






目录
(6)修改slaves文件,打开该配置文件,先删除里面的内容(默认是localhost)
4.5 执行结束后,hadoop02和hadoop03上执行命令:
一、实验环境及工具介绍
1、集群环境(Linux)
VMware版本:16.2.4
Linux版本:CentOS 6.7
SSH连接工具:FinalShell
Java版本:1.8
Hadoop版本:2.7.4
Hive版本:1.2.1
MySQL版本:5.7.25
Sqoop版本:1.4.6
2、web环境
Tomcat版本:7.0.47
Sping版本:4.2.4
Spring MVC版本:4.2.4
MyBatis版本:3.2.8
Echarts:4.2.1
3、开发环境(Windows)
Windows版本:Windows11专业版 / Windows10专业版
Eclipse版本:Eclipse IDE for Enterprise Java and Web Developers
Java版本:1.8
Maven:3.3.9
4、工具获取链接:
链接:https://pan.xunlei.com/s/VNru73AEa4yTNQYlHlKRdE8WA1
提取码:z5ea
二、Hadoop安装配置
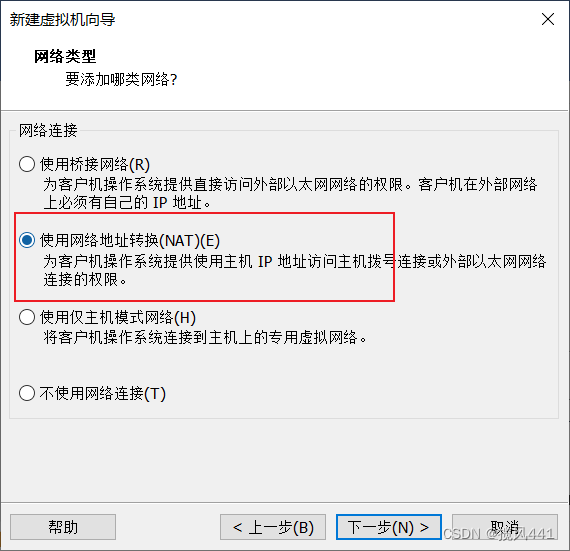
1. 配置VM-NAT网络
1.1 打开虚拟网络编辑器

1.2 选择更改设置

1.3 根据图示设置网络
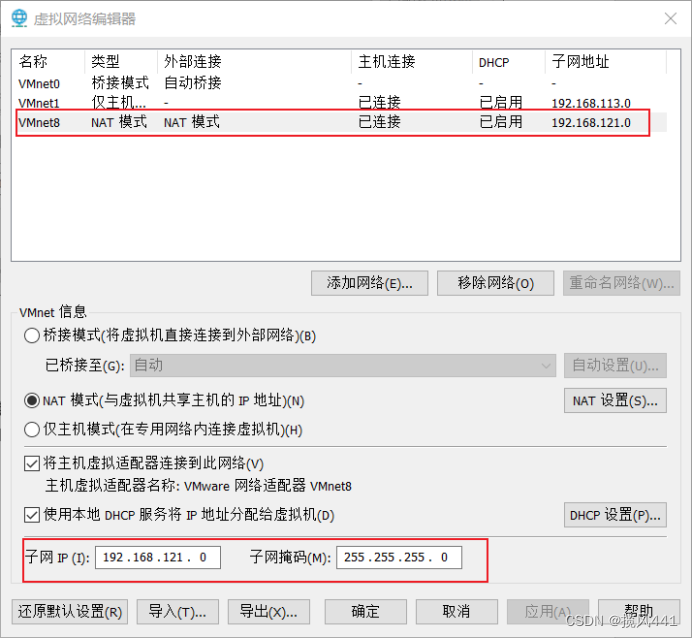


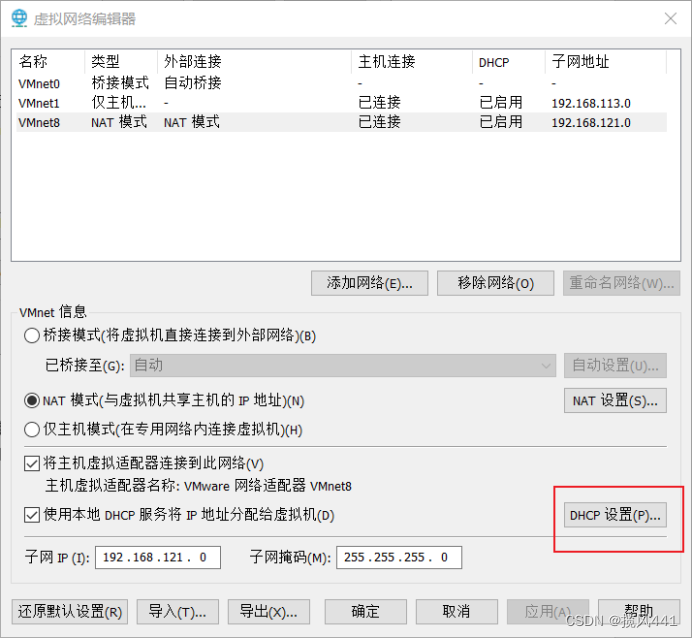
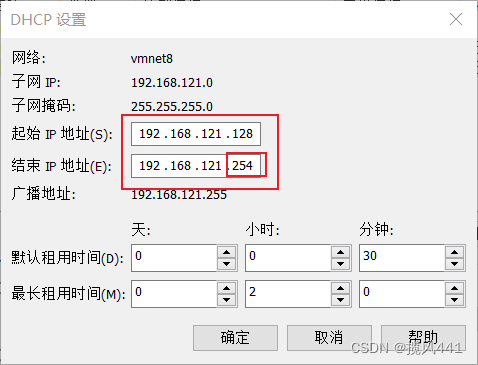
至此VM网络配置完成,保存退出至主页面
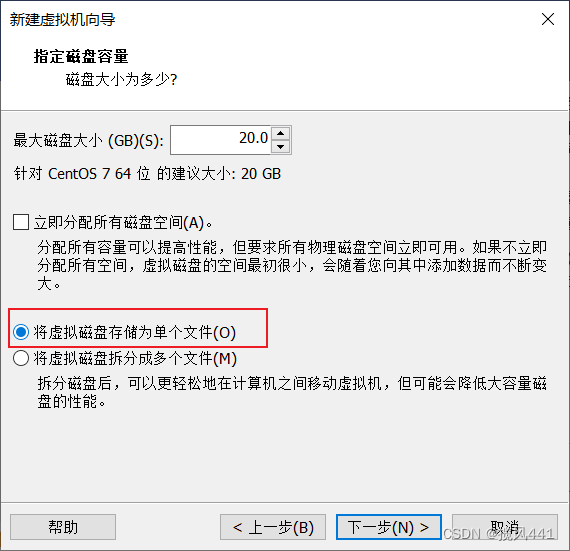
2. 安装虚拟机(本教程使用三台独立安装,非克隆安装)
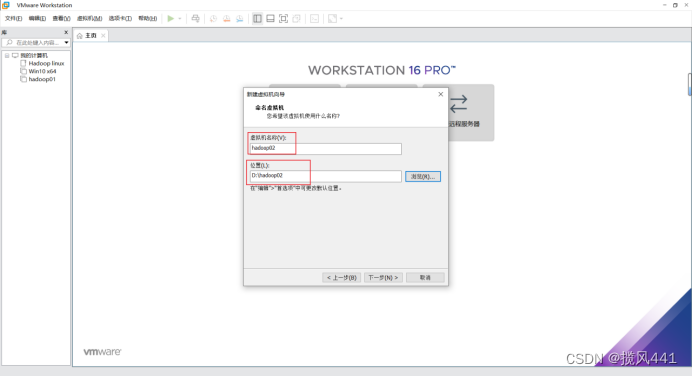
2.1 创建第一台虚拟机Hadoop01
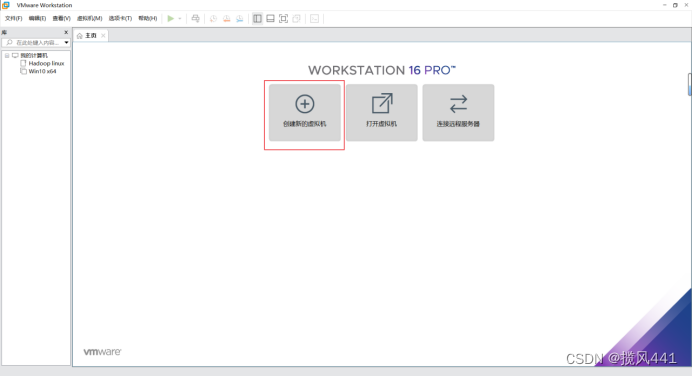




下图为设置hadoop02配置,配置hadoop01请忽略,hadoop03也在本步更改名称即可





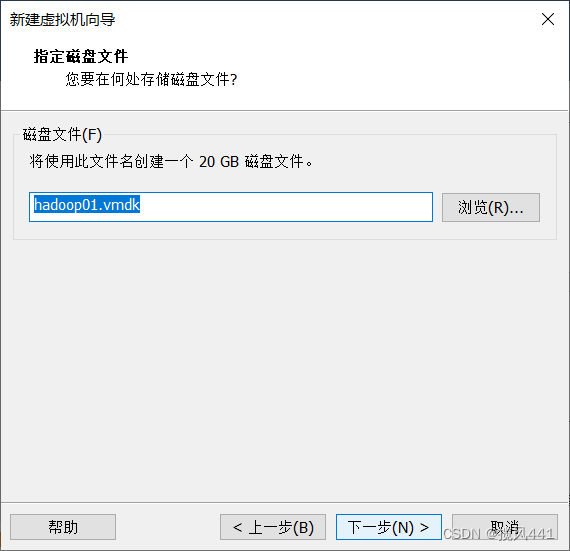

至此虚拟机创建完成。
2.2 安装centos7(hadoop01)

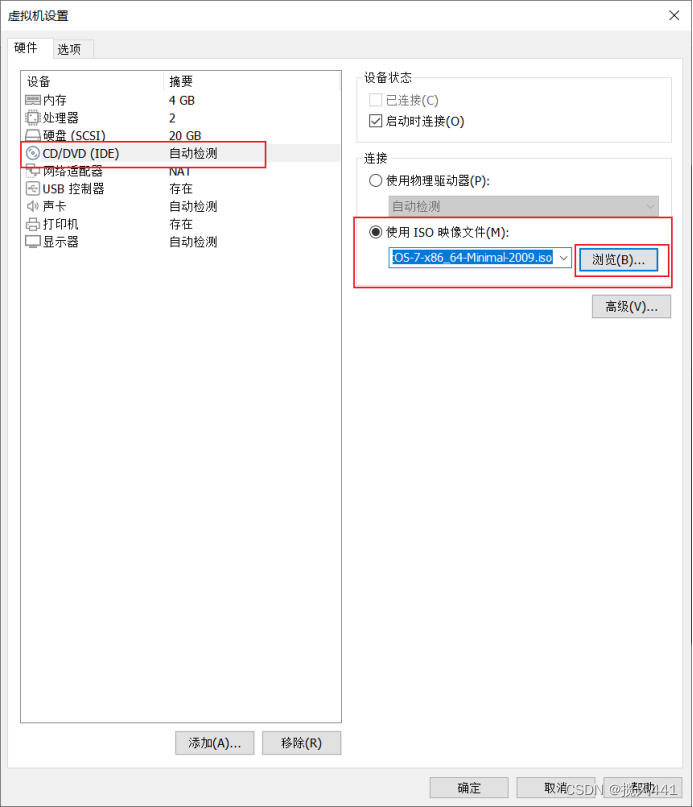

鼠标点击屏幕,选择图示选项安装



不做更改,点击完成

提醒:以下为重要部分,三台虚拟机均按此配置,只有IP不同
Hadoop01:192.168.121.134
Hadoop02:192.168.121.135
Hadoop03:192.168.121.136

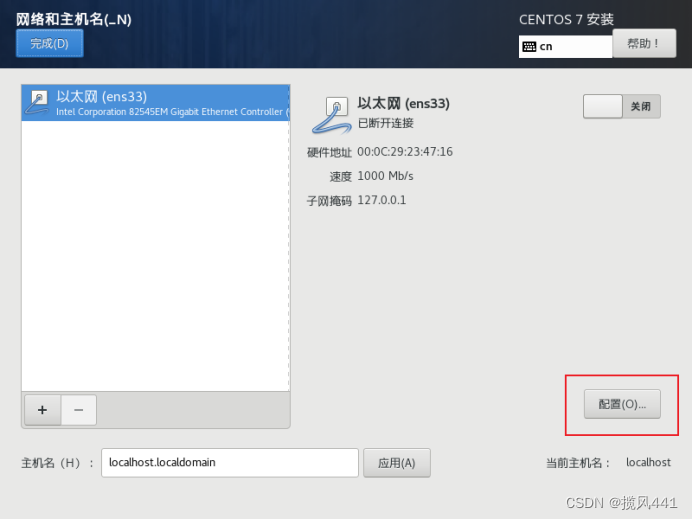


下图为hadoop02设置图,安装hadoop01跳过该图,hadoop03也在本图做更改,IP为192.168.121.136,主机名改为hadoop03





建议普通用户密码和root密码一致

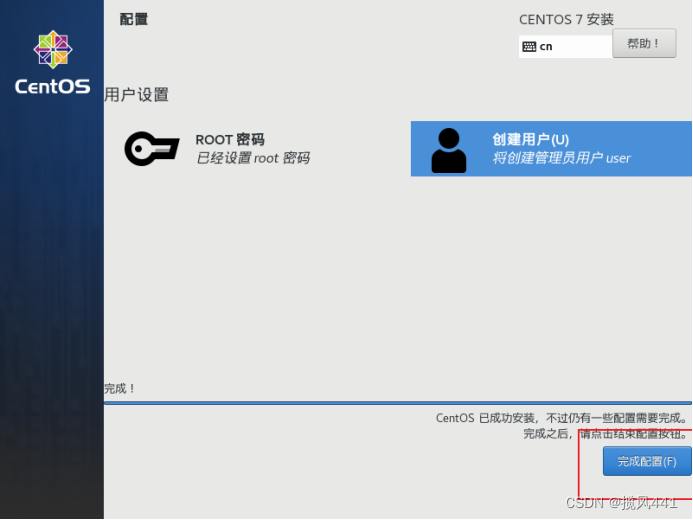

重启进入系统后,当前系统有两个用户
user 自己设置的密码
root 自己设置的密码
登陆系统以后,使用
ping www.baidu.com检测网络是否正常,不正常请重新配置,ping正常连通以后关机
下图为hadoop03展示ping命令正确运行,使用Ctrl+C停止命令执行

弹出安装镜像,该步骤还需取消启动时连接选项,图中未标出!


第一台虚拟机安装完成。
2.3 安装hadoop02,hadoop03
步骤与hadoop01相同,只需注意设置虚拟机名称和主机名称时更改为hadoop02,设置对应IP即可。
hadoop03相同操作。
2.4 配置windows hosts
该操作目的:后续hadoop搭建完成以后,使用hadoop01:50070访问hdfs web 服务
进入C:\Windows\System32\drivers\etc,使用记事本打开hosts,加入
192.168.121.134 hadoop01
192.168.121.135 hadoop02
192.168.121.136 hadoop03
2.5 运行FinalShell,配置三台机器


分别双击三台机器,连接,接受并保存密匙


选择全部会话,在全部会话上方输入命令,点击发送,会直接发送到三台机器,同时执行一个命令,避免重复操作
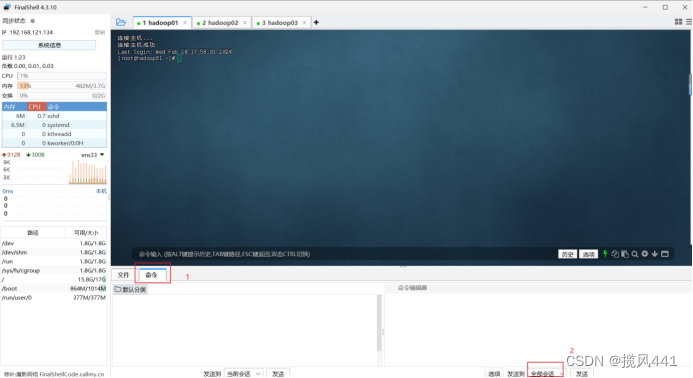
2.6 修改hadoop01的hosts映射文件
注:每次访问192.168.121.134的ip地址比较麻烦,所以采用主机名的方式进行配置。
输入如下命令:
vi /etc/hosts添加下面内容:(其实就是三台虚拟机IP及各自对应的主机名)
192.168.121.134 hadoop01
192.168.121.135 hadoop02
192.168.121.136 hadoop03
点击屏幕,进入主机输入模式,按照正常vim模式编辑即可,三台机器进行同样操作
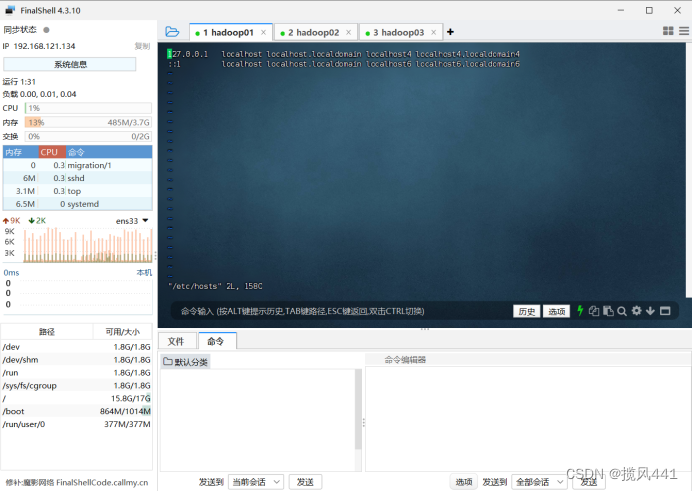



2.7 关闭防火墙,关闭防火墙自启动(三台)
分别执行下面两条命令(使用全部会话方式发送命令至三台机器):
systemctl stop firewalld
systemctl disable firewalld.service
2.8 配置yum国内源(三台机器同时进行)
备份默认源:
cp /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
更改默认源:
sudo sed -e 's|^mirrorlist=|#mirrorlist=|g' \
-e 's|^#baseurl=http://mirror.centos.org/centos|baseurl=https://mirrors.ustc.edu.cn/centos|g' \
-i.bak \
/etc/yum.repos.d/CentOS-Base.repo
重建缓存:
sudo yum makecache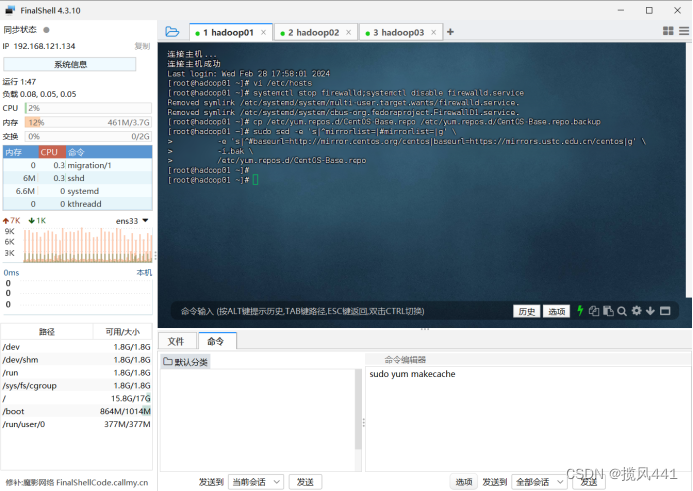

2.9 安装vim(三台机器)
yum -y install vim-enhanced
配置vim
vim /etc/vimrc加入以下信息:
set nu " 设置显示行号
set showmode " 设置在命令行界面最下面显示当前模式等
set ruler " 在右下角显示光标所在的行数等信息
set autoindent " 设置每次单击Enter键后,光标移动到下一行时与上一行的起始字符对齐
syntax on " 即设置语法检测,当编辑C或者Shell脚本时,关键字会用特殊颜色显示

2.10 安装Linux中必备常用支持库(三台)
yum install -y gcc gdb strace gcc-c++ autoconf libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel libxml2 libxml2-devel zlib zlib-devel glibc glibc-devel glib2 glib2-devel bzip2 bzip2-devel ncurses ncurses-devel curl curl-devel e2fsprogs patch e2fsprogs-devel krb5-devel libidn libidn-devel openldap-devel nss_ldap openldap-clients openldap-servers libevent-devel libevent uuid-devel uuid net-tools
2.11 配置三台主机之间的免密登录(三台分别执行)
ssh-keygen -t rsa输入上方命令后,回车两次即可

输入以下命令,查看生成的公私钥对:
cd .ssh
ls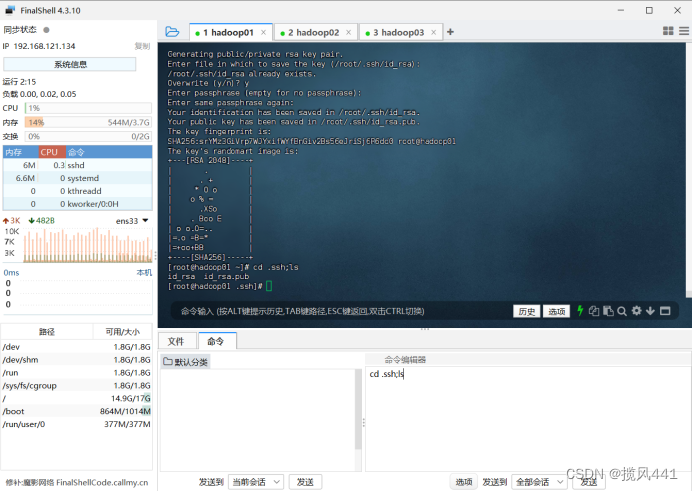
将三台虚拟机的公钥拷贝到一台机器上:
ssh-copy-id hadoop01
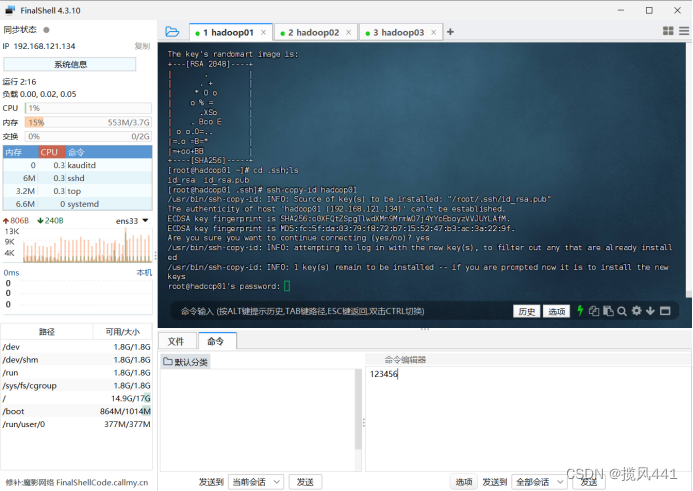
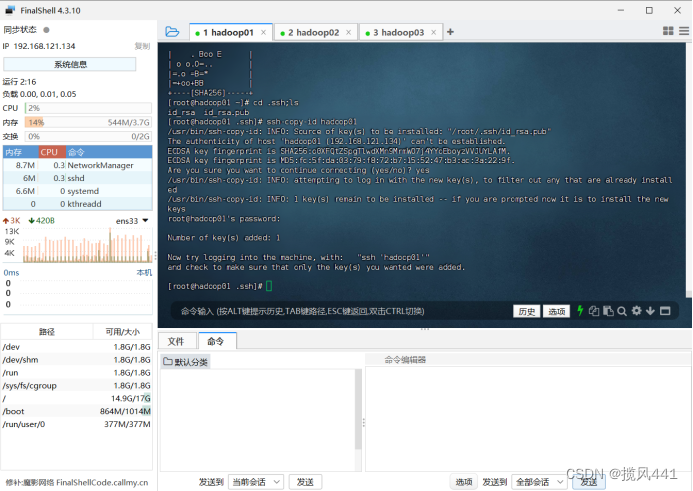
在hadoop01虚拟机中,定位到目录.ssh下面,输入ls
cd .ssh
ls可以查看到出现一个文件authorized_keys,该文件保存的就是三台机器的公钥

注意:以下步骤只在hadoop01操作!!!
将authorized_keys发送给其它机器(hadoop01执行,其余不执行):
注意该步骤命令输入位置!回车即可运行命令
scp /root/.ssh/authorized_keys hadoop02:/root/.ssh;
scp /root/.ssh/authorized_keys hadoop03:/root/.ssh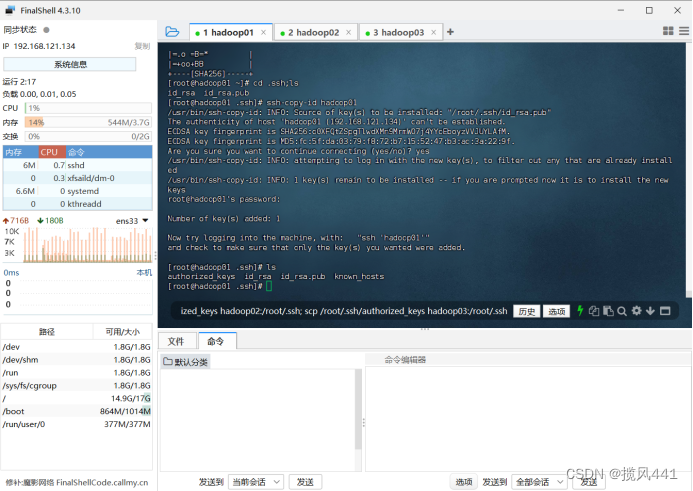


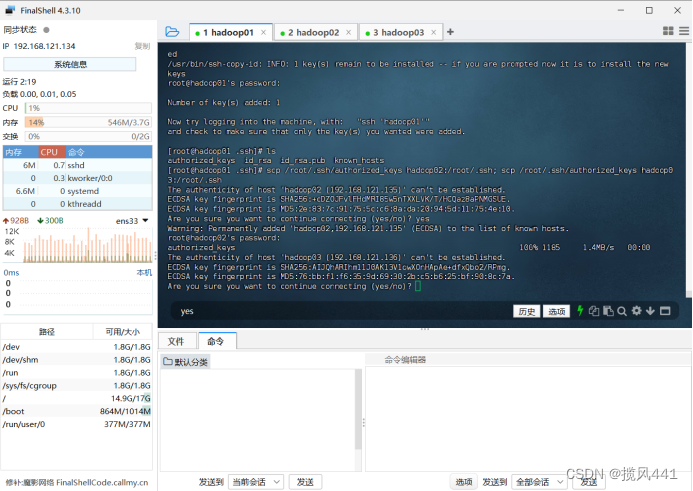


验证免密登陆是否成功:
ssh hadoop02
验证完毕,输入exit,hadoop01将退出登录hadoop02,回到hadoop01
exit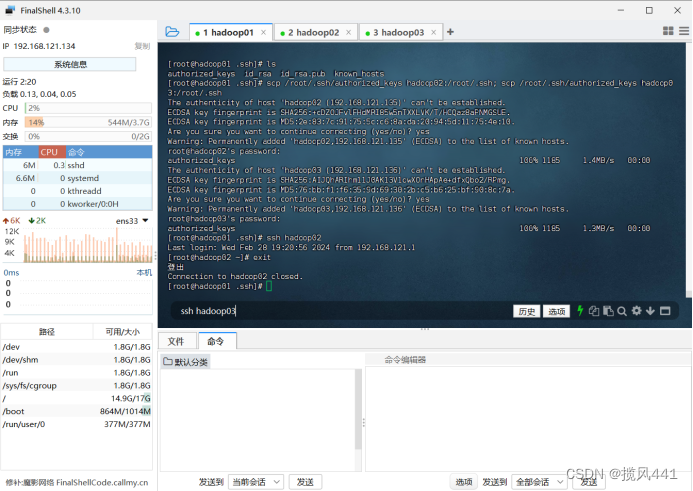


至此,虚拟机安装完成
3. JDK安装(hadoop01安装)
3.1 自建软件安装目录
mkdir -p /export/software;
mkdir -p /export/data;
mkdir -p /export/servers
3.2 进入/export/software目录
cd /export/software
上传JDK安装包

解压文件
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /export/servers/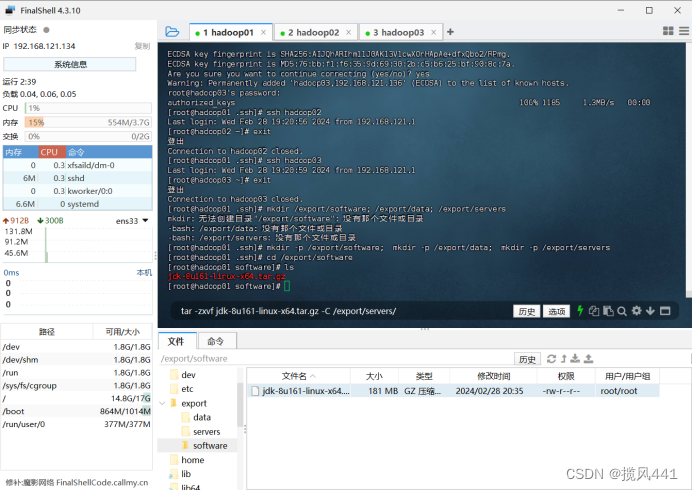
查看解压缩后的jdk文件夹,并利用mv命令对文件夹进行重命名。
cd /export/servers/
ls
mv jdk1.8.0_161/ jdk
ls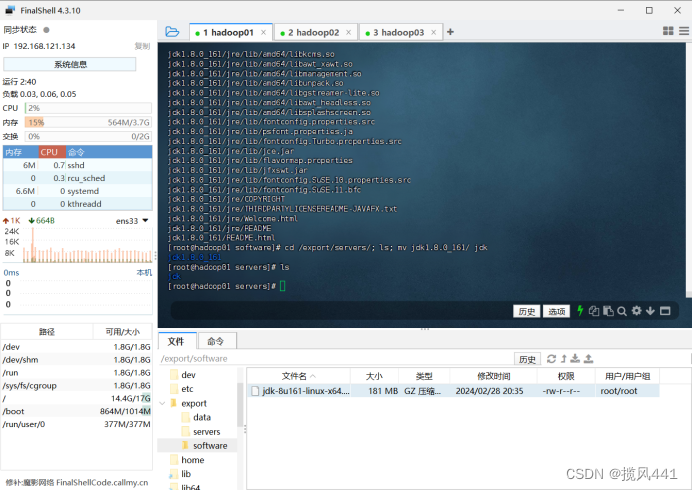
配置JDK环境变量
vim /etc/profile添加如下内容:
#JAVA_HOME
export JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin
编辑保存好后,重启使配置文件生效。
source /etc/profileJDK环境验证
java -version
4. Hadoop安装
4.1 上传安装包至/export/software

4.2 进入/export/software
cd /export/software解压hadoop压缩包。解压后的目标路径为/export/servers
tar -zxvf hadoop-2.7.4.tar.gz -C /export/servers/
进入到/export/servers目录下
cd /export/servers
ls配置Hadoop系统环境变量
vim /etc/profile
添加如下内容:
export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
输入如下命令,使配置文件生效
source /etc/profile查看hadoop版本
hadoop version
4.3 配置Hadoop集群主节点。
(1)修改hadoop-env.sh文件。
命令:
cd /export/servers/hadoop-2.7.4/etc/hadoop/
vim hadoop-env.sh添加如下内容:
export JAVA_HOME=/export/servers/jdk
(2)修改core-site.xml文件
命令:
vim core-site.xml添加内容如下:
<configuration>
<!-- 用于设置Hadoop的文件系统,由URI指定 -->
<property>
<name>fs.defaultFS</name>
<!-- 用于指定namenode地址在hadoop01机器上 -->
<value>hdfs://hadoop01:9000</value>
</property>
<!-- 配置Hadoop的临时目录,默认/tmp/hadoop-${user.name} -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.7.4/tmp</value>
</property>
</configuration> 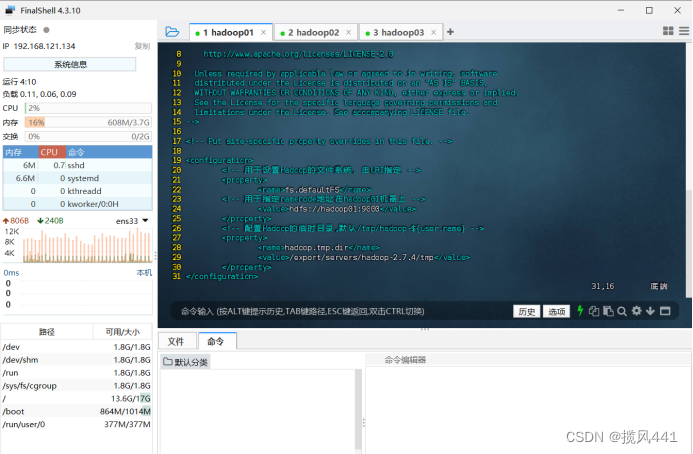
(3)修改hdfs-site.xml文件
命令:
vim hdfs-site.xml<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- secondary namenode 所在主机的ip和端口-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:50090</value>
</property>
</configuration> 添加如下内容:

(4)修改mapred-site.xml
这里我们首先拷贝下mapred-site.xml.template文件,命名为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml接下来编辑此文件
vim mapred-site.xml添加的内容如下:
<configuration>
<!-- 指定MapReduce运行时框架,这里指定在Yarn上,默认是local -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>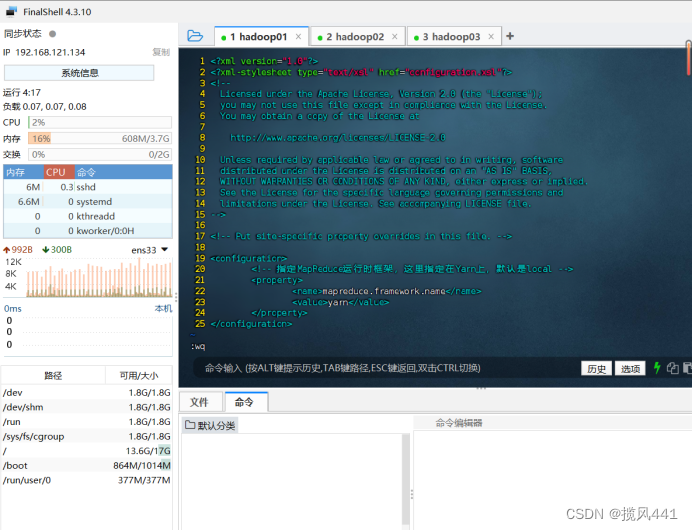
(5)修改yarn-site.xml
vim yarn-site.xml添加的内容如下:
<configuration>
<!-- 指定Yarn集群的管理者(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration> 
(6)修改slaves文件,打开该配置文件,先删除里面的内容(默认是localhost)
vim slaves然后添加如下内容:
hadoop01
hadoop02
hadoop03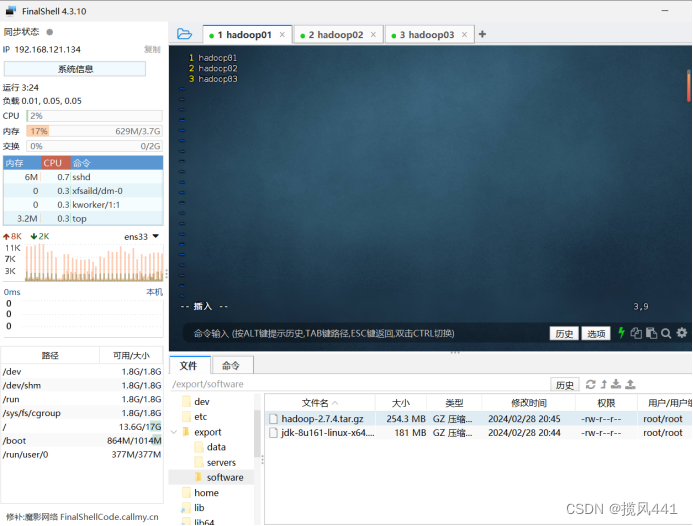
至此集群主节点hadoop01中一些配置配置文件配置完成。
接下来将配置好的文件分发到另外两个节点下hadoop02和hadoop03。
4.4 分别执行如下四条命令进行分发
scp /etc/profile hadoop02:/etc/profile
scp /etc/profile hadoop03:/etc/profile
scp -r /export/servers/ hadoop02:/export/
scp -r /export/servers/ hadoop03:/export/4.5 执行结束后,hadoop02和hadoop03上执行命令:
source /etc/profile4.6 格式化文件系统(在主节点hadoop01上执行)
hdfs namenode -format格式化文件系统这个操作只能在第一次启动hdfs集群时来操作,后面不能再进行格式化!!!

5. 启动或关闭hadoop
#启动hadoop
start-dfs.sh && start-yarn.sh#关闭hadoop
stop-dfs.sh && stop-yarn.sh
5.1 jps命令查看开启的进程
jps

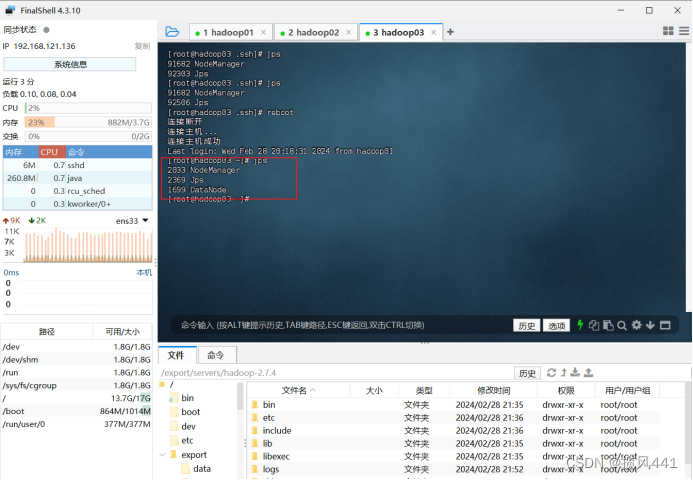
确保:hadoop01有5个,hadoop02有4个,hadoop03有3个
5.2 查看HDFS和YARN集群状态
(1)在浏览器访问hadoop01:50070或者192.168.121.134:50070查看HDFS集群状态

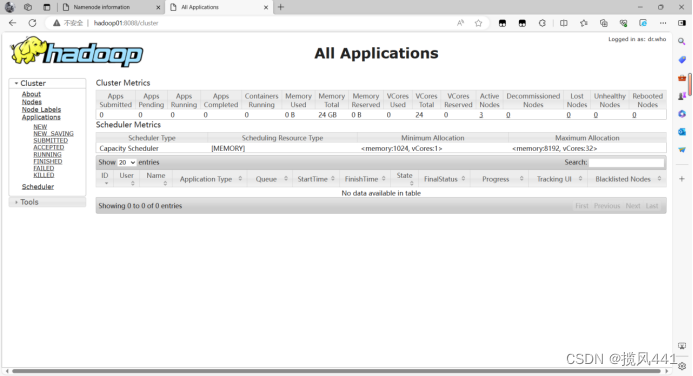
(2)浏览器访问hadoop01:8088或者192.168.121.134:8088查看YARN集群管理页面.














 661
661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









