







目录
为何要知道到底是卡在local minima,还是卡在saddle point呢
如何判断local minima与saddle point呢?
1.Small Batch v.s. Large Batch
“Noisy” update is better for training
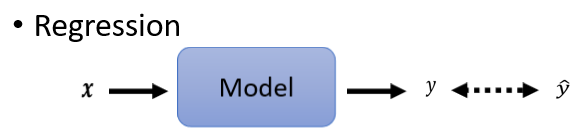
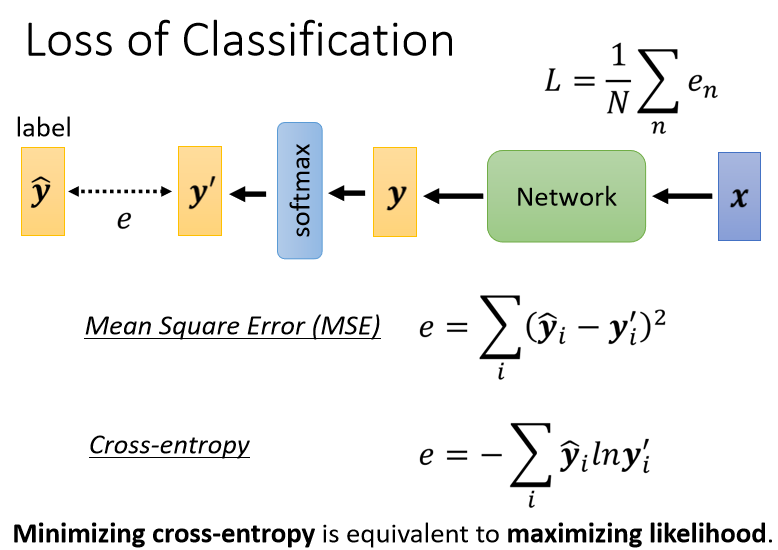
1、Classification as Regression?
1、啥时候会出现比较不好 train 的 error surface 呢?

一、鞍点
local minima 与saddle point 都能使gradient为0
为何要知道到底是卡在local minima,还是卡在saddle point呢
因為如果是卡在local minima,那可能就没有路可以走了
但saddle point就比较没有这个问题
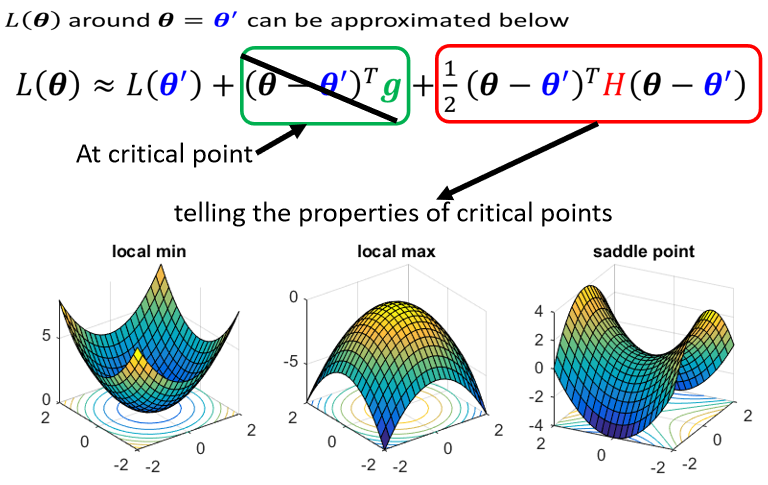
如何判断local minima与saddle point呢?
1.泰勒展开


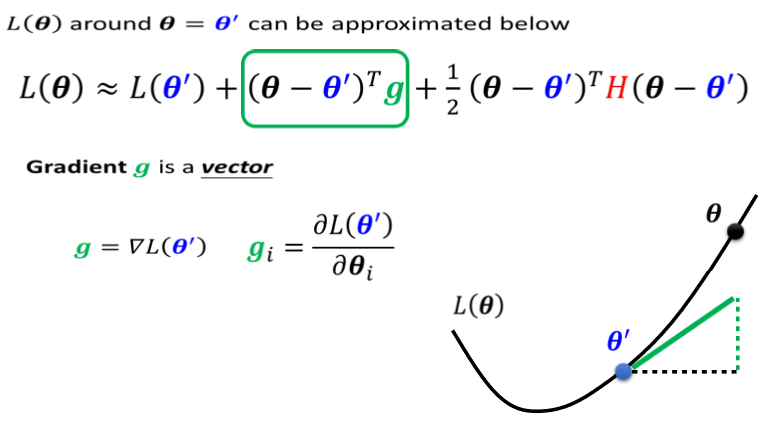
g是一个向量,这个g就是我们的gradient
第三项跟Hessian有关,这边有一个H
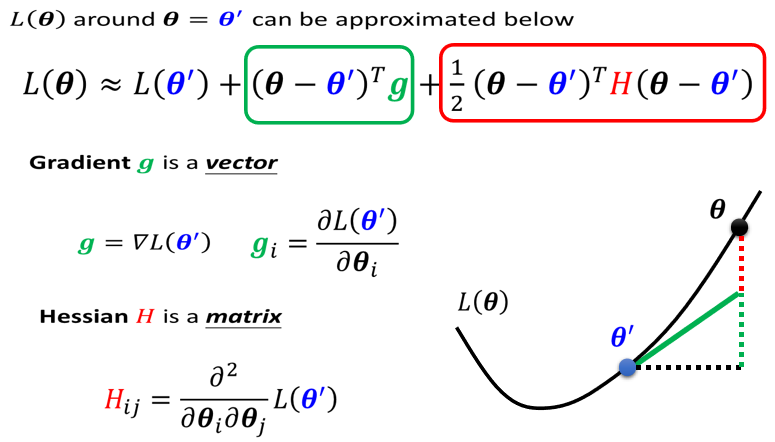
这个H叫做Hessian矩阵
2.Hession矩阵
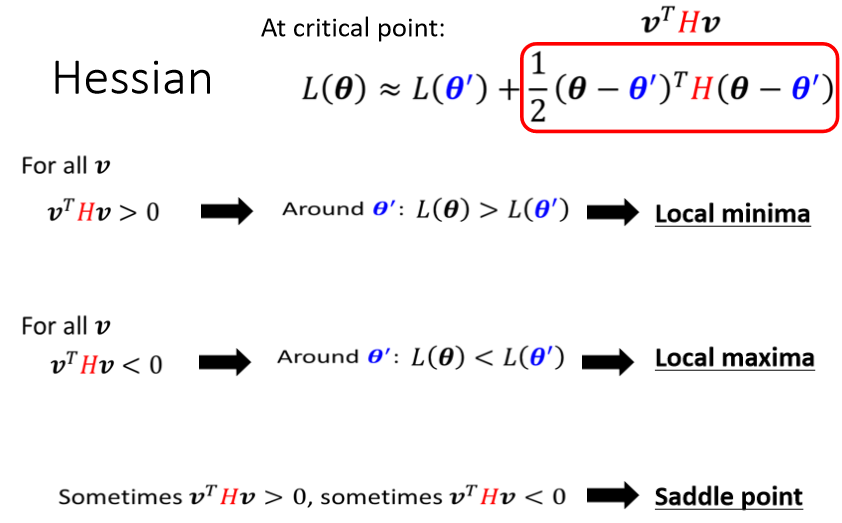


Hv都大於零,那这种矩阵叫做positive definite 正定矩阵,positive definite的矩阵,它所有的eigen value特征值都是正的
3.史上最废的network
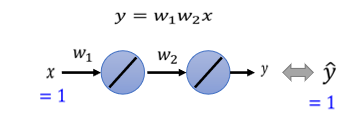
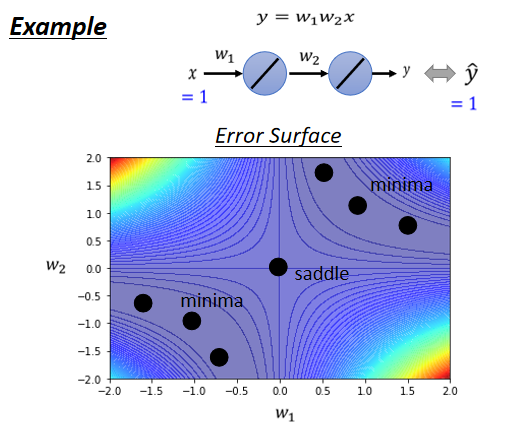
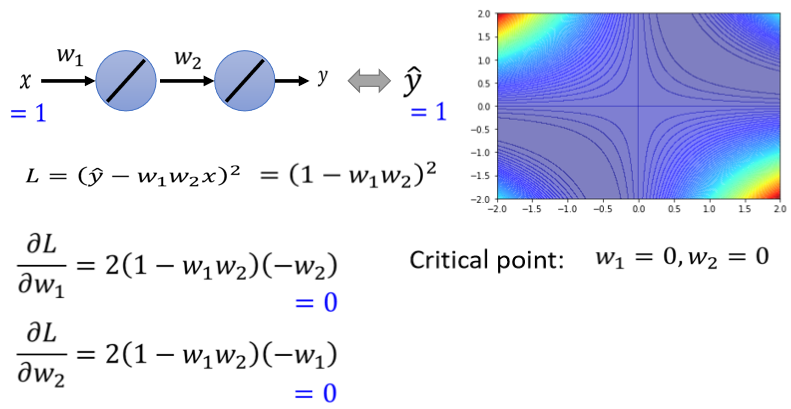
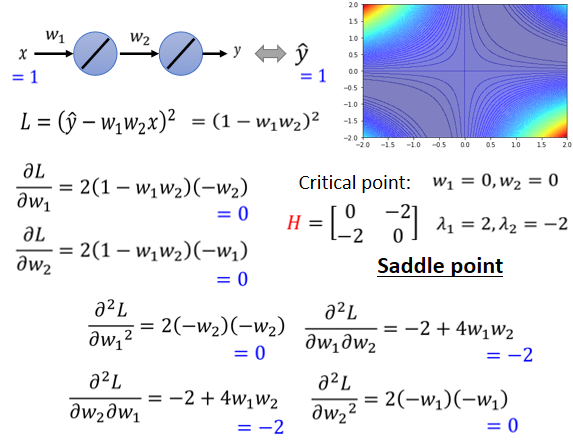
eigen value有正有负,代表saddle point
二、saddle point(鞍点)


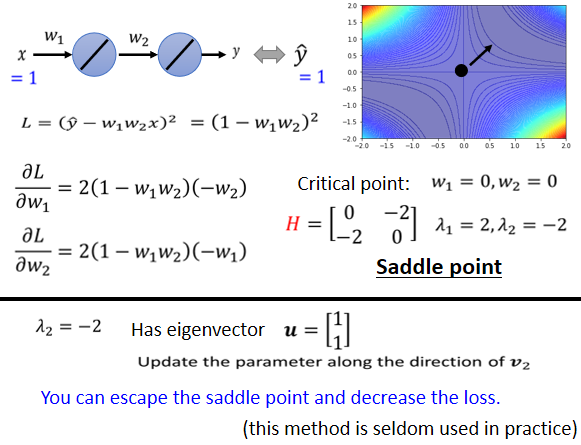
但是当然实际上,在实际的implementation裡面,你几乎不会真的把Hessian算出来
如果所有的eigen value都是正的,代表我们今天的critical point,是local minima,如果有正有负代表saddle point
三、Optimization with Batch
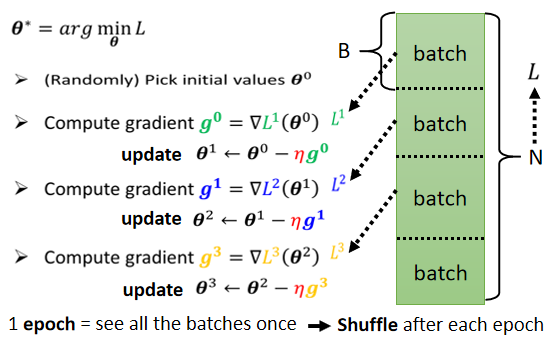
所有的 Batch 看过一遍,叫做一个 Epoch。
1.Small Batch v.s. Large Batch
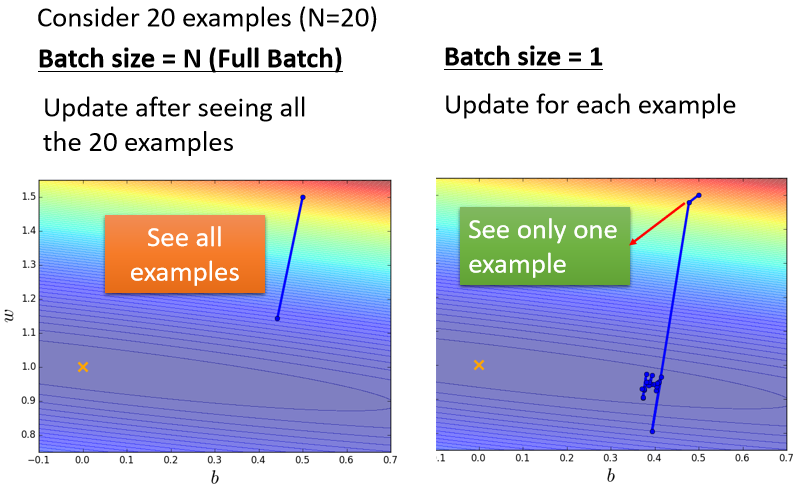
假设现在我们有20笔训练资料
左边的 Case 就是没有用 Batch,这种状况叫做 Full Batch,就是没有用 Batch 的意思
那右边的 Case 就是,Batch Size 等於1
左边的 Case,必须要把所有20笔 Example s 都看完以后,我们的参数才能够 Update 一次
如果 Batch Size 等於1的话,代表我们只需要拿一笔资料出来算 Loss,我们就可以 Update 我们的参数
如果今天总共有20笔资料的话 那在每一个 Epoch 裡面,我们的参数会 Update 20次,
所以如果我们比较左边跟右边,哪一个比较好呢,他们有什麼差别呢?

左边是蓄力时间长,但是威力比较大,右边技能冷却时间短,但是它是比较不準的, 实际上考虑并行运算的话,左边这个并不一定时间比较长
更大的batch不需要花费更多的时间计算梯度
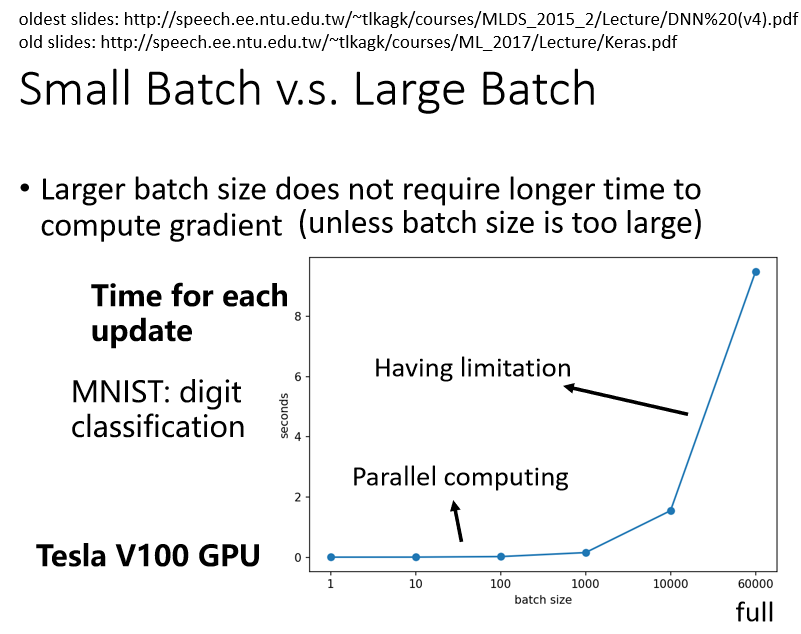
GPU,可以做并行运算


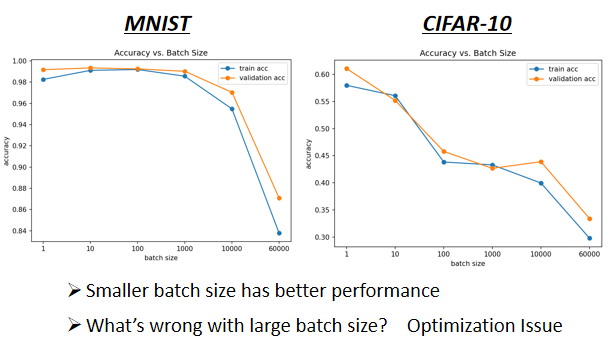
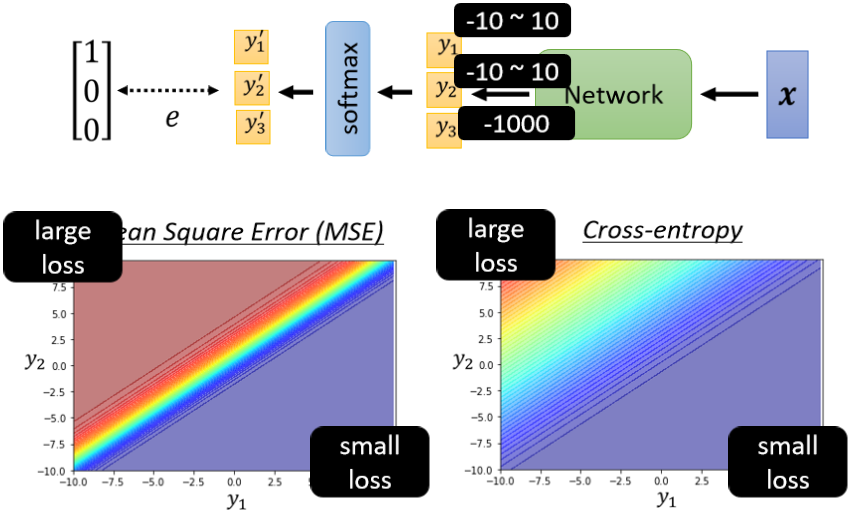
- 横轴代表的是 Batch Size,从左到右越来越大
- 纵轴代表的是正确率,越上面正确率越高,当然正确率越高越好
这个是 Optimization 的问题,代表当你用大的 Batch Size 的时候,你的 Optimization 可能会有问题,小的 Batch Size,Optimization 的结果反而是比较好的,好 為什麼会这样子呢
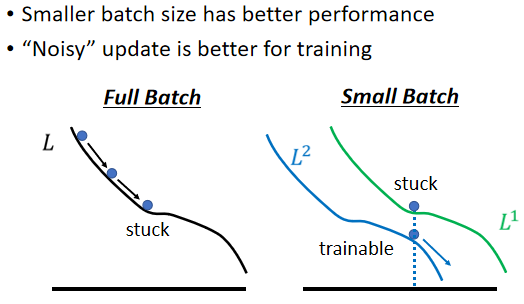
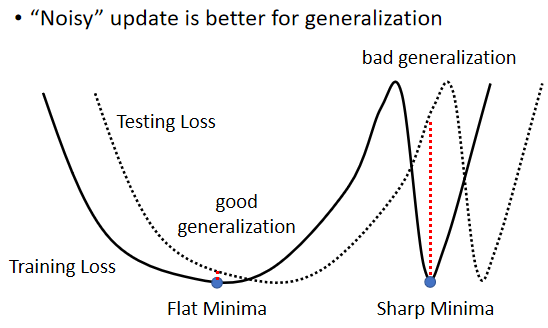
(3)“Noisy” update is better for training
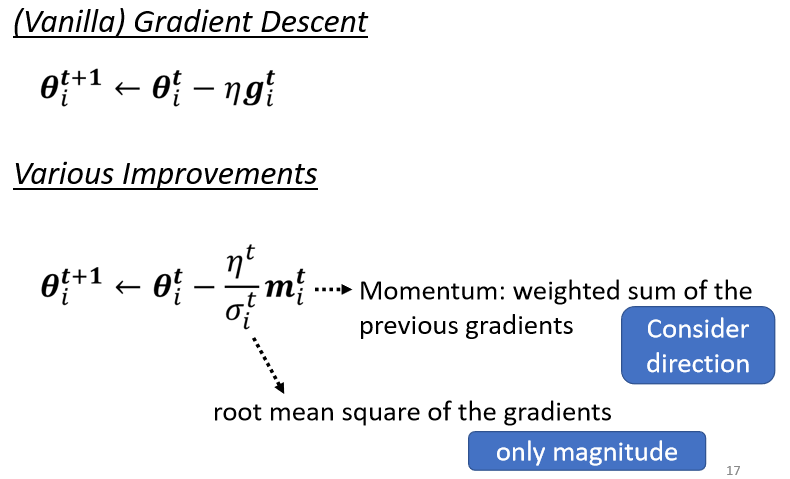
四、Momentum
(1)Small Gradient
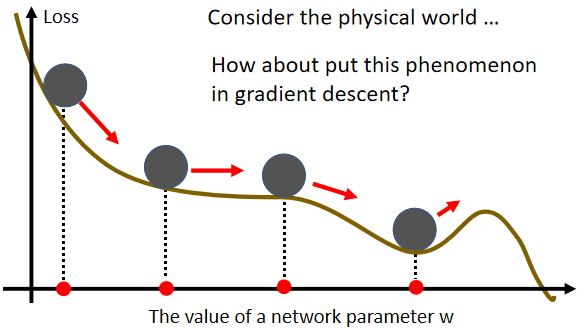
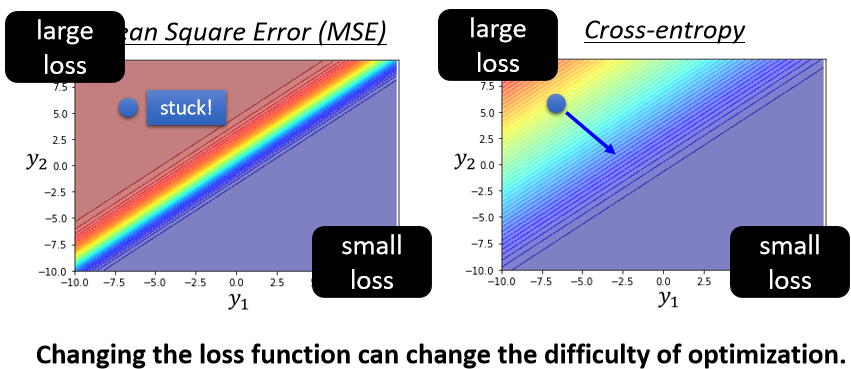
它的概念,你可以想像成在物理的世界裡面,假设 Error Surface 就是真正的斜坡,而我们的参数是一个球,你把球从斜坡上滚下来,如果今天是 Gradient Descent,它走到 Local Minima 就停住了,走到 Saddle Point 就停住了
但是在物理的世界裡,一个球如果从高处滚下来,从高处滚下来就算滚到 Saddle Point,如果有惯性,它从左边滚下来,因為惯性的关係它还是会继续往右走,甚至它走到一个 Local Minima,如果今天它的动量够大的话,它还是会继续往右走,甚至翻过这个小坡然后继续往右走
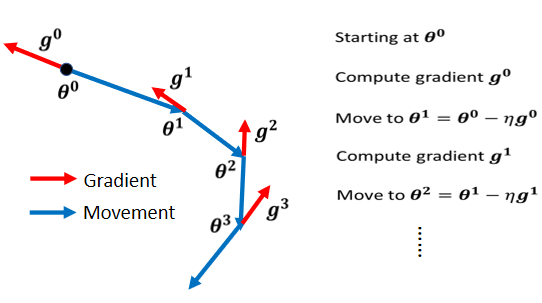
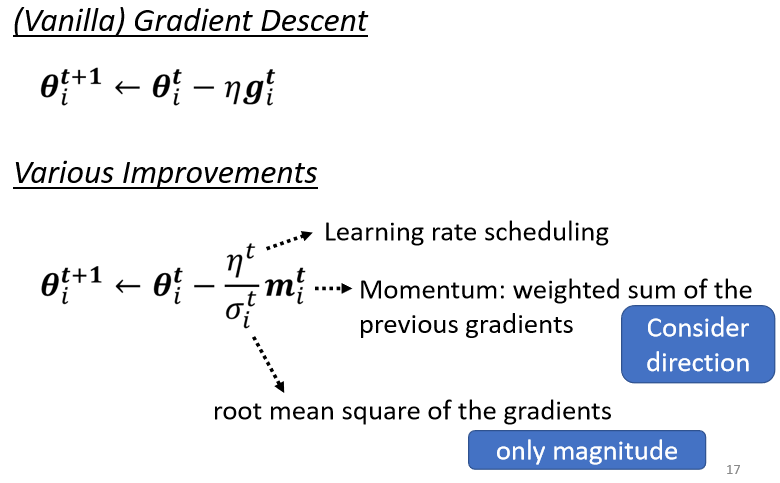
(2)Vanilla Gradient Descent
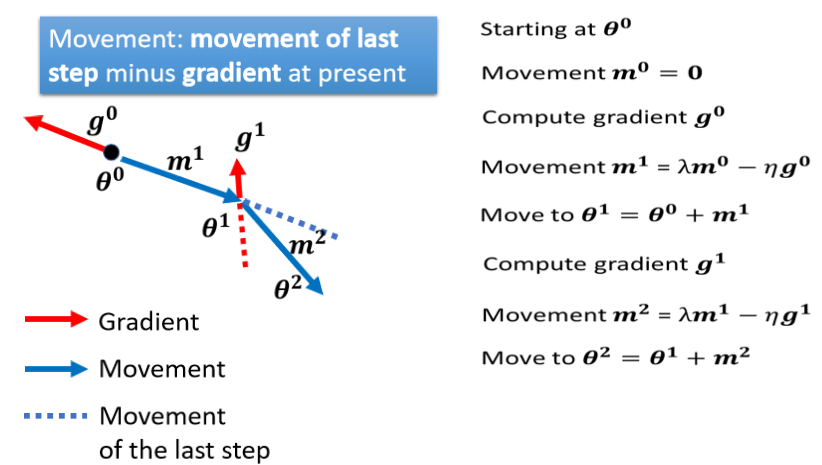
我们是 Gradient 的反方向,加上前一步移动的方向,两者加起来的结果,去调整去到我们的参数,

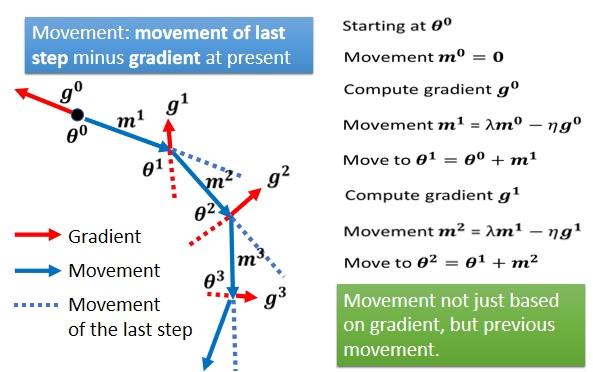



如果有 Momentum 的话,你还是有办法继续走下去,因為 Momentum 不是只看 Gradient,Gradient 就算是 0,你还有前一步的方向,前一步的方向告诉我们向右走,我们就继续向右走,甚至你走到这种地方,Gradient 告诉你应该要往左走了,但是假设你前一步的影响力,比 Gradient 要大的话,你还是有可能继续往右走,甚至翻过一个小丘,搞不好就可以走到更好 Local Minima,这个就是 Momentum 有可能带来的好处
五、Learning Rate
1.训练中stuck ≠ 小梯度
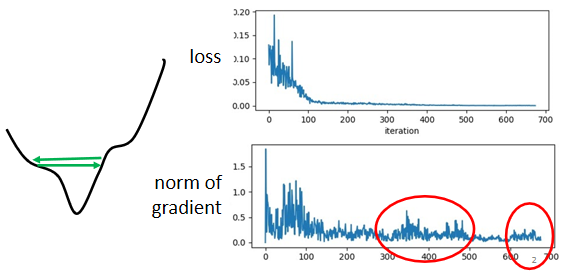
gradient是一个向量,下面是gradient的norm,即gradient这个向量的长度,随著参数更新的时候的变化,你会发现说虽然loss不再下降,但是这个gradient的norm,gradient的大小并没有真的变得很小

这个是我们的error surface,然后你现在的gradient,在error surface山谷的两个谷壁间,不断的来回的震荡
它的gradient仍然很大,只是loss不见得再减小了
2、Wait a minute
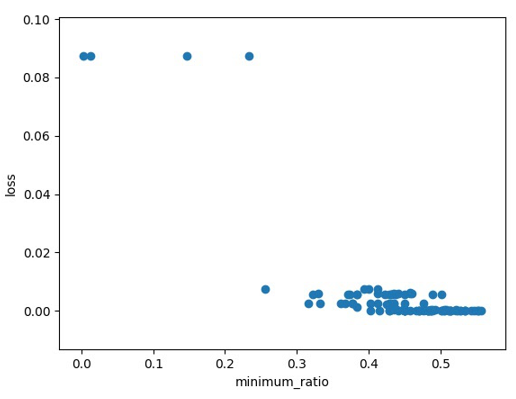
训练到现在参数在critical point附近,然后我们再来根据eigen value的正负号,来判断说这个critical point,比较像是saddle point,还是local minima
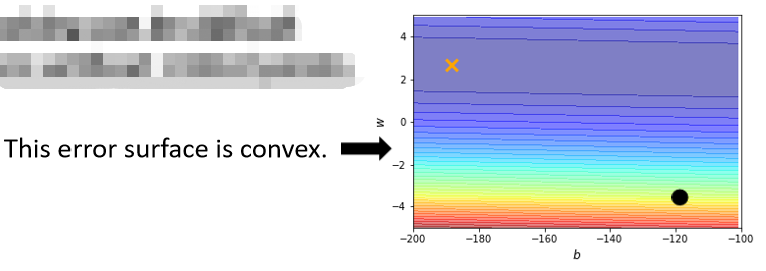
没有critical points时训练可能也困难
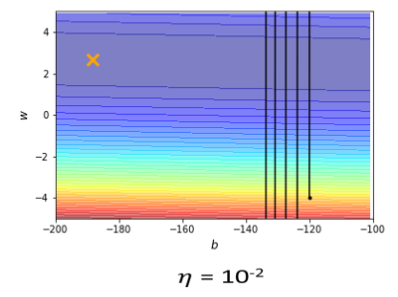
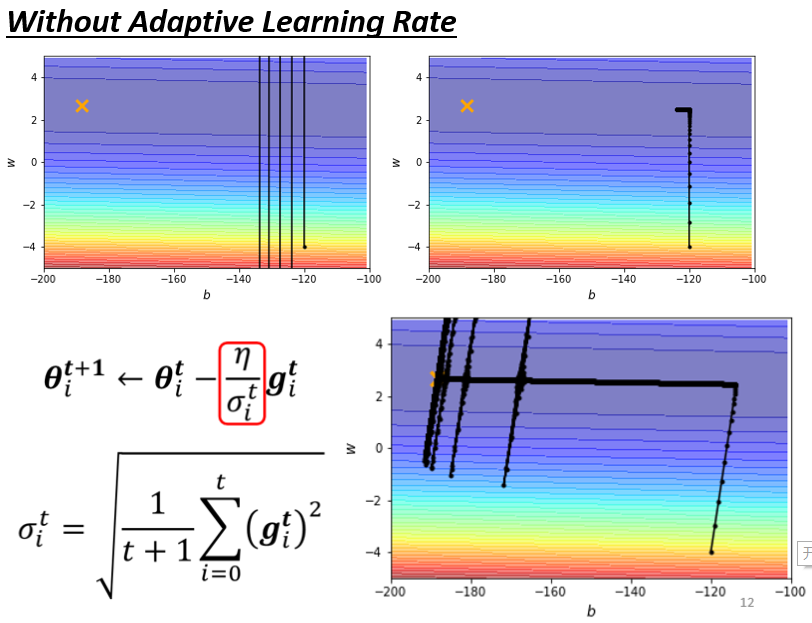
learning rate设10⁻²的时候,我的这个参数在峡谷的两端,我的参数在山壁的两端不断的震盪,
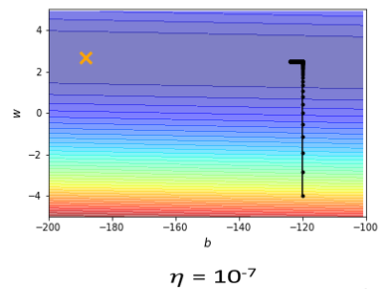
learning rate太小,这个训练永远走不到终点
3、均方根Root mean square
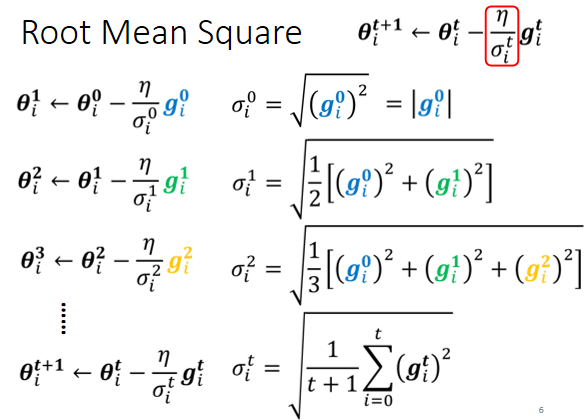
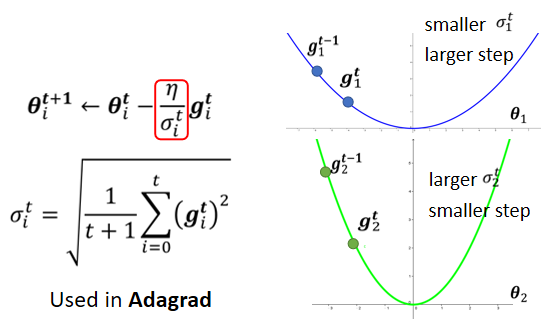
4、Adagrad

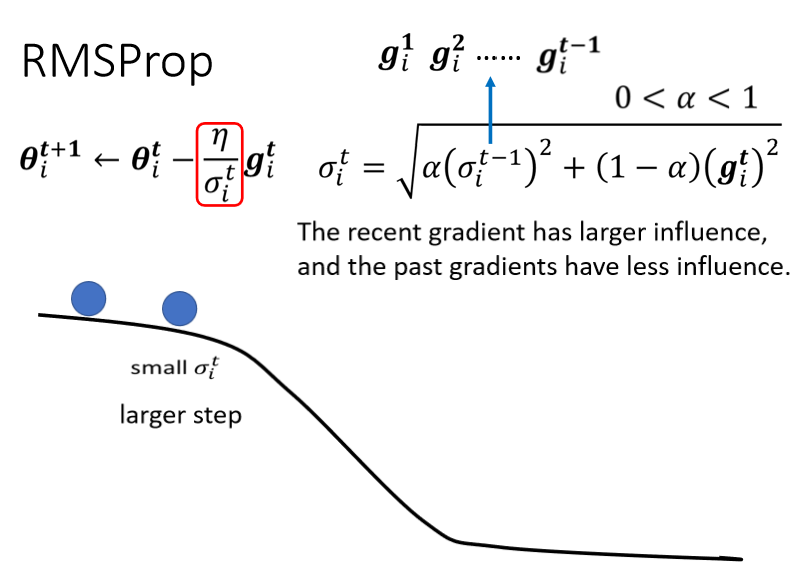
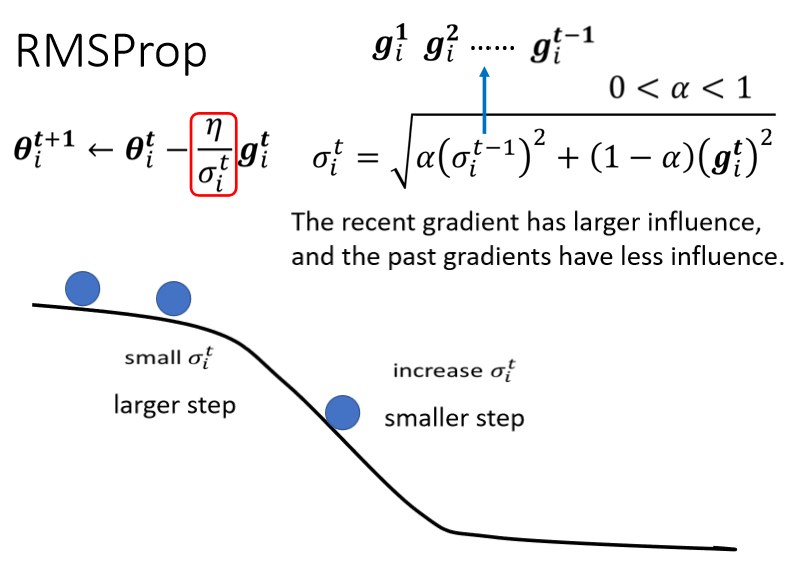
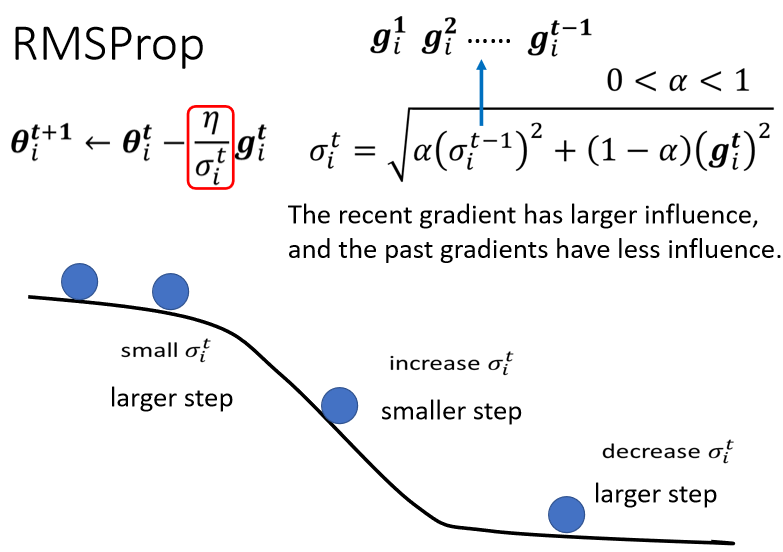
5、RMSProp
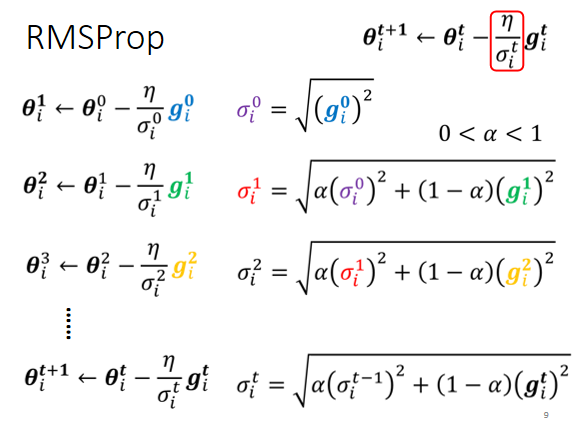

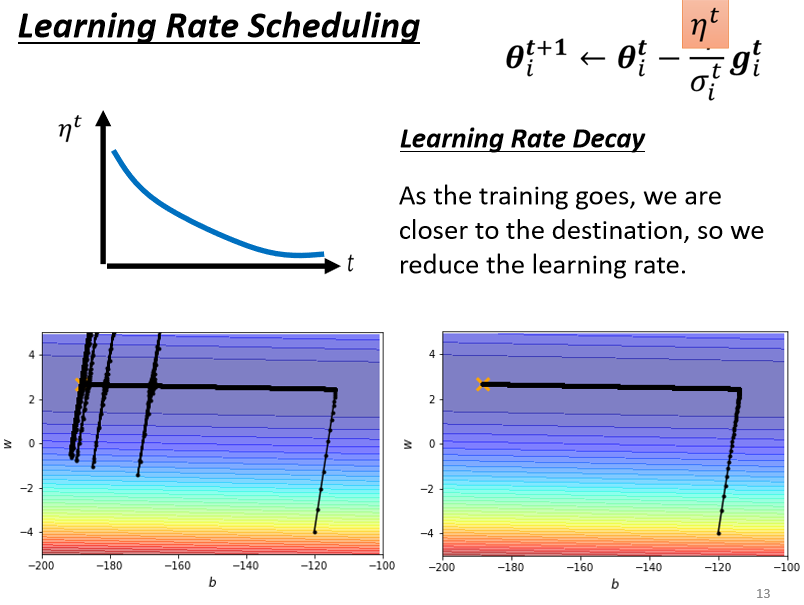
6.Learning Rate Scheduling
所以这个纵轴的方向,在这个初始的这个地方,感觉gradient很大
可是这边走了很长一段路以后,这个纵轴的方向,gradient算出来都很小,所以纵轴这个方向,这个y轴的方向就累积了很小的σ
因為我们在这个y轴的方向,看到很多很小的gradient,所以我们就累积了很小的σ,累积到一个地步以后,这个step就变很大,然后就爆走就喷出去了
喷出去以后没关係,有办法修正回来,因為喷出去以后,就走到了这个gradient比较大的地方,走到gradient比较大的地方以后,这个σ又慢慢的变大,σ慢慢变大以后,这个参数update的距离,Update的步伐大小就慢慢的变小
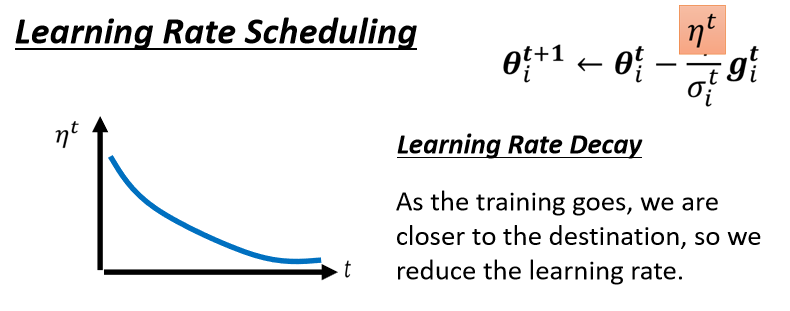
不要把η当一个常数,我们把它跟时间有关
常用的Learning Rate Scheduling的方式,叫做Warm Up
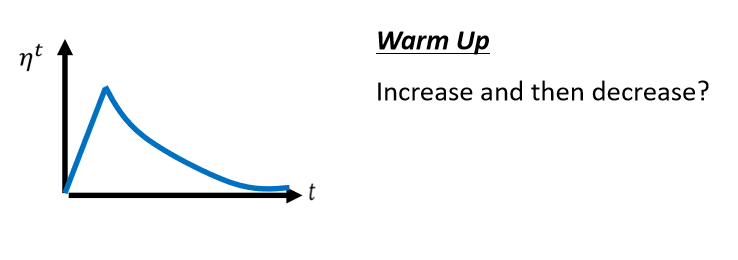
Warm Up的方法是让learning rate,要先变大后变小

σ告诉我们,某一个方向它到底有多陡,或者是多平滑,那这个统计的结果,要看得够多笔数据以后,这个统计才精準,所以一开始我们的统计是不精準的
所以一开始learning rate比较小,是让它探索 收集一些有关error surface的情报,先收集有关σ的统计数据,等σ统计得比较精準以后,在让learning rate呢慢慢地爬升
Optimization总结

六、Classification
1、Classification as Regression?
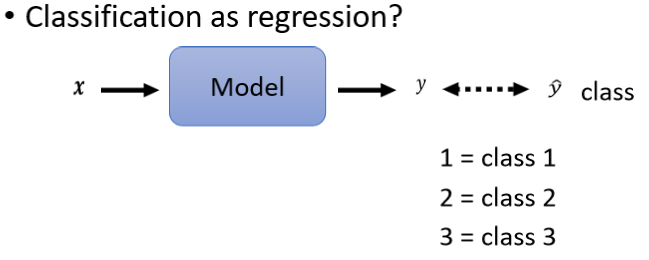
举例来说 Class1就是编号1,Class2就是编号2,Class3就是编号3,接下来呢 我们要做的事情,就是希望y可以跟Class的编号,越接近越好
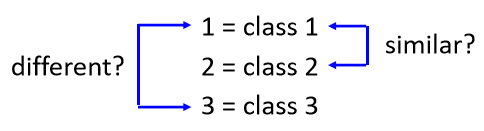
假设你的Class one two three真的有某种关係举例来说,你想要根据一个人的身高跟体重,然后预测他是几年级的小学生,一年级 二年级 还是三年级,那可能一年级真的跟二年级比较接近,一年级真的跟三年级比较没有关係
但是假设你的三个Class本身,并没有什麼特定的关係的话,你说Class one是1,Class two是2 Class two是3,那就很奇怪了,因為你这样是预设说,一二有比较近的关係,一三有比较远的关係,所以怎麼办呢
2、Class as one-hot vector
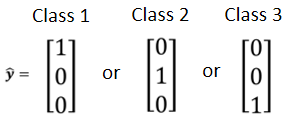
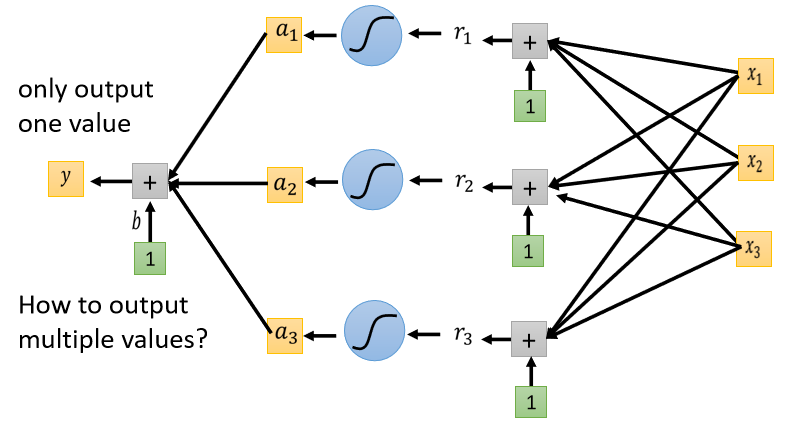
Classification with softmax
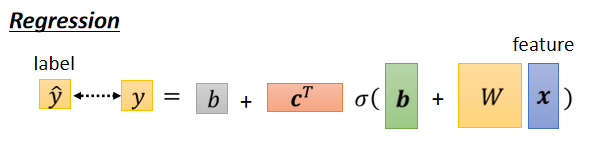

既然我们的目标只有0跟1,但是y有任何值,我们就先把它Normalize到0到1之间,这样才好跟 label 的计算相似度

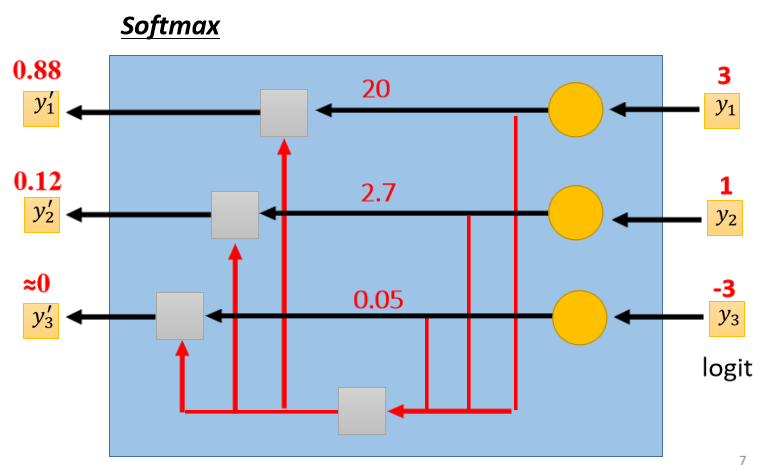
当两个class用sigmoid,跟soft-max两个class,你如果推一下的话,会发现说这两件事情是等价的
分类时的损失函数loss

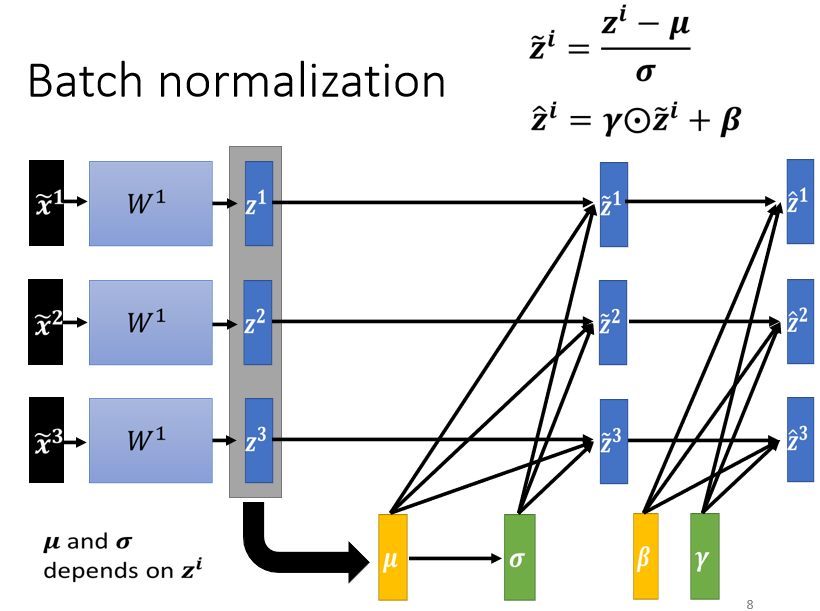
Batch Normalization
1、改变Landscape的必要性
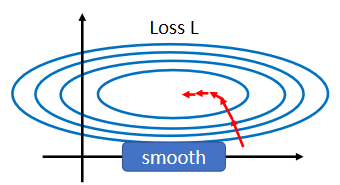
1、啥时候会出现比较不好 train 的 error surface 呢?



2、Feature Normalization

Feature Normalization的一种可能性

做完 normalize 以后啊,这个 dimension 上面的数值就会平均是 0,然后它的 variance就会是 1,所以这一排数值的分布就都会在 0 上下
对每一个 dimension都做一样的 normalization,就会发现所有 feature 不同 dimension 的数值都在 0 上下,那你可能就可以制造一个比较好的 error surface


3、对 z 做 Feature Normalization


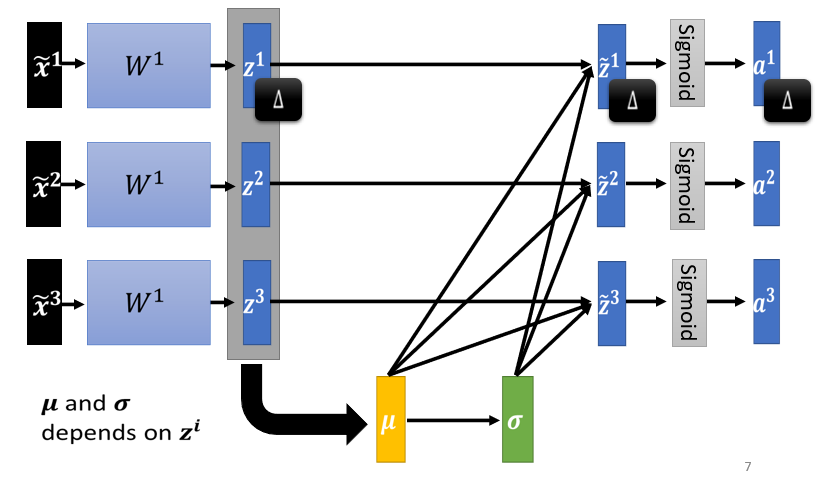
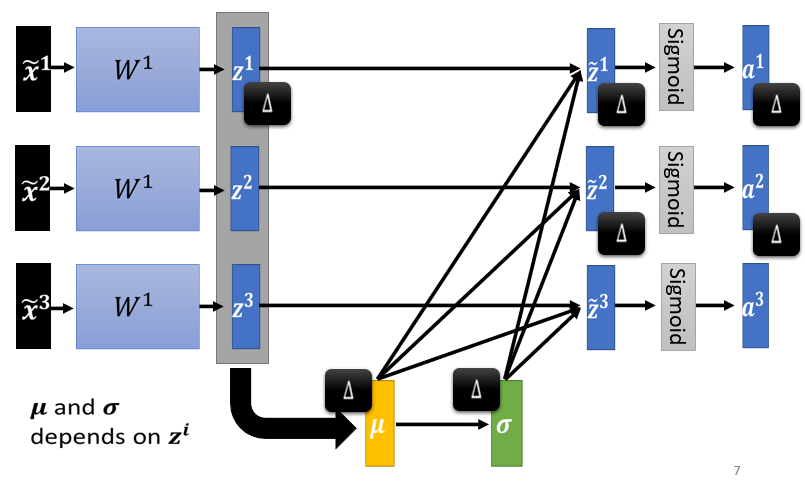
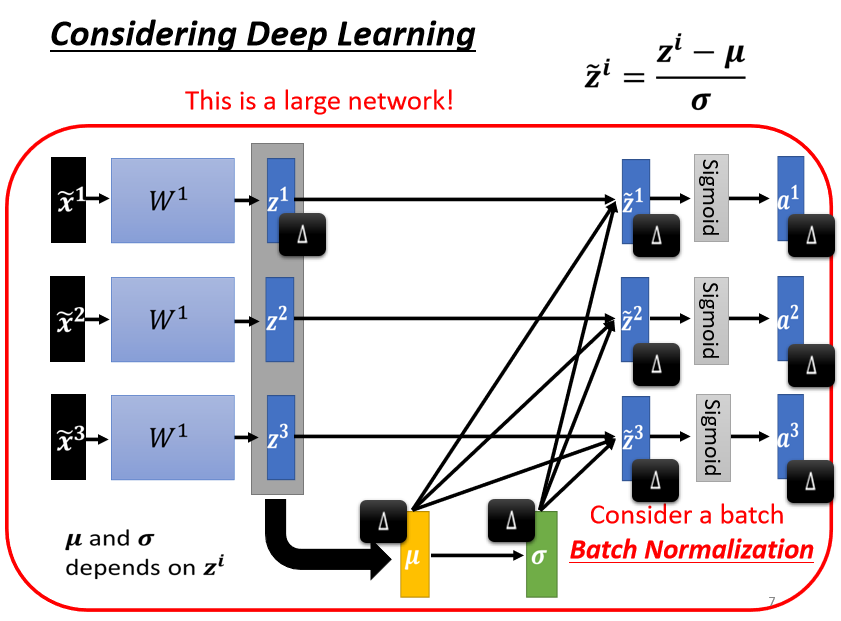
4、Testing
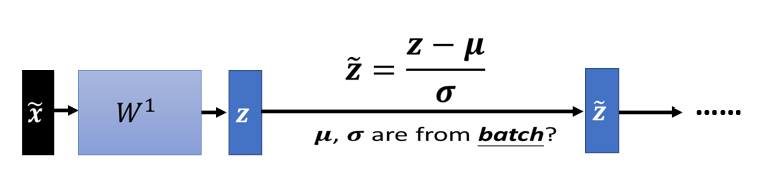
















 7123
7123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









