






流式计算中的Window机制
1. 概述
1.1 流式计算VS批式计算
数据价值:实时性越高,数据价值越高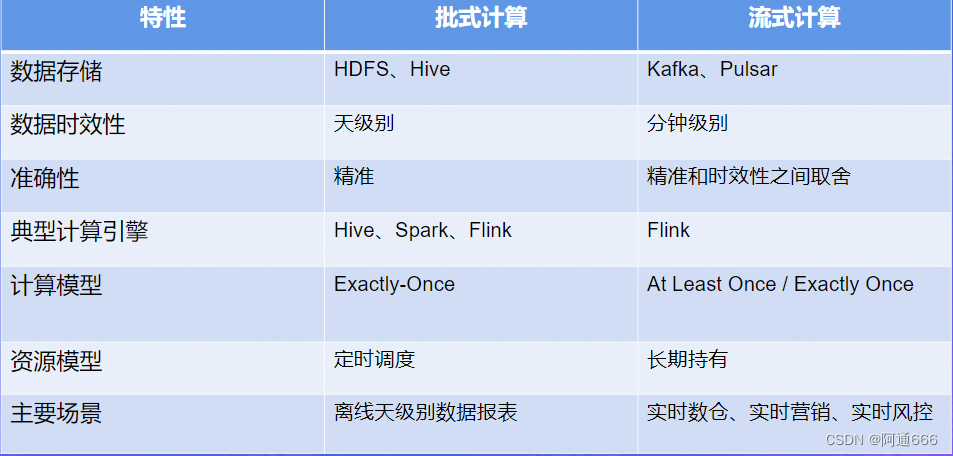
1.2 批处理
批处理模型典型的数仓架构为T+1架构,即数据计算时天级别的,当天只能看到前一天的计算结果。
通常使用的计算引擎为Hive或者Spark等。计算的时候,数据是完全 ready 的,输入和输出都是确定性的。
1.2.1 小时级批处理
将调度级别下降到小时级,每小时一次调度,理论上可以实现更实时的数仓,但是每次周期处理调度外还有申请、释放等过程,比较消耗资源。
一般线上数仓任务,计算时间从几分钟到几小时不等,分布不均匀,数仓的建模是分层的,三层五层甚至七层都存在,若所有的数据从产生到计算完成都要求在一个小时内,在很多场景下是做不到的。
1.2.2 处理时间窗口
实时计算:处理时间窗口
数据实时流动,实时计算,窗口结束直接发送结果,不需要周期调度任务。
1.2.3 处理时间VS事件时间
处理时间:数据在流式计算系统中真正处理时所在机器的当前时间。
事件时间:数据产生的时间,比如客户端、传感器、后端代码等上报数据时的时间。
1.2.4 事件时间窗口
实时计算:事件时间窗口
数据实时进入到真实事件发生的窗口中进行计算,可以有效的处理数据延迟和乱序。
1.2.5 Watermark
在数据中插入一些 watermark,来表示当前的真实时间。
在数据存在乱序的时候,watermark 就比较重要了,它可以用来在乱序容忍和实时性之间做一个平衡。
2. Watermark
2.1 什么是Watermark
表示系统认为的当前真实的事件时间。
2.2 如何产生Watermark
Watermark产生:一般是从数据的事件时间来产生,产生策略可以灵活多样,最常见的包括使用当前事件时间的时间减去一个固定的delay,来表示可以可以容忍多长时间的乱序。
SQL
CREATE TABLE Orders(
user BIGINT,
product STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time-INTERVAL '5' SECOND
) WITH(...);
DataStream
WatermarkStrategy
.<Tuple2<Long,String>>forBoundedoutofOrderness(Duration.ofSeconds(20))
.withTimestampAssigner((event,timestamp)->event.f0);
2.3 如何传递Watermark
Watermark传递:这个类似于上节课中介绍的Checkpoint的制作过程,传递就类似于Checkpoint的barrier,上下游task之间有数据传输关系的,上游就会将watermark传递给下游;下游收到多个上游传递过来的watermark后,默认会取其中最小值来作为自身的watermark,同时它也会将自己watermark传递给它的下游。经过整个传递过程,最终系统中每一个计算单元就都会实时的知道自身当前的watermark是多少。
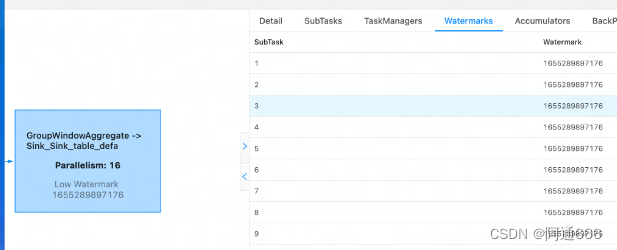
2.4 如何通过Flink UI观察 Watermark
2.5 典型问题
Per-partition VS per-subtask watermark 生成
(1)Per-subtask watermark生成
早期版本都是这种机制。典型的问题是如果一个source subtask 消费多个 partition,那么多个partition 之间的数据读取可能会加剧乱序程度。
(2)Per-partition watermark生成
新版本引入了基于每个partition单独的watermark生成机制,这种机制可以有效避免上面的问题。
部分partition/subtask 断流
根据上面提到的 watermark 传递机制,下游 subtask 会将上游所有 subtask 的 watermark 值的最小值作为自身的 watermark 值。如果上游有一个 subtask 的 watermark 不更新了,则下游的 watermark 都不更新。
解决方案:Idle source
当某个 subtask 断流超过配置的 idle 超时时间时,将当前 subtask 置为 idle,并下发一个 idle 的状态给下游。下游在计算自身 watermark 的时候,可以忽略掉当前是 idle 的那些 subtask。
迟到数据处理
因为watermark表示当前事件发生的真实时间,那晚于watermark的数据到来时,系统会认为这种数据是迟到的数据。
算子自身来决定如何处理迟到数据:
Window聚合,默认会丢弃迟到数据;
双流join,如果是outer join,则可以认为它不能join到任何数据;
CEP,默认丢弃。
3. Window
3.1 基本功能
3.1.1 Window分类
典型的Window:
Tumble Window(滚动窗口)
Sliding Window(滑动窗口)
Session Window(会话窗口)
其它Window:
全局Window
Count Window
累计窗口
…
3.1.2 滚动窗口
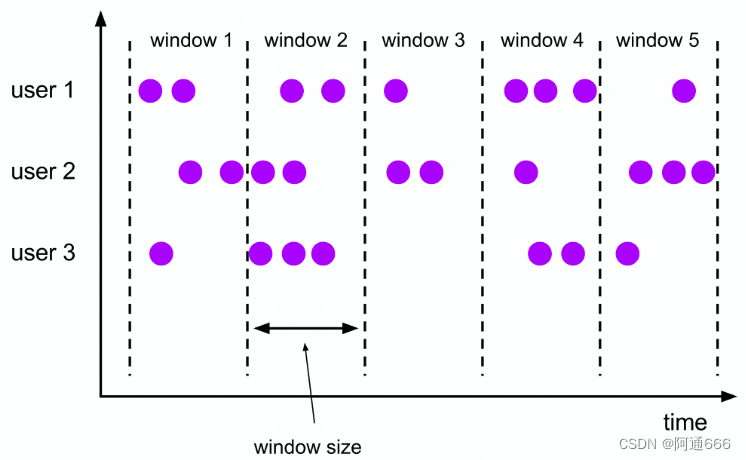
窗口划分:
每个 key 单独划分
每条数据只会属于一个窗口
窗口触发:
Window 结束时间到达的时候一次性触发
3.1.3 滑动窗口
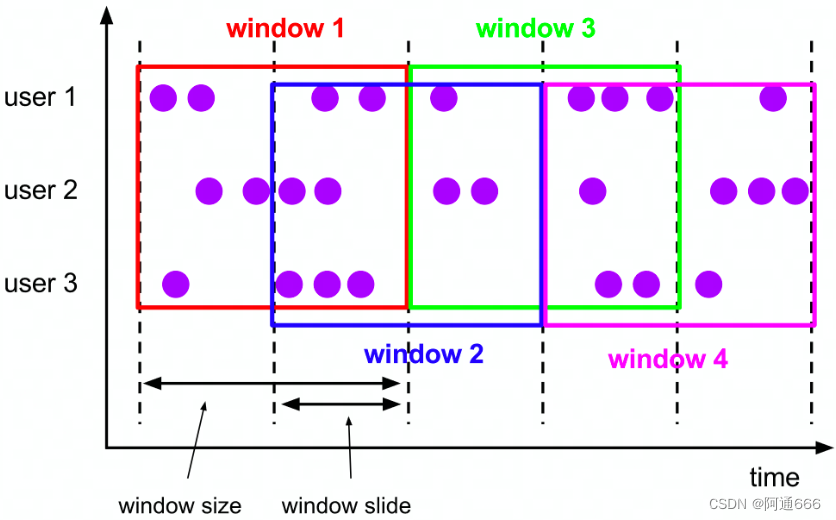
窗口划分:
每个 key 单独划分
每条数据可能会属于多个窗口
窗口触发:
Window 结束时间到达的时候一次性触发
3.1.4 会话窗口
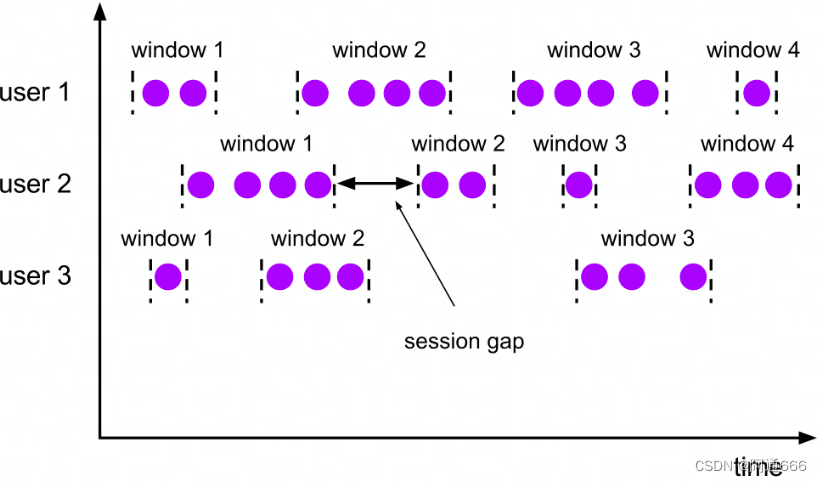
窗口划分:
每个key单独划分
每条数据会单独划分为一个窗口,如果window之间有交集,则会对窗口进行merge
窗口触发:
Window结束时间到达的时候一次性触发
3.1.5 迟到数据的处理
怎么定义迟到?
一条数据到来后,会用WindowAssigner 给它划分一个 window,一般时间窗口是一个时间区间,比如[10:00,11:00),如果划分出来的 window end 比当前的 watermark 值还小,说明这个窗口已经触发了计算了,这条数据会被认为是迟到数据。
什么情况下会产生迟到数据?
只有事件时间下才会有迟到的数据。
迟到数据默认处理?
丢弃
Allow lateness
这种方式需要设置一个允许迟到的时间。设置之后,窗口正常计算结束后,不会马上清理状态,而是会多保留 allowLateness 这么长时间,在这段时间内如果还有数据到来,则继续之前的状态进行计算。
适用于:DataStream、SQL
SideOutput(侧输出流)
这种方式需要对迟到数据打一个 tag,然后在 DataStream 上根据这个 tag 获取到迟到数据流,然后业务层面自行选择进行处理。
适用于:DataStream
3.1.6 增量VS全量计算
增量计算:
每条数据到来,直接进行计算,window只存储计算结果。
比如计算sum,状态中只需要存储sum的结果,不需要保存每条数据。
典型的reduce、aggregate等函数都是增量计算
SQL中的聚合只有增量计算
全量计算:
每条数据到来,会存储到window的state中。等到window触发计算的时候,将所有数据拿出来一起计算。
典型的process函数就是全量计算
3.1.7 EMIT 触发
什么叫EMIT?
通常来讲,Window 都是在结束的时候才能输出结果,比如 1h 的 tumble window,只有在 1 个小时结束的时候才能统一输出结果。
如果窗口比较大,比如 1h 或者 1 天,甚至于更大的话,那计算结果输出的延迟就比较高,失去了实时计算的意义。
EMIT 输出指的是,在 window 没有结束的时候,提前把 window 计算的部分结果输出出来。
怎么实现?
在DataStream里面可以通过自定义Trigger来实现,Trigger的结果可以是:
(1) CONTINUE
(2) FIRE(触发计算,但是不清理)
(3)PURGE
(4)FIRE_AND_PURGE
SQL也可以使用,通过配置:
(1)table.exec.emit.early-fire.enabled=true
(2)table.exec.emit.early-fire.delay=(time)
3.2 高级优化
3.2.1 Mini-batch 优化
Mini-batch优化解决频繁访问状态的问题
一般来讲,Flink的状态比较大一些都推荐使用rocksdb statebackend,这种情况下,每次的状态访问就都需要做一次序列化和反序列化,这种开销还是挺大的。为了降低这种开销,我们可以通过降低状态访问频率的方式来解决,这就是mini-batch最主要解决的问题:即赞一小批数据再进行计算,这批数据每个key的state访问只有一次,这样在单个key的数据比较集中的情况下,对于状态访问可以有效的降低频率,最终提升性能。
这个优化主要是适用于没有窗口的聚合场景,字节内部也扩展了window来支持mini-batch,在某些场景下的测试结果可以节省20-30%的CPU开销。
mini-batch看似简单,实际上设计非常巧妙。假设用最简单的方式实现,那就是每个算子内部自己进行攒一个小的batch,这样的话,如果上下游串联的算子比较多,任务整体的延迟就不是很容易控制。所以真正的mini-batch实现,是复用了底层的watermark传输机制,通过watermark事件来作为mini-batch划分的依据,这样整个任务中不管串联的多少个算子,整个任务的延迟都是一样的,就是用户配置的delay时间。
3.2.2倾斜优化-local-global
local-global 优化解决倾斜问题
local-global优化是分布式系统中典型的优化,主要是可以降低数据shuffle的量,同时也可以缓解数据的倾斜。
所谓的local-global,就是将原本的聚合划分成两阶段,第一阶段先做一个local的聚合,这个阶段不需要数据shuffle,是直接跟在上游算子之后进行处理的;第二个阶段是要对第一个阶段的结果做一个merge(还记得上面说的session window的merge么,这里要求是一样的。如果存在没有实现merge的聚合函数,那么这个优化就不会生效)。
3.2.3 Distinct 计算状态复用
Distinct 状态复用降低状态量
对于distinct的优化,一般批里面的引擎都是通过把它优化成aggregate的方式来处理,但是在流式window中,我们不能直接这样进行优化,要不然算子就变成会下发retract的数据了。所以在流式中,对于count distinct这种情况,我们是需要保存所有数据是否出现过这样子的一个映射。
3.2.4 Pane 优化
Pane 优化降低滑动窗口的状态存储量
滑动窗口如上面所述,一条数据可能会属于多个window。所以这种情况下同一个key下的window数量可能会比较多,比如3个小时的窗口,1小时的滑动的话,每条数据到来会直接对着3个窗口进行计算和更新。这样对于状态访问频率是比较高的,而且计算量也会增加很多。
优化方法就是,将窗口的状态划分成更小粒度的pane,比如上面3小时窗口、1小时滑动的情况,可以把pane设置为1h,这样每来一条数据,我们就只更新这条数据对应的pane的结果就可以了。当窗口需要输出结果的时候,只需要将这个窗口对应的pane的结果merge起来就可以了。















 642
642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









