







目录
学习内容:获取重庆贝壳新房房价数据,CSV形式保存在本地,解决Excel打开乱码问题,并对其数据进行简单词云处理........
-
目标网址分析
-
目标网址
- 【重庆楼盘_重庆新楼盘_重庆新房房价】信息网-重庆贝壳新房
-
大体结构
查看后得到:
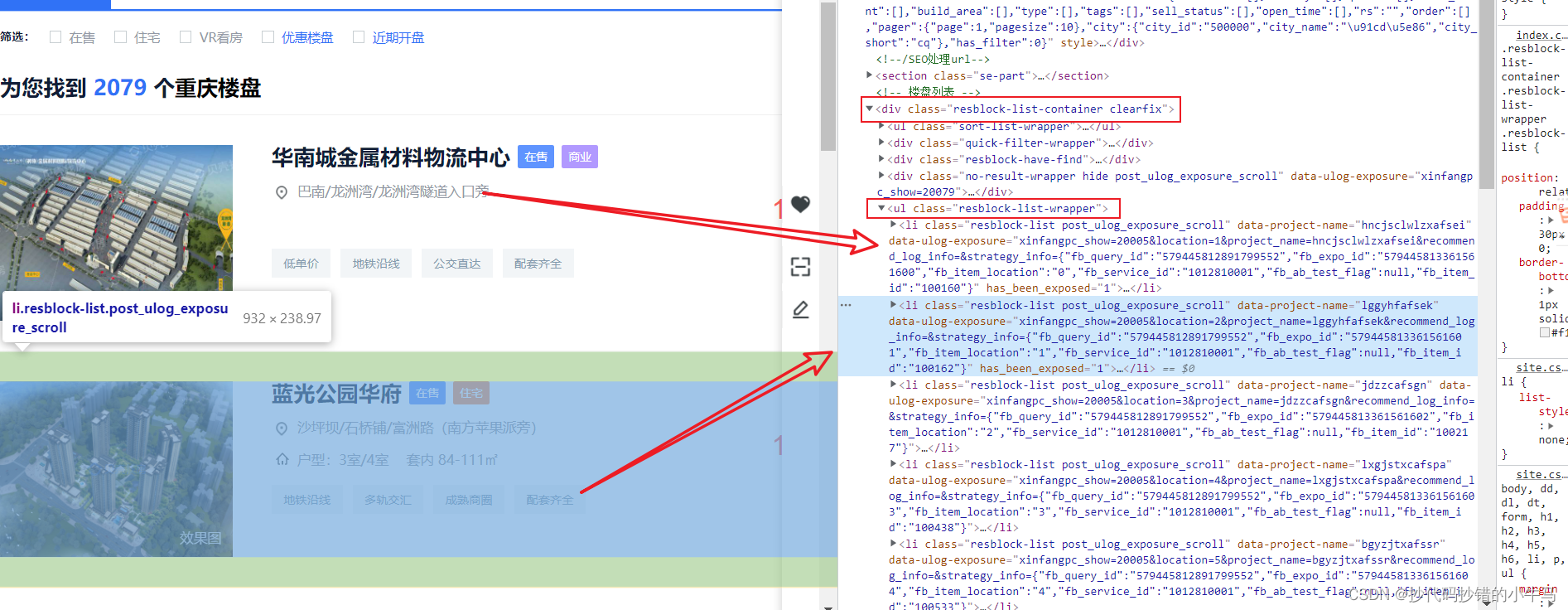
- 提取结构:
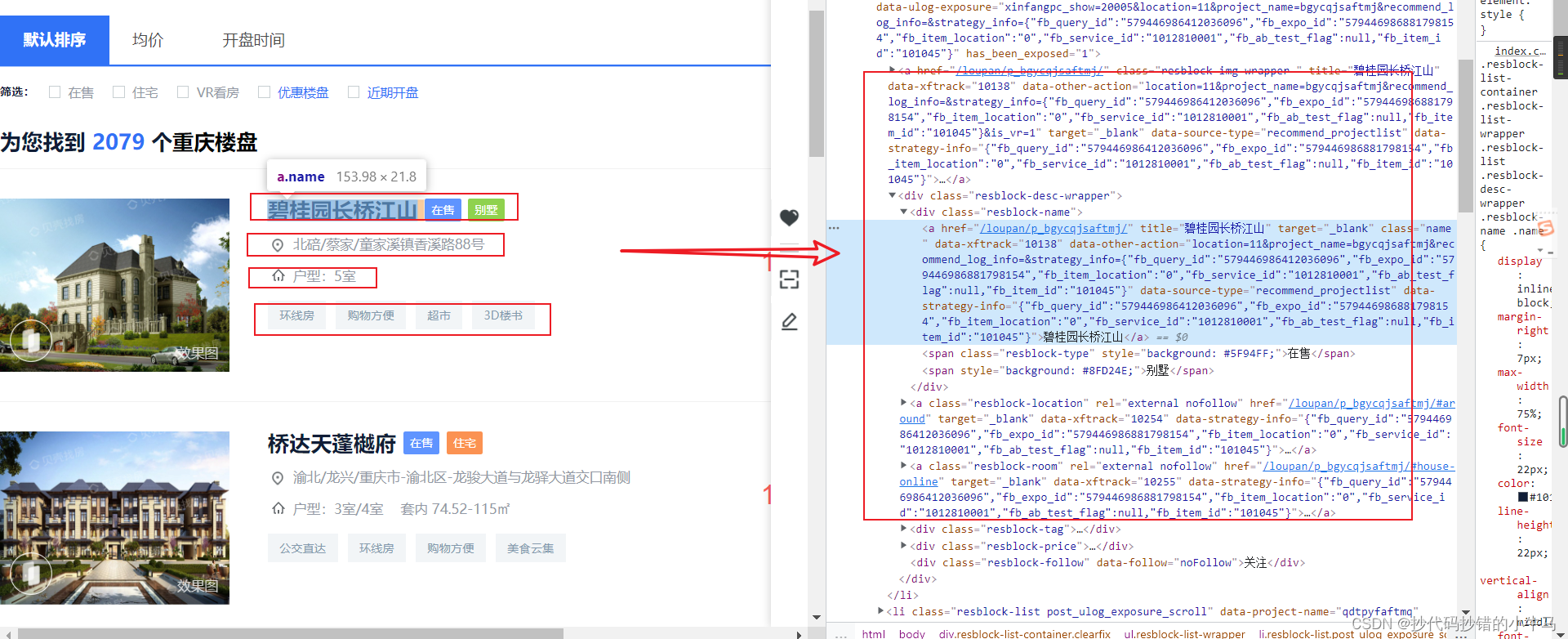
-
查看分页
- 发现分页很规则,,,,,,,,,
# https://cq.fang.ke.com/loupan/pg1/ 第 1 页 # https://cq.fang.ke.com/loupan/pg2/ 第 2 页 # https://cq.fang.ke.com/loupan/pg3/ 第 3 页 # url = 'https://cq.fang.ke.com/loupan/pg' + str(page)
-
数据获取与保存
代码:
"""
2022年
CSDN:抄代码抄错的小牛马
"""
import requests
from lxml import etree
import csv
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36',
}
# 分页操作
def get_url():
star_page = int(input("请输入起始页码:"))
end_page = int(input("请输入结束页码:"))
s = []
for page in range(star_page, end_page + 1):
url = 'https://cq.fang.ke.com/loupan/pg' + str(page)
# print(url)
s.append(url)
# print(s)
return s
# 解析数据与保存
def get_data(s):
for url in s:
# print(url)
resp = requests.get(url=url, headers=headers)
content = resp.text
# 解析
tree = etree.HTML(content)
li_list = tree.xpath('//div[@class="resblock-list-container clearfix"]/ul[@class="resblock-list-wrapper"]/li')
# 循环
for i in li_list:
# 标题
title = i.xpath('./div/div/a/text()')[0]
# 销售状态和房屋类型
type = i.xpath('./div/div[1]/span/text()')
zhuangtai_type = ','.join(type)
# 地理位置
location = i.xpath('./div[@class="resblock-desc-wrapper"]/a/text()')
locations = ' '.join(location).replace('\n\t', '').replace('\t', '')
# 平米均价
price = i.xpath('./div[@class="resblock-desc-wrapper"]/div[@class="resblock-price"]/div/span/text()')
avg_price = ''.join(price)
# 总价/套
General_price = \
i.xpath(
'./div[@class="resblock-desc-wrapper"]/div[@class="resblock-price"]/div[@class="second"]/text()')
General_prices = ''.join(General_price)
# 户型
room_type = i.xpath('./div[@class="resblock-desc-wrapper"]/a[@class="resblock-room"]/span/text()')
room_types = ''.join(room_type)
# 房子简介
Brief_introduction = i.xpath('./div[@class="resblock-desc-wrapper"]/div[@class="resblock-tag"]/span/text()')
Brief_introductions = ','.join(Brief_introduction)
# 写入数据
writer.writerow(
[title, zhuangtai_type, locations, avg_price, General_prices, room_types, Brief_introductions])
if __name__ == '__main__':
# 新建CSV文件 newline=''防止空行写入
f = open('重庆新房房价.csv', mode='a', encoding='utf-8', newline='')
writer = csv.writer(f)
# 写入表头, 在这里写如表头,可避免重复写入
head = ['标题', '销售状态和房屋类型', '地理位置', '平米均价', '总价/套', '户型', '房子简介']
writer.writerow(head)
s = get_url()
get_data(s)
# 关闭文件
f.close()
-
数据查看
-
CSV查看

-
Excel打开
- 解决乱码问题
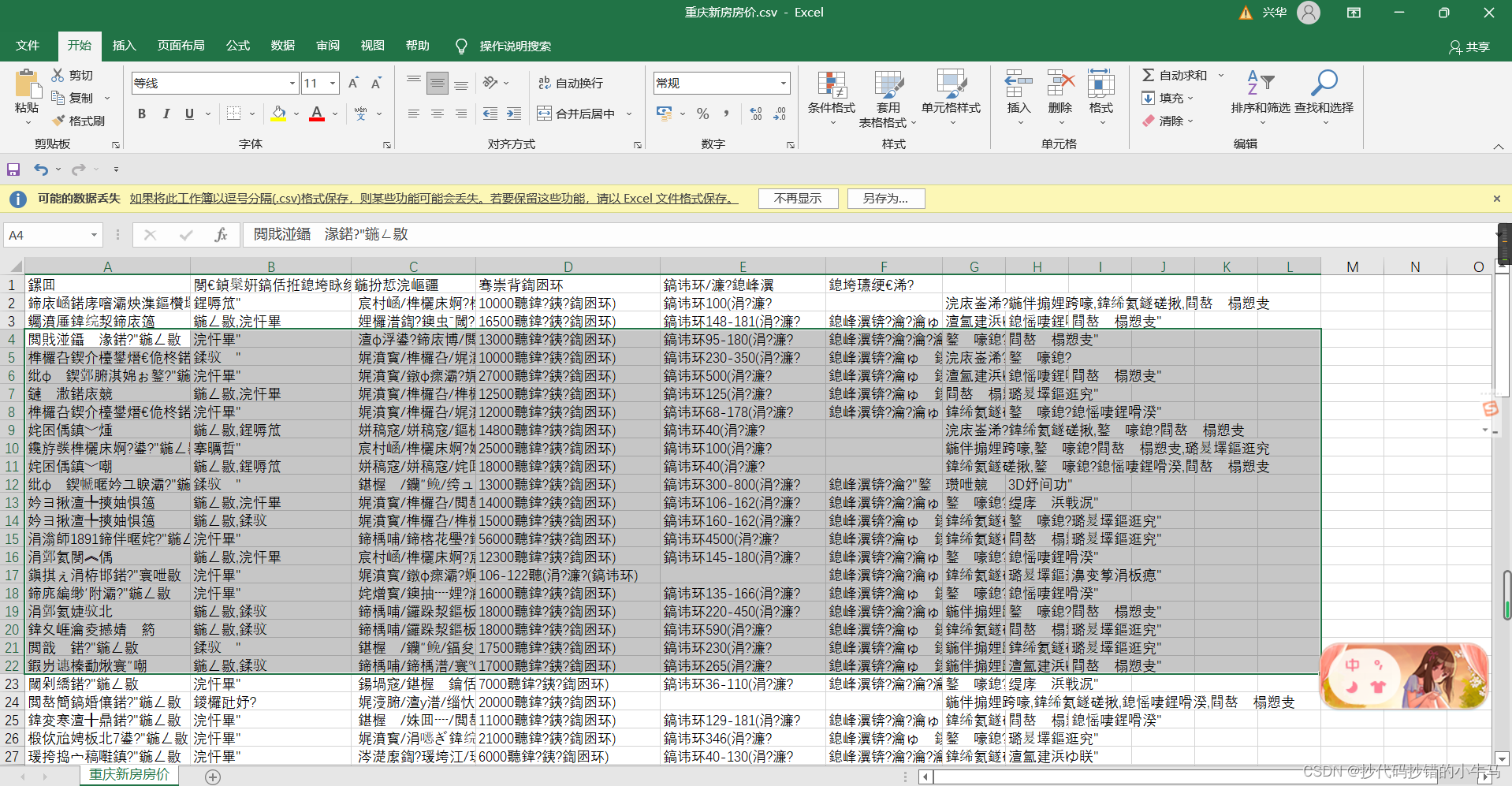
- 解决
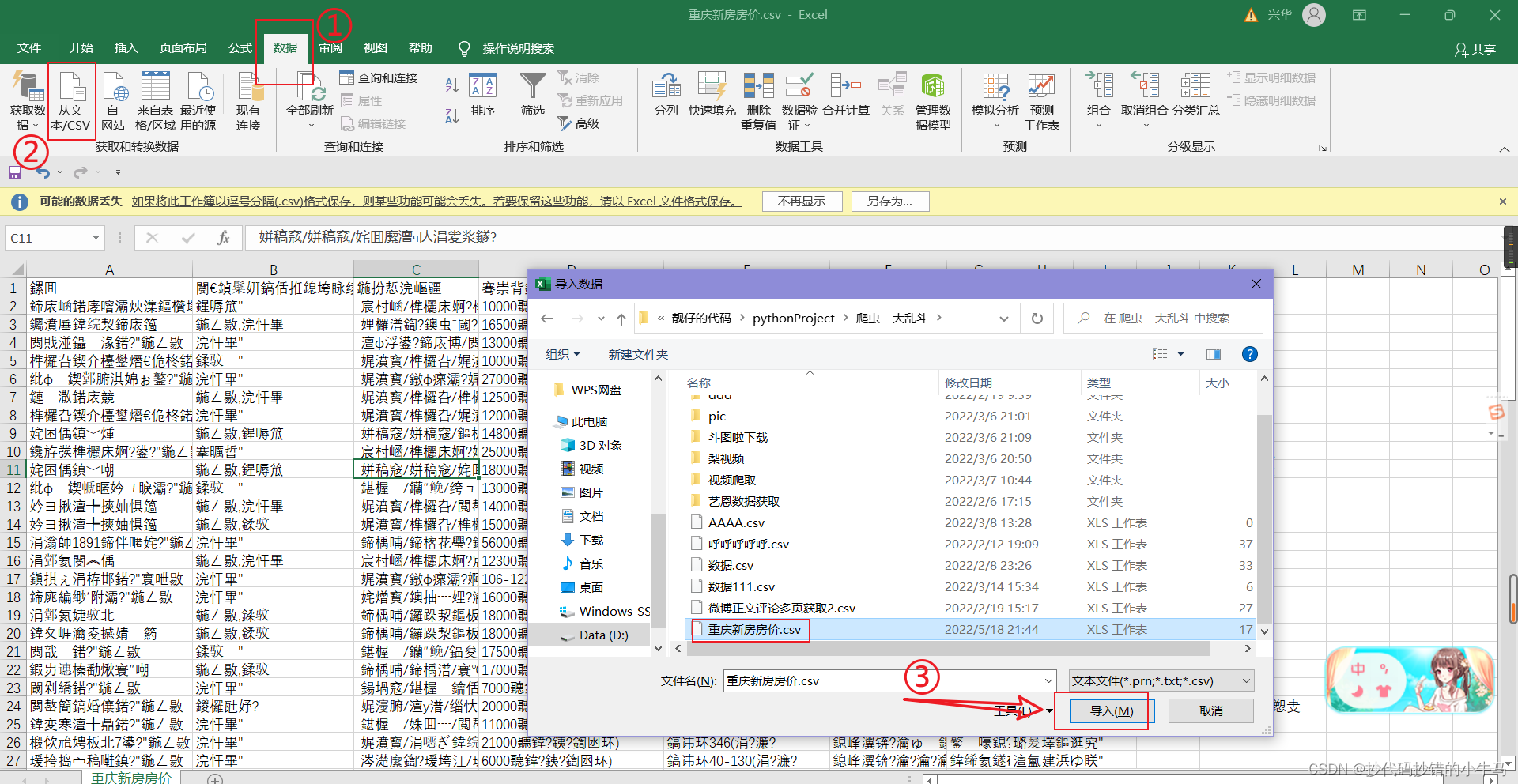
加载后,打开并另存为:

-
词云
代码:
"""
2022年
CSDN:抄代码抄错的小牛马
"""
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import wordcloud
import jieba
from wordcloud import ImageColorGenerator
def func1():
file = open('重庆新房房价.csv', encoding="utf-8") # 当前路径
result = file.read()
file.close()
return result
def func2(words):
wordList = jieba.lcut(words)
pic = np.array(Image.open("1.jpg"))
pic_color = ImageColorGenerator(pic)
c = wordcloud.WordCloud(scale=4,
mask=pic,
font_path="./1.ttf", # 字体路径(隶书)
background_color='white', ) # 背景颜色
c.generate(",".join(wordList)) # 生成词云
plt.imshow(c.recolor(color_func=pic_color), interpolation='bilinear')
c.to_file('./重庆重庆新房房价.jpg')
words = func1()
func2(words)
效果:

拜~~~
















 188
188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











