







由于之前获取到的数据量只有127条,显得有点不足,我们小组决定通过爬虫再次获取数据量。
这里主要对爬取的网站进行分析。
代码实现博客:数据获取(代码实现)-CSDN博客
爬取网站
爬取的网站老样子,还是裁判文书网,因为它里面的数据集比较规范。
爬取计划的分析
-
直接在列表页的搜索框中输入“烟草”,我们只能获取到很少一部分的数据集。
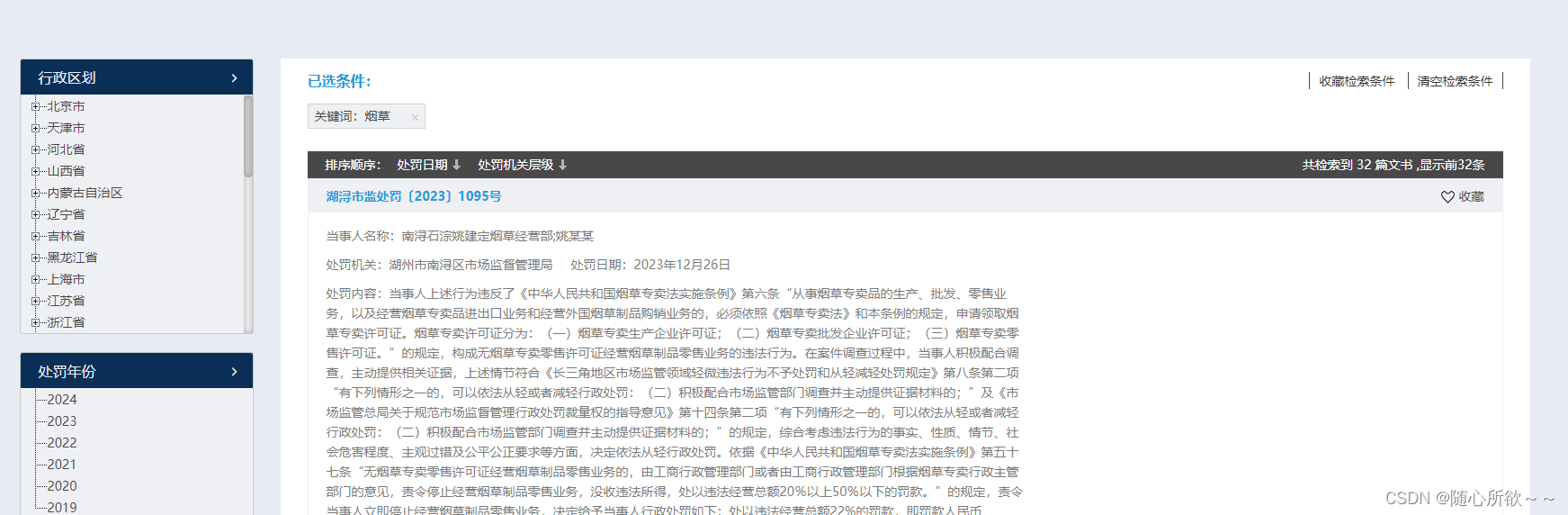
可以发现,居然只有32条有关于烟草的裁判文书,这显然不符合我们所需要的数据量的要求!
在我的多次尝试下,最后发现了,如果通过在首页的搜索框中输入“烟草”,然后再进行跳转,这样才能出现比较足够的数据集。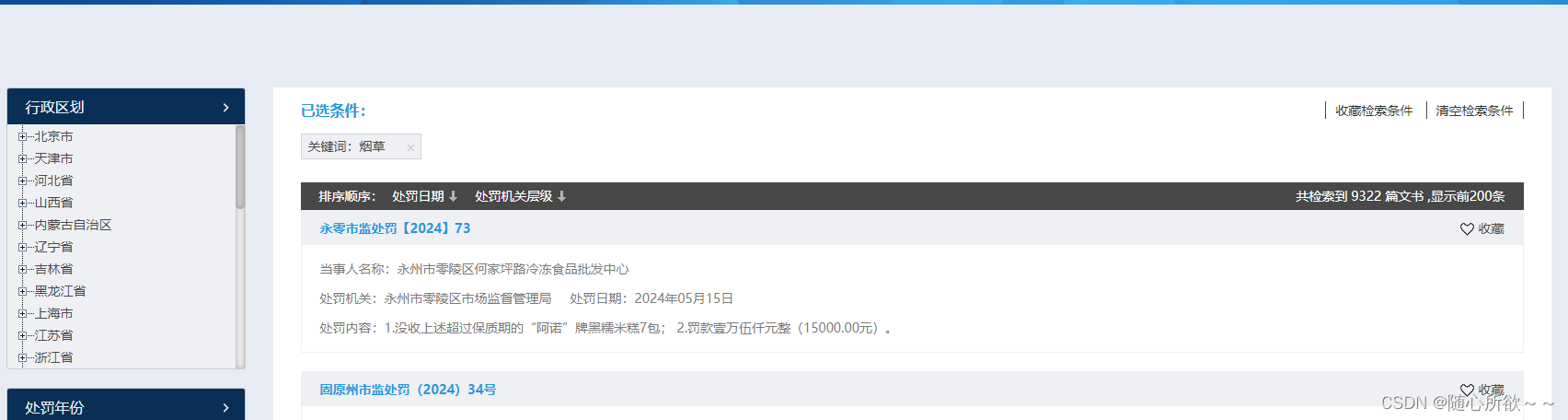
所以我们需要先进入首页,再通过搜索“烟草”关键字进入列表页,这样才能获取到足够的裁判文书。
-
进入列表页后,发现该网站只显示了200条裁判文书,这显然是不符合我们数据量需求的,又陷入了困境当中,网站只提供全部文书中的一部分裁判文书。
在观察左边的侧边栏时,发现处罚年份分成了2024、2023、2022、2021、2020、2019等六个年份,依次搜索后发现
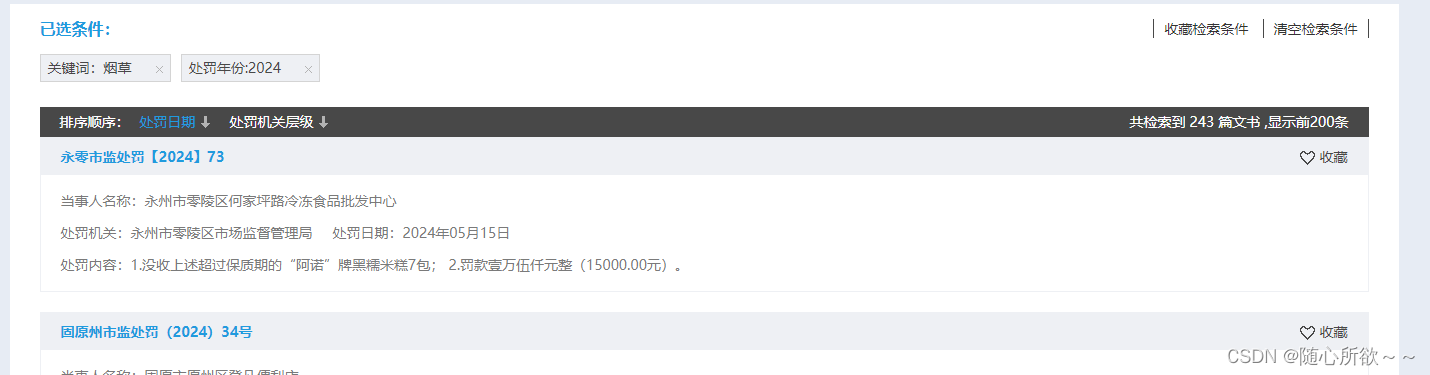
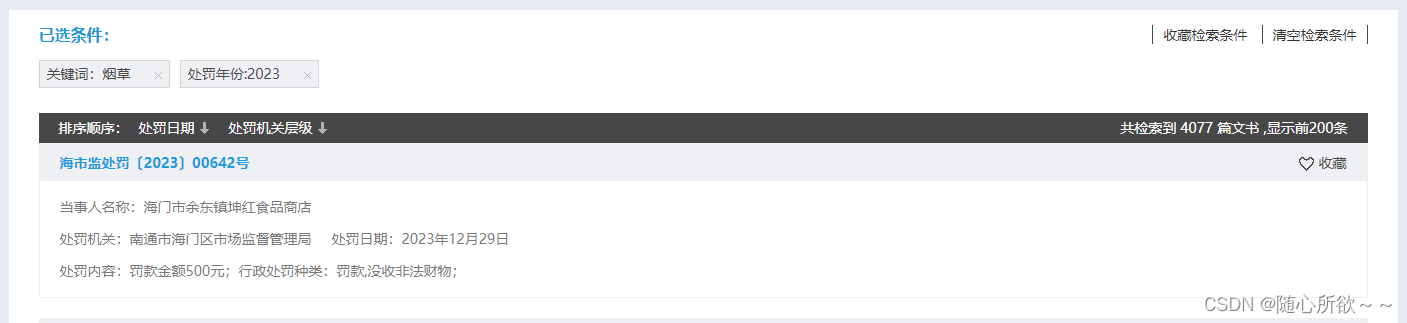
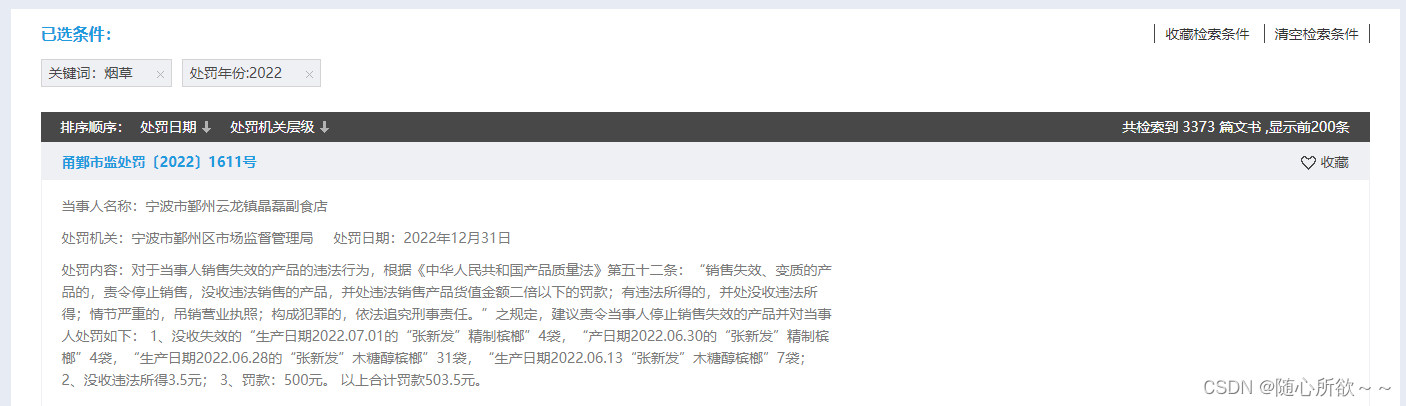
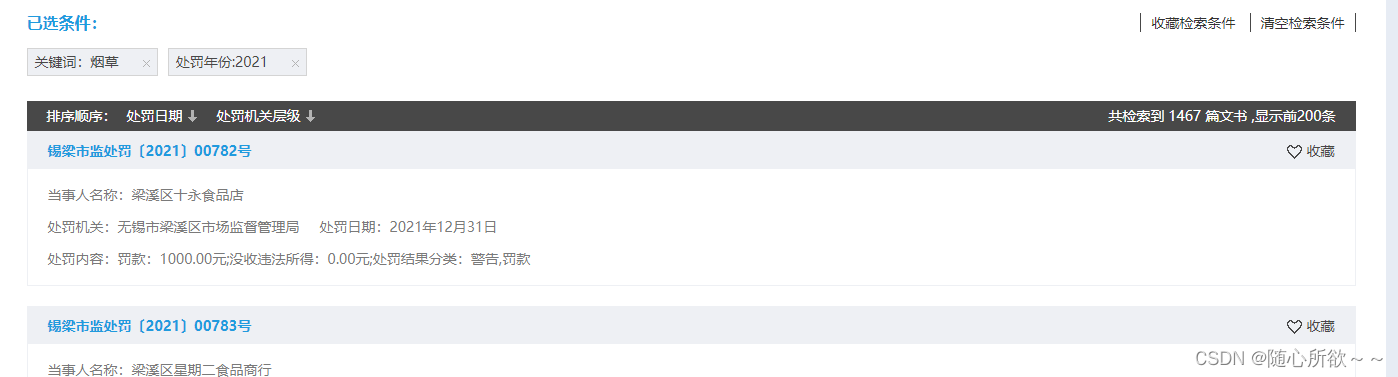
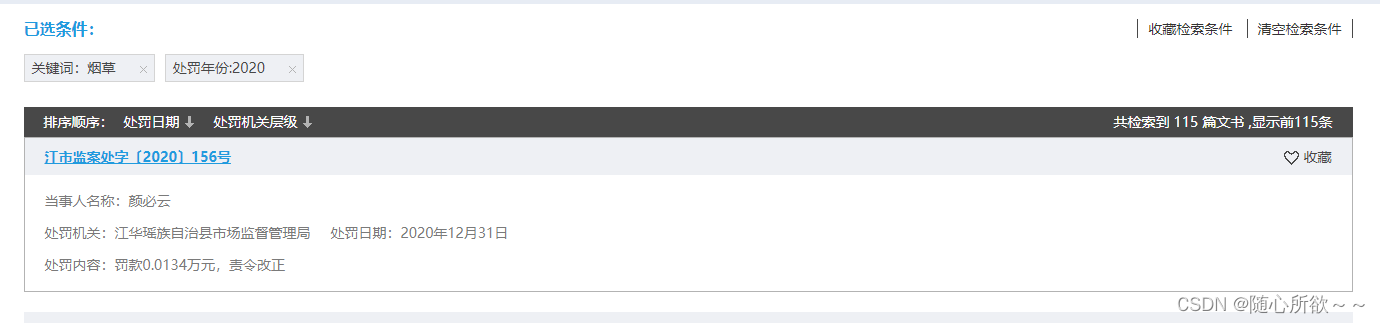
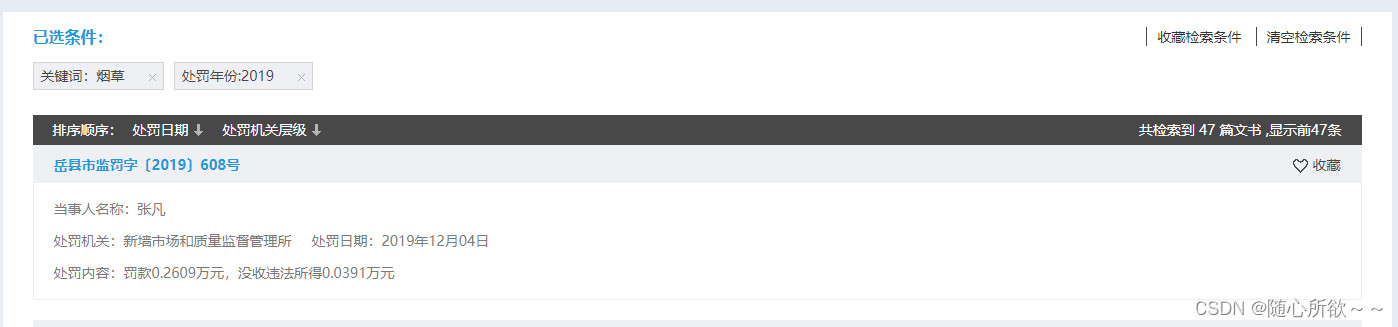
可以看出,2024、2023、2022、2021都显示了200篇,2020显示了115篇,2019显示了47篇,再加上之前的数据集,可以达成1000条以上数据集的需求!
-
在确保数据集的量足够的情况下,我们点击进入其中一个裁判文书,进入对应链接查看裁判文书的具体信息。
f12,找到我们需要的裁判文书内容对应的具体位置。
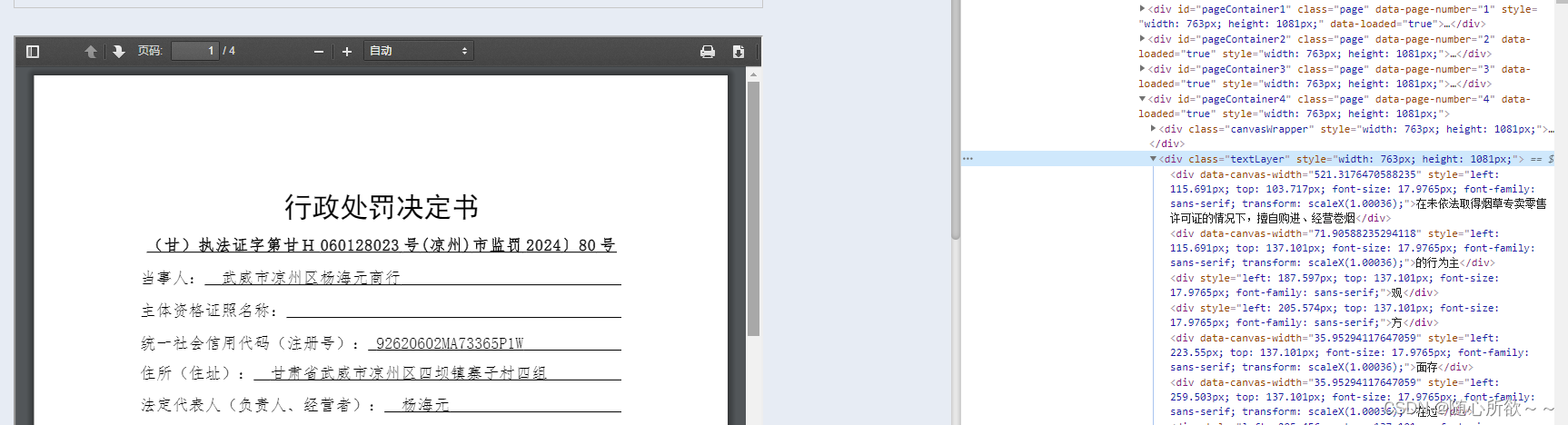
从界面可以看出,裁判文书保存在了一个pdf页面中,与此同时,网页的html中也有对应的页面信息以及文档内容!这样就确保了我们可以爬取到裁判文书的内容。
-
对于反爬的分析
网页对于爬虫的拦截力度其实并不大。爬取这些数据不需要我们进行登录的验证,也没有验证码的验证,当然,现如今还不知道是否在频繁访问网站后会被网站根据ip进行封锁,当然,就算是ip的封锁我们也是可以解决的,比如依据ip池或者在多个队员的设备上分开爬取。
总结
本次爬取网站总体看下来最后的实现应该不会特别难,但是需要注意
-
我们需要从首页的搜索框进入列表页,不能直接进入列表页进行搜索,不然数据集会少得可怜
-
我们必须要根据处罚年份进行筛选,因为它只展示200条数据,也就是每个关键词只提供200条数据
-
爬取时,需要的信息展现在了pdf文档中,我们可能需要获取每一页的信息最后再整合。

















 1122
1122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









