









机器学习(七)——SVM
7.1 SVM概述
支持向量机(Support Vector Machine,简称SVM)是一种经典的机器学习算法,它在解决小样本、非线性及高维模式识别等问题中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
是一种二分类模型,监督性学习。目的是找到集合边缘上的若干数据(支持向量)用这些点找出一个平面(决策面)使支持向量到该平面的距离最大。
7.1.1 预备知识
7.1.1.1 四种分隔的情况
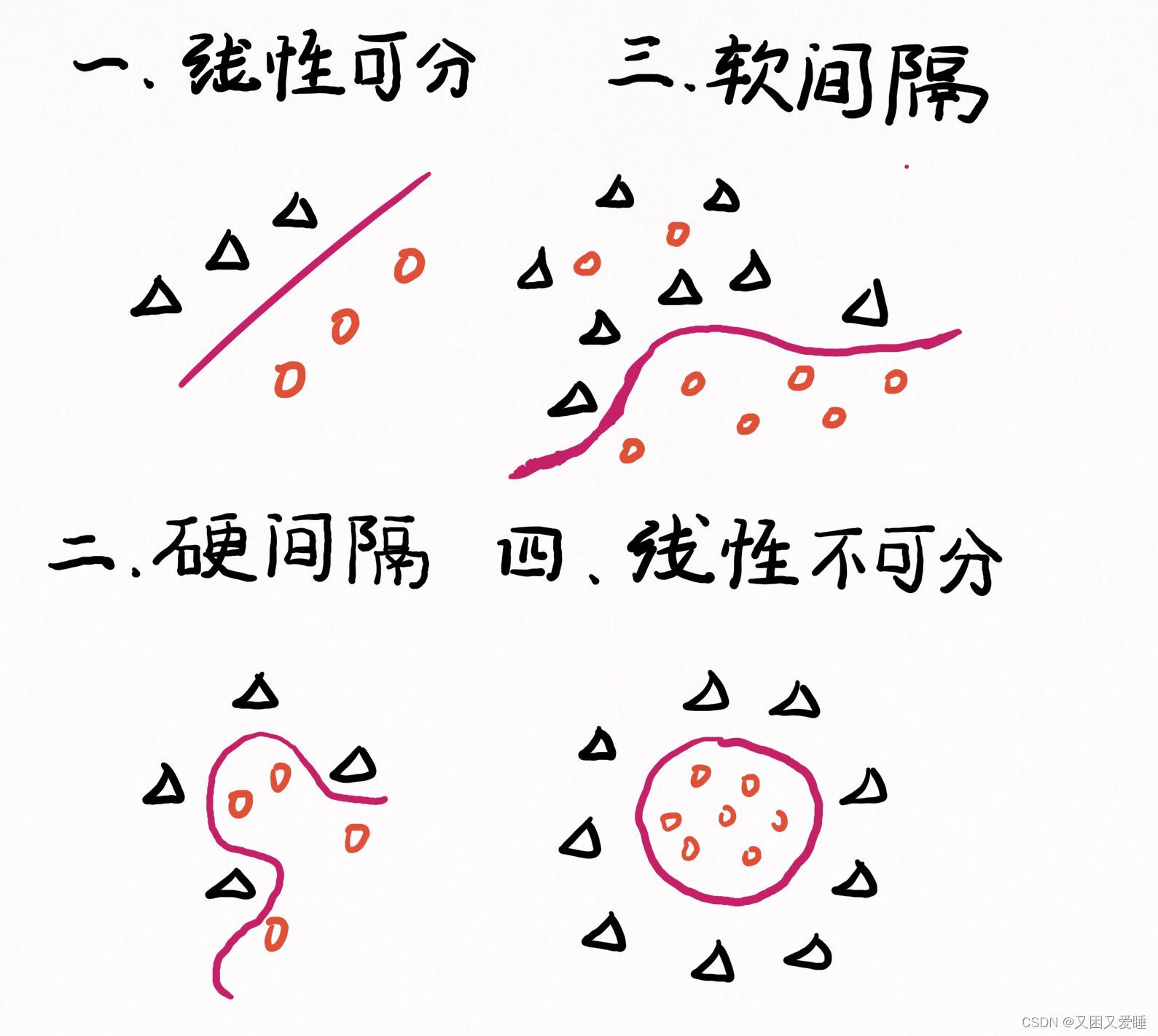
此外,我们将详细介绍一些线性可分的情况
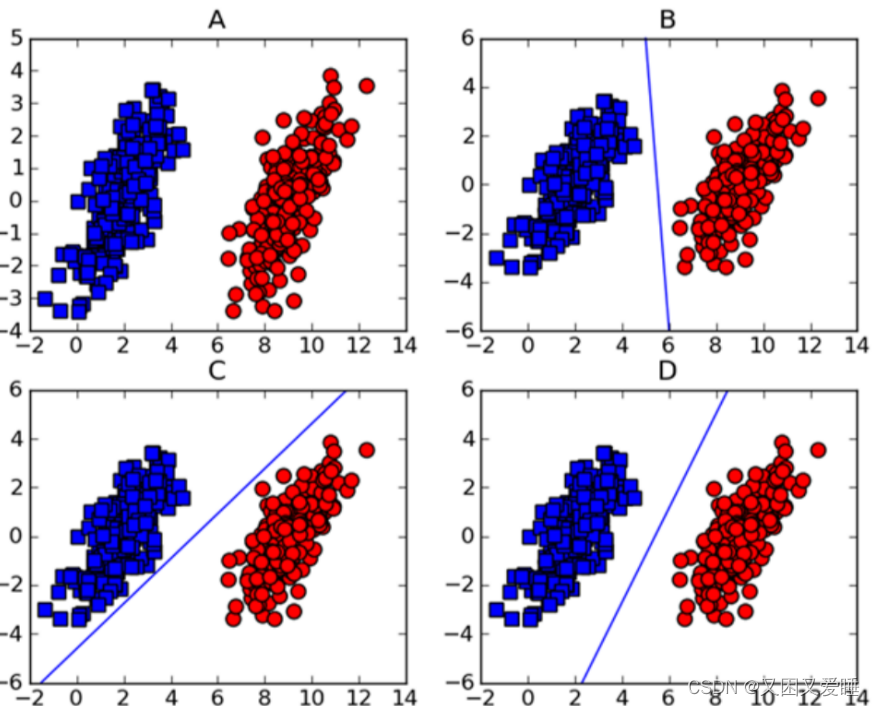
如上图所示,在图A中的两组数据已经分的足够开,因此很容易就可以画一条直线将两组数据点分开。
这种情况下,这组数据就被称为线性可分数据。
将数据集分开的直线称为分割超平面。当数据点都在二维平面上时,分割超平面只是一条直线。当数据集是三维时就是一个平面。如果数据集是N维的,那么就需要N-1维的某某对象对数据进行分割。该对象就被称为超平面也是分类的决策边界。
根据这种方法我们构造一个分类器,如果数据点离决策边界越远,那么其最后的预测结果也就越可信
点到分割线的距离称为间隔
而支持向量就是离分隔超平面最近的那些点。
7.1.1.2 最大间隔与分类
什么样的决策边界才是最好的呢?
首先我们引入
超平面方程:
w
T
x
+
b
=
0
w^{T}x+b= 0
wTx+b=0
对于线性可分的数据集来说,超平面有许多个,但几何间隔最大的分离超平面是唯一的。
① 两类样本分别分割在超平面的两侧
② 两侧距离超平面最近的样本点到超平面的距离被最大化
点
x
=
(
x
1
,
x
2
,
…
…
x
n
)
x=({x_{1},x_{2},…… x_{n})}
x=(x1,x2,……xn)
到直线
w
T
x
+
b
=
0
w^{T}x+b= 0
wTx+b=0
距离为
(
w
T
x
+
b
)
∣
∣
w
∣
∣
\frac{(w^Tx+b)}{||w||}
∣∣w∣∣(wTx+b)
其中 ∣ ∣ w ∣ ∣ = w 1 2 + … … + w n 2 ||w||=\sqrt{w_1^2+……+w_n^2} ∣∣w∣∣=w12+……+wn2
{ ( w T x + b ) ∣ ∣ w ∣ ∣ ≥ d , y = 1 ( w T x + b ) ∣ ∣ w ∣ ∣ ≤ − d , y = − 1 \begin{cases} & \frac{(w^Tx+b)}{||w||}\ge d ,y=1 \\ & \frac{(w^Tx+b)}{||w||} \le -d,y=-1\end{cases} {∣∣w∣∣(wTx+b)≥d,y=1∣∣w∣∣(wTx+b)≤−d,y=−1
支持向量(正、负)之差为
2
∣
∣
w
∣
∣
\frac{2}{||w||}
∣∣w∣∣2
则最大间隔转化为求其最大值
a
r
g
max
w
,
b
2
∣
∣
w
∣
∣
arg\max_{w,b} \frac{2}{||w||}
argw,bmax∣∣w∣∣2
即
a
r
g
min
w
,
b
1
2
∣
∣
w
∣
∣
2
arg\min_{w,b} \frac{1}{2} ||w||^2
argw,bmin21∣∣w∣∣2
7.1.1.3 对偶问题:等式约束
引入拉格朗日函数:
L
(
x
,
λ
)
=
f
(
x
)
+
λ
g
(
x
)
L(x,\lambda )=f(x)+\lambda g(x)
L(x,λ)=f(x)+λg(x)
可将原本约束条件转换为
min
x
,
λ
L
(
x
,
λ
)
\min_{x,\lambda } L(x,\lambda )
x,λminL(x,λ)
分别求偏导得
{
∇
x
L
=
∇
f
+
λ
∇
g
=
0
∇
λ
L
=
g
(
X
)
=
0
\begin{cases} & \nabla_x L=\nabla f+\lambda \nabla g=0 \\ & \nabla_\lambda L =g(X)=0\end{cases}
{∇xL=∇f+λ∇g=0∇λL=g(X)=0
转换为KKT条件
{ ∇ x L = ∇ f + λ ∇ g = 0 g ( x ) ≤ 0 λ ≥ 0 λ g ( x ) = 0 \begin{cases} & \nabla_x L=\nabla f+\lambda \nabla g=0 \\ & g(x)\le 0\\& \lambda \ge 0 \\& \lambda g(x)=0\end{cases} ⎩ ⎨ ⎧∇xL=∇f+λ∇g=0g(x)≤0λ≥0λg(x)=0
通过SMO优化求得最优解
7.1.1.4 核函数
将样本从原始空间映射到一个更高维的特征空间, 使得样本在这个特
征空间内线性可分
例如
a
x
1
2
+
b
x
2
2
+
c
x
1
x
2
=
1
ax_1^2+bx_2^2+cx_1x_2=1
ax12+bx22+cx1x2=1
转化为
w
1
z
1
+
w
2
z
2
+
w
3
z
3
+
b
=
0
w_1z_1+w_2z_2+w_3z_3+b=0
w1z1+w2z2+w3z3+b=0
7.2 实现
7.2.1 数据集介绍
数据来源 openslr官网 主要是饮品的英语发音,有Cappucino、Coffee、Espresso、Hot_Chocolate、Latte、Macchiato、Mocha、Tea.
7.2.2 代码
AudioSignal:
读取音频文件、获取信号属性、绘制时域波形、归一化和预加重
from scipy.io import wavfile
import matplotlib.pyplot as plt
import numpy as np
class AudioSignal:
def __init__(self, path):
self.sample_freq, self.signal = wavfile.read(path)
self.duration = self.signal.shape[0] / float(self.sample_freq)
if (self.signal.ndim == 2):
self.signal = self.signal[:,0]
#print(len(self.signal[self.signal < 0.01]) / len(self.signal))
#self.signal = self.signal[self.signal < 0.01]
@property
def signal(self):
return self._signal
@property
def sample_freq(self):
return self._sample_freq
@property
def duration(self):
return self._duration
@signal.setter
def signal(self, val):
self._signal = val
@sample_freq.setter
def sample_freq(self, val):
self._sample_freq = val
@duration.setter
def duration(self, val):
self._duration = val
def get_info(self):
print('\nSignal Datatype:', self.signal.dtype)
print("Sampling rate: ", self.sample_freq)
print("Shape of the signal: ", self.signal.shape)
print('Signal duration:', round(self.duration, 2), 'seconds\n')
def plot_timedomain_waveform(self):
time = np.linspace(0., self.duration, self.signal.shape[0])
plt.plot(time, self.signal)
plt.legend()
plt.xlabel("Time [s]")
plt.ylabel("Amplitude")
plt.show()
def normalize(self):
self.signal = self.signal / np.max(np.abs(self.signal))
def pre_emphasis(self):
pre_emphasis = 0.97
self.signal = np.append(self.signal[0], self.signal[1:] - pre_emphasis * self.signal[:-1])
MFCCProcessor:
处理音频信号,并计算梅尔频率倒谱系数(MFCC)
import warnings
import numpy as np
from scipy.signal import get_window
from scipy.fftpack import fft
class MFCCProcessor:
def __init__(self, audio_signal):
self.signal = audio_signal
@property
def signal(self):
return self._signal
@property
def frame(self):
return self._frame
@property
def signal_freq(self):
return self._signal_freq
@signal.setter
def signal(self, val):
self._signal = val
@frame.setter
def frame(self, val):
self._frame = val
@signal_freq.setter
def signal_freq(self, val):
self._signal_freq = val
@signal.deleter
def signal(self):
del self._signal
def frame_audio(self, fft_size=2048, hop_size=10, sample_rate=44100):
self.signal = np.pad(self.signal, fft_size // 2, mode="reflect")
frame_len = np.round(sample_rate * hop_size / 1000).astype(int)
frame_num = int((len(self.signal) - fft_size) / frame_len) + 1
self.frames = np.zeros((frame_num, fft_size))
for i in range(frame_num):
self.frames[i] = self.signal[i * frame_len : i * frame_len + fft_size]
def convert_to_frequency(self, fft_size):
window = get_window("hann", fft_size, fftbins=True)
signal_win = self.frames * window
signal_win_T = np.transpose(signal_win)
signal_freq = np.empty((int(1 + fft_size // 2), signal_win_T.shape[1]), dtype=np.complex64, order='F')
for i in range(signal_freq.shape[1]):
signal_freq[:, i] = fft(signal_win_T[:, i], axis=0)[:signal_freq.shape[0]]
self.signal_freq = np.transpose(signal_freq)
def get_filter_points(self, freq_min, freq_max, mel_filter_num,
fft_size, sample_freq=44100):
mel_freq_min = self.freq_to_mel(freq_min)
mel_freq_max = self.freq_to_mel(freq_max)
mels = np.linspace(mel_freq_min, mel_freq_max, num = mel_filter_num+2)
freqs = self.mel_to_freq(mels)
return np.floor((fft_size + 1) / sample_freq * freqs).astype(int), freqs
def get_filters(self, filter_points, fft_size):
filters = np.zeros((len(filter_points) - 2, int(fft_size/2 + 1)))
for i in range(len(filter_points)-2):
filters[i, filter_points[i] : filter_points[i + 1]] = np.linspace(0, 1, filter_points[i + 1] - filter_points[i])
filters[i, filter_points[i + 1] : filter_points[i + 2]] = np.linspace(1, 0, filter_points[i + 2] - filter_points[i + 1])
return filters
def normalize_filters(self, filters, mel_freqs, mel_filter_num):
enorm = 2.0 / (mel_freqs[2:mel_filter_num+2] - mel_freqs[:mel_filter_num])
filters *= enorm[:, np.newaxis]
return filters
def filter_signal(self, filters, sig_power):
warnings.filterwarnings("ignore")
return (10.0 * np.log10(np.dot(filters, np.transpose(sig_power))))
def get_dct_filters(self, filter_num, filter_len): # DCT-III
dct_filters = np.empty((filter_num, filter_len))
dct_filters[0, :] = 1.0 / np.sqrt(filter_len)
samples = np.arange(1, 2 * filter_len, 2) * np.pi / (2.0 * filter_len)
for i in range(1, filter_num):
dct_filters[i, :] = np.cos(i * samples) * np.sqrt(2.0 / filter_len)
return dct_filters
def get_cepstral_coefficients(self, signal_filtered, dct_filters):
return np.dot(dct_filters, signal_filtered)
def calculate_power(self):
return np.square(np.abs(self.signal_freq))
def freq_to_mel(self, freq):
return 2595.0 * np.log10(1.0 + freq / 700.0)
def mel_to_freq(self, mels):
return 700.0 * (10.0**(mels / 2595.0) - 1.0)
SignalProcessorEngine:
继承了MFCCProcessor类,并提供了处理音频信号和计算MFCC
import numpy as np
from sklearn.preprocessing import normalize
from .mfcc_processor import MFCCProcessor
class SignalProcessorEngine:
def __init__(self, fft_size=2048, frame_hop_size=20, mel_filter_num=10, dct_filter_num=40, norm="l2"):
self.params = dict()
self.params["fft_size"] = fft_size
self.params["frame_hop_size"] = frame_hop_size
self.params["mel_filter_num"] = mel_filter_num
self.params["dct_filter_num"] = dct_filter_num
self.params["norm"] = norm
def process(self, audio_signal, sample_freq=44100):
self.mfcc_processor = MFCCProcessor(audio_signal=audio_signal)
self.mfcc_processor.frame_audio(self.params["fft_size"], self.params["frame_hop_size"], sample_freq)
self.mfcc_processor.convert_to_frequency(self.params["fft_size"])
signal_power = self.mfcc_processor.calculate_power()
filter_points, mel_freqs = self.mfcc_processor.get_filter_points(freq_min=0, freq_max=sample_freq/2,
mel_filter_num=self.params["mel_filter_num"],
fft_size=self.params["fft_size"],
sample_freq=sample_freq)
filters = self.mfcc_processor.get_filters(filter_points=filter_points, fft_size=self.params["fft_size"])
filters = self.mfcc_processor.normalize_filters(filters, mel_freqs=mel_freqs, mel_filter_num=self.params["mel_filter_num"])
signal_filtered = self.mfcc_processor.filter_signal(filters=filters, sig_power=signal_power)
dct_filters = self.mfcc_processor.get_dct_filters(filter_num=self.params["dct_filter_num"], filter_len=self.params["mel_filter_num"])
self.cepstral_coefficients = self.mfcc_processor.get_cepstral_coefficients(signal_filtered=signal_filtered, dct_filters=dct_filters)
def get_cepstral_coefficients(self, normalized=True, mfcc_num=40):
self.cepstral_coefficients[np.isnan(self.cepstral_coefficients)] = 0
self.cepstral_coefficients[np.isinf(self.cepstral_coefficients)] = 0
if normalized:
return normalize(self.cepstral_coefficients[:mfcc_num,:], axis=1, norm=self.params["norm"])
else:
return self.cepstral_coefficients[:mfcc_num,:]
pad:
调整MFCC矩阵的列数,使其变为70列。
import numpy as np
import matplotlib.pyplot as plt
def pad(mfcc, max_col=70):
if (mfcc.shape[1] < max_col):
mfcc = np.pad(mfcc, ((0, 0), (0, max_col - mfcc.shape[1])), "mean")
else:
mfcc = mfcc[:,:max_col]
return mfcc
def plot_cepstral_coeffs(audio_signal, sample_rate, cepstral_coefficients):
plt.figure(figsize=(15,5))
plt.plot(np.linspace(0, len(audio_signal) / sample_rate, num=len(audio_signal)), audio_signal)
plt.imshow(cepstral_coefficients, aspect='auto', origin='lower')
plt.show()
训练函数:
import os
import numpy as np
from sklearn import svm
import pickle
from sr.audio_signal import AudioSignal
from sr.signal_processor_engine import SignalProcessorEngine
from util.util import pad
word_list = ["Cappucino", "Coffee", "Espresso", "Hot_Chocolate", "Latte", "Macchiato", "Mocha", "Tea"]
def main():
x_test = []
y_test = []
model = train()
for n, word in enumerate(word_list):
if (word == "Cappucino" or word == "Espresso"): end = 25
else: end = 26
for i in range(20, end):
mfcc = get_coeffs(word, i)
mfcc_padded = pad(mfcc).reshape(-1, )
x_test.append(mfcc_padded)
y_test.append(n)
x_test = np.array(x_test)
y_test = np.array(y_test)
index = np.arange(len(x_test))
np.random.shuffle(index)
x_test = x_test[index]
y_test = y_test[index]
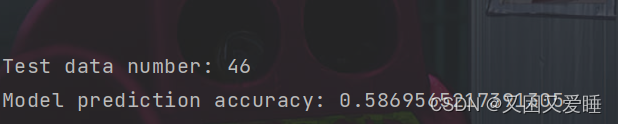
print(f"\n\nTest data number: {x_test.shape[0]}")
print(f"Model prediction accuracy: {model.score(x_test, y_test)}")
filename = os.getcwd() + "/model/svm.sav"
pickle.dump(model, open(filename, "wb"))
def train():
x_train = []
y_train = []
for n, word in enumerate(word_list):
for i in range(1, 20):
mfcc = get_coeffs(word, i)
mfcc_padded = pad(mfcc).reshape(-1, )
x_train.append(mfcc_padded)
y_train.append(n)
x_train = np.array(x_train)
y_train = np.array(y_train)
index = np.arange(len(x_train))
np.random.shuffle(index)
x_train = x_train[index]
y_train = y_train[index]
model = svm.SVC(kernel="poly", C=1, degree=2, tol=0.001, decision_function_shape="ovo")
model.fit(x_train, y_train)
print("-- Training is finished")
return model
def get_coeffs(word, i):
if (i < 10): audio_signal = AudioSignal(os.getcwd() + f"/data/{word}/00{i}.wav")
else: audio_signal = AudioSignal(os.getcwd() + f"/data/{word}/0{i}.wav")
audio_signal.normalize()
engine = SignalProcessorEngine(fft_size=2048 ,frame_hop_size=20, dct_filter_num=40)
engine.process(audio_signal.signal, sample_freq=audio_signal.sample_freq)
mfcc = engine.get_cepstral_coefficients(normalized=True, mfcc_num=10)
return mfcc
if __name__ == "__main__":
main()
预测函数:
import os
import argparse
from scipy import signal
import pickle
from sr.audio_signal import AudioSignal
from sr.signal_processor_engine import SignalProcessorEngine
from util.util import *
word_list = ["Cappucino", "Coffee", "Espresso", "Hot_Chocolate", "Latte", "Macchiato", "Mocha", "Tea"]
def main(path):
model_file = os.getcwd() + "/model/svm.sav"
svm_model = pickle.load(open(model_file, "rb"))
audio_signal = AudioSignal(path)
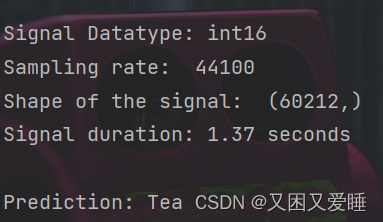
audio_signal.get_info()
audio_signal.normalize()
#audio_signal.plot_timedomain_waveform()
engine = SignalProcessorEngine(fft_size=2048 ,frame_hop_size=20, dct_filter_num=40)
engine.process(audio_signal=audio_signal.signal, sample_freq=audio_signal.sample_freq)
mfcc = engine.get_cepstral_coefficients(normalized=True, mfcc_num=10)
mfcc_padded = pad(mfcc).reshape(1, -1)
#plot_cepstral_coeffs(audio_signal.signal, audio_signal.sample_freq, mfcc)
[res] = svm_model.predict(mfcc_padded)
print(f"Prediction: {word_list[res]}")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--audio_file", "-f", type=str, required=True,
help="Path to the audio (.wav) file to be processed")
args = parser.parse_args()
filepath = os.getcwd() + args.audio_file
main(filepath)
7.2.3 结果
训练结果
随机以数据集中某信息做预测:
测试效果:
7.3 总结
7.3.1 优点
计算复杂性取决于向量数目而不是样本空间维数
可以处理线性不可分
可实现特征空间划分的最优超平面
简化了回归和分类等问题
抓住了关键样本,具有较好鲁棒性,增删非支持向量样本对模型没有影响
7.3.2 缺点
大规模训练难实施
多分类问题解决困难
7.3.3 非线性问题处理
非线性问题可以采用非线性变换将非线性问题变换成线性问题
如:核函数从原始空间映射到更高维的特质空间中,使样本在新的空间中线性可分,之后在新的空间中推导。














 3647
3647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









