






目录
数据库简介
数据库相关概念
DB(database):数据库
DBMS(database management system):数据库管理系统
DBA(database administrator):数据库管理员
SQL(structured query language):结构化查询语言
软件的使用
软件登录
-
命令行打开:Windows+r->输入cmd->输入mysql -uroot -p123456
-
软件打开:Windows->MySQL->输入密码
退出
exit
quit
\q
数据库管理常用命令
显示数据库的命令:show database
使用数据库的命令:use 数据库名
查询当前数据库的信息
查询当前连接的数据库:select database()
查询当前的数据库版本:select version()
查询当前的日期:select now()
查询当前的用户:select user()
数据库基本操作
-
创建数据库:在系统盘上划分一块区域用于数据库的存储和管理
create database [if not exists] 数据库名;-
删除数据库:将已经存在的数据库清除,数据库中的数据也会被清除
drop database [if exists] 数据库名-
导入数据库脚本
source脚本文件路径
#语句后面不加分号,导入数据之前要选择创建好的数据库,脚本路径不含中文-
显示数据库中的表
show tables;基本查询
-
查询指定字段
select 字段名1[,字段名2,....] from 表名;
-
查询全部字段
select * from 表名;
-
条件查询:条件查询使用where语句,where必须写在from的后面
select * from emp where 条件;
-
算术运算符:

-
比较运算符:
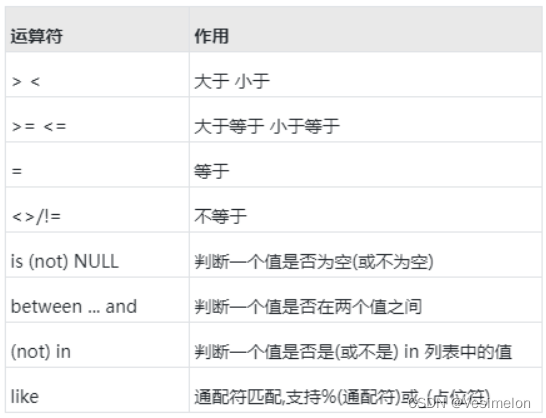
-
逻辑运算符:

&& 、|| 、 !
表
数据类型
-
整型
| 数据类型 | 存储范围 | 字节 |
| TINYINT(s) | 有符号值:-128到127 无符号值:0-255 | 1 |
| SMALLINT(s) | 有符号值:-32768到32767 无符号值:0到65535 | 2 |
| MEDIUMINT(s) | 有符号值:-8388608到8388607 无符号值:0到16777215 | 3 |
| INT(s) | 有符号值:-2^31 ~ 2^31-1 无符号值:0~2^32-1 | 4 |
| BIGINT(s) | 有符号值:-2^63 ~ 2^63-1 无符号值:0~2^64-1 | 8 |
-
浮点型和定点型
| 数据类型 | 存储范围 |
| 浮点数类型:FLOAT[(M,D)] | 4个字节存储 -3.402823466E+38到-1.175494351E-38、0和1.175494351E-38到3.402823466E+38 |
| 浮点数类型:DOUBLE[(M,D)] | 8个字节存储 -1.7976931348623157E+308到-2.2250738585070214E-308、0到2.2250738585070214E-308到1.7976931348623157E+308 |
| 定点数类型 DECIMAL[(M,D)] | M是精度(=整数位数+小数位数),D是标度(小数点后的位数) |
-
日期时间类型
| 列类型 | 字节数 | 取值范围 | 表示形式 |
| YEAY | 1 | 1901~2155 | YYYY |
| TIME | 3 | -838:59:59~838:59:59 | HH:MM:SS |
| DATE | 4 | 1000-01-01~9999-12-31 | YYYY-MM-DD |
| DATETIME | 8 | 1000-01-01 00:00:00~9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS |
| TIMETAMP | 4 | 19700101080001~20380119111407 | YYYY-MM-DD HH:MM:SS |
-
字符型
| 列类型 | 存储需求 |
| CHAR(M) | 定长字符串,0<M<=255 |
| VARCHAR(M) | 变长字符串,0<M<=65535 |
| ENUM('VALUE1','VALUE2',...) | 取决于枚举值的个数(最多65535个值)例:性别 enum('男','女') |
| SET('VALUE1','VALUE2',...) | 取决于set成员的数目(最多64个成员 |
数据定义语言 - DDL
-
创建表
create table 表名(
字段名 字段类型,
字段名 字段类型,
,,,
字段名 字段类型
);
-
查看当前数据库表:show tables;
-
查看表的详细的结构语句:show create table 表名;
-
查看数据库表的基本结构:desc 表名;
-
删除表:drop table 表名;
-
修改表
-
修改表名:alter table 表名rename 新表名;
-
添加字段:alter table 表名 add 新字段名 字段类型;
-
删除字段:alter table 表名drop 字段名[,drop 字段名];
-
修改字段名:alter table 表名 change 字段名 新字段名 字段类型;
-
修改字段类型:alter table 表名 modify 字段名 字段类型;
-
修改字段的相对位置:alter table 表名 modify 字段名 字段类型 first|after 已经存在的字段名;
-
数据操纵语言-DML
-
insert 插入:insert into 表名(字段1,字段2,....) values(值1,值2,...);
-
update 修改:update 表名 set 表达式 where 条件;
-
delete 删除: delete from 表 where 条件;
约束 constraint
约束的类型
| 约束类型 | 非空约束 | 唯一约束 | 主键约束 | 默认约束 | 外键约束 |
| 关键字 | NOT NULL | UNIQUE | PRIMARY KEY | DEFAULT | FOREIGN KEY |
-
非空约束 not null
-
创建表时添加非空约束
-
create table 表名(
字段名 字段类型 not null,
.....
);-
通过修改字段类型添加非空约束: alter table 表名modify 字段名 字段类型 not null;
-
删除非空约束(修改字段类型方式):alter table 表名 modify 字段名 字段类型;
-
默认约束 default
-
创建表时添加默认约束
-
drop table if exists stu1;
create table if not exists stu1(
id int not null,
sname char(20) not null,
sage int default 18
);
-
修改表字段类型时添加默认约束
alter table 表名 modify 字段名 字段类型 default 默认值;
-
修改表修改字段时设置默认约束
alter table 表名 alter 字段名 set default 默认值;-
删除默认约束(修改字段类型)
alter table 表名 modify 字段名 字段类型;-
唯一约束 unique
-
创建表时添加唯一约束
-
列级
-
-
create table 表名(
字段名 字段类型 unique,
.....
);
-
-
表级
-
create table 表名(
字段名 字段类型,
[constraint 约束名] unique(字段名)
);
-
通过修改表添加唯一约束:
alter table 表名 add [constraint 约束名] unique(字段名);
-
通过修改字段类型添加唯一约束:
alter table 表名 modify 字段名 字段类型 unique;-
删除唯一约束(通过约束名字/字段名删除):
alter table 表名 drop index|key 约束名|字段名;
-
主键约束 primary key
-
创建表时添加单字段主键约束
-
列级
-
-
create table 表名(
字段名 字段类型 primary key,
.....
);
-
-
表级
-
create table 表名(
字段名 字段类型,
...,
[constraint 约束名] primary key(字段名)
);
-
创建表时添加联合主键约束
-
表级
-
create table 表名(
字段名 字段类型,
...,
[constraint 约束名] primary key(字段名1,字段名2)
);
-
通过修改表添加主键约束
alter table 表名 add [constraint 约束名] primary key (字段名);
-
通过修改字段类型添加主键约束
alter table 表名 modify 字段名 int primary key;-
删除主键
alter table 表名 drop primary key;
-
自增值
drop table if exists stu1;
create table stu1(
id int auto_increment,
sname char(4),
constraint p1 primary key(id)
);
-
外键约束 foreign key
-
创建表时添加外键约束
-
drop table if exists student;
create table if not exists student(
sno int primary key,
sname char(4)
);
drop table if exists score;
create table if not exists score(
sno int,
sres double(4,1),
constraint fk1 foreign key (sno) references student(sno)
);
-
通过修改表添加外键约束
alter table 子表名 add constraint 约束名 foreign key(外键字段名) references 父表名(外键字段名);
-
删除外键约束
alter table 表名 drop foreign key 约束名;
-
级联更新级联删除:
on delete cascade on update cascade
数据排序
order by
limit
select 字段
from 表
where 筛选条件
order by 字段名 asc|desc
limit n;
函数
数值函数
-
获取整数的函数
-
ceil(x)
-
floor(x)
-
-
四舍五入的函数
-
round(x)
-
round(x,y)
-
-
截断函数
-
Truncate(x,y)
-
-
取模(求余)函数
-
mod(x,y)
-
-
随机数函数
-
rand()
-
-
格式化函数
-
format(num,n)
-
字符函数
-
字符连接函数
-
concat(s1,s2...)
-
concat_ws(c,s1,s2...)
-
-
字母转换大小写函数
-
lower(str)
-
upper(str)
-
-
求字符串长度的函数
-
length(str)
-
-
删除空格的函数
-
ltrim(str)
-
rtrim(str)
-
trim(str)
-
-
截取字符串的函数
-
substr(str,n,len)
-
-
截取指定长度的字符串函数
-
left(str,len)
-
right(str,len)
-
-
替换函数
-
replace(str,from_str,to_str)
-
日期时间函数
-
获取当前日期的函数
-
curdate()
-
current_date()
-
-
获取当前时间的函数
-
curtime()
-
current_time()
-
-
获取当前日期和时间
-
now()
-
sysdate()
-
-
执行日期的加运算函数
-
date_add(date,interval n type)
-
-
计算两个日期之间的间隔天数函数
-
datediff(data1,data2)
-
-
日期格式化函数
-
date_format(date,format)
-
str_to_date('日期字符串','日期格式')
-
将字符串转换成date类型
| date_format | 时间日期格式 |
| %Y:4位数形式表示年份 | %y:2位数形式表示年份 |
| %b:月份,缩写名称(Jan...Dec) | %c:月份,数字形式(0...12) |
| %m:月份,数字形式(00...12) | %M:月份名称(January..Dec) |
| %d:该月日期,数字形式(00...31) | %e:该月日期,数字形(0...31) |
| %p:上下午,am、pm | %h: 时 |
| %i : 分 | %s或%S:秒 |
聚合函数/组函数
| 名称 | 描述 |
| AVG() | 返回某列的平均值 |
| SUM() | 返回某列值的和 |
| COUNT() | 返回某列的行数 |
| MAX() | 返回某列的最大值 |
| MIN() | 返回某列的最小值 |
-
注意
-
聚合函数会自动的忽略空值,不需要手动增加条件排除NULL
-
聚合函数不能作为where子句后的限制条件
-
分组查询
group by 字段
distinct 去重
having 筛查分组之后的数据
#总结
select 字段名
from 表
where 筛选条件:对分组前的数据进行筛选
group by 字段
having 条件:对分组之后的数据进行筛选
order by 字段
limit n
表连接查询 join on
两表连接查询
-
交叉连接(笛卡尔积现象)
-
内连接 [innner] join
-
等值连接: 查询员工所属部门得部门名称
-
非等值连接: 查询员工的薪水等级
-
自连接: 查询员工所对应的领导的姓名
-
-
外连接 left | right [outer] join
-
左连接:显示左表全部记录,右表满足连接条件的记录
-
右连接:显示右表全部记录,左表满足连接条件的记录
-
select 查询字段
from 表1 别名 [连接类型]
join 表2 别名 on 连接条件
join 表3 别名 on 连接条件
where 筛选条件
group by 分组
having 筛选条件
order by 排序列表
limit n;
多表连接查询
子查询
比较运算符 < > ... in
# 查询出薪水大于20部门平均薪水的员工信息
# 查询成绩大于80分的学生姓名
常用操作符
-
any / some
# 查询出薪水大于任意一个部门的平均薪水的员工信息
-
all
-
注意:select 子查询常用在在where、from 的后面
正则表达式 regexp
匹配单个实例
-
regexp 操作符
-
like 和 regexp 的区别
-
| 为正则表达式的or操作符
-
[] 匹配字符之一
-
[-] 匹配范围
-
匹配特殊字符
-
\\. 匹配 .
-
-
匹配字符类
匹配多个实例
-
常用元字符
| . | 匹配任意字符 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
-
重复元字符
| 元字符 | 说明 |
| * | 0个或多个匹配 |
| + | 一个或多个匹配(等于{1,}) |
| ? | 0个或1个(等于{0,1}) |
| {n} | 指定数目的匹配 |
| {n,} | 不少于指定数目的匹配 |
| {n,m} | 匹配数目的范围(m不超过255) |
-
注意
-
^ 在[]中,表示否定;否则,表示开始处
-
存储过程
创建存储过程
create procedure pro()
begin
// 过程体
end;
-
定义变量
-
存储过程内部定义变量
-
declare 变量名 变量类型 default 默认值;
-
存储过程外部定义变量
set @变量名 = 值;
-
修改变量的值
set 变量名 = 值;
select 值 into 变量名;
-
控制流程语句
-
if
-
if 条件1 then 执行语句;
[elseif 条件2 then 执行语句;]
[else 执行语句;]
end if;
-
while
while 条件
do
循环语句;
end while;
-
repeat ( 了解 )
repeat
循环语句;
until 条件 end repeat;
-
loop ( 了解 )
loop_name:loop
循环语句;
if 条件 then leave loop_name;end if;
end loop;
-
参数
-
in ( 默认 )
-
out
-
inout
-
#in:只可以接受到外部变量的值,但无法修改外部变量的值(默认)
#out:无法接收外部变量的值,但可以 修改外部变量的值
#inout:即可以接收又可以修改外部变量的值
使用存储过程
call pro();
删除存储过程
drop procedure pro;
自定义函数
-
自定义函数含义
-
函数:
-
需要有返回值
-
可以指定0~n个参数
-
-
查看是否已经开启了创建函数的功能
show variables like '%fun%';
# 如果变量值为off,则需要开启:
Set global 变量值=1;
-
创建自定义函数
create function fun_name([变量1 变量类型,变量2 变量类型]) returns 数据类型
begin
...
return 数据;
end;
-
函数体是由sql代码构成
-
函数体可以为复合结构,需要使用begin...end语句复合结构可以包含声明、流程控制
-
删除自定义函数
drop function [if exists] fun_name;
-
调用函数
select 函数名(参数列表);
-
存储过程与函数的区别功能上不同
-
存储过程:一般来说,存储过程实现的功能要复杂一点。功能强大,可以执行包括修改表等一系列数据库操作
-
存储函数:实现的功能针对性比较强
-
-
返回值上的不同
-
存储过程:可以返回多个值,也可以不返回值,只是实现某种效果或动作。
-
存储函数:必须有返回值,而且只能有一个返回值
-
-
参数的不同
-
存储过程:参数类型有三种,in、out、inout
-
存储函数:参数类型只有一种,类似于in参数
-
-
语法结构的不同
-
存储过程:存储过程声明时不需要指定返回类型
-
存储函数:函数声明时需要指定返回类型,且在函数体中必须包含一个有效的return语句
-
-
调用方式的不同
-
存储过程:一般是作为一个独立的部分来执行,用call语句进行调用
-
存储函数:嵌入在sql中使用,可以在select 中调用
-
习题
写一个登录验证的函数。创建用户密码表
-
录入用户信息(用户名和密码)
-
自定义函数实现登录验证的功能 输入的用户名不存在是输出用户名不存在 输入用户名存在,密码不匹配时输出密码错误 输入用户名密码一致时,输出登录成功
触发器
-
创建触发器在创建触发器时,需要给出4条信息:
-
1.唯一的触发器名;
-
2.触发器关联的表;
-
3.触发器应该响应的活动(DELETE/INSERT/UPDATE);
-
4.触发器何时执行(after/before处理之前或之后);
-
-
创建触发器:
create trigger after_emp_update before|after update|insert|delete on t_name for each row
begin
...
end;
create table t_info(
old_ename char(10),
new_ename char(10),
e_time time,
e_user char(20),
e_event char(12)
);
create trigger before_emp_insert before insert on emp for each row
begin
insert into t_info values('',new.ename,now(),user(),'insert');
end;
insert into emp(empno,ename)values(7777,'xiaoming');
-
删除触发器
drop trigger 触发器名字
习题
创建一张日志表log_info用来记录score表degree的操作(update/delete/insert),日志表的字段包括(主键id,更新前的degree,更新后的degree,执行时间,执行事件,执行人)
游标
-
游标的含义
游标(cursor)是一个存储在MySQL服务器上的数据库查询,它不是一条SELECT语句,而是被该语句检索出来的结果集。在存储了游标之后,应用程序可以根据需要滚动或浏览其中的数据。游标主要用于交互式应用,其中用户需要滚动屏幕上的数据,并对数据进行浏览或做出更改。
Ps:MySQL游标只能用于存储过程(和函数)。
-
使用步骤创建定义游标
declare 游标名称 cursor for 查询语句;
DECLARE命名游标,并定义相应的SELECT语句,根据需要带WHERE和其他子句。
-
存储过程处理完成后,游标就消失(因为它局限于存储过程)。在定义游标后,可以打开它。
-
打开游标:Open 游标名称;
-
在处理OPEN语句时执行查询,存储检索出的数据以供浏览和滚动。
-
将游标数据匹配到变量中:Fetch 游标名称 into 变量名称 ;
在一个游标被打开后,可以使用 FETCH语句分别访问它的每一行。 FETCH指定检索什么数据(所需的列),检索出来的数据存储在什么地方。它还向前移动游标中的内部行指针,使下一条FETCH语句检索下一行(不重复读取同一行)。
-
关闭游标:Close游标名称;
CLOSE释放游标使用的所有内部内存和资源,因此在每个游标不再需要时都应该关闭。在一个游标关闭后,如果没有重新打开,则不能使用它。但是,使用声明过的游标不需要再次声明,用OPEN语句打开它就可以了。
-
使用游标数据
FETCH如果在循环内,因此它反复执行直到条件为真(由UNTIL 条件 END REPEAT;)为使它起作用,用一个DEFAULT 0(假,不结束)定义变量条件。条件在结束时被设置为真,语句定义了一个CONTINUE HANDLER, 它是在条件出现时被执行的代码.它指出当SQLSTATE '02000'出现时,SET 条件变量=1。SQLSTATE '02000'是一个未找到条件,当循环由于没有更多的行供循环而不能继续时,出现这个条件
declare flag int default 0;
declare continue handler for sqlstate '02000' set flag=1;
Ps:
DECLARE语句的发布存在特定的次序。 用DECLARE语句定义的局部变量必须在定义任意游标或句柄之前定义 而句柄必须在游标之后定义
局部变量 > 游标 > 句柄
create procedure procedure1()
begin
declare s_no char(5);
declare c_no char(5);
declare d decimal(4,1);
declare cur cursor for select * from score;
open cur;
fetch cur into s_no,c_no,d;
select s_no,c_no,d;
close cur;
end;
call procedure1();
drop procedure procedure1;
create procedure procedure1()
begin
declare s_no char(5);
declare c_no char(5);
declare d decimal(4,1);
declare flag int default 0;
declare cur cursor for select * from score;
declare continue handler for sqlstate '02000' set flag=1;
open cur;
while flag=0 do
fetch cur into s_no,c_no,d;
if flag=0 then
select s_no,c_no,d;
end if;
end while;
close cur;
end;
call procedure1();
视图
虚拟的表
-
创建视图:create view 视图名称 as 查询语句;
-
查看视图:show create view my_view;
-
修改视图:alter view 视图名称 as 查询语句;
-
删除视图:drop view if exists my_view;
-
作用:
-
-
-
-
-
-
-
简化查询语句(查询两张表形成一张虚拟表)
-
权限的控制(将表的权限关闭 视图中部分字段开放)
-
分表查看(大数据分表查看 分工)
-
-
-
-
-
-
数据库设计三范式
范式:数据库设计的时候所依据的规范
-
第一范式 1NF
每个字段是原子性的,列不能再分
不符合第一范式的示例:
| 学生编号 | 学生姓名 | 联系方式 |
| 1001 | 张三 | zs@gmail.com ,1359999999 |
| 1002 | 李四 | ls@gmail.com,13699999999 |
| 1001 | 王五 | ww@163.net ,13488888888 |
改以上设计方案:
| 学生编号(pk) | 学生姓名 | | 联系电话 |
| 1001 | 张三 | 13599999995 | |
| 1002 | 李四 | 13699999999 | |
| 1003 | 王五 | 13488888888 |
-
结论:
-
每一行必须唯一,也就是每个表必须有主键,是数据库设计的最基本要求
-
主键通常主要采用数值型或定长字符串表示
-
关于列不可再分,应该根据具体的情况来决定。
-
第二范式
第二范式是建立在第一范式基础上的,唯一性,要求所有非主键字段完全依赖主键,不能产生部分依赖;(严格意义上说:不要使用联合主键)
示例:
| 学生编号 | 学生姓名 | 教师编号 | 教师姓名 |
| 1001 | 张三 | 001 | 王老师 |
| 1002 | 李四 | 002 | 赵老师 |
| 1003 | 王五 | 001 | 王老师 |
| 1001 | 张三 | 002 | 赵老师 |
联合主键:
| 学生编号(PK) | 教师编号(PK) | 学生姓名 | 教师姓名 |
| 1001 | 001 | 张三 | 王老师 |
| 1002 | 002 | 李四 | 赵老师 |
| 1003 | 001 | 王五 | 王老师 |
| 1001 | 002 | 张三 | 赵老师 |
以上虽然确定了主键,但此表会出现大量的冗余,主要涉及到的冗余字段为"学生姓名"和"教师姓名",出现冗余的原因在于,学生姓名部分依赖了主键的一个字段学生编号,而教师姓名部分依赖了主键的一个字段教师编号,这就是第二范式部分依赖.
解决方案如下:
学生信息表
| 学生编号(PK) | 学生姓名 |
| 1001 | 张三 |
| 1002 | 李四 |
| 1003 | 王五 |
教师信息表
| 教师编号(PK) | 教师姓名 |
| 001 | 王老师 |
| 002 | 赵老师 |
教师和学生的关系表
| 学生编号(PK) fk->学生表的学生编号 | 教师编号(PK) fk->教师表的教师编号 |
| 1001 | 001 |
| 1002 | 002 |
| 1003 | 001 |
| 1001 | 002 |
-
第三范式
建立在第二范式基础上的,非主键字段不能传递依赖于主键字段。
| 学生编号(PK) | 学生姓名 | 班级编号 | 班级名称 |
| 1001 | 张三 | 01 | 一年一班 |
| 1002 | 李四 | 02 | 一年二班 |
| 1003 | 王五 | 03 | 一年三班 |
| 1004 | 刘六 | 03 | 一年三班 |
从上表可以看出,班级名称字段存在冗余,因为班级名称字段没有直接依赖于主键,班级名称字段依赖于班级编号,班级编号依赖于学生编号,那么这就是传递依赖,解决的办法是将冗余字段单独拿出来建立表,如:
学生信息表
| 学生编号(PK) | 学生姓名 | 班级编号(FK) |
| 1001 | 张三 | 01 |
| 1002 | 李四 | 02 |
| 1003 | 王五 | 03 |
| 1004 | 刘六 | 03 |
班级信息表
| 班级编号(PK) | 班级名称 |
| 01 | 一年一班 |
| 02 | 一年二班 |
| 03 | 一年三班 |
-
三范式总结
-
第一范式:具有原子性,字段不可分割
-
第二范式:有主键,完全依赖,没有部分依赖
-
第三范式:没有传递依赖
-















 391
391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









