






第一章Linux简介
目录
严格的来讲,Linux 不算是一个操作系统,只是一个 Linux 系统中的内核,即计算机软件与硬件通讯之间的平台;Linux的全称是GNU/Linux,这才算是一个真正意义上的Linux系统。GNU是Richard Stallman组织的一个项目,世界各地的程序员可以变形GNU程序,同时遵循GPL协议,允许任何人任意改动。但是,修改后的程序必须遵循GPL协议。
Linux 是一个多用户多任务的操作系统,也是一款自由软件,完全兼容POSIX标准,拥有良好的用户界面,支持多种处理器架构,移植方便。
为程序分配系统资源,处理计算机内部细节的软件叫做操作系统或者内核。如果你希望详细了解操作系统的概念,请查看操作系统教程。
用户通过Shell与Linux内核交互。Shell是一个命令行解释工具(是一个软件),它将用户输入的命令转换为内核能够理解的语言(命令)。
Linux下,很多工作都是通过命令完成的,学好Linux,首先要掌握常用命令。
Linux版本
内核版本指的是在 Linus 领导下的开发小组开发出的系统内核的版本号。Linux 的每个内核版本使用形式为 x.y.zz-www 的一组数字来表示。其中:
- x.y:为linux的主版本号。通常y若为奇数,表示此版本为测试版,系统会有较多bug,主要用途是提供给用户测试。
- zz:为次版本号。
- www:代表发行号(注意,它与发行版本号无关)。
当内核功能有一个飞跃时,主版本号升级,如 Kernel2.2、2.4、2.6等。如果内核增加了少量补丁时,常常会升级次版本号,如Kernel2.6.15、2.6.20等。
一些组织或厂家将 Linux 内核与GNU软件(系统软件和工具)整合起来,并提供一些安装界面和系统设定与管理工具,这样就构成了一个发型套件,例如Ubuntu、Red Hat、Centos、Fedora、SUSE、Debian、FreeBSD等。相对于内核版本,发行套件的版本号随着发布者的不同而不同,与系统内核的版本号是相对独立的。因此把Red Hat等直接说成是Linux是不确切的,它们是Linux的发行版本,更确切地说,应该叫做“以linux为核心的操作系统软件包”。
Linux体系结构
下面是Linux体系结构的示意图:

在所有Linux版本中,都会涉及到以下几个重要概念:
- 内核:内核是操作系统的核心。内核直接与硬件交互,并处理大部分较低层的任务,如内存管理、进程调度、文件管理等。
- Shell:Shell是一个处理用户请求的工具,它负责解释用户输入的命令,调用用户希望使用的程序。
- 命令和工具:日常工作中,你会用到很多系统命令和工具,如cp、mv、cat和grep等。在Linux系统中,有250多个命令,每个命令都有多个选项;第三方工具也有很多,他们也扮演着重要角色。
- 文件和目录:Linux系统中所有的数据都被存储到文件中,这些文件被分配到各个目录,构成文件系统。Linux的目录与Windows的文件夹是类似的概念。
第二章操做系统简介
2.1操作系统的概念
操作系统是管理计算机硬件与软件资源的计算机程序。操作系统需要处理如管理与配置内存、决定系统资源供需的优先次序、控制输入设备与输出设备、操作网络与管理文件系统等基本事务。操作系统也提供一个让用户与系统交互的操作界面。
2.2Linux接口
Linux系统是一种金字塔型的系统,如下所示

应用程序发起系统调用把参数放在寄存器中(有时候放在栈中),并发出trap系统陷入指令切换用户态至内核态。因为不能直接在C语言中编写trap指令,因此C提供了一个库,库中的函数对应着系统调用。有些函数是使用汇编编写的,但是能从C中调用。每个函数首先把参数放在合适的位置然后执行系统调用指令。因此如果你想要执行read系统调用的话,C程序会调read函数库来执行。是由POSIX指定的库接口而不是系统调用接口。也就是说,POSIX会告诉一个标椎系统应该提供哪些库过程,它们的参数是什么,它们必须做什么以及它们必须返回什么结果。
Linux具有三种不同的接口:系统调用接口、库函数接口和应用程序接口
2.3Linux操作系统重要概念呢
2.3.1并发
假设我们的计算机只有一个cpu,并且只有一个核心(core)
并发:
在操作系统中,一个时间中有多个进程都处于已启动运行到完毕运行之间的状态。但任一个时刻点上任只有一个进程在运行
单道程序设计:
所有程序一个一个排队执行。若A阻塞,B只能等待,即使CPU处于空闲状态。而在人机交互时阻塞的出现时必然的。所有这种模型在系统资源利用上极其不合理,在计算机发展历史上存在不久,大部分被淘汰了。
多道程序设计:
在计算机内存中同时存放几道相互独立的程序,它们在管理程序控制之下,相互穿插的运行。多道程序设计必须有硬件基础作为保证。
时间中断即为多道程序设计模型的理论基础。并发时,任意进程在执行期中都不希望放弃CPU。因此系统需要一种强制让进程让出CPU资源的手段。时钟中断有硬件基础作为保障,对进程而言不可抗拒。操作系统中断处理函数,来负责调度程序执行。
在多道程序设计模型中,多个进程轮流使用CPU(分时复用CPU资源)。而当下常见CPU为纳米级,1秒可以执行大约10亿条指令。由于人眼的反应速度是毫秒级,所以看似同时进行。
1s=1000ms,1ms=1000us,1us=1000ns
2.3.2进程的基本概念
进程是计算机中的程序关于某数据集合上的一次运动活动,是系统进行资源分配的基本单位,是操作系统结构的基础。
进程的概念主要有两点:第一,进程是一个实体。每一个进程都有它自己的地址空间,一般情况下,包括文本区域(text regio)。数据区域(date region)和堆栈(stack region)。文本区域存储处理器执行的代码;数据区域存储变量和进程执行期间使用的动态分配的内存;堆栈区域存储着活动过程调用的指令和本地变量。第二,进程是一个“执行中的程序”。程序是一个没有生命的实体,只有处理器赋予程序生命时(操作系统执行之),它才能成为一个活动的实体,我们称其为进程。
2.3.3PCB进程控制块和文件描述符表

每个进程在内核中都有一个进程控制块(PCB)来维护进程相关的信息,Linux内核的进程控制块是task_struct结构体。
-
进程id。系统中每个进程有唯一的id,在C语言中用pid_t类型表示,其实就是一个非负整数。
-
进程的状态,有就绪、运行、挂起等状态。
-
描述虚拟地址空间的信息。
-
文件描述符,包含很多指向file结构体的指针。
-
进程切换时需要保存和恢复的一些CPU寄存器
2.3.4虚拟地址空间

进程的虚拟地址空间分为用户区和内核区,其中内核区失手保护的,用户是不能否对其进行读写操作的;
内核区中很重要的一个就是进程管理,进程管理中有一个区域就是PCB(本质是一个结构体);
PCB中有文件描述符表,文件描述符表中存放着打开的文件描述符,涉及到文件的IO操作都会用到这个文件描述符。
2.3.5CPU的两种运行状态
CPU有两种运行状态:
-
用户态:运行用户程序
-
内核态:运行操作系统程序,操作硬件
CPU状态之间的转换:
-
用户态-->内核态:只能通过中断、异常、陷入指令
-
内核态-->用户态:设置程序状态PSW
内核态于用户态的区别:
两种运行级别,3级特权级上时,为用户态。因为这是最低特权,当程序运行在0级特权上时,运行在内核态。
这两种状态的主要差别是:
-
处于用户态执行时,进程所能访问的内存空间和对象受到限制,其占有的处理器资源是可被占有的。
-
处于内核态执行时,则能访问所有的内存空间和对象,且所占的处理器是不允许被抢占的。
通常来说,以下三种情况会导致用户态到内核态的切换
系统调用:
这是用户态进程主动要求切换到内核态的一种方式,用户态进程通过系统调用申请使用操作系统提供的服务程序完成工作,比如fork()实际上就是执行了一个创建新进程的系统调用
而系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现
用户程序通常调用库函数,由库函数在调用系统调用,因此有的库函数会使用户程序进入内核态(只要库函数中某处调用了系统调用),有的则不会
异常:
当CPU执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常。
外围设备的中断:
当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这是CPU不会执行下一条即将要执行的指令而去执行与中断信号对应的处理程序。
如果先前执行的指令时用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换,比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
这三种方式是系统在运行时由用户态转到内核态的最主要方式,其中系统调用可以认为是用户进程主动发起的,异常和外围设备中断则是被动的。
2.3.6什么是库函数
库函数是把函数放在库里,供别人使用的一种方式。方法是把一些常用的库函数编完放到一个文件里,供不同的人进行调用。调用的时候把它所在的文件名用#includde<>加到里面,一般放到lib文件里。
2.3.7什么是系统调用
由操作系统实现提供的所有系统调用所构成的集合即程序接口或应用编程接口。是应用程序同系统之间的接口,用户程序只在用户态下运行,有时需要访问系统核心功能,这时通过系统调用接口使用系统调用。
C标准库函数和系统函数调用关系:一个hello word如何打印到屏幕。

第三章文件IO
3.1c库io函数的工作流程

磁盘为什么慢:
大部分硬盘都是机械硬盘,读取寻道时间都是在毫秒级(ms)
相对来说内存速写速度都非常快,因为内存属于电子设备,读写速度时纳米级(ns)级别的

c语言操作文件相关问题:
使用fopen函数打开一个文件,返回一个FILE* fp,这个指针指向的结构体有三个重要的成员
-
文件描述符:通过文件描述可以找到文件的inode,通过inode可以找到对应的数据块
-
文件指针:读和写共享一个文件指针,读或写都会引起文件指针的变化;
-
文件缓冲区:读或写会先通过文件缓冲区,主要目的是为了减少磁盘的读写次数,提高读写磁盘的效率
3.1.1文件读写的基本流程
读文件
-
进程调用库函数向内核发其读写文件请求
-
内核通过检查进程的文件描述符定位到虚拟文件系统的以打开文件列表表项
-
调用该文件可用的系统调函数read()
-
read()函数通过文件表项链接到目录项模块,根据传入的文件路径,在目录项模块中检索,找到该文件的inode
-
在inode中通过文件内容偏移量计算出要读取的页
-
通过inode找到文件对应得sddress_space
-
在address_space中访问该文件的页缓存树,查找对应的页缓存节点
-
如果页缓存命中,那么直接返回文件内容
-
如果页缓存缺失,那么产生一个缺页异常,创建一个页缓存页,同时通过inode找到文件该页的磁盘地址,读取相应的页填充该缓存页,重新进行第六步查找页缓存
-
文件读取成功
写文件
前5步和读文件一致,在address_space中查询对应的页缓存是否存在。
6.如果页缓存命中,直接把文件内容修改更新在页缓存的页中。写文件就结束了。这时文件修
改位于页缓存,并没有写回磁盘文件中去。
7.如果页缓存缺失,那么产生一个缺页异常,创建一个页缓存页,同时通过inode找到文件该页的磁盘地址,读取相应的页填充该缓存页命中,进行第六步。
8.一个页缓存中的页如果被修改,那么会被标注成脏页。脏页需要写回到磁盘中的文件块,有两种方式可以把脏页写回到磁盘:
-
手动调用sync()或者fsync()系统调用把脏页写回
-
b.pdflush进程会定时把脏页写回到磁盘
同时注意:脏页不能被换出内存,如果脏页正在被写回,那么会设置写回标记,这时候该页就会被上锁,其他写请求被阻塞直到锁释放
3.2c库函数与系统函数的关系

3.3文件描述符
一个进程启动之后,默认打开三个文件描述符:
#define STDIN_FILENO 0
#define STDOUT_FILENO 1
#define STDERR_FILENO 2
新打开文件返回文件描述符表中未使用的最小文件描述符,调用open函数可以打开或创建一个文件,得到一个文件描述符。
3.4文件IO函数
3.4.1open/close
open函数:
函数描述:打开或者新建一个文件
函数原型:
int open(const char *pathname,int flags)
int open(const chat *pathname,int flags,mode_t mode)
函数参数:pathname参数是要打开或创建的文件名,和fopen一样, pathname既可以是相对路径也可以是绝对路径。
flags参数有一系列常数值可供选择,可以同时选择多个常数用按位或运算符(|)连接起来,所以这些常数的宏定义都以o_开头,表示or。
必选项:以下三个常数中必须指定一个,且仅允许指定一个。
-
O_RDONLY 只读打开
-
O_WRONLY 只写打开
-
O_RDWR 可读可写打开
以下可选项可以同时指定0个或多个,和必选项按位或起来作为flags参数。可选项有很多,这里只介绍几个常用选项:
-
O_APPEND 表示追加。
-
O_CREAT 若此文件不存在则创建它。
-
O_EXCL 若果同时指定O_CREAT,并且文件已存在,则出错返回
-
O_TRUNC 如果文件已存在,将其长度截断为0字节
-
O_NONBLOCK 对于设备文件,以O_NONBLOC方式打开可以做非阻塞I/O
函数返回值:
-
成功:返回一个最小且未被占用的文件描述符
-
失败:返回-1,并设置errno值.
close函数:
函数描述:关闭文件
函数原型:
int close (int fd)
函数参数:fd文件描述符
函数返回值:
-
成功返回0
-
失败返回-1,并设置erron值
3.4.2read/write
read函数:
函数描述:从打开的设备或文件中读取
函数原型:
ssize_t read(int fd,void *buf,size_t count)
函数参数:
-
fd:文件描述符
-
buf:读上来的数据保存在缓冲区buf中
-
count:buf缓冲区存放的最大字节数
函数返回值:
-
>0:读取到的字节数
-
=0:文件读取完毕
-
-1:出错,并设置errno
write函数:
函数描述:向打开的设备或文件中写数据
函数原型:
ssize_t write(int fd,const void *buf,size_t const);
函数参数:
-
fd:文件描述符
-
buf:缓冲区,要写入文件或设备的数据
-
count:buf中数据的长度
函数的返回值:
-
成功:返回写入的字节数
-
失败:返回-1并设置errno
3.4.3lseek
所有打开的文件都有一个当前文件偏移量,以下简称为cfo。cfo通常是一个非负整数,用于表明文件开始出到文件当前位置的字节数。读写操作会被初始化为0,除非使用了O_APPEND。
使用lseek函数可以改变文件的cfo
头文件:
-
#include<sys/types.h>
-
#include<unistd.h>
函数描述:移动文件指针
函数原型:
off_t lseek(int fd,off_t offset,int whence);
函数参数;
-
fd:文件描述符
-
参数offset的含义取决与参数whence
-
如果whence是SEEK_SET,文件偏移量将设置为offset。
-
如果whence是SEEK_CUR,文件偏移量将被设置为cfo加上offset,offset‘可以为正也可以为负。
函数返回值:
-
若lseek成功执行,则返回新的偏移量
-
失败返回-1并设置errno
lseek函数常用操作:
-
文件指针移动到头部
-
lseek(fd,0,SEEK_SET);
-
获取当前文件指针当前位置
-
int len=lseek(fd,0,SEEK_CUR);
-
获取文件长度
-
int len=lseek(fd,0,SEEK_END);
-
lseek实现文件拓展
off_t currpos;
//从文件尾部开始向后拓展1000个字节
currpos = lseek(fd, 1000, SEEK_END);
//额外执行一次写操作,否则文件无法完成拓展
write(fd, "a",1); //数据随便写
3.4.4perror和errno
许多系统调用和库函数都会因为各种各样的原因失败。
常用错误代码的取值和含义如下:
1 EPERM 操作不允许
2 ENOENT 文件或目录不存在
3 EINTR 系统调用被中断
4 EAGAIN 重试,下次有可能成功!
5 EPADF 文件描述符失效或本身无效
6 EIO I/O错误
7 EBUSY 设备或资源忙
9 EEXIST 文件存在
10 EINVL 无效参数
11 EMFILE 打开的文件过多
12 ENODEV 设备不存在
13 EISDIR 是一个目录
14 ENOTDIR 不是一个目录
两个有效函数可报告出现的错误:strerror和perror
strerror函数
作用:把错误带好映成一个字符串,该字符串对发生的错误类型进行说明。
#include <string.h>
char *strerror(int errnum);
perror函数
作用:perror函数也把error变量中报告的当前错误映射成一个字符串,并把它输出到标准错误输出流。
#include <stdio.h>
void perror(const char *s);
perror("text");
结果:
text:Too many open files
3.4.5阻塞和非阻塞
普通文件: hello.c
默认是非阻塞的
终端设备:如/dev/tty
默认阻塞
管道和套接字
默认阻塞
-
读写普通文件,没有阻塞非阻塞的概念
-
只有在读写c\b\p\s文件的时候才有阻塞非阻塞的概念
-
阻塞
当以阻塞方式读取文件的时候
文件为空 进程阻塞等待
文件非空 read write返回操作成功的字节数
以非阻塞方式读取文件
文件为空 read write返回-1,设置errno EAGAIN 什么也没读到 read返回
文件非空 read write返回操作成功的字节数
问题:
比较:如果一个只读一个字节实现文件拷贝,使用read、write效率高,还是使用对应的标库函数(fgetc、 fputc)效率高呢?
strace命令
shell 中使用strace命令跟踪程序执行,查看调用的系统函数。
使用库函数效率高,能使用库函数尽量使用库函数
预读入缓输出:

第四章文件和目录
文件通常有两部分组成:内容+属性,属性即管理信息 :包括文件的创建修改日期和访问权限等。
4.1文件操作相关函数
4.1.1 stat/lstat
stat/lstat函数:
函数描述:获取文件属性
函数原型;
int stat(const char *pathname, struct stat *buf)
int lstat(const char *pathname,struct stat *buf)
函数返回值:
-
成功返回0
-
失败返回-1
参数类型:
-
pathname为待解析文件的路径名,可以为绝对路径,也可以为相对路径
-
buf为传出,传出文件的解析结果,buf为struct stat*类型,需要进一步解析
struct stat结构体:
4.2目录操作相关函数
opendir函数:
函数描述:打开一个目录
函数原型:
DIR *opendir(const char *name)
函数返回值:指向目录的指针
函数参数:要遍历的目录(相对路径或者绝对路径)
readdir函数:
函数描述:读取目录内容--目录项
函数原型:
struct dirent *readdir(DIR *dirp);
函数返回值:读取的目录项指针
函数参数:opendir函数的返回值
closedir函数:
函数描述:关闭目录
函数原型:
int closedir(DIR *dirp)
函数返回值:
-
成功返回0
-
失败返回-1
函数参数:opendir函数的返回值
4.3读取目录的一般操作步骤
DIR *pDIR = opendir("dir");//打开目录
while (p = readdir(pDIR) != NULL) {}//循环获取文件
closedir(pDIR);//关闭目录
4.4dup/dup2/fcntl
图解dup和dup2的功能

dup函数:
函数描述:复制文件描述符
函数原型:
int dup(int oldfd);
函数参数:old fd -要复制的文件描述符
函数返回值:
成功:返回最小没被占用的文件描述符
失败:返回-1,设置error值
dup2函数:
函数描述:复制文件描述符
函数原型:
int dup2(int oldfd,int newfd)
函数参数:
oldfd:原来的文件描述符
newfd:复制成的新文件描述符
函数返会值:
成功:将oldfd复制给newfd,两个文件描述符指向同一个文件
失败:返回-1,设置errorno值
假设newfd已经指向一个文件:
首先close原来的文件,然后newfd指向oldfd指向的文件
若newfd没有被占用:
newfd指向oldfd指向的文件
fcntl函数:
函数描述:改变已经打开的文件的属性
函数原型:
int fcntl(int fd,int cmd,.../*arg*/ );
cmd值:
-
若cmd为F_DUPFD,复制文件描述符,与dup相同
-
若cmd为F_GETEL,获取文件描述符的flag属性值
-
若cmd为F_SETFL,设置文件描述符的flag属性
函数返回值:返回值取决于cmd
-
成功
若cmd为F_DUPFD,返回一个文件描述符
若cmd为F_GETFL,返回文件描述符的flag值
若cmd为F_SETFL,返回0
失败返回-1,并设置errorno值
fcntl函数常用的操作:
-
复制一个新的文件描述符
-
int newfd=fcntl(fd,F_FUPFD,0)
-
获取文件的属性标志
-
设置文件状态
-
常用的属性标志
第五章进程
5.1对进程的理解
在许多多道程序系统中,CPU会在进程间快速切换,使每个程序运行几十或者几百毫秒。然而,严格意义来说,在某一个瞬间,CPU只能运行一个进程,然而我们如果把时间定位为1秒内的话,它可能运行多个进程。这样就会让我们产生并行的错觉。有时候人们说的伪并行(pseudoparallelism)就是这种情况,以此来区分多处理器系统(该系统由两个或多个CPU来共享同一个物理内存)
再来详细解释一下伪并行:伪并行是指单核或多核处理器同时执行多个进程,从而使程序更快。通过以非常有限的时间间隔在程序之间快速切换CPU,因此会产生并行感。缺点是CPU时间可能分配给下一个进程,也可能不分配给下一个进程。
因为 CPU执行速度很快,进程间的换进换出也非常迅速,因此我们很难对多个并行进程进行跟踪,所以,在经过多年的努力后,操作系统的设计者开发了用于描述并行的一种概念模型(顺序进程),使得并行更加容易理解和分析,对该模型的探讨,也是本节的主题。下面我们就来探讨一下进程模型
5.2进程模型
在进程模型中,所有计算机上运行的软件,通常也包括操作系统,被组织为若干顺序进程,简称为进程。一个进程就是一个正在执行的实例,进程也包括程序计数器、寄存器和变量的当前值。从概念上来说,每个进程都有各自的虚拟CPU,但是实际前情况是CPU会在各个进程之间进行来回切换。

如上图所示,这是一个具有4个程序的多道程序,在进程不断切换的过程中,程序计数器也在不同的变化。

这四道程序被抽象为四个拥有各自控制流程(即所有自己的程序计数器)的进程,并且每个程序都是独立运行的。当然,实际上只有一个物理程序计数器,每个程序要运行时,其逻辑程序计数器会装载到物理程序计数器中。
从下图我们可以看到,在观察足够长的一段时间后,所有的进程都运行了,但在任何一个给定的瞬间仅有一个进程真正运行

因此,我们说一个CPU只能真正一次运行一个进程的时候,即使有两个核, 每一个核也只能一次运行一个线程
5.3进程创建
操作系统需要一些方式来创建进程。下面是一些创建进程的方式
-
系统初始化(init)
-
正在运行的程序执行了创建进程的系统调用(比如fork)
-
用户请求创建一个新进程
5.3.1系统初始化
启动操作系统时,通常会创建若干个进程。其中有些是前台进程,也就是同用户进行交互并替换它们的工作的进程。一些运行在后台,并不与特定的用户进行交互,例如设计一个进程来接收发来的电子邮件,这个进程大部分的时间都是在休眠,但是只要邮件到来后这个进程就会被唤醒。还可以设计一个进程来接收对该计算机上网页的传入请求,在请求到达的进程唤醒来处理网页的传入请求。进程运行在后台来处理一些活动像是e_mail,web网页,新闻,打印等等被称作守护进程。大型系统会有很多守护进程。在UNIX中,ps程序可以列出正在运行的进程,在Windows中,可以使用任务管理器。
5.3.2系统调用创建
除了在启动阶段创建进程之外,一些新的进程也可以在后面创建。通常,一个正在运行的进程会发出系统调用用来创建一个或多个新进程来帮助其完成工作。例如,如果有大量的数据需要经过网络调取并进行顺序处理,那么创建一个进程读数据,并把数据放到共享缓冲区中,而让第二个进程取走并正确处理会比较容易些。在多处理器中,让每个进程同时运行在不同的CPU上也可以使工作做的更快。
5.3.3用户请求创建
在许多交互式系统中,输入一个命令或者双击图标就可以启动程序,以下任意一种操作都可以选择开启一个新的进程,在基本的UNIX系统中运行X,新进程将接管启动它的窗口。在Windows中启动进程时,它一般没有窗口,但是它可以创建一个或者多个窗口。每个窗口都可以运行进程。通过鼠标或者命令·切换窗口并与进程进行交互。
交互式系统是以人与计算机之间大量交互为特征的计算机系统,比如游戏,web浏览器,IDE等集成开发环境。
在UNIX和Windows中,进程创建之后,父进程和子进程有各自不同的地址空间。如果其中某个进程在其地址空间中修改了一个词,这个修改将对另一个进程不可见。在UNIX中,子进程的地址空间是父进程的一个拷贝,但是确是两个不同的地址空间;不可写的内存区域是共享的。某些UNIX实现是正是在两者之间共享,因为它不能被修改。或者,子进程共享父进程的所有内存,但是这种情况下内存通过写时复制,共享,这意味着一旦两者之一想要修改部分内存,则这块内存首先明确的复制,以确保修改发生在私有内存区域。再次强调,可写的内存是不能被共享的。但是,对于一个新进程来说,确实有可能共享创建者的资源,比如可以共享打开的文件。在Windows中从一开始父进程的地址空间和子进程的地址空间就是不同的。
5.4进程的终止
进程在创建之后,它就开始运行并做完成任务。然而,没有什么事是永不停歇的,包括进程也一样。进程早晚会发生终止,但是通常是由于以下情况触发的
-
正常退出(自愿的)
-
错误退出(自愿的)
-
严重错误(非自愿的)
-
被其他进程杀死(非自愿的)
5.4.1正常退出
多数进程是由于完成了工作而终止。当编译器完成了所给定程序的编译之后,编译器会执行一个系统调用告诉系统它完成了工作。这个调用在UNIX中是exit,在Windows中是ExitProcess。面向屏幕中的软件也是支持自愿终止操作。自处理软件、Internet浏览器类似的程序中总有一个供用户点击的图标或菜单项,用来通知进程删除它所打开的任何临时文件,然后终止。
5.4.2错误退出
进程发生种终止的第二个原因是发现严重错误,例如,如果用户执行如下命令
gcc main.c
为了能够编译main.c但是该文件不存在,于是编译器就会发出声明并退出。在给出了错误参数时,面向屏幕的交互式进程通常并不会直接退出,因为这从用户的角度来说并不合理,用户需要知道发生了什么并想要进行重试,所以这时候应用程序通常会弹出一个对话框告知用户发生了系统错误,是需要重试还是退出。
5.4.3严重错误
进程终止的第三个原因时由进程引起的错误,通常时由于程序中的错误所导致的。例如,执行了一条非法指令,引用不存在的内存,或者除数是0等。在有些系统比如UNIX中进程可以通知操作系统,它希望自行处理某种类型的错误,在这类错误种进程会收到信号(中断)而不是在这类错误出现时直接终止进程。
5.4.4被其它进程杀死
第四各终止进程的原因时,某个进程执行系统调用告诉操作系统杀死某个进程。在UNIX中,这个系统调用就是kill。
5.5进程的层次结构
在一些系统中,当一个进程创建了其它进程后,父进程和子进程就会以某种方式进行关联。子进程它自己就会创建更多进程,从而形成一个进程层次结构。
5.5.1UNIX进程体系
在UNIX中,进程和它的所有子进程以及子进程的子进程共同组成一个进程组。当用户从键盘中发出一个信号后,该信号被发送给当前与键盘相关的进程组中得所有成员(它们通常是在当前窗口创建的所有活动进程)。每个进程可以分别捕获该信号、忽略该信号或采取默认的动作,即被信号kill掉。
这里另外一个例子,可以用来说明层次的作用,考虑UNIX在启动时如何初始化自己。一个称为init的特殊进程出现在启动映像中,当init进程开始运行时,它会读取一个文件,文件会告诉它有多少个终端。然后为每个终端创建一个新进程。这些进程等待用户登录。如果登录成功,该登录进程就执行一个shell来等待接收用户输入指令,这些命令可能会启动更多的进程,以此类推。因此,整个操作系统中所有的进程都隶属于一个以init为根的进程树。
5.6进程的状态
尽管每个进程是一个独立的实体,有其自己的程序计数器和内部状态,但是,进程之间仍然需要相互帮助。例如,一个进程的结果可以作为另一个进程输入,在shell命令中
cat chapter1 chapter2 chapter3 | grep tree
第一个进程时cat,将三个文件级联并输出。第二个进程是grep,它从输入中选这具有包含关键字tree的内容,根据这两个进程的相对速度(这取决于两个程序的相对复杂度和各自所分配到的CPU时间片),可能会发生下面的情况,直到输入完毕。
当一个进程开始运行时,他可能会经历下面的这几种状态

图中会涉及三种状态
-
运行态:运行态指的就是进程实际占用CPU时间片运行时
-
就绪态:就绪态指的是可运行,但因为其它进程正在运行而处于就绪状态
-
阻塞态:除非某种外部事件发生,否则进程不能运行
逻辑上来说,运行态和就绪态时很相似的。这两种情况下都表示进程可运行,但是第二种情况没有获得CPU时间分片。第三种状态与前两种状态不同的原因是这个进程不能运行,CPU空闲时也不能运行。
三种状态会涉及四种状态间的切换,在操作系统发现进程不能继续执行时会发生状态1的轮转,在某些系统中进程执行系统调用,例如pause,来获取一个阻塞的状态。在其它系统中包括UNIX,当进程从管道或特殊文件(例如终端)中读取没有可用的输入时,该进程会被自动终止。
转换2和转换3都是由进程调度程序(操作系统的一部分)引起的,进程本身不知道调度程序的存在。转换2的出现说明进程掉度器认定当前进程已经运行足够长的时间,是时候让其它进程运行CPU时间片了。当所有其它进程都运行过后,这时候该让第一个进程重新获得CPU时间片的时候了,就会发生转换3.
程序调度指的是,决定哪个进程优先被运行和运行多久,这是很重要的一点。
当进程等待的一个外部事件发生时(如从外部输入一些数据后),则发生转换4,如果此时没有其它进程在运行,则立刻触发转换3,该进程便开始运行,否则该进程会处于就绪阶段,等待CPU空闲后在轮到它运行。
从上面的观点引入了下面的模型

操作系统最底层的就是调度程序,在它上面有许多进程。所有关于中断处理、启动进程和停止进程的具体细节都是隐藏在调度程序中。事实上,调度程序只是一段非常小的程序。
*5.7进程的实现
操作系统为了执行进程间的切换,会维护这一张表格,这张表就是进程表(process table)。每个进程占用一个进程表项。该表项包含了进程状态的重要信息,包括进程计数器、堆栈指针、内存分配状况、所打开文件的状态、账号和调度信息,以及其它在进程由运行态转换到就绪态或阻塞态时所必须保存的信息,保证该进程随后能再次启动,就像从未被中断过一样。
下面展示了一个典型系统中的关键字段

第一列内容与进程管理有关,第二列内容与存储管理有关,第三列内容与文件管理有关。
存储管理的text segment . data segment、stack segment
现在我们应该利进程表有个人致的了解了,就可以在刘单个CPU上如何运行多个顺序进程的错觉做更多的解释。与每一I/0 类相关联的是一个称作中断向量
(interrupt vector)的位置(靠近内存底部的固定区域)。它包含中断服务程序的入口地址。假设当一个磁盘中断发生时,用户进程3正在运行,则中断硬件将程序计数器、程序状态字、有时还有一个或多个寄存器压入堆栈,计算机随即跳转到中断向量所指示的地址。这就是硬件所做的事情。然后软件就随即接管一切剩余的工作。
当中断结束后,操作系统会调用一个C程序来处理中断剩下的工作。在完成剩下的工作后,会使某些进程就绪,接着调用调度程序,决定随后运行哪个进程。然后将控制权转移给一段汇编语言代码,为当前的进程装入寄存器值以及内存映射并启动该进程运行。
下面显示了中断处理个调度的过程。
-
硬件压入堆栈程序计数器等
-
硬件从中断向量装入新的程序计数器
-
汇编语言过程设置保存寄存器的值
-
汇编语言过程设置新的堆栈
-
C中断服务器运行(典型的读和缓存写入)
-
调度器决定下面哪个程序先运行
-
C过程返回至汇编代码
-
汇编语言过程开始运行新的当前进程
5.8进程的控制
5.8.1进程的创建函数
进程的创建函数fork()函数
Linux系统允许任何一个用户进程创建子进程,创建成功后,子进程将存在于系统之中,并且独立于父进程,该子进程可以接受系统调度,可以得到分配的系统资源,系统也可以检测到子进程的存在,并且赋予它与父进程同样的权利。
Linux系统下使用fork()函数创建一个子进程,其函数原型如下:
#include<unistd.h>
pid_t fork(void);
fork()函数不需要参数,返回值是一个进程标识符( PID )对于返回值,有以下3种情况:
-
对于父进程, fork()函数返回新创建的子进程的ID ;
-
对于子进程,fork()函数返回0;
-
如果创建出错,则fork ()函数返回-1,子进程不被创建。
fork ()函数会创建一个新的进程,并从内核中为此进程分配一个新的可用的进程标识符(PID),之后,为这个新进程分配进程空间,并将父进程的进程空间中的内容复制到子进程的进程空间中,包括父进程的数据段和堆栈段,并且和父进程共享代码段,这时候,系统中又多了一个进程,这个进程和父进程一样,两个进程都要接受系统的调度。由于在复制时复制了父进程的堆栈段,所以两个进程都停留在了fork()函数中,等待返回,因此,fork()函数返回两次,一次是在父进程中返回,另一次是在子进程中返回,这两次的返回值是不一样的。
fork函数创建子进程:
#include<stdio.h>
#include<unistd.h>
int main(int argc,char* argv[])
{
int pid=fork();
if(pid==0)
{
printf("I'm child,ID=%d,Myparent ID=%d\n",getpid(),getppid());
}
else if(pid>0)
{
printf("I'm parent,ID=%d,Myparent ID=%d\n",getpid(),getppid());
sleep(1);
}
return 0;
}

fork后父进程和子进程的异同:
父子进程之间在fork 后。有哪些相同,哪些相异之处呢?
刚fork 之后:
父子相同处:全局变量、.data、.text、栈、堆、环境变量、用户ID、宿主目录、进程工作目录.....
父子不同处:进程ID、fork 返回值、父进程ID、进程运行时间。
似乎,子进程复制了父进程0-3G用户空间内容,以及父进程的 PCB,但 pid 不同。真的每 fork一个子进程都要将父进程的0-3G地址空间完全拷贝一份,然后在映射至物理内存吗?
当然不是!
父子进程间遵循读时共享写时复制(copy-on-write)的原则。
现在的Linux内核在fork()函数时往往在创建子进程时并不立即复制父进程的数据段和堆栈段,而是当子进程修改这些数据内容时复制操作才会发生,内核才会给子进程分配进程空间,将父进程的内容复制过来,然后继续后面的操作,这样的实现更加合理,对于那些只是为了复制自身完成一些工作的进程来说,这样做的效率会更高这也是现代操作系统的一个重要的概念之一“写时复制”的一个重要体现。
5.8.2进程的结束函数
进程的结束exit()函数
当一个进程需要退出时,需要调用退出函数,Linux环境下使用exit()函数退出进程,其函数原型如下:
#include<stdlib.h>
void exit(int status);
exit()函数的参数表示进程的退出状态,这个状态的值是一个整型,保存在全局变量$?中 ,Linux程序员可以通过shell得到已结束进程的结束状态,执行“echo $ ?”命令即可
$?是 Linux shell中的一个内置变量其中保存的是最近一次运行的进程的返回值,这个返回值有以下3种情况:
1.程序中的main函数运行结束,$?中保存main 函数的返回值;
2.程序运行中调用exit函数结束运行,$?中保存exit函数的参数;
3.程序异常退出$?中保存异常出错的错误号。
5.8.3问题?
创建n个进程,当n=10:
int main(int argc,char* argv[])
{
pid_t pid;
int i=0;
for(i;i<10;i++)
{
pid=fork();
if(pid==0)
{
return 0;
}
printf("i=%d\n",i);
printf("pid=%d\n",getpid());
}
return 0;
}
5.8.4exec函数族
fork 创建子进程后执行的是和父进程相同的程序(但有可能执行不同的代码分支),子进程往往要调用一种exec函数以执行另一个程序。当进程调用一种 exec函数时,该进程的用户空间代码和数据完全被新程序替换,从新程序的启动例程开始执行。调用exec并不创建新进程,所以调用exec前后该进程的id 并未改变。
将当前进程的.text、.data 替换为所要加载的程序的.text、.data,然后让进程从新的.text第一条指令开始执行,但进程ID不变,换核不换壳。
其实有六种以exec开头的函数,统称exec函数:
#include <unistd.h>
int execl(const char *path, const char *arg, ...
/* (char*) NULL*/);
int execlp(const char *file, const char *arg, ...
/* (char*) NULL*/);
int execle(const char *path, const char *arg, ...
/*, (char *)NULL, char * const envp[]*/ );
int execv(const char *path, char *const argvI[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[]);
execlp函数
加载一个进程,借助PATH环境变量
int execlp(const char *file, const char *arg, ...
/* (char *)NULL*/);
成功:无返回;失败:-1
参数1:要加载的程序的名字。该函数需要配合PATH环境变量来使用,当PATH中所有目录搜索后没有参数1则出错返回。
该函数通常用来调用系统程序。如:ls、data、cp、cat、等命令
execl函数
加载一个进程,通过路径+程序名来加载
int execl(const char *path, const char *arg, ...
/* (char *)NULL*/);
成功:无返回;失败:-1
对比execlp,如加载"ls"命令带有-1,-h参数
5.8.5孤儿进程
孤儿进程:父进程先于子进程结束,则子进程成为孤儿进程,子进程的父进程成为init进程,称为init进程领养孤儿进程。
5.8.6僵尸进程
僵尸进程:进程终止,父进程尚未回收,子进程残留资源(PCB)存放于内核中,变成僵尸(zombie)进程。
特别注意,僵尸进程是不能使用kill命令杀掉的。因为kill命令只是用来终止进程的,而僵尸进程已经终止。
5.8.7守护进程
守护进程是什么?
Linux Daemon(守护进程)是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。他不需要
创建守护进程的步骤
-
进程组:
-
每个进程也属于一个进程组
-
每个进程组都有一个进程组号,该号等于进程组阻长的PID号。
-
一个进程只能为它自己或子进程设置进程组ID号
-
会话:
-
会话是一个或多个进程组的集合。
-
setsid()函数可以建立一个会话:
-
如果调用setsid的进程不是一个进程组的组长,此函数创建一个新的会话。
-
此进程变成该会话的首进程
-
此进程变成一个新进程组的组长进程
-
此进程没有控制终端,如果在调用setsit前,该进程有控制终端,那么与该终端的联系会解除、如果该进程是一个进程组的组长,此函数返回错误。
-
为了保证这一点,我们先调用fork()然后exit(),此时只有子进程在运行
编写守护进程的一般步骤:
-
父进程中执行fork并exit退出;
-
在子进程中调用setsid函数创建新的会话
-
在子进程中调用chdir函数,让根目录”/“成为工作目录
-
在子进程中调umask函数,设置进程的umask为0
-
在子进程中关闭任何不需要的文件描述符
创建守护进程
#include<stdio.h>
#include<unistd.h>
#include<fcntl.h>
#include<stdlib.h>
#include<sys/socket.h>
#include<sys/stat.h>
int main(int argc,char* argv[])
{
pid_t pid;
pid=fork();
if(pid==0)
{
setsid();
chdir("/");
umask(0);
int fd=open("/dev/null",O_RDWR);
dup2(fd,0);
dup2(fd,1);
dup2(fd,2);
while(1);
}
if(pid>0)
{
return 0;
}
return 0;
}
/dev/null:表示 的是一个黑洞,通常用于丢弃不需要的数据输出, 或者用于输入流的空文件
说明:
1.在后台运行
为避免挂起控制终端将Daemon放入后台执行。方法是在进程中调用fork使父进程终止,让Daemon在子进程中后台执行
if(pid=fork())
exit(0);//是父进程,结束父进程,子进程继续
2.脱离控制终端,登录会话进程组
Linux中的进程与控制终端,登录会话和进程组之间的关系:进程属于一个进程组,进程组号(GID) 就是进程组长的进程号(PID) 。登录会话可以包含多个进程组。这些进程组共享一个控制终端。这个控制终端通常是创建进程的登录终端。
控制终端,登录会话和进程组通常是从父进程继承下来的。我们的目的就是要摆脱它们,使之不受它们的影响。方法是在第1点的基础上,调用setsid() 使进程成为会话组长:
setsid();
说明:当进程是会话组长时setsid()调用失败。但第一点已经保证进程不是会话组长。setsid()调用成功后,进程成为新的会话组长和新的进程组长,并与原来的登录会话和进程组脱离。由于会话过程对抗控终端的独占性,进程同时与控制终端脱离。
3.禁止进程重新打开控制终端
现在,进程已经成为无终端的会话组长。但它可以重新申请打开一个控制终端。可以通过使进程不再成为会话组长来禁止进程重新打开控制终端:
if(pid=fork())
exit(0);//结束第一个子进程,第二个进程继续(第二子进程不在是会话组长)
4.关闭打开的文件描述符
进程从创建它的父进程那里继承了打开的文件描述符。如不关闭,将会浪费系统资源,造成进程所在的文件系统无法卸下以及引起无法预料的错误。
5.改变当前工作目录
进程活动时,其工作目录所在的文件系统不能卸下。一般需要将工作目录改变到根目录。对于需要转储核心,写运行日志的进程将工作目录改变到特定目录
如/ tmpchdir("/")
6.重设文件创建掩码
进程从创建它的父进程那里继承了文件创建掩码。它可能修改守护进程所创建的文件的存取位。为防止这一一点, 将文件创建掩码清除: umask(O) ;
7.处理SIGCHLD信号
处理SIGCHLD信号并不是必须的。但对于某些进程,特别是服务器进程往往在请求到来时生成子进程处理请求。如果父进程不等待子进程结束,子进程将成为僵尸进程(zombie)从而占用系统资源。如果父进程等待子进程结束,将增加父进程的负担,影响服务器进程的并发性能。在Linux 下可以简单地将SIGCHLD信号的操作设为SIG_ IGN。
signal(SIGCHLD,SIG_LGN);
这样,内核在子进程结束时不会产生僵尸进程。这一点与BSD4不同,BSD4下必须显示等待子进程结束才能释放僵尸进程
5.8.5进程回收
wait函数
一个进程在终止时会关闭所有文件描述符,释放在用户空间分配的内存,但它的PCB还保留着,内核在其中保存了一些信息:如果是正常终止则保存着退出状态,如果是异常终止则保存着导致该进程终止的信号是哪个。这个进程的父进程可以调用wait或waitpid 获取这些信息,然后彻底清除掉这个进程。一个进程的退出状态可以在Shell 中用特殊变量$?查看,因为Shell 是它的父进程,当它终止时Shell调用wait 或waitpid得到它的退出状态同时彻底清除掉这个进程。
父进程调用wait函数可以回收子进程终止信息。该函数有三个功能:
-
阻塞等待子进程退出
-
回收子进程残留资源
-
获取子进程结束状态(退出原因)

#include<sys/types.h>
#include<sys/wait.h>
pid_t wait(int *status);
成功:返回清理掉的子进程ID;
失败:返回-1 (没有子进程)
当进程终止时,操作系统的隐式回收机制会:
1.关闭所有文件描述符
2.释放用户空间、分配的内存。内核的PCB 仍存在。其中保存该进程的退出状态。(正常终止→退出值;异常终止→终止信号)
可使用wait函数传出参数status 来保存进程的退出状态。借助宏函数来进一步判断进程终止的具体原因。宏函数可分为如下三组:
1.WIFEXITED(status) //为真 ->进程正常结束
WEXITSTATUS(status) //如上宏为真,使用此宏 ->获取进程退出状态(exit的参数)
2.WIFSIGNALED(status) //为真 ->进程异常终止
WTERMSIG(status) //上宏为真,使用此宏 ->取得使进程终止的那个信号的编号。
* 3. WIFSTOPPED(status) //为非真->进程处于暂停状态
WSTOPSIG(status) //如上宏为真,使用此宏->取得使进程暂停的那个信号的编号。
WIFCONTINUED(status) //如WIFSTOPPED(status)为真->进程暂停后已经继续运行
waitpid函数
作用同wait,但可指定进程id为pid的进程清理,可以不阻塞。
#include<sys/types.h>
#include<sys/wait.h>
pid_t waitpid(pid_t,int *status,int options);
成功:返回清理掉的子进程ID;
失败:-1(无子进程)
特殊参数和返回情况:
参数pid:
-
>0回收指定ID的子进程
-
-1回收任意子进程(相当于wait)
-
0回收和当前调用waitpid一个组的任一子进程
-
<0回收指定进程组内的任意子进程
返回0:参数3为WNOHANG,且子进程正在运行
一次wait或waitpid调用只能清理一个子进程,清理多个子进程应使用循环。
第六章进程间通信
6.1进程间通信介绍
6.1.1进程间通信的概念
进程间通信简称IPC,进程间通信就是在不同进程之间传播或交换信息。
6.1.2进程间通信的目的
-
数据传输:一个进程需要将它的数据发送给另一个进程。
-
资源共享:多个进程之间共享同样的资源
-
通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件,比如进程终止时需要通知其父进程。(信号)
-
*进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
6.1.3进程间通信的本质
进程间通信的本质就是,让不同的进程看到同一份资源。
由于各个运行进程之间具有独立性,这个独立性主要体现在数据层面,而代码逻辑层面可以私有也可以共有(例如父子进程)因而各个进程之间要实现通信是非常困难的。
各个进程之间若是想实现通信,一定要借助第三方资源,这些进程就可以通过向这个第三方资源写入或是读取,进而实现进程之间的通信,这个第三发方资源实际上就是操作系统提供的一段内存区域。

因此,进程间通信的本质就是,让不同的进程看到同一块资源(内存,文件,内存缓冲等)。由于这份资源可以由操作系统中的不同模块提供,因此出现了不同的进程间的通信方式。
6.2进程间通信的分类
6.2.1常见的进程间通信方式简介
-
管道pipe:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
-
命名管道FiFO:有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
-
消息队列:消息队列是由信息的链表,存放在内核中并有消息队列标识符标识。消息队列克服了信号传递信息少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。
-
共享存储:共享内存就是映射一段能被其它进程所访问的内存,这段共享内存由一个进程
创建,但是多个进程都可以访问。共享内存是最快的IPC方式,它是针对其它进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
-
套接字Socket:套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。
-
信号( sinal):信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
6.3管道
6.3.1什么是管道
管道是UNIX中最古老的进程间通信的形式,我们把从一个进程连接到另一个进程的数据流称为一个“管道”
例如,统计我们当前使用云服务器上的登录用户个数。

其中,who命令和wc命令都是两个程序,当它们运行起来后就变成了两个进程,who进程通过标准输出将数据打到“管道”当中,wc进程再通过标准输入从“管道”当中读取数据,至此完成了数据的传输,进而完成数据的进一步加工处理。

注明:who命令用于查看当前云服务器的登录用户(一行显示一个用户),wc -l 用于统计当前的行数。
6.3.2匿名管道
匿名管道用于进程间通信,且仅限于本地关联进程之间的通信。
进程间通信的本质就是让不同的进程看到同一块资源,使用匿名管道实现父子进程间通信的原理就是,让两个父子进程先看到同一份被打开的文件资源,然后父子进程就可以对该文件进行写入或者读取操作,进而实现父子进程间通信。

注意:
这里父子进程看到的同一份文件资源是由操作系统来维护的,所以父子进程对该文件进行写入操作时,该文件缓冲区当中的数据并不会进行写时拷贝。
管道虽然用的是文件的方案,但操作系统一定不会把进程进行通信的数据刷新到磁盘当中,因为这样做有IO参与会降低效率,而且也没有必要。也就是说,这种文件是一批不会把数据写到磁盘当中的文件,换句话说,磁盘文件和内存文件不一定是一一对应的,有些文件只会在内存当中存在,而不会在磁盘当中存在。
pipe函数
pipe函数用于创建匿名管道,pip函数的函数原型如下:
int pipe(int pipefd[2]);
pipe函数的参数是一个传出型参数,数组pipefd用于返回两个指向管道读端和写端的文件描述符:

在创建匿名管道实现父子进程间通信的过程中,需要pipe函数和fork函数搭配使用,具体步骤如下:
-
父进程调用pipe函数创建管道。

-
父进程创建子进程。

-
父进程关闭写端,子进程关闭读端。

注意:
管道只能够进行单向通信,因此当父进程创建完子进程后,需要确认父子进程谁读谁写,然后关闭相应的读写端。
从管道写端写入的数据会被存到内核缓冲,直到从管道的读端读取。
可以站在文件描述符的呃呃角度再来看看这三个步骤:
-
父进程调用pipe函数创建管道。

-
父进程创建子进程。

-
父进程关闭写端,子进程关闭读端。

例如,在以下代码当中,子进程向匿名管道当中写入10行数据,父进程从匿名管道当中将数据读出
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
int fd[2]={0};
if(pipe(fd)<0)//使用pipe创建匿名管道
{
perror("pipe");
return 1;
}
pid_t id=fork();//使用fork创建子进程
if(id==0)
{
//child
close(fd[0]);//子进程关闭读端
//子进程向管道写入数据
const char*msg="hello father,i am child...";
int count=10;
while(count--)
{
write(fd[1],msg,strlen(msg));
sleep(1);
}
close(fd[1]);//子进程写入完毕,关闭文件
exit(0);
}
close(fd[1]);//父进程关闭写端
//父进程从管道读取数据
char buff[64];
while(1)
{
ssize_t s=read(fd[0],buff,sizeof(buff));
if(s>0)
{
buff[s]='\0';
printf("child send to father%s\n",buff);
}
else if(s==0)
{
printf("read file end\n");
break;
}
else
{
printf("read erro\n");
break;
}
}
close(fd[0]);//父进程读取完毕,关闭文件
waitpid(id,NULL,0);
return 0;
}
管道读写规则
pipe2函数与pipe函数类似,也是用于创建匿名管道,其函数原型如下:
int pipe2(int pipefd[2],int flags)
pipe2函数的第二个参数用于设置选项。
-
当没有数据可读时:
-
O_NONBLOCK disableread:调用阻塞,即进程暂停执行,一直等到有数据来为止。
-
O_NONBLOCK enable:read调用返回-1,error值为EAGAIN
-
当管道满的时候:
-
O_NONBLOCK disable:read调用阻塞,直到有进程读走数据。
-
O_NONBLOCK enable:write调用返回-1,errno值为EAGAIN。
3、如果所有管道写端对应的文件描述符被关闭,则read返回0。
4、如果所有管道读端对应的文件描述符被关闭,则write操作会产生信号SIGPIPE,进而可能导致write进程退出。
5、当要写入的数据量不大于PIPE_BUF时,Linux将保证写入的原子性。
6、当要写入的数据量大于PIPE_BUF时,Linux将不再保证写入的原子性。
总结:
读管道:
1.管道中有数据,read返回实际读到的字节数。
2.管道中无数据:
-
管道写端被全部关闭,read返回0(像读到文件结尾)
-
写端没有全部被关闭,read阻塞等待(不久的将来可能有数据递达,此时会让出cpu)
写管道:
1.管道读端全部被关闭,进程异常终止(也可使用捕捉SIGPIPE信号,使进程不终止)
2.管道读端没有全部关闭:
1.管道已满, write 阻塞。
2.管道未满,write 将数据写入,并返回实际写入的字节数。
6.3.3命名管道
命名管道的原理
匿名管道只能用于具有共同祖先的进程(具有亲缘关系的进程)之间的通信,通常,一个管道由一个进程创建,然后该进程调用fork,此后父子进程之间就可应用该管道。如果要实现两个毫不相关进程之间的通信,可以使用命名管道来做到。命名管道就是一种特殊类型的文件,两个进程通过命名管道的文件名打开同一个管道文件,此时这两个进程也就看到了同一份资源,进而就可以进行通信了。
使用命令创建命名管道
mkfifo fifo

创建出来的文件类型是p,代表该文件是命名管道文件,使用这个命名管道就像使用普通文件一样,就能实现两个进程之间的通信了。
创建一个命名管道
int mkfifo(const char* pathname,mode_t mode);
mkfio函数的第一个参数是pathname,表示要创建的命名管道。
-
若pathname以路径的方式给出,则将命名管道文件创建在pathname路径下。
-
若pathname以文件名的方式给出,则将命名管道文件默认创建在当前路径下。(注意当前路径的含义)
mkfifo函数的第二个参数是mode,表示创建命名管道文件的默认权限。
umask函数将文件默认掩码设置为0。
umask(0);
mkfifo函数的返回值。
-
命名管道创建成功,返回0。
-
命名管道创建失败,返回-1。
#include <sys/types.h>
#include <sys/stat.h>
#include <stdio.h>
#define FILE_NAME "myfifo"
int main()
{
umask(0); //将文件默认掩码设置为0
if (mkfifo(FILE_NAME, 0666) < 0)
{
// 使用mkfifo创建命名管道文件
perror("mkfifo");
return 1;
}
//create success...
return 0;
}
用命名管道实现server&client通信
实现服务端(server)和客户端(client)之间的通信之前,我们需要先让服务端运行起来,需要让服务端运行后创建一个命名管道文件,然后再以读的方式打开该命名管道文件,之后服务端就可以从该命名管道当中读取客户端发来的通信信息了。
server
#include "comm.h"
int main()
{
umask(0);//将文件默认掩码设置为0
if (mkfifo(FILE_NAME,0666) < 0)
{
//使用mkfifo创建命名管道文件
perror("mkfifo");
return 1;
}
int fd = open(FILE_NAME, O_RDONLY); //以读的方式打开命名管道文件if(fd < 0) {
if(fd<0)
{
perror("open");
return 2;
}
char msg[128];
while (1)
{
msg[0] = '\0';//每次读之前将msg清空
//从命名管道当中读取信息
ssize_t s = read(fd, msg, sizeof(msg) - 1);
if (s > 0)
{
msg[s] = '\0'; // 手动设置0',便于输出
printf("client# %s\n", msg); //输出客户端发来的信息
}
else if (s == 0)
{
printf("client quit!\n");
break;
}
else
{
printf("read error!\n");
break;
}
}
close(fd); //通信完毕,关闭命名管道文件
return 0;
}
命名管道和匿名管道的区别
-
匿名管道由pipe函数创建并打开。
-
命名管道由mkfifo函数创建,由open函数打开。
FIFO(命名管道)与pipe(匿名管道)之间唯一的区别在于它们创建与打开的方式不同,一旦这些工作完成之后,它们具有相同的语义。
6.4mmap
存储映射I/O使一个磁盘文件与存储空间中的一个缓冲区相映射。于是当从缓冲区中取数据,就相当于读文件中的相应字节。于此类推,将数据存入缓冲区,则相应的字节就自动写入文件。这样,就可使用地址(指针)完成I/O操作,对文件的操作就可以改对内存的操作。
使用这种方法,首先应通知内核,将一个指定文件映射到存储域中。这个映射工作可以通过mmap函数来实现。

mmap将一个文件或者其它对象映射进内存。文件被映射到多个页上,如果文件的大小不是所有页的大小之和,最后一页不被使用的空间将会清零。
函数原型:
<sys/mman.h>
void *mmap(void *addr,size_t length,int prot,int flags,int fd,off_t offset);
int munmap(void *addr,size_t length);
6.4.1内存映射的步骤
-
用open系统调用打开文件,并返回文件描述符fd;
-
用mmap建立内存映射,并返回映射首地址指针addr;
-
对映射(文件)进行各种操作,显示,修改
-
用munmap(void *addr,size_t lenght)关闭内存映射
-
用close系统调用关闭文件fd
6.4.2主要功能
该函数主要用途有三个:
-
将一个普通文件映射到内存中,通常在需要对文件进行频繁读写时使用,这样用内存读写取代I/O读写,以获得较高的性能
-
将特殊文件进行匿名内存映射,可以为关联进程提供共享内存空间
-
为无关联的进程提供共享内存空间,一般也是将一个普通文件映射到内存中

6.4.3参数及返回值
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
参数:
-
参数addr:指向欲映射的内存起始地址,通常设为NULL,代表让系统自动选定地址,映射成功后返回该地址。
-
参数length映射区的长度。
-
参数prot:映射区域的保护方式。可以为以下几种方式的组合:
-
PROT_READ映射区域可被读取
-
PROT_WRITE映射区域可被写入
-
参数flags:影响映射区域的各种特性。在调用mmap()时必须要指定MAP_SHARED或MAP_PRIVATE。
-
MAP_SHARED对映射区域的写入数据会复制回文件内,而且允许其他映射该文件的进程共享。
-
MAP_PRIVATE对映射区域的写入操作会产生一个映射文件的复制,即私人的“写入时复制”(copy on write)对此区域作的任何修改都不会写回原来的文件内容。
-
MAP_ANONYMOUS建立匿名映射。此时会忽略参数fd,不涉及文件,而且映射区域无法和其他进程共享。
-
参数fd:要映射到内存中的文件描述符。如果使用匿名内存映射时,即flags中设置了MAP_ANONYMOUS,fd设为-1。有些系统不支持匿名内存映射,则可以使用fopen打开/dev/zero文件,然后对该文件进行映射,可以同样达到匿名内存映射的效果。
-
参数offset:文件映射的偏移量,通常设置为0,代表从文件最前方开始对应,offset必须是分页大小的整数倍。
返回值:
若映射成功则返回映射区的内存起始地址,否则返回MAP_FAILED(-1),错误原因存于errno中。
6.4.4系统掉用mmap()用于共享内存的两种方式
-
使用普通文件提供的内存映射:
适用于任何进程之间。此时,需要打开或创建一个文件,然后再调用mmap ()典型调用代码如下:
fd=open(name, flag, mode); if(fd<0) ...
ptr=mmap(NULL, len , PROT_READ|PROT_WRITE, MAP_SHARED , fd , 0);
-
使用特殊文件提供匿名内存映射:
适用于具有亲缘关系的进程之间。由于父子进程特殊的亲缘关系,在父进程中先调mmap(),然后调用fork()。那么在调用fork()之后,子进程继承父进程匿名映射后的地址空间,同样也继承mmap()返回的地址,这样,父子进程就可以通过映射区域进行通信了。注意,这里不是一般的继承关系。一般来说,子进程单独维护从父进程继承下来的一些变量。而mmap()返回的地址,却由父子进程共同维护。对于具有亲缘关系的进程实现共享内存最好的方式应该是采用匿名内存映射的方式。此时,不必指定具体的文件,只要设置相应的标志即可。
6.4.5mmap注意事项
1.创建映射区的过程中,隐含着一次对映射文件的读操作。
2.当MAP_SHARED时,要求:映射区的权限应<=文件打开的权限(出于对映射区的保护)。而MAP_PRIVATE则无所谓,因为mmap中的权限是对内存的限制。
3.映射区的释放与文件关闭无关。只要映射建立成功,文件可以立即关闭。
4.特别注意,当映射文件大小为0时,不能创建映射区。所以:用于映射的文件必须要有实际大小! ! mmap使用时常常会出现总线错误,通常是由于共享文件存储空间大小引起的。如,400字节大小的文件,在建立映射区时offset 4096字节,则会报出总线错。
5. munmap传入的地址一定是mmap的返回地址。坚决杜绝指针++操作。
6.如果文件偏移量必须为4K的整数倍
7.mmap创建映射区出错概率非常高,一定要检查返回值,确保映射区建立成功再进行后续操作。
6.5消息队列
6.5.1消息队列概念
消息队列可以看作一个消息链表,有足够写权限的进程可往队列中放置消息,有足够读权限的进程可从队列中取走消息。每个消息都是一个记录,它由发送者赋予一个优先级。在某个进程往一个队列写入消息之前,并不需要另外某个进程在该队列上等待消息的到达(恰好与PIPE和 FIFO相反,因为管道中除非读出者已存在,否则先有写入者是没有意义的)。

6.5.2消息队列的创建和关闭
POSIX消息队列的创建,关闭和删除用的以下三个函数接口:
#include <mqueue.h>
mqd_t mq_open(const char *name, int oflag, /* mode_t mode,struct mq_attr *attr */);
//成功返回消息队列描述符,失败返回 -1
mqd_t mq_close(mqd_t mqdes);
mqd_t mq_unlink(const char *name);
mq_open函数
mq_open函数用于创建一个新的消息队列或打开一个已存在的消息列表。
mq_close函数
mq_close用于关闭一个消息队列,和文件的close类型,关闭后,消息队列并不从系统中删除。一个进程结束,会自动调用关闭打开的消息队列。
6.5.3消息队列的属性
struct mq_attr
{
long mq_flags;/* Message queue flags(0,O_NONBLOCK)*/
long mq_maxmsg; /* Maximum number of messages.*/最大消息数
long mq_msgsize;/* Maximum message size.*/最大消息大小
long mq_curmsgs;/*Number of messages currently queued.*/当前消息的个数
};
6.5.4POSIX消息队列的使用
6.5.5消息队列限制
POSIX消息队列本身的限制就是mq_attr中的mq_maxmsg和mq_msgsize,分别用于限定消息队列中的最大消息数和每个消息的最大字节数。在前面已经说过了,这两个参数可以在调用mq_open创建一个消息队列的时候设定。当这个设定是受到系统内核限制的。
第七章 内存管理
7.1操作系统存储层次
常见的计算机存储层次如下:
-
寄存器:CPU提供的,读写ns级别,容量字节级别
-
主存:动态内存,读写100ns级别,容量GB级别
-
外部存储介质:磁盘、SSD,读写ms级别,容量可扩展到TB级别。
这里忽略CPU的缓存、主存的磁盘以及磁盘的缓存
7.2什么是内存
简单地说,内存就是一个数据货架。内存是一个最小的存储单位,大多数都是一个字节。内存用内存地址来为每个字节的数据顺序编号。因此,内存地址说明了数据在内存中的位置。内存地址从0开始,每次增加1。这种线性增加的存储器地址称为线性地址(linear address)。为了方便,我们用十六进制数来表示内存地址,比如0x00000003、0x1A010CB0。这里“0x"用来表示十六进制。“0x"后面跟着的,就是作为内存地址的十六进制数。
内存地址的编号有上限。地址空间的范围和地址总线(address bus)的位数直接相关。CPU通过地址总线来向内存说明想要存取数据的地址。以英特尔32位的80386型CPU为例,这款CPU有32个针脚可以传输地址信息。每个针脚对应了一位。如果针脚上是高电压,那么这一位是1。如果是低电压,那么这一位是0。32位的电压高低信息通过地址总线传到内存的32个针脚,内存就能把电压高低信息转换成32位的二进制数,从而知道CPU想要的是哪个位置的数据。用十六进制表示,32位地址空间就是从0x00000000到0xFFFFFFFF。
内存的存储单元采用了随机读取存储器(RAM,Random Access Memory)。所谓的“随机读取”,是指存储器的读取时间和数据所在位置无关。与之相对,很多存储器的读取时间和数据所在位置有关。就拿磁带来说,我们想听其中的一首歌,必须转动带子。如果那首歌是第一首,那么立即就可以播放。如果那首歌恰巧是最后一首,我们快讲到可以播放的位置就需要花很长时间。我们已经知道,进程需要调用内存中不同位置的数据。如果数据读取时间和位置相关的话,计算机就很难把控进程的运行时间。因此,随机读取的特性是内存成为主存储器的关键因素。
内存提供的存储空间,除了能满足内核的运行需求,还通常能支持运行中的进程。即使进程所需空间超过内存空间,内存空间也可以通过少量拓展来弥补。换句话说,内存的存储能力,和计算机运行状态的数据总量相当。内存的缺点是不能持久地保存数据。一旦断电,内存中的数据就会消失。因此,计算机即使有了内存这样一个主存储器,还是需要硬盘这样的外部存储器来提供持久的储存空间。
7.3早期的内存分配机制
在早期的计算机中,要运行一个程序,需要把程序全部加载到物理内存(可以理解为内存条上的内存,所有的程序运行都是在内存中运行,CPU运行程序时,如果要访问外部存储诸如磁盘,那么必须先把磁盘内存拷贝到内存中CPU才能操作,内存是CPU和外部存储的桥梁)如果我们的一个计算机只运行一个程序,那么只有这个程序所需要的内存空间不超过物理内存空间的大小,就不会有问题,计算机如何把有限的物理内存分配给多个程序使用呢?
某台计算机总的物理内存大小是128M,现在同时运行两个程序A和B,A需占用内存10M,B需占用内存110M。计算机在给程序分配内存时会采取这样的方法:先将内存中的前10M分配给程序A,接着再从内存中剩余的118M中划分出110M分配给程序B。这种分配方法可以保证程序A和程序B都能运行,但是这种简单的内存分配策略问题很多。

7.4虚拟内存
内存的一项主要任务,就是存储进程的相关数据。之前已经看到过进程空间的程序段、全局数据、堆和栈,以及这些存储结构在进程运行中所起的关键作用。有趣的是,尽管不能直接读写内存中地址的关系如此紧密,但进程并不能直接访问内存。在Linux下,进程不能直接读写内存中地址为0x1位置的数据。进程中能访问的地址,只能是虚拟内存地址(virtual memory address)。操作系统会把虚拟内存地址翻译成真实的内存地址。这种内存管理方式,称为虚拟内存(virtual memory)。
每个进程都有自己的一套虚拟内存地址,用来给自己的进程空间编号。进程空间的数据同样以字节为单位,依次增加。从功能上说,虚拟内存地址和物理内存地址类似,都是为数据提供位置索引。进程的虚拟内存地址相互独立。因此,两个进程空间可以有相同的虚拟内存地址,如0x10001000。虚拟内存地址和物理内存地址又有一定的对应关系,如图1所示。对进程某个虚拟内存地址的操作,会被CPU翻译成对某个具体内存地址的操作。

图1 虚拟内存地址和物理内存地址的对应
应用程序来说对物理内存地址一无所知。它只可能通过虚拟内存地址来进行数据读写。程序中表达的内存地址,也都是虚拟内存地址。进程对虚拟内存地址的操作,会被操作系统翻译成对某个物理内存地址的操作。由于翻译的过程由操作系统全权负责,所以应用程序可以在全过程中对物理内存地址一无所知。因此,C程序中表达的内存地址,都是虚拟内存地址。比如在C语言中,可以用下面指令来打印变量地址:
int v =0;
printf( "%p", (void* ) &v);
本质上说,虚拟内存地址剥夺了应用程序自由访问物理内存地址的权利。进程对物理内存的访问,必须经过操作系统的审查。因此,掌握着内存对应关系的操作系统,也掌握了应用程序访问内存的闸门。借助虚拟内存地址,操作系统可以保障进程空间的独立性。只要操作系统把两个进程的进程空间对应到不同的内存区域,就让两个进程空间成为“老死不相往来"的两个小王国。两个进程就不可能相互篡改对方的数据,进程出错的可能性就大为减少。
另一方面,有了虚拟内存地址,内存共享也变得简单。操作系统可以把同一物理内存区域对应到多个进程空间。这样,不需要任何的数据复制,多个进程就可以看到相同的数据。内核和共享库的映射,就是通过这种方式进行的。每个进程空间中,最初一部分的虚拟内存地址,都对应到物理内存中预留给内核的空间。这样,所有的进程就可以共享同一套内核数据。共享库的情况也是类似。对于任何一个共享库,计算机只需要往物理内存中加载一次,就可以通过操纵对应关系,来让多个进程共同使用。IPC中的共享内存,也有赖于虚拟内存地址。
虚拟化的出现和硬件有密不可分的联系,可以说是软硬件组合的结果,虚拟地址空间就是在程序和物理空间所增加的中间层,这也是内存管理的重点。
7.5内存分页
虚拟内存地址和物理内存地址的分离,给进程带来便利性格安全性。但虚拟内存地址和物理内存地址的翻译,又会额外耗费计算机资源。在多任务的现代计算机中,虚拟内存地址已经成为必备的设计。那么,操作系统必须要考虑清楚,如何能高效地翻译虚拟内存地址。
记录对应关系最简单的办法,就是把对应关系记录在一张表中。为了让翻译速度足够地快,这个表必须加载在内存中。不过,这种记录方式惊人地浪费。如果树莓派1GB物理内存的每个字节都有一个对应记录的话,那么光是对应关系就要远远超过内存的空间。由于对应关系的条目众多,搜索到一个对应关系所需的时间也很长。这样的话,会让树莓派陷入瘫痪。
因此,Linux采用了分页(paging)的方式来记录对应关系。所谓的分页,就是以更大尺寸的单位页(page)来管理内存。在Linux中,通常每页大小为4KB。如果想要获取当前系统的的内存页大小,可以使用命令:
$getconf PAGE_SIZE
得到结果,即内存分页的字节数:
4096
返回的4096代表每个内存页可以存放4096个字节,即4KB。Linux把物理内存和进程空间都分割成页。
内存分页,可以极大地减少所要记录的内存对应关系。我们已经看到,以字节为单位的对应记录实在太多。如果把物理内存和进程空间的地址都分成页,内核只需要记录页的对应关系,相关的工作量就会大为减少。由于每页的大小是每个字节的4000倍。因此,内存中的总页数只是总字节数的四千分之一。对应关系也缩减为原始策略的四千分之一。分页让虚拟内存地址的设计有了实现的可能。
无论是虚拟页,还是物理页,一页之内的地址都是连续的。这样的话,一个虚拟页和一个物理页对应起来,页内的数据就可以按顺序——对应。这意味着,虚拟内存地址和物理内存地址的末尾部分应该完全相同。大多数情况下,每一页有4096个字节。由于4096是2的12次方,所以地址最后12位的对应关系天然成立。我们把地址的这一部分称为偏移量(offset)。偏移量实际上表达了该字节在页内的位置。地址的前一部分则是页编号。操作系统只需要记录页编号的对应关系。

7.6多级分页表
内存分页制度的关键,在于管理进程空间页和物理页的对应关系。操作系统把对应关系记录在分页表(page table)中。这种对应关系让上层的抽象内存和下层的物理内存分离,从而让Linux能灵活地进行内存管理。由于每个进程会有一套虚拟内存地址,那么每个进程都会有一个分页表。为了保证查询速度,分页表也会保存在内存中。分页表有很多种实现方式,最简单的一种分页表就是把所有的对应关系记录到同一个线性列表中,即如图2中的“对应关系”部分所示。
这种单一的连续分页表,需要给每一个虚拟页预留一条记录的位置。但对于任何一个应用进程,其进程空间真正用到的地址都相当有限。我们还记得,进程空间会有栈和堆。进程空间为栈和堆的增长预留了地址,但栈和堆很少会占满进程空间。这意味着,如果使用连续分页表,很多条目都没有真正用到。因此,Linux中的分页表,采用了多层的数据结构。多层的分页表能够减少所需的空间。我们来看一个简化的分页设计,用以说明Linux的多层分页表。我们把地址分为了页编号和偏移量两部分,用单层的分页表记录页编号部分的对应关系。对于多层分页表来说,会进一步分割页编号为两个或更多的部分,然后用两层或更多层的分页表来记录其对应关系,如图3所示。

在图3的例子中,页编号分成了两级。第一级对应了前8位页编号,用2个十六进制数字表示
7.7页表项
7.9常见的页面置换算法
在地址映射过程中,如果在页面
-
最优算法在当前页面中置换最后要访问的页面。不
第八章 信号
8.1信号的概念
信号在我们的生活中随处可见,如:古代战争中摔杯为号;现代战争中的信号弹;体育比赛中使用的信号枪他们都有共性:
-
简单
-
不能携带大量信息
-
满足某个特设条件才发送
信号是信息的载体,Linux/UNIX环境下,古老、经典的通信方式,现下依然是主要的通信手段。
UNIX早期版本就提供了信号机制,但不可靠,信号可能丢失。Berkeley和AT&T都对信号模型做了更改,增加了可靠的机制。但彼此不兼容。POSIX.1对可靠信号历程进行了标椎化。
8.2信号的机制
A给B发送信号,B收到信号之前执行自己的代码,收到信号后,不管执行到程序的什么位置,都要暂停运行,去处理信号,,处理完毕再继续执行。与硬件中断类似---异步模式。但信号时软件层面上实现的中断,早期常被称为“软中断”。
信号的特质:由于信号是通过软件方法实现,其实现手段导致信号有很强的延时性但对于用户来说,这个延迟时间非常短,不易察觉。
每个进程收到的所有信号,都是由内核负责发送的内核处理。
8.3与信号相关的事件和状态
产生信号:
-
按键产生,如:Ctrl+c、Ctrl+z、Ctrl+\
-
系统调用产生,如:kill、raise、about
-
软件条件产生,如:定时器(闹钟)alarm
-
硬件异常产生,如:非法访问内存(段错误)、除0(浮点数例外)、内存对齐出错(总线错误)
-
命令产生,如:kill命令
递达:递送并且到达进程
未决:产生递达之间的状态。主要由于阻塞(屏蔽)导致该状态。
8.4信号的处理方式
-
执行默认动作
-
忽略(丢弃)
-
捕捉(调用户处理函数)
Linux内核的进程控制块PCB时一个结构体,task_struct,除了包含进程id,状态,工作目录,用户id,组id,文件描述符,还包含了信号相关的信息,主要指阻塞信号集和未决信号集。
阻塞信号集(信号屏蔽字):
将某些信号加入集合,对他们设置屏蔽,当屏蔽x信号后,再收到该信号,该信号的处理将推后(解除屏蔽后);
未决信号集:
-
信号产生,未决信号集中描述该信号的位立刻翻转为1,表示信号处于未决状态。当该信号被处理,对应位翻转回为0。这一刻往往非常短暂。
-
信号产生后由于某些原因(主要是阻塞)不能抵达。这类信号的集合称之为未决信号集。在屏蔽解除前,信号一直处于未决状态。
8.5信号的编号
可以使用kill-I命令查看当前系统可使用的信号用哪些。
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 1 9) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
不存在编号为0的信号。其中1-31号信号称之为常规信号(也叫普通信号或标准信号),34-36称之为实时信号,驱动编程与硬件相关。名字区别不大。而前32个名字各不相同。
8.6信号4要素
与变量三要素类似的,每个信号也有其必备4要素,分别是:
-
编号 2.名称 3默认处理动作 4.事件
可通过man 7 signal查看帮助文档获取。
默认动作:
Term:终止进程
Ign:忽略信号(默认)
Core:终止信号,生成Core文件。(查验进程死亡原因,用于gdb调试)
Stop:停止(暂停)进程
Cont:继续运行进程
注意从man 7 signal帮助文档中查看到:The signal SIGKILLand SIGSTOP cannot be caught,blocked,or ignored.
这里特别强调了9)SIGKLL和19)SIGSTOP信号,不允许忽略和捕捉,只能执行默认动作。甚至不能将其设置为阻塞。
另外需清楚,只有每个信号所对应的事件发生了,该信号才会被递送(但不一定递达),不应乱发信号。
8.7Linux常规信号一览表
-
SIGHUP:
8.8信号的产生
8.8.1终端按键产生信号
8.8.2硬件异常产生信号
8.8.3kill函数/命令产生信号
kill命令产生信号:kill-SIGKILL pid
kill函数:给指定进程发送指定信号(不一定杀死)
8.8.4软件条件产生信号
alarm函数
设置定时器(闹钟)。在指定seconds后,内核会给当前进程发送14)SIGALRM信号。进程收到该信号,默认动作终止。
每个进程都有且只有唯一个定时器。
unsigned int alarm(unsigned int seconds);返回0或剩余的秒数,无失败。
常用:取消定时器alarm(0),返回旧时钟余下秒数。
例:alarm(5)—>3se—>calarm(4)—>5sec—>alarm(5)—>alarm(0)
定时,与进程状态无关(自然定时法)!就绪、运行、挂起(阻塞、暂停)、终止、僵尸···无论进程处于何种状态,alarm都计时。
使用time命令查看程序执行的时间。程序运行的瓶颈在于IO,优化程序,首选优化IO。
实际执行时间=系统时间+用户时间+等待时间
setitimer函数
设置定时器(闹钟)。可代替alarm函数。精度微秒us,可以实现周期定时。
8.9信号集操作函数
内核通过读取未决信号集来判断信号是否应被处理。信号屏蔽字mask可以影响未决信号集。而我们可以在应用程序中自定义set来改变mask。已达到屏蔽指定信号的目的。
8.9.1信号集设定
sigset_t set;//typedef usigned long sigset_t;
int sigemptyset(sigset_t *set);
功能:蒋某个信号集清零
成功:0;失败:-1
int sigfillset(sigset_t,*set)
功能:蒋某个信号集置1
成功:0;失败:-1
int sigaddset(sigset_t*set,intsignum);
功能:将某个信号加入信号集
成功:0;失败:-1
int sigdelset(sigset_t*set,int signum);
功能:将某个信号清除信号集
成功:0;失败:-1
intsigismember(const sigset_t*set,intsignum);
判断某个信号是否在信号集中
在:1;不在:0;出错:-1;
sigset_t类型的本质是位图。但不应该直接使用位操作,而应该使用上述函数,保证跨系统操作有效。
sigprocmask函数
用来屏蔽信号、解除屏蔽也使用该函数。其本质,读取或修改进程的信号屏蔽字(PCB中)
严格注意,屏蔽信号:只是将信号处理延后执行(延至解除屏蔽);而忽略表示将信号做丢弃处理。
int sigprocmask(int how,const sigset_t*set,sigset_t*oldset);
成功:0;失败:-1,设置errno
参数:
set:传入参数,是一个位图,set中哪位置1,就表示当前进程屏蔽哪个信号。
oldset:传出参数,保存旧的信号屏蔽集。
how参数取值:假设当前的信号屏蔽字为mask
-
SIG_BLOCK:当how设置为此值,set表示需要屏蔽的信号。相当于mask=mask|set
-
SIG_UNBLOCK:当how设置为此值,set表示需要解除屏蔽的信号。相当于mask=mask & ~set
-
SIG_SETMASK:当how设置为此值,set表示用于替代原始屏蔽集的新屏蔽集。相当于mask=set,若调用signprocmask解除了对当前若干个信号的阻塞,则在sigprocmask返回前,至少将其中一个信号递达。
sigpending函数
读取当前进程的未决信号集
int sigpending(sigset_t*set);
set传出参数。
返回值:成功:0;失败:-1,设置errno
8.10信号捕捉
signal函数
注册一个信号捕捉函数:
typedef void(*sighandler_t)(int);
sighandler_t signal(int signmu,sighandler_t handler);
该函数由ANSI定义,由于历史原因在不同版本的UNIX和不同版本的Linux中可能有不同的行为。因此应该尽量避免使用它,取而代之使用sigaction函数。
sigaction函数
修改信号处理动作(通常在Linux用来注册一个信号的捕捉函数)
int sigaction(int signum,const strutsigactionact,struct sigaction * oldact);
成功:0;失败:-1,设置errno
参数:
act:传入参数,新的处理方式。
oldact:传出参数,旧的处理方式。
第九章 线程
9.1线程概念
-
LWP:light weight process 轻量级的进程,本质仍是进程(在Linux环境下)
-
进程:独立地址空间,拥有PCB
-
线程:也有PCB,但没有独立的地址空间(共享)
-
区别:在于是否共享地址空间。独居(进程);合租(线程)。
-
Linux下:线程:最小的执行单位,调度的基本单位。
-
进程:最小分配资源单位,可看成时只有一个线程的进程。
9.2线程控制原语
9.2.1pthread_self函数
功能:获取线程ID其作用对应进程中个getpid()函数。
-
pthread_t pthread_self(void);返回值:成功:0;失败:无!
-
线程ID:pthread_t类型,本质:在Linux下为无符号整数(%lu),其它系统中可能是结构体实现
-
线程ID是进程内部,识别标志。(两个进程间,线程ID允许相同)
-
注意:不应该使用全局变量pthread_t tid,在子线程中通过pthread_create传出参数来获取线程ID,而应使用pthread_self。
9.2.2ptherad_create函数
功能:创建一个新线程。其作用,对应进程中fork()函数。
-
int pthread_create(ptherad_t *thread,const pthread_attr_*attr,void*(*start_routine)(void*),void *arg);
-
返回值:成功:0;失败:错误号----Linux环境下,所用线程特点,失败均直接返回错误号。
参数:
-
pthread_t:当前Linux中可理解为:typedef unsigned long int pthread_t;
-
参数1:传出参数,保存系统为我们分配好的线程ID
-
参数2:通常传NULL,表示使用线程默认属性。若想使用具体属性也可以修改该参数。
-
参数3:函数指针,指向线程主函数(线程体),该函数运行结束,则线程结束。
-
参数4:线程主函数执行期间所使用的参数,如要传多个参数,可以使用结构体封装
9.2.3pthread_exit函数
功能:将单个线程退出
-
void pthread_exit(void *retval);参数:retval表示线程退出状态,通常传NULL
使用exit将指定线程退出,可以吗?
结论:线程中禁止使用exit函数,会导致进程内所有线程全部退出。
在不添加sleep控制输出顺序的情况下。pthread_create在循环中,几乎瞬间创建5个线程,但只有第1个线程有机会输出(或者第2个也有,也可能没有,取决于内核调度)如果第三个线程执行了exit,将整个进程退出了,所以全部线程退出了。
所以,多线程环境中应尽量少用,或者不适用exit函数,取而代之使用pthread_exit函数,将单个线程退出。任何线程里exit导致进程退出
9.2.4pthread_join函数
功能:回收线程
int pthread_join(pthread_t thread,void **retval);
成功:0;失败:错误号
参数:thread线程ID;
retval:储存线程结束状态。
第十章 线程同步
进程的重点是进程间通信,线程是线程同步。fork()创建子进程之后,子进程有自己的独立地址空间和PCB,想和父进程或其它进程通信,就需要各种通信方式,例如管道(无名管道)、有名管道(命名管道)、信号、消息队列、共享内存等;而pthread_create创建子线程之后,子线程没有独立的地址空间,大部分数据都是共享的,如果同时访问数据,就会造成混乱,所以要控制,就是线程同步了。
10.1什么时线程同步
同步就是协同步调,按预定的先后次序进行运行。如:你说完,我再说。这里的同步不是同时进行。应是指协同、协助、互相配合。线程同步是指多线程通过特定的设置(如互斥量,条件变量等)来控制线程之间的执行顺序(即所谓的同步)也可以说是线程之间通过同步建立起执行顺序的关系,如果没有同步,那线程之间是各自运行各自的!
线程互斥是指对于共享的进程系统资源,在各单个线程访问时的排它性。当有若干个线程都要使用某一共享资源时,任何时刻最多只允许一个线程去使用,其它要使用该资源的线程必须等待,直到占用资源者释放该资源。
10.2线程同步的方式
10.2.1互斥锁(互斥量)
-
介绍

Linux中提供了一把互斥锁mutex(也称之为互斥量)。
每个线程在对资源操作前都尝试先加锁,成功加锁才能操作,操作结束解锁。
资源还是共享的,线程间也还是竞争的,但通过“锁”就将资源的访问变成互斥操作,而后与时间有关的错误也不会再产生了。
(2)相关函数
主要应用函数:
pthread_mutex_init 函数
pthread_mutex_destory 函数
pthread_mutex_lock 函数
pthread_mutex_trylock 函数
pthread_mutex_unlock 函数
函数解释
1、
int pthread_mutex_init(pthread_mutex_t *mutex,const pthread_mutexattr_t *mutexattr)
功能:初始化一个互斥锁(互斥量)
参1:传出参数,调用时应传&mutex
参2: 互斥量属性。是一个传入参数,通常传NULL,选用默认属性(线程间共享)。
2、
int pthread_mutex_lock(pthread_mutex_t *mutex);
功能:加锁
如果加锁不成功,线程阻塞,阻塞到持有互斥量的其它线程解锁为止。
3、
int pthread_mutex_trylock(pthread_mutex_t *mutex);
功能:尝试加锁
trylock 加锁失败直接返回错误号(如:EBUSY) ,不阻塞。
4、
int pthread_mutex_unlock(pthread_mutex_t *mutex);
功能:解锁
unlock主动解锁函数,同时将阻塞在该锁上的所有线程全部唤醒,至于哪个线程先被唤醒,取决于优先级、调度。默认:先阻塞、先唤醒。
5、
int pthread_mutex_destroy(pthread_mutex_t *mutex);
功能:销毁一个互斥锁
以上5个函数的返回值都是:成功返回 0,失败返回错误号。
pthread_mutex_t类型,其本质是一个结构体。为简化理解,应用时可忽略其实现细节,简单当成整数看待。
pthread_mutex_t mutex;变量mutex只有两种取值1、0。
在访问共享资源前加锁,访问结束后立即解锁。锁的“粒度”应越小越好。
10.2.2读写锁
与互斥量类似,但读写锁允许更高的并行性。其特性为:写独占,读共享(读锁优先级高于写锁)。
特别强调:读写锁只有一把,但其具备两种状态:
-
读模式下加锁状态(读锁)
-
写模式下加锁状态(写锁)
读写锁特性:
-
读写锁是“写模式加锁”时,解锁前,所有对该锁加锁的线程都会被阻塞。
-
读写锁是“读模式加锁”时,如果线程以读模式对其加锁会成功;如果线程以写模式加锁会阻塞。
3、如果一个读线程和一个写线程同时申请读写锁,读线程优先加锁。
读写锁也叫共享-独占锁。当读写锁以读模式锁住时,它是以共享模式锁住的;当它以写模式锁住时,它是以独占模式锁住的。写独占、读共亭。
读写锁非常适合于对数据结构读的次数远大于写的情况。
读写锁的场景分析
一:均是读要求
当下面4个线程请求读锁时,不管是否是同时,都能成功上锁访问数据。

二:均是写要求
当下面四个线程同时请求写锁时,因为写独占,所以只能依次加锁,谁先抢到谁先加锁,没抢到的阻塞等待写锁被释放再继续加锁。

三:线程持有写锁期间,读线程和写线程同时申请加锁
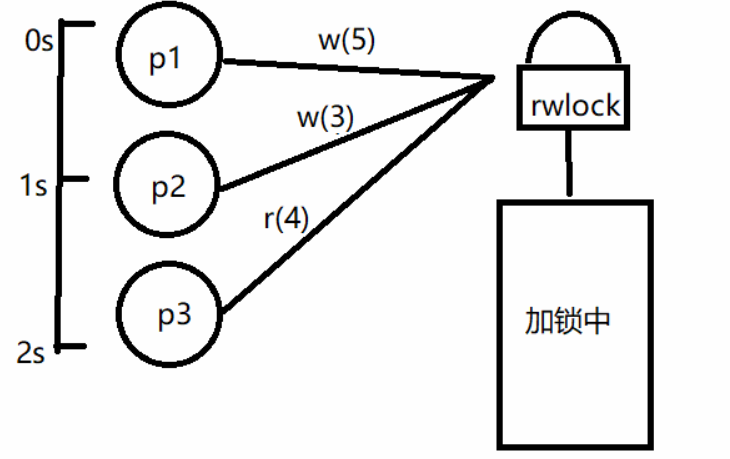
在开始的时侯p1持有写锁并持续持有5秒,在第1秒时p2线程申请写锁,因为写独占,p2会阻塞等待,在第2秒时p3线程申请读锁,也因为写独占p3线程也无法加锁成功导致在线程持有写锁期间,读线程和写线程同时申请加锁,p2,p3线程会一直阻塞直到p1线程解锁,在ubuntu20中,读锁优先级高于写锁,导致在p1解锁时,p3线程会加锁成功。
四:某线程持有读锁期间,读线程和写线程同时申请加锁
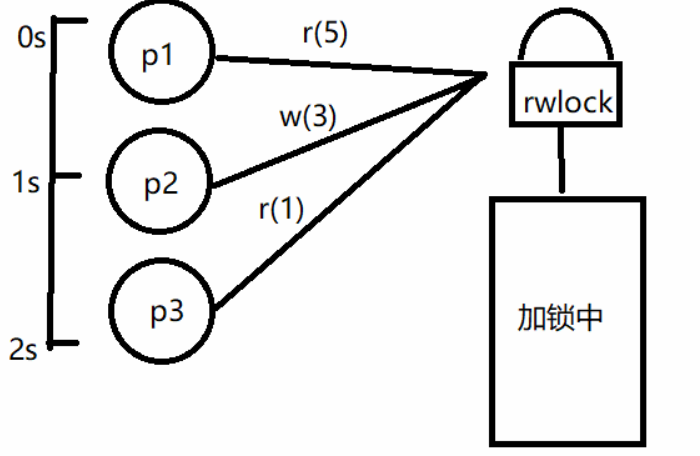
在开始时p1请求读锁并持续持有读锁5秒钟,在第1秒时p2请求写锁会被阻塞,在第2秒时p3请求读锁,这个时候相当于在p1持有读锁时,p2, p3都想加锁且分别为请求写锁和读锁,在ubuntu20中,读锁优先级高于写锁,所以p3会加锁成功,p2需要等到p3解锁后才能加锁成功,如果在p3持有读锁期间还有其他线程持续请求读锁也会加锁成功,可能会导致p2一直无法请求写锁成功,造成饥饿。
相关函数
主要应用函数
int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock,
const pthread_rwlockattr_t * restrict attr);
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);
int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock);
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);
int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock);
int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
10.2.3条件变量
条件变量本身不是锁!但它也可以造成线程阻塞。通常与互斥锁配合使用。给多线程提供一个会合的场所。
相关函数
函数解析
1、
int pthread_cond_init(pthread_cond_t *cond, pthread_condattr_t *cond_attr);
功能:初始化一个条件变量
参1:要初始化的条件变量
参2: attr表条件变量属性,通常为默认值,传NULL即可
2、
int pthread_cond_destroy(pthread_cond_t *cond);
功能:销毁一个条件变量
3、
int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex);
功能:阻塞等待一个条件变量函数作用:
1、阻塞等待条件变量cond(参1)满足
2、释放已掌握的互斥锁(解锁互斥量)相当于pthread_mutex_unlock(&mutex);1、2、两步为一个原子操作。
3、当被唤醒,pthread_cond_wait函数返回时,解除阻塞并重新申请获取互斥锁pthread_mutex_lock (&mutex) ;
4、
int pthread_cond_timedwait(pthread_cond_t *cond,pthread_mutex_t *mutex, const struuct
功能:限时等待一个条件变量
参3:查看struct timespec结构体。
struct timespec
{
time_t tv_sec; /* seconds*/秒
long tv_nsec; /* nanosecondes*/纳秒
}
形参abstime:绝对时间。
如: time(NULL)返回的就是绝对时间。而alarm(1)是相对时间,相对当前时间定时1秒钟。
struct timespec t = {1,0};
pthread_cond_timedwait (&cond, &mutex,&t);只能定时到1970 年1月1日00:00:01秒(早已经过去)
正确用法:
time_t cur = time (NULL);获取当前时间。
struct timespec t;定义 timespec结构体变量t
t. tv_sec = cur+1;定时1秒
5、
int pthread_cond_signal(pthread_cond_t *cond);
功能:唤醒一个阻塞在条件变量上的线程
6、
int pthread_cond_broadcast(pthread_cond_t *cond);
功能:唤醒全部阻塞在条件变量上的线程
10.3生产者消费者模型
线程同步典型的案例即为生产者消费者模型,而借助条件变量来实现这一模型,是比较常见的一种方法。假定有两个线程,一个模拟生产者行为,一个模拟消费者行为。两个线程同时操作一个共享资源(一般称之为汇聚),生产者向其中添加产品,消费者从中消费掉产品。
条件变量的优点:
相较于mutex 而言,条件变量可以减少竟争。
如直接使用mutex,除了生产者、消费者之间要竞争互斥量以外,消费者之间也需要竞争互斥量,但如果汇聚(链表)中没有数据,消费者之间竞争互斥锁是无意义的。有了条件变量机制以后,只有生产者完成生产,才会引起消费者之间的竞争。提高了程序效率。
10.4信号量
信号量是用来解决线程间同步或互斥的一种机制,也是一个特殊的变量,变量的值代表着当前可以利用的资源数。
如果等于0,那就意味着现在没有资源可用。
根据信号量的值可以将信号量分为二值信号量和计数信号量:
(计数信号量)就像一间公共厕所,里面一共有十个坑(最大是32767),算是十个资源。在同一时间可以容纳十个人,当满员的时候,外面的人必须等待里面的人出来,释放一个资源,然后才能再进一个,当他进去之后,厕所又满员了,外面的人还得继续等待……
(二值信号量)就像自己家的卫生间,一般只有一个马桶,在同一时间只能有一个人来用。
信号量只能进行两个原子操作,P操作和V操作,概念:
原子操作,就是不能被更高等级中断抢夺优先的操作。
由于操作系统大部分时间处于开中断状态,所以,一个程序在执行的时候可能被优先级更高的线程中断。
而有些操作是不能被中断的,不然会出现无法还原的后果,这时候,这些操作就需要原子操作。就是不能被中断的操作。
P操作:如果有可用的资源(信号量>0),那么占用一个资源(信号量-1)。如果没有可用的资源(信号量=0),则进程被阻塞,直到系统重新给他分配资源。
V操作:如果在该信号量的等待队列中有进程在等待该资源,则唤醒一个进程,否则释放一个资源(信号量+1)
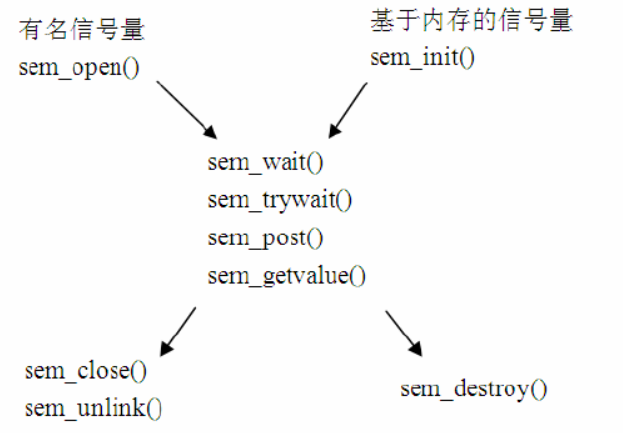
POSIX提供两种信号量,有名信号量和无名信号量,有名信号量一般是用在进程间同步,无名信号量一般用在线程间同步。
两种信号量的操作流程,大概有下面的几点不同:
主要在于两种信号量初始化和销毁的方式不同。
还有一点是非常需要注意的,和在操作共享内存时需要连接库一样,在编译信号量的时候,也需要加上-pthread参数。
10.4.1有名信号量
1、创建有名信号量:
创建或者打开一个信号量,需要使用sem_open()函数,函数原形如下:
sem_t sem_open(const char * name, int oflag, mode_t mode,unsigned intvalue)
返回值sem_t是一个结构,如果函数调用成功,则返回指向这个结构的指针,里面装着当前信号量的资源数。
参数name,就是信号量的名字,两个不同的进程通过同一个名字来进行信号量的传递。参数oflag,当他是o_CREAT时,如果name给出的信号量不存在,那么创建,此时必须给出mode和vaule。也可以指定O_EXCL
参数mode,很好理解,用来指定信号量的权限。
参数vaule,则是信号量的初始值。
2、关闭有名信号量:
关闭有名信号量所使用的函数是sem_close(sem_t *sem)
这个函数只有一个参数,意义也非常明显,就是指信号量的名字。
3、信号量操作:
在使用信号量时,有两个非常重要的操作
P操作:使用的函数是sem_wait(sem_t *sem)
如果信号量的值大于零,sem_wait函数将信号量减一,并且立即返回。如果信号量的值小于零,那么该进程会被阻塞在原地。
V操作:使用的函数是sem_post(sem_t *sem)
当一个进程使用完某个信号量时,他应该调用sem_post函数来告诉系统收回资源。sem_post函数和sem_wait函数的功能刚好相反,他会把指定的信号量加一
4、删除有名信号量:
当使用完有名信号后,需要调用函数sem_unlink来释放资源。
函数原形: int sem_unlink (const char *name)
10.4.2无名信号量
无名信号量常用于多线程间的同步,同时也用于相关进程间的同步。
1、初始化信号量
int sem_init(sem_t *sem, int pshared, unsigned int value);
sem是要进行初始化的信号量
pshared==0用于同一进程下多线程的同步;
若pshared>0用于多个相关进程间的同步(即fork产生的)
value则是信号量的初始值。
2、获取信号量的值
int sem_getvalue(sem_t *sem, int *sval);
3、销毁信号量
int sem_destroy(sem_t *sem);
10.5死锁
10.5.1死锁产生的原因
死锁产生的原因大致有两个:
-
资源竞争
-
程序执行顺序不当
注意:死锁并不是锁,而是在使用锁的过程中遇到的一种现象
10.5.2死锁产生的必要条件
资源死锁可能出现的情况主要有
-
互斥条件:资源要么被分配给一个进程,要么资源是可用的
-
保持和等待条件:已经获取资源的进程被认为能够获取新的资源
-
不可抢占条件:分配给一个进程的资源不能强制的被其他进程抢占,它只能由占有它的进程显示释放
-
循环等待:死锁发生时,系统中一定有两个或者两个以上的进程组成一个循环,循环中的每个进程都在等待下一个进程释放的资源。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









