







数据获取(代码实现)
本篇文章爬取的数据可能包含一定隐私信息,请不要将爬虫爬到的数据用于非法盈利上。
爬虫实现
根据上一篇博客,我们进行了爬虫可行性的分析,应该是可以获取到足够的量的数据的,现在我们开始编写爬虫程序。
首先,进入首页(在上一篇博客中我们提到了不能直接进入列表页的原因)。
url = "https://cfws.samr.gov.cn/" driver = webdriver.Chrome() driver.get(url) WebDriverWait(driver, 10)
使用webdriver打开谷歌浏览器,然后进入到指定的网站。
然后通过find.element函数,找到id为keyword的input标签,把“烟草”作为key值送到input标签中:
driver.find_element(By.ID, 'keyword').send_keys("烟草")
然后等待通过CSS获取到的元素可点击,再模拟点击按钮:
# 等待按钮可点击 login_button = WebDriverWait(driver, 10).until( EC.element_to_be_clickable((By.CSS_SELECTOR, '.quickly-entry a')) ) # 模拟点击按钮 login_button.click()
在点击完成之后,它会自己打开一个新的界面:
我们可以通过如下方式,将driver切换到新打开的界面:
# 等待新窗口打开 WebDriverWait(driver, 10).until(EC.number_of_windows_to_be(2)) # 获取所有窗口句柄 all_handles = driver.window_handles # 切换到新打开的页面 new_window_handle = [handle for handle in all_handles if handle != driver.current_window_handle][0] driver.switch_to.window(new_window_handle)
切换到新打开的界面之后,我们就可以在新的界面上进行操作了,现在需要的是点击2024来实现信息的筛选:
# 在新页面上继续操作 element_2024 = WebDriverWait(driver, 10).until( EC.element_to_be_clickable((By.ID, f'j2_1_anchor')) ) element_2024.click()
完成点击2024之后,我们开始仔细查看页面的结构: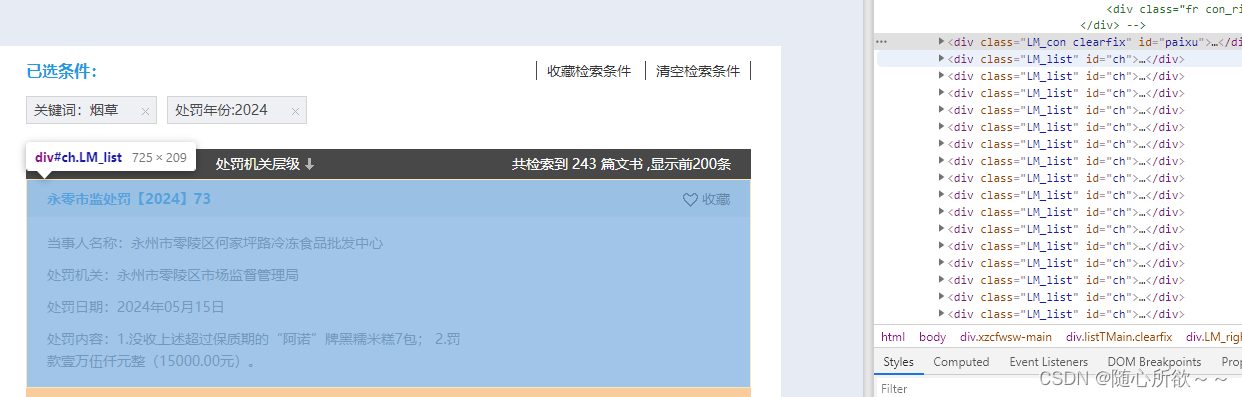
如图所示,每一个裁判文书都被包含在了class=LM_list的div标签中
# 找到 LM_list 中的每个项目 lm_items = driver.find_elements(By.CSS_SELECTOR, '.LM_list') # 选择 LM_list 中的每个项目 # 遍历每个项目,提取详情页的 URL for item in lm_items:
通过该代码找到所有的LM_list,然后再对每个LM_list进行遍历,在for循环中编写爬取过程的代码:
首先找到详情页的url,然后用webdriver打开新的页面,使用美丽汤来找到pdf_title元素
# 获取详情页 URL
detail_url = item.find_element(By.CSS_SELECTOR, '.list_title h4 a').get_attribute('href')
# print(detail_url)
driver_detail = webdriver.Chrome()
driver_detail.get(detail_url)
html_detail_data = driver_detail.page_source
# 使用 BeautifulSoup 解析页面内容
soup_detail = BeautifulSoup(html_detail_data, 'html.parser')
# 找到 PDF_title 元素
pdf_title = soup_detail.find('div', class_='PDF_title')
然后把对应标签中的文本内容作为文件名。
# 提取文本内容作为文件名 file_name = pdf_title.get_text().strip() + '.txt'
由于pdf写在了一个iframe的document下面,所以我们需要先将driver_detail转向iframe:
iframe = WebDriverWait(driver_detail, 10).until(
EC.presence_of_element_located((By.XPATH, "//iframe"))
)
# 在 iframe 内进行操作
print(file_name)
driver_detail.switch_to.frame(iframe)
time.sleep(3)
time.sleep(3)是为了保证document的html更新了足够长的时间,不然的话可能会出现某些html没有出现的情况。
在爬取的过程中,我们发现最后一页pdf的文本没有获取到
查看html得知,最后一页不像第一页一样,有textlayer属性,于是我们开始想办法让它加载出文本,首先考虑让seleium模拟向下滑动,但是出了一点小问题,没有成功滑动,然后查看html代码发现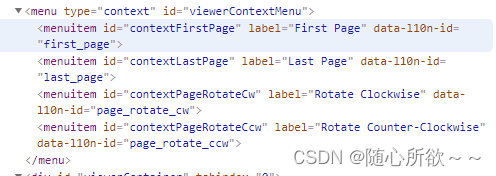
html中有一个菜单,里面有一个lastpage标签,可以实现跳转到最后一页,这样就可以成功加载出来最后一页了。
# 模拟跳转到PDF最后一页
driver_detail.execute_script("""
var viewer = window.PDFViewerApplication;
if (viewer && viewer.page) {
viewer.page = viewer.pagesCount; // 设置当前页为最后一页
}
""")
time.sleep(3)
这里是通过script实现的,让程序停三秒也是为了等待加载。
下面就是后续的代码了:
# 再次获取iframe内的页面内容
html_detail_data = driver_detail.page_source
print(html_detail_data)
soup_detail = BeautifulSoup(html_detail_data, 'html.parser')
# 找到所有 class 为 textLayer 的 div
text_layers = soup_detail.find_all('div', class_='textLayer')
# 获取所有 textLayer 中所有的 div 元素并提取文本
all_texts = []
for text_layer in text_layers:
divs = text_layer.find_all('div')
for div in divs:
all_texts.append(div.get_text())
# 将所有文本内容合并到一个字符串中
combined_text = ' '.join(all_texts)
# 用于调试
# print(all_texts)
# print(combined_text)
# 确保上级目录的/2024文件夹存在
output_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), '..', 2024)
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 创建并写入文件
file_path = os.path.join(output_dir, file_name)
with open(file_path, 'w', encoding='utf-8') as file:
file.write(combined_text)
完成以上的工作后,爬虫可以完成爬取一页裁判文书的工作,要想实现爬取多页,还需要加点东西,
for a in range(1, 21):
# 完成点击下一页
pagination_link = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, f"//div[@id='pagination']/a[@οnclick='loadData({a})']"))
)
pagination_link.click()
time.sleep(2)
这样就实现了完成2024年的爬取了。
但是仅仅是2024年的爬取,还是不够的。
注意到我们可以通过修改参数来实现多个年份的爬取,于是继续修改代码,将该爬虫封装。
def pachong(t,nian,page): pachong(1,'2024',11) pachong(2,'2023',11) pachong(3,'2022',11) pachong(4,'2021',11) pachong(5,'2020',7) pachong(6,'2019',4)
主要是三个参数:第一个是点击的年份作为筛选条件的时候所需要的a值,第二个是存入文件夹时存入对应年份的文件夹,第三个是爬取的页数,因为2021-2024都有两百条以上的数据,每页展示20条数据,所以参数为21,2020年仅仅只有115条数据,所以参数为7,2019年只有45条数据,所以参数为4。
结果展示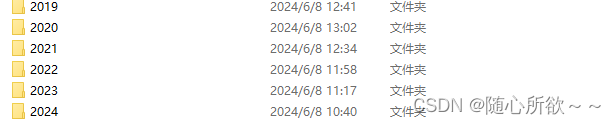
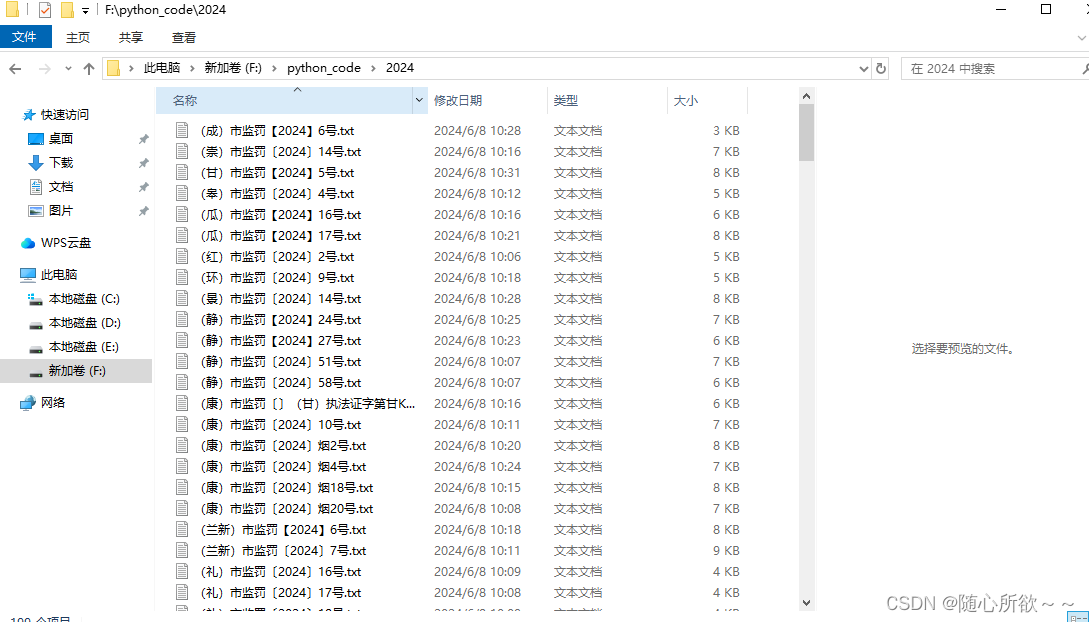
总结
本次爬取的过程总体难度不是特别大,其中遇见了一些小挫折,但是好在都顺利的解决了,成功的获取到了需要的数据集。爬虫是获取大量数据最好的办法,这门技术还是要好好掌握!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









