







文章目录
1.正则表达式的介绍以及作用
所谓正则表达式就是用某种模式去匹配字符串的一个公式,熟练的运用,可以让你从繁重的文本处理工作中解脱出来。
许多的语言都支持正则表达式,例如JS,PHP。
正则表达式常用于文本的搜索,例如找出一大段文本中所有的数字,英文字符,在或者在网页爬虫到的内容中快速得到例如标题等内容。

例如在以上一段文字中找到4位的数字

2.正则表达式的底层实现
public static void main(String[] args) {
String string="1998年12月8日,第二代Java平台的企业版J2EE发布。" +
"1999年6月,Sun公司发布了第二代Java平台(简称为Java2)的3个版本:" +
"J2ME(Java2 Micro Edition,Java2平台的微型版)," +
"应用于移动、无线及有限资源的环境;J2SE(Java 2 Standard Edition,Java 2平台的标准版)," +
"应用于桌面环境;J2EE(Java 2Enterprise Edition,Java 2平台的企业版),应用于基于Java的应用服务器。" +
"Java 2平台的发布,是Java发展过程中最重要的一个里程碑,标志着Java的应用开始普及。";
//创建正则表达式
// \为转义字符,\d代表一个任意数字
String reg="\\d\\d\\d\\d";
//创建一个模式对象
Pattern pattern = Pattern.compile(reg);
//创建一个匹配器,按照上面的正则表达式的规则匹配上面string字符串
Matcher matcher = pattern.matcher(string);
//开始匹配
/*
* matcher.find()
* 1.根据指定的规则定位满足的字符串
* 2.找到后,将子字符串开始的位置索引记录到matcher对象的属性 int[] groups
* 开始的索引记录到groups[0]位置,将子字符串结束位置的索引加一记录到groups[1]中
* groups数组中默认值为-1
* 3.同时记录oldlast值为子字符串结束位置的索引加一,即下一次执行find是从该位置开始匹配
*
* matcher.group()
* 以下是源码
*
* public String group(int group) {
if (first < 0)
throw new IllegalStateException("No match found");
if (group < 0 || group > groupCount())
throw new IndexOutOfBoundsException("No group " + group);
if ((groups[group*2] == -1) || (groups[group*2+1] == -1))
return null;
return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
}
* 1.根据groups[0]和groups[1]的记录,从string字符串中返回子字符串
* [groups[0],groups[1])
*
*重复执行以上过程
*
* * */
while (matcher.find()){
System.out.println(matcher.group(0));
}
}
以上是正则表达式中未有分组的情况,接下来考虑分组
public static void main(String[] args) {
String string="1998年12月8日,第二代Java平台的企业版J2EE发布。" +
"1999年6月,Sun公司发布了第二代Java平台(简称为Java2)的3个版本:" +
"J2ME(Java2 Micro Edition,Java2平台的微型版)," +
"应用于移动、无线及有限资源的环境;J2SE(Java 2 Standard Edition,Java 2平台的标准版)," +
"应用于桌面环境;J2EE(Java 2Enterprise Edition,Java 2平台的企业版),应用于基于Java的应用服务器。" +
"Java 2平台的发布,是Java发展过程中最重要的一个里程碑,标志着Java的应用开始普及。";
//创建正则表达式
// \为转义字符,\d代表一个任意数字
String reg="(?<g1>\\d\\d)(?<g2>\\d\\d)";
//创建一个模式对象
Pattern pattern = Pattern.compile(reg);
//创建一个匹配器,按照上面的正则表达式的规则匹配上面string字符串
Matcher matcher = pattern.matcher(string);
//开始匹配
/*
* matcher.find()
* 非命名分组,正则表达式中()代表分组,第一个()代表第一组,以此类推
* 1.根据指定的规则定位满足的字符串
* 2.找到后,将子字符串开始的位置索引记录到matcher对象的属性 int[] groups
* 2.1 记录整个字符串 groups[0]=0,groups[1]=4;
* 2.2 记录第一组的字符串 groups[2]=0,groups[3]=2;
* 2.2 记录第二组的字符串 groups[4]=2,groups[5]=4;
* 2.3 如有更多以此类推
* groups数组中默认值为-1
* 3.同时记录oldlast值为子字符串结束位置的索引加一,即下一次执行find是从该位置开始匹配
*
* 命名分组
* String reg="(?<g1>\\d\\d)(?<g2>\\d\\d)";
* 名字不可以为数字开头,不能包含任何的符号
* 可以通过
* System.out.println("第一组:"+ matcher.group("g1"));
* 去到
*
*
*
* matcher.group()
* 以下是源码
*
* public String group(int group) {
if (first < 0)
throw new IllegalStateException("No match found");
if (group < 0 || group > groupCount())
throw new IndexOutOfBoundsException("No group " + group);
if ((groups[group*2] == -1) || (groups[group*2+1] == -1))
return null;
return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
}
* 1.根据groups[0]和groups[1]的记录,从string字符串中返回子字符串
* [groups[0],groups[1])
*
*重复执行以上过程
*
* * */
while (matcher.find()){
System.out.println(matcher.group(0));
System.out.println("第一组:"+ matcher.group(1));
System.out.println("第一组:"+ matcher.group("g1"));
System.out.println("第二组:"+ matcher.group(2));
}
}
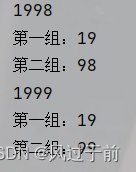
运行结果如下
3.正则表达式语法
1.转义号 \
在匹配一些特殊的符号是,往往需要用到转义符号\,例如要匹配(,则需要\(的形式。
在Java的正则表达式中\代表其他语言中的一个\。
常见的需要转义号的字符: . * + ( ) $ / \ ? [ ] ^ { }
2.字符匹配符
[abc] [ ] 中括号,包含a,b,c中任意字符
[^abc] [ ]中括号加^, 表示否定,除a,b,c之外的
[a-z] 从a到z的任意字符
. (小数点) 任意字符,除了\n
\d 数字0-9
\D 非数字,等价于[^0-9]
\w 词字符,数字,大小写字母,等价于[0-9a-zA-Z]
\W 非词,等价于[^\w]
\s 空白字符,包含空格,换行,回车,tab,换页
\S 大写为小写的取反,非空白字符,等价于[^\s]
java正则表达式默认区分大小写
但是在前面加(?i),表示不区分
(?i)abc abc均不分
a(?i)bc bc不分
a((?i)b)c b不分
或者
public static void main(String[] args) {
String string="Abc";
String rege="abc";
//创建pattern对象是,指定Pattern.CASE_INSENSITIVE,表示匹配不区分大小写
Pattern pattern = Pattern.compile(rege, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(string);
while (matcher.find()){
System.out.println("找到 :"+ matcher.group(0));
}
}
3.选择匹配符
| 匹配|之前或之后的表达式
4.限定符
* 指定字符出现0次或n次
+ 指定字符出现1次或n次(至少一次)
? 指定字符出现0次或1次(最多一次)
{n} 只能有n个字符
{n,} 至少n个字符
{n,m} n到m个字符之间
java默认为贪婪匹配,优先匹配字符多的选项
5.定位符
^ 一行的开始
$ 一行的结束
\b 匹配字符串的边界
\B 与\b意义相反
6.分组
1.非命名分组
2.命名分组
3.非捕获分组(不能使用group获取分组)
xxx(?: aa|bb|cc)
匹配xxxaa或xxxbb或xxcc
xxx(?=aa|bb|cc)
匹配xxxaa或xxxbb或xxcc中的xxx
xxx(?!aa|bb|cc)
匹配除xxxaa或xxxbb或xxcc中的xxx
7.反向引用
括号内的内容被捕获后可以在括号后面被使用
内部反向引用\组号,外部反向引用$组号
取五位相同的数字
(\d)\1{4}
匹配千位和个位相同,十位和百位相同
(\d)(\d)\2\1
8.非贪婪匹配
\d+?
优先匹配一个数字
4.matcher的一些方法
matcher.start() //返回匹配子字符串的开始位置
matcher.end() //返回匹配子字符串结束位置加一
Pattern.matchers(pattern,string) //返回一个bool值,找到匹配的返回1,否者返回0
matcher.matchers() //整体匹配,同样是返回一个bool值
String string=matcher.replaceAll("xxx") //将匹配到子符替换成xxx,并返回一个String类型的字符串,原字符串不会变化
5.正则表达式在String类中的使用
替换
public static void main(String[] args) {
String string="jdk1.3和jdk1.4";
//将上面的jdk1.3,jsk1.4为jdk
string=string.replaceAll("jdk1\\.(3|4)","jdk");
System.out.println(string);
}
验证
public static void main(String[] args) {
//判断是否为138,139开头
String string="13612345678";
if(string.matches("1(38|39)\\d{8}")){
System.out.println("Fonud it");
}
else{
System.out.println("No");
}
}
字符串分割
public static void main(String[] args) {
//按照空格分割字符串
String string="hello world , ni hao";
String[] s=string.split("\\s");
for (String s1:s){
System.out.println(s1);
}
}
















 2628
2628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











