







0x45 点分治
到目前为止,我们用数据结构处理的大多是序列上的问题。这些问题的形式一般是给定序列中的两个位置 l l l和 r r r,在区间 [ l , r ] [l,r] [l,r]上执行查询或修改指令。如果给定一棵树,以及树上两个节点 x x x和 y y y,那么与“序列上的区间”相对应的就是“树上两点之间的路径”。我们先不考虑对路径进行修改的的操作。本节中介绍的点分治就是在一棵树上,对具有某些限定条件的路径静态进行统计的算法。
点分治是一种解决树上统计问题的常用方法,本质思想就是选择一点(重心)作为分治中心,将原问题划分为几个相同的子树上的问题,进行递归解决。
给一颗有 N N N个点的树,每条边都有一个权值。树上两个节点 x x x和 y y y之间的路径长度就是路径上各条边的权值之和。求长度不超过 K K K的路径有多少条。
本题中的边是无向的,即这棵树是一个由 N N N个点、 N − 1 N-1 N−1条边构成的无向连通图。我们把这种树称为“无根树”(所需维护的信息与根节点是谁无关),也就是说可以任意指定一个节点为根节点,而不影响问题的答案。
若指定节点 p p p为根,则对 p p p而言,树上的路径可以分为两类:
1.经过根节点 p p p(包含一端为根节点 p p p)。
2.包含于 p p p的某一棵子树中(不经过根节点)。
根据分治的思想,对于第2类路径,显然可以把 p p p的每棵子树作为子问题,递归进行处理。
而对于第1类路径,可以从根节点
p
p
p分成“
x
∼
p
x\sim p
x∼p”与“
p
∼
y
p\sim y
p∼y”两段。回顾在0x21节所学到的知识,我们可以从
p
p
p出发对整棵树进行DFS,求出数组
d
d
d,其中
d
[
x
]
d[x]
d[x]表示点
x
x
x到根节点
p
p
p的距离。同时还可以求出数组
b
b
b,其中
b
[
x
]
b[x]
b[x]表示点
x
x
x属于根节点
p
p
p的哪一棵子树,特别的,令
b
[
p
]
=
p
b[p]=p
b[p]=p。
此时满足题目要求的第1类路径满足以下两个条件的点对 ( x , y ) (x,y) (x,y)的个数:
1. b [ x ] ≠ b [ y ] b[x]\neq b[y] b[x]=b[y]。
2. d [ x ] + d [ y ] ≤ K d[x]+d[y]\leq K d[x]+d[y]≤K。如下图所示。
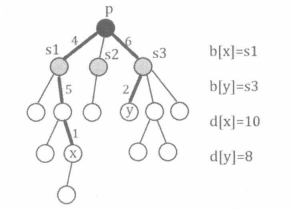
定义 C a l ( p ) Cal(p) Cal(p)表示在以 p p p为根的树中统计上述点对的个数(第1类路径的条数)。 C a l ( p ) Cal(p) Cal(p)有两种常见的实现方式。针对不同的题目,二者各有优劣。
方法一:树上直接统计
设 p p p的子树为 s 1 , s 2 , . . . , s m s_1,s_2,...,s_m s1,s2,...,sm。
对于 s i s_i si中每个节点 x x x,把在子树 s 1 , s 2 , . . . , s i − 1 s_1,s_2,...,s_{i-1} s1,s2,...,si−1中满足 d [ x ] + d [ y ] ≤ K d[x]+d[y]\leq K d[x]+d[y]≤K的节点 y y y的个数累加到答案中即可。
具体来说,可以建立一个树状数组,依次处理每棵子树 s i s_i si。
1.对于 s i s_i si中的每个节点 x x x,查询前缀和 a s k ( K − d [ x ] ) ask(K-d[x]) ask(K−d[x]),即为所求的 y y y的个数。
2.对于 s i s_i si中的每个节点 x x x,执行 a d d ( d [ x ] , 1 ) add(d[x],1) add(d[x],1),表示与 p p p距离为 d [ x ] d[x] d[x]的节点增加了1个。
按子树一棵棵进行处理保证了 b [ x ] ≠ b [ y ] b[x]\neq b[y] b[x]=b[y],查询前缀和保证了 d [ x ] + d [ y ] ≤ K d[x]+d[y]\leq K d[x]+d[y]≤K。
需要注意的是,树状数组的范围与路径长度有关,这个范围远比 N N N要大。而本题中不易进行离散化。一种解决方案是用平衡树代替树状数组,以保证 O ( N l o g N ) O(NlogN) O(NlogN)的复杂度,但代码复杂度显著增加。所以本题更适用下一种方法。
方法二:指针扫描数组
把树中每个点放进一个数组 a a a,并把数组 a a a按照节点的 d d d值排序。
使用两个指针 L , R L,R L,R分别从前、后开始扫描 a a a数组。
容易发现,在指针 L L L从左往右扫描的过程中,恰好使得 d [ a [ L ] ] + d [ a [ R ] ] ≤ K d[a[L]]+d[a[R]]\leq K d[a[L]]+d[a[R]]≤K的指针 R R R的范围是从右往左单调递减的。
另外,我们用数组 c n t [ s ] cnt[s] cnt[s]维护在 L + 1 L+1 L+1与 R R R之间满足 b [ a [ i ] ] = s b[a[i]]=s b[a[i]]=s的位置 i i i的个数。
于是,当路径的一端 x x x等于 a [ L ] a[L] a[L]时,满足题目要求的路径另一端 y y y的个数就是 R − L − c n t [ b [ a [ L ] ] ] R-L-cnt[b[a[L]]] R−L−cnt[b[a[L]]]。
总而言之,整个点分治算法的过程就是:
1.任选一个根节点 p p p(后面我们将说明, p p p应该取树的重心)。
2.从
p
p
p出发进行一次DFS,求出
d
d
d数组和
b
b
b数组。
3.执行 C a l ( p ) Cal(p) Cal(p)。
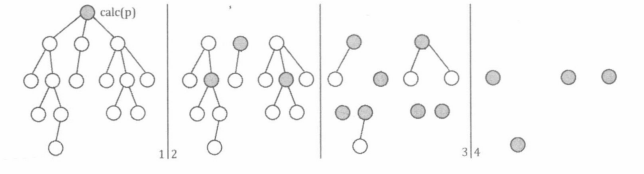
4.删除根节点 p p p,对 p p p的每棵子树(看作无根树)递归执行1~4步。
在点分治过程中,每一层的所有递归过程合计对每个点处理1次。因此,若递归最深处到达第 T T T层,整个算法的时间复杂度为 O ( T N l o g N ) O(TNlogN) O(TNlogN)。
如果问题中的树是一条链,最坏情况下每次都以链的一端为根,那么点分治将需要递归
N
N
N层,时间复杂度退化到
O
(
N
2
l
o
g
N
)
O(N^2logN)
O(N2logN)。为了避免这种情况,我们每次选择树的重心(曾在0x21节提及)作为根节点
p
p
p。对于树上的每一个点,计算其所有子树中最大的子树节点数,这个值最小的点就是这棵树的重心。而不难证明树的重心具有以下性质:以树的重心为根时,所有子树的大小都不超过整棵树大小的一半。
点分治就至多递归 O ( l o g N ) O(logN) O(logN)层,算法的时间复杂度为 O ( N l o g 2 N ) O(Nlog^2N) O(Nlog2N)。如下图所示。
#include <bits/stdc++.h>
using namespace std;
const int SIZE=1e4+5;
int N,K,tot,w,sum,cnt,ans;
int ver[SIZE*2],edge[SIZE*2],nex[SIZE*2],head[SIZE];
int max_part[SIZE],siz[SIZE],dis[SIZE],root[SIZE],rec[SIZE],point[SIZE];
bool del[SIZE];
inline int read()
{
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9')
{
if(ch=='-') f=-1;
ch=getchar();
}
while(ch>='0'&&ch<='9')
x=x*10+ch-'0',ch=getchar();
return x*f;
}
inline void add(int x,int y,int z)
{
ver[++tot]=y,edge[tot]=z;
nex[tot]=head[x],head[x]=tot;
}
void dfs_w(int x,int fa)
{
siz[x]=1,max_part[x]=0;
for(int i=head[x];i;i=nex[i])
{
int y=ver[i];
if(y==fa||del[y]) continue;
dfs_w(y,x);
siz[x]+=siz[y];
max_part[x]=max(max_part[x],siz[y]);
}
max_part[x]=max(max_part[x],sum-siz[x]);
if(max_part[x]<max_part[w])
w=x;
}
void dfs(int x,int fa)
{
point[++cnt]=x,siz[x]=1;
for(int i=head[x];i;i=nex[i])
{
int y=ver[i],z=edge[i];
if(y==fa||del[y]) continue;
if(x==w) root[y]=y;
else root[y]=root[x];
rec[root[y]]++;
dis[y]=dis[x]+z;
dfs(y,x);
siz[x]+=siz[y];
}
}
void solve(int x,int fa)
{
dfs_w(x,fa);
dis[w]=0;
root[w]=w;
rec[w]=1;
for(int i=head[w];i;i=nex[i])
{
int y=ver[i];
rec[y]=0;
}
cnt=0;
dfs(w,0);
sort(point+1,point+cnt+1,[](int x,int y){
return dis[x]<dis[y];
});
int L=1,R=cnt;
rec[root[point[L]]]--;
while(L<R)
{
if(dis[point[L]]+dis[point[R]]>K)
{
rec[root[point[R]]]--;
R--;
}
else
{
ans+=R-L-rec[root[point[L]]];
L++;
rec[root[point[L]]]--;
}
}
del[w]=true;
for(int i=head[w];i;i=nex[i])
{
int y=ver[i];
if(y==fa||del[y]) continue;
sum=siz[y],w=0,max_part[0]=0x3f3f3f3f;
solve(y,w);
}
}
int main()
{
N=read();K=read();
while(N||K)
{
tot=0;
for(int i=1;i<=N;++i) head[i]=0,del[i]=false;
int x,y,z;
for(int i=1;i<N;++i)
{
x=read();y=read();z=read();
x++,y++;
add(x,y,z);
add(y,x,z);
}
ans=0;
sum=N,w=0,max_part[0]=0x3f3f3f3f;
solve(1,0);
printf("%d\n",ans);
N=read();K=read();
}
return 0;
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











