







 该项目分析了微博上关于ChatGPT的评论,利用LDA进行话题聚类,发现10个主要讨论主题,并通过SnowNLP进行情感分析,揭示了用户对ChatGPT的两极化情感。此外,还通过词云图展示了高频词汇,并运用多元线性回归探索了影响微博热度的因素。
该项目分析了微博上关于ChatGPT的评论,利用LDA进行话题聚类,发现10个主要讨论主题,并通过SnowNLP进行情感分析,揭示了用户对ChatGPT的两极化情感。此外,还通过词云图展示了高频词汇,并运用多元线性回归探索了影响微博热度的因素。
为了分析热点话题背后演化的逻辑,本项目选取了掀起大范围讨论的OpenAI发布的语言训练模型“ChatGPT”作为研究对象。通过对微博、豆瓣、知乎等社交平台进行考察分析,微博以活跃用户多、讨论热度高、公众关注度广等特点成为了本小组的第一首选。因此我们决定选用微博评论来作为数据分析主要数据来源。通过爬取3月1日到3月31日“ChatGPT”每个小时的相关热点话题下的博文,包括博主名称、微博内容、博文是否含有表情、主题、图片、视频、博主的性别、粉丝数、发文数、是否获得认证、以及时间、转发量、评论量、点赞量等数据,同时,利用百度指数平台爬取了3月1日到3月31日有关“ChatGPT”的搜索指数,借助 LDA 模型完成主题挖掘,详尽分析各主题的产生及其内在原因。针对微博评论,我们通过词频分析探究chatgpt在全国整体的舆论态度;借助 SnowNLP、pandas 进行情感分析,探究人们对于chatgpt的情感倾向。
一、数据获取
本项目使用了 Python requests 爬虫库以及 Beautiful Soup 解析库。爬虫循环获取网页内容,使用 Beautiful Soup 库解析 HTML 文本获取所需内容存入excel 文件用于初步分析。爬取了包括博主、内容、是否含有表情、是否有@、是否有主题、时间、转发量、评论量、点赞数、是否包含图片、是否包含视频、博主地区、博主性别、博主粉丝数、博主发文数、博主是否认证、地区标签在内的数据。部分代码如下所示(全部代码太长啦不放了):
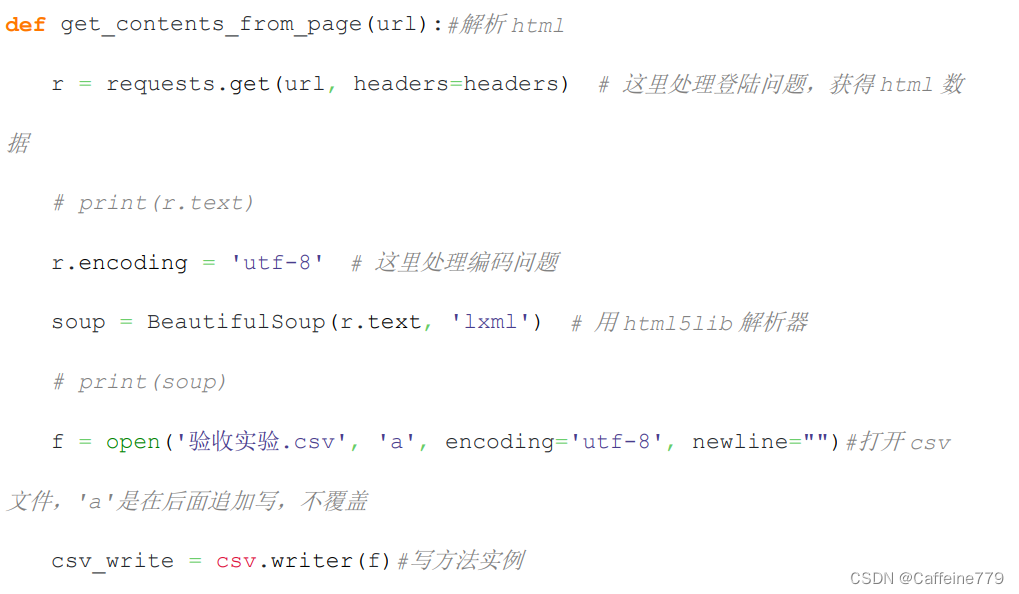
二、数据预处理
1.数据清洗
在进行多爬取到的微博内容进行数据分析之前,需要先进行分词操作。我选用的是基于统计的分词方法的中文分词工具包——jieba 分词。
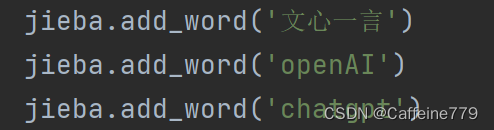
首先,要通过观察jieba分词结果,识别出分得不好的词语,通过jieba.add_word(word, freq=None, tag=None)这个函数,加入自定义词典,确保一些词语能被准确识别:
其次,加入停用词,将一些不重要的标点符号和语气词过滤掉。

为了保证分词的质量,不仅要过滤掉停用词,只保留词性为“n(名词)”“nz(专有名词)”“vn(动名词)”的词语,且长度需要大于等于2。
这里会出现一个问题,通过add_word函数添加的自定义词典词性为x,即未知词性,在筛选的过程中会将其过滤掉,导致分词结果中没有自定义词典。所以,我定义了一个名为 custom_words的列表,将自定义词典放入列表里,通过词性过滤时判断该词是否在custom_words中,在则留下。最后输出一个excel文件,存放分词结果。
这里用到了pandas、jieba、re等库:
import re
import jieba
import jieba.posseg as psg
import pandas as pd
from openpyxl import Workbook
def chinese_word_cut(mytext):
try:
stopword_list = open(stop_file, encoding='utf-8')
except:
stopword_list = []
print("error in stop_file")
stop_list = []
flag_list = ['n', 'nz', 'vn']
for line in stopword_list:
line = re.sub(u'\n|\\r', '', line) # 去除换行符
stop_list.append(line)
word_list = []
custom_words = ['文心一言', 'openAI',’ chatgpt’]
jieba.add_word('文心一言')
jieba.add_word('openAI')
jieba.add_word('chatgpt')
# 使用jieba分词
seg_list = psg.cut(mytext)
for seg_word in seg_list:
word = seg_word.word
find = 0
for stop_word in stop_list:
if stop_word == word or len(word) < 2:
find = 1
break
if find == 0 and (seg_word.flag in flag_list or seg_word.word in custom_words):
word_list.append(word)
return " ".join(word_list)
data["content_cutted"] = data.content.apply(chinese_word_cut)
output_excel_path = r'D:\桌面\python练习\lda\result\output.xlsx'
data.to_excel(output_excel_path, index=False)
2.数据集成
在此项目中,由于数据源包括微博和百度指数两部分。因此进行数据集成。最终通过处理,数据包括了博主、内容、是否含有表情、是否有@、是否有主题、时间、转发量、评论量、点赞数、总热度、是否包含图片、是否包含视频、博主地区、博主性别、博主粉丝数、博主发文数、博主是否认证、搜索指数、咨询指数、情感倾向、地区标签。集成结果如下:
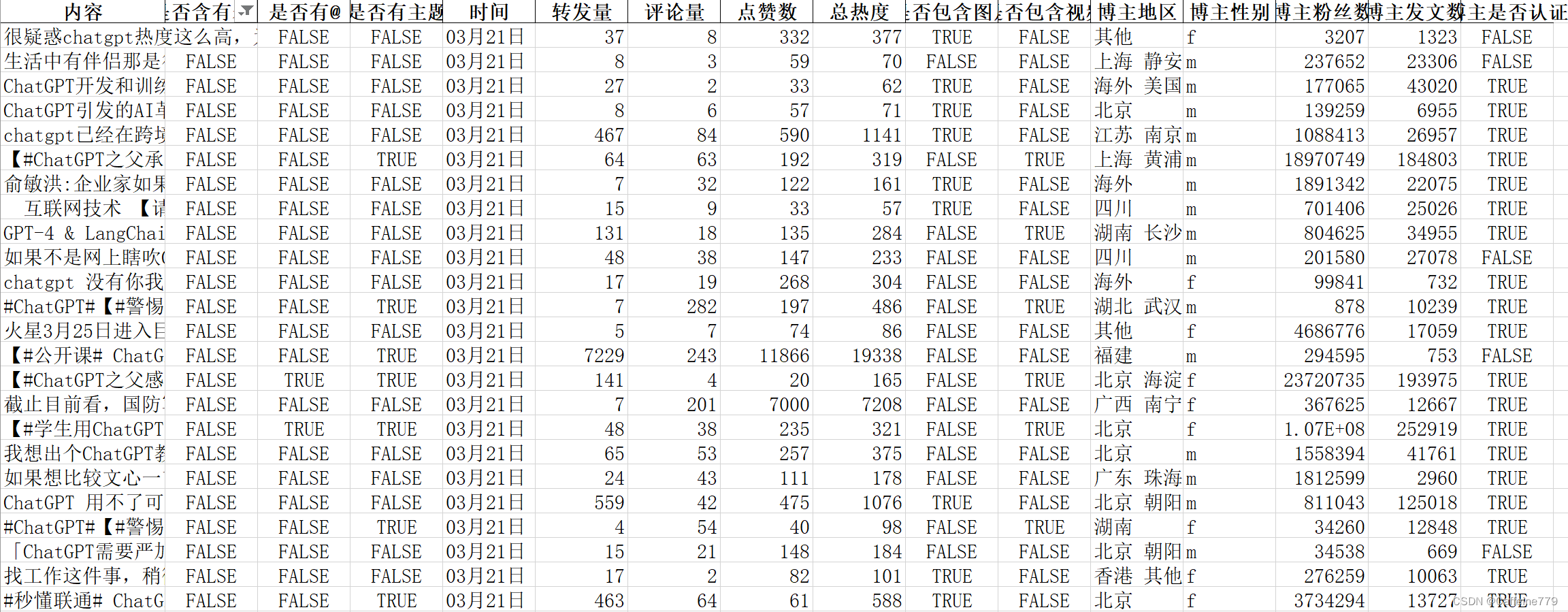
三、数据分析
1.基于 LDA 的话题聚类
(1)确定主题聚类个数
经过数据预处理后,本文选用 gensim 中的类实例化 LDA 主题模型,对预处理后的文本进行分类训练,并拟定在区间[1,15]内的整数作为候选主题数,通过调用 LDA 主题模型类下的 Perplexity 方法,分别对数据进行 LDA 聚类分析,得出不同模型的对数化困惑度数值:
首先,求解困惑度,选出最合适的主题数:
plexs = []
n_max_topics = 16
for i in range(1, n_max_topics):
print(i)
lda = LatentDirichletAllocation(n_components=i, max_iter=50,
learning_method='batch',
learning_offset=50, random_state=0)
lda.fit(tf)
plexs.append(lda.perplexity(tf))
n_t = 15 # 区间最右侧的值。注意:不能大于 n_max_topics
x = list(range(1, n_t))
plt.plot(x, plexs[1:n_t])
plt.xlabel("number of topics")
plt.ylabel("perplexity")
plt.show()困惑度折线图如下:
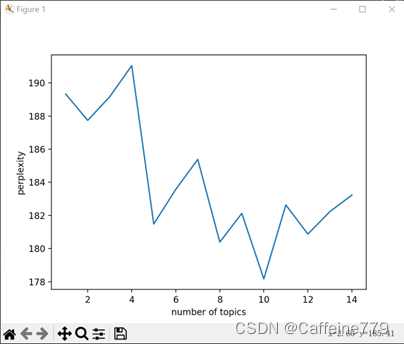
该折线图显示,随着主题数的增加,总体上困惑度呈现下降的态势;困惑度的局部极小值点,出现在主题数为 10的模型选择上。主题数越多,则后续的主题分析也越为复杂。根据奥卡姆剃刀准则,本文选择 perplexity 相对小且主题数量相对较少的主题数值 T=10 作为 LDA模型训练的最优模型参数。在采用 LDA 模型进行主题求解过程中,参数选择分别为:T=10,α=0.1,β=0.01,Gibbs 抽样的迭代次数为 50 次。
(2)主题聚类
创建了一个 CountVectorizer 对象 tf_vectorizer,用于将文本转换为特征向量。使用 tf_vectorizer 对象将文本数据 data.content_cutted 转换为特征向量矩阵 tf。再定义主题模型的数量 n_topics,并创建了一个 LatentDirichletAllocation 对象 lda,用于执行主题建模。
def print_top_words(model, feature_names, n_top_words):
twor 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









