会员免费看
1.创新点分析
概述
本文介绍了一个改进版 Vision Transformer (ViT) 的实现。
该实现通过引入 Channel Prior Convolutional Attention (CPCA) 模块来增强模型的特征提取能力。代码结合了标准的 ViT 架构和创新的注意力机制,在保持 Transformer 优势的同时,融入了卷积神经网络的局部感知特性。
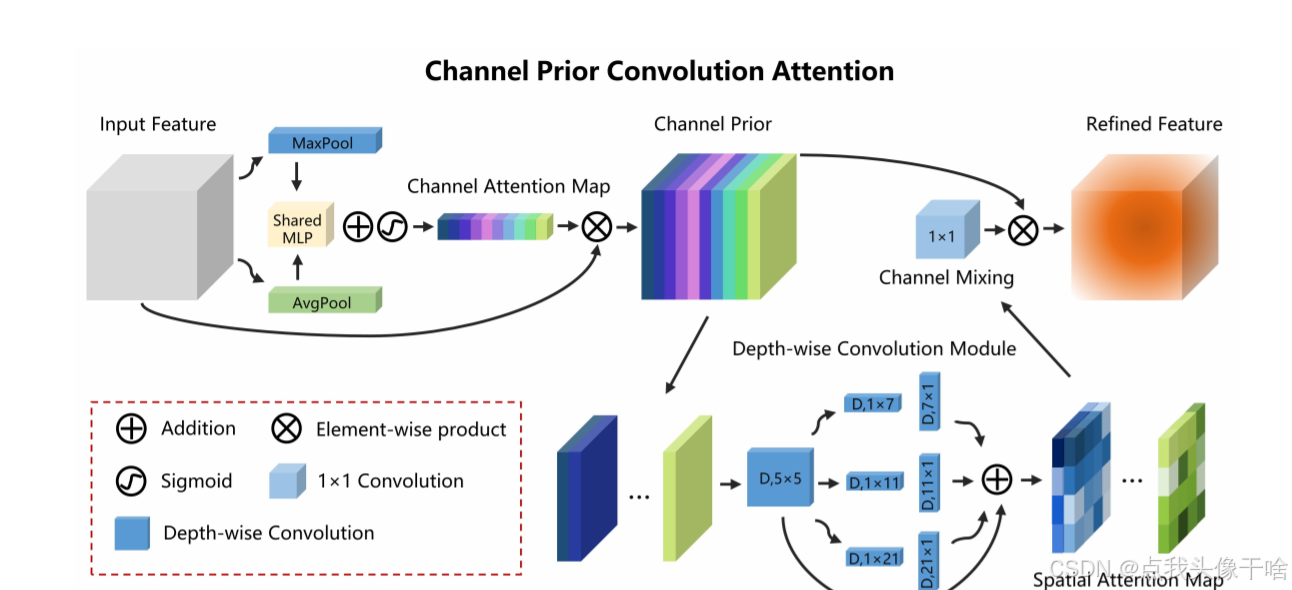
代码结构
整个实现包含三个主要部分:
CPCA模块 - 自定义的注意力机制ViTWithCPCA类 - 将 CPCA 集成到 ViT 中的包装器get_model函数 - 模型构建的便捷接口
CPCA 模块详解
class CPCA(nn.Module):
"""Channel Prior Convolutional Attention module"""
def __init__(self, channels, reductio
 订阅专栏 解锁全文
订阅专栏 解锁全文



















 325
325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











