






一、导包erer
1、打开idear创建一个项目(JDK选择自己下载的已有的)
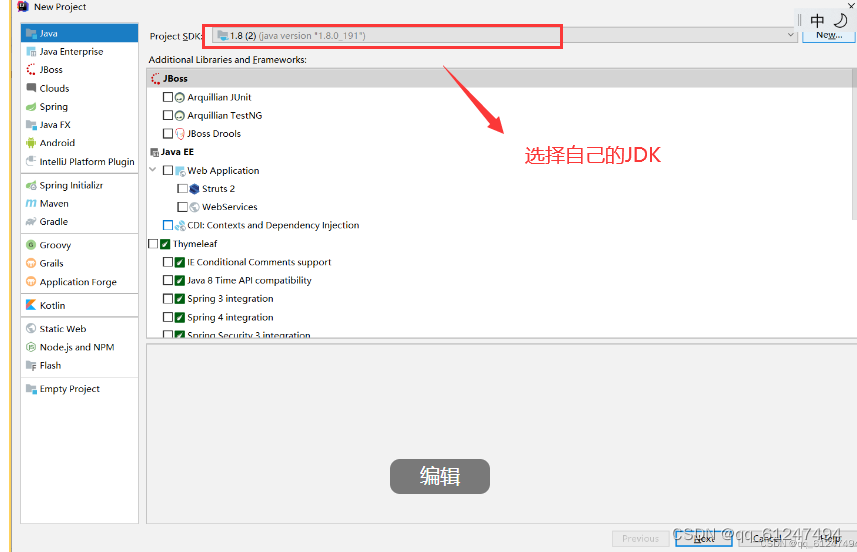
2、创建好项目以后可以看见自己JDK的jar包已经存在
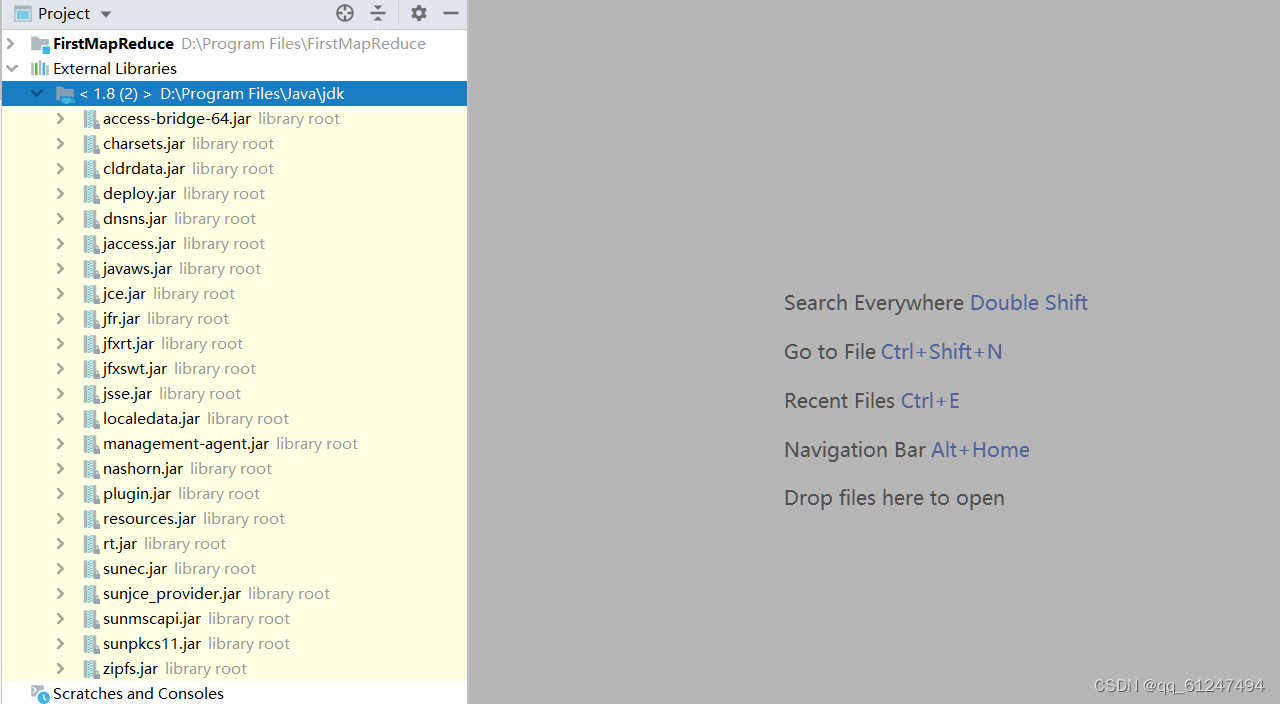
3、点击File->Project Structure...
4、点击modules->Dependencies->+加入jar包

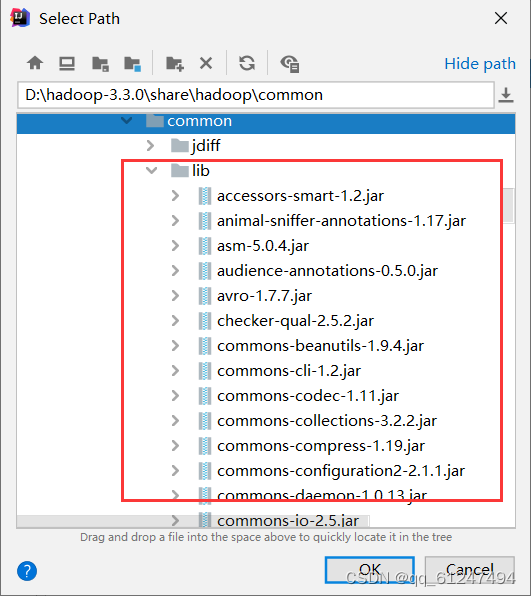
5、解压hadoop的压缩包,下载链接hadoop 提取码:6s5a,找到hadoop-common-3.3.0.jar(路径hadoop-3.3.0\share\hadoop\common)点击OK

6、lib下的jar包全部选中
7、hdfs下hadoop-hdfs-3.3.0.jar也选中
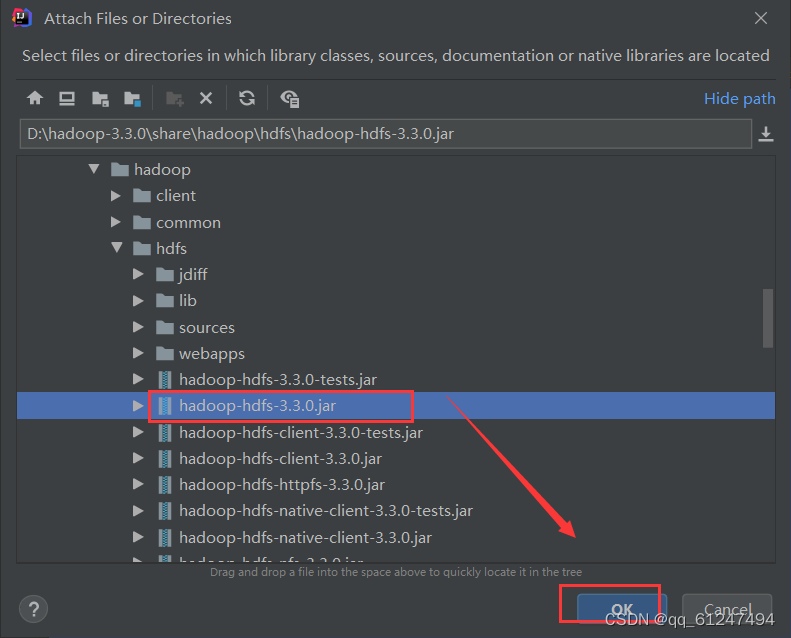
8、mapreducr下的jar包全部选中

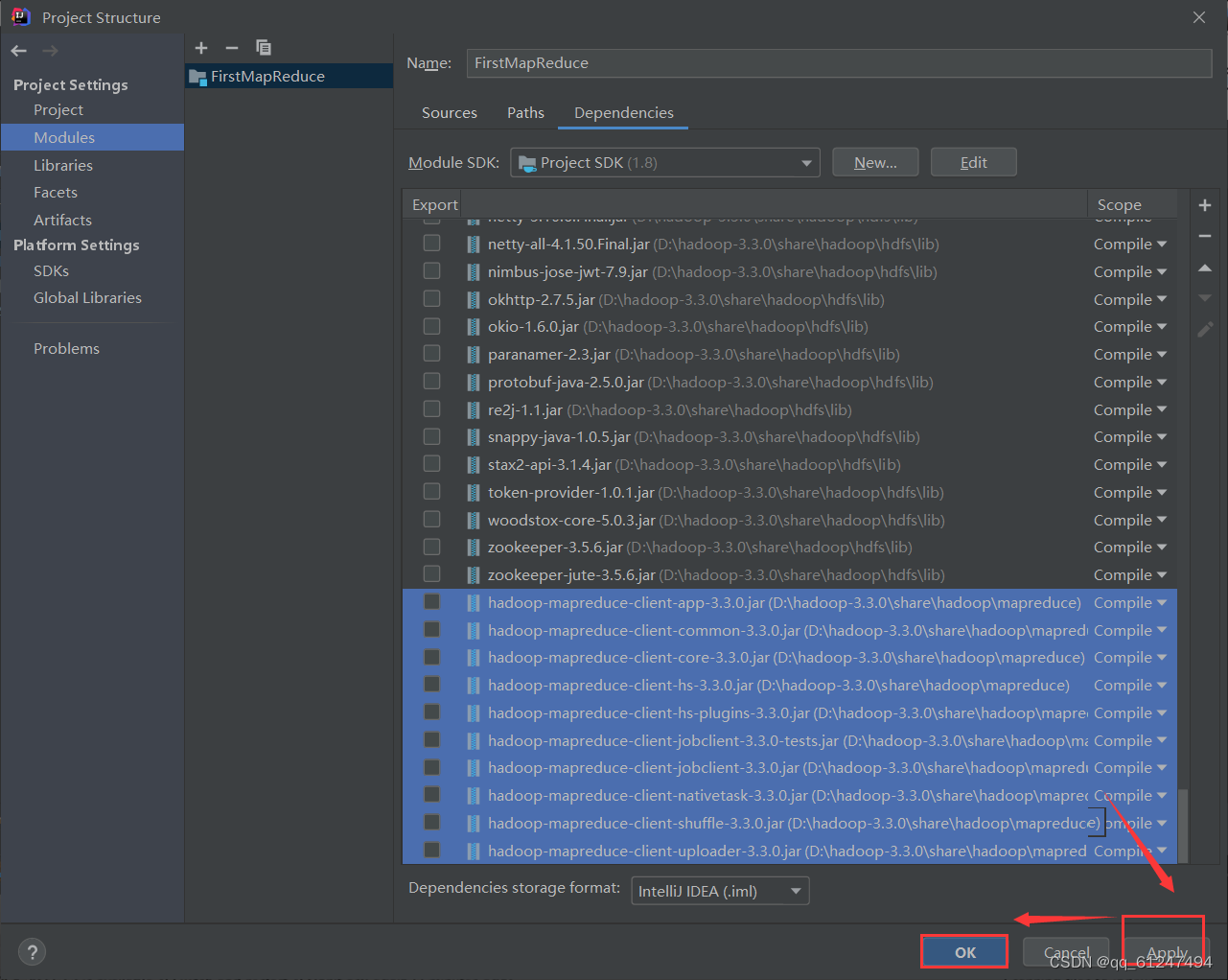
9、最后点击Apply点击ok确定导入
二、代码
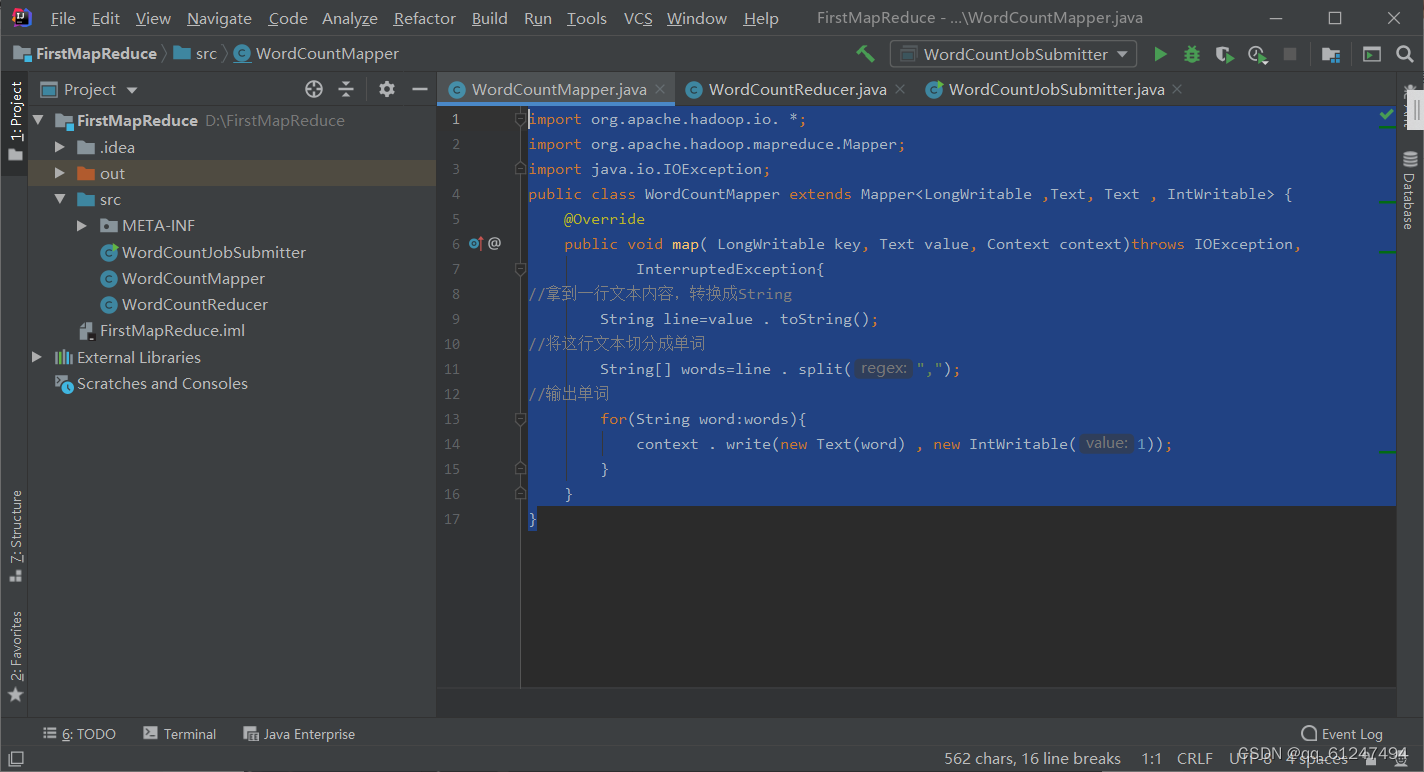
1、创建一个名为Mapper的类写入以下内容
import org.apache.hadoop.io. *;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable ,Text, Text , IntWritable> {
@Override
public void map( LongWritable key, Text value, Context context)throws IOException,
InterruptedException{
//拿到一行文本内容,转换成String
String line=value . toString();
//将这行文本切分成单词
String[] words=line . split(",");
//输出单词
for(String word:words){
context . write(new Text(word) , new IntWritable(1));
}
}
}
2、WordCountReducer内容
import org .apache . hadoop.io.*;
import org .apache . hadoop . mapreduce . Reducer;
import java . io. IOException;
public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException,
InterruptedException {
//定义一个计数器
int count = 0;
for (IntWritable value : values) {
count += value.get();
}
context.write(key, new IntWritable(count));
}
}3、WordCountJobSubmitter
import org. apache . hadoop. conf . Configuration;
import org. apache . hadoop. fs.Path;
import org. apache . hadoop . io .IntWritable;
import org .apache.hadoop.io. Text;
import org. apache . hadoop . mapreduce . Job;
import org. apache . hadoop . mapreduce. lib. input . FileInputFormat;
import org .apache.hadoop.mapreduce.lib. output.FileOutputFormat ;
import java. io. IOException;
public class WordCountJobSubmitter {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job wordCountJob = Job.getInstance(conf);
//指定本job所在的jar包
wordCountJob.setJarByClass(WordCountJobSubmitter.class);
//设置wordCountJob所在的mapper逻辑为哪个类
wordCountJob.setMapperClass(WordCountMapper.class);
//设置wordCountJob所用的reducer逻辑类为哪个类
wordCountJob.setReducerClass(WordCountReducer.class);
//设置map阶段输出的KV数据类型
wordCountJob.setMapOutputKeyClass(Text.class);
wordCountJob.setMapOutputValueClass(IntWritable.class);
//设置最终的KV数据类型
wordCountJob.setOutputKeyClass(Text.class);
wordCountJob.setMapOutputValueClass(IntWritable.class);
//设置要处理的文本数据所存放的路径
FileInputFormat.setInputPaths(wordCountJob, "hdfs://192.168.43.26:9000/mapreduce/mydata02");
FileOutputFormat.setOutputPath(wordCountJob, new Path("hdfs://192.168.43.26:9000/mapreduce/output/"));
wordCountJob.waitForCompletion(true);
}
}三、打jar包
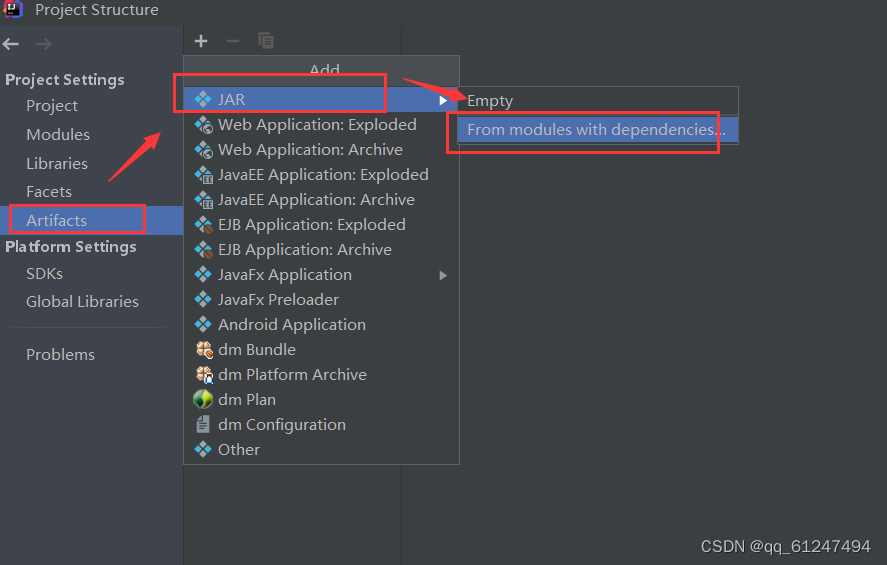
1、点击Artifacts->JAR->选择第二项
2、加入main class
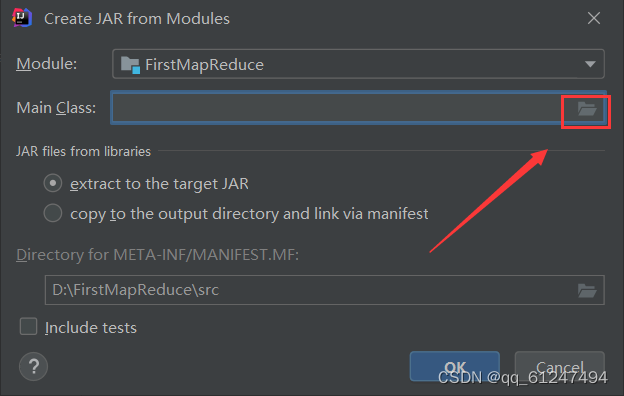

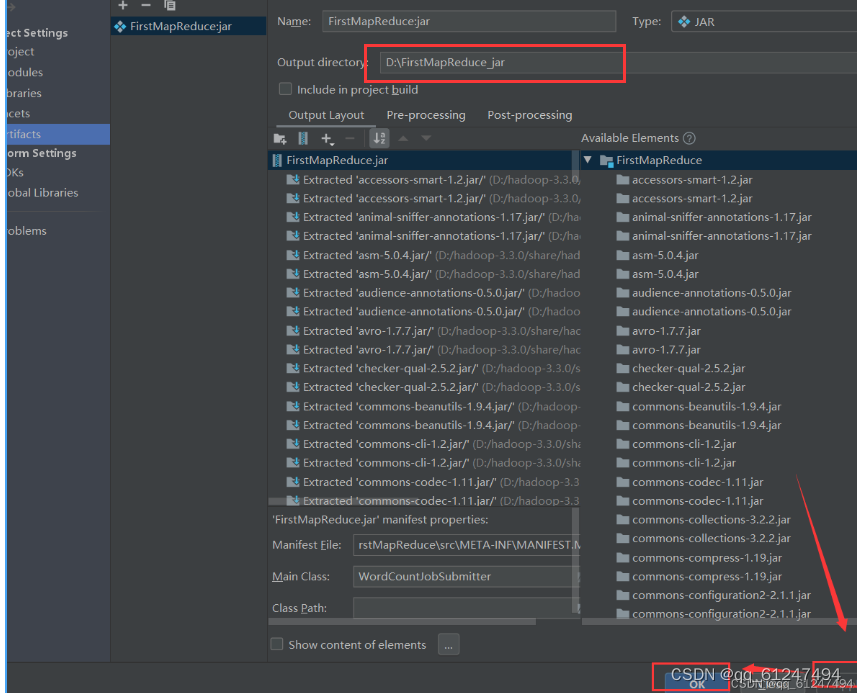
3、点击选择jar包的生成路径,点击Apply之后点击ok
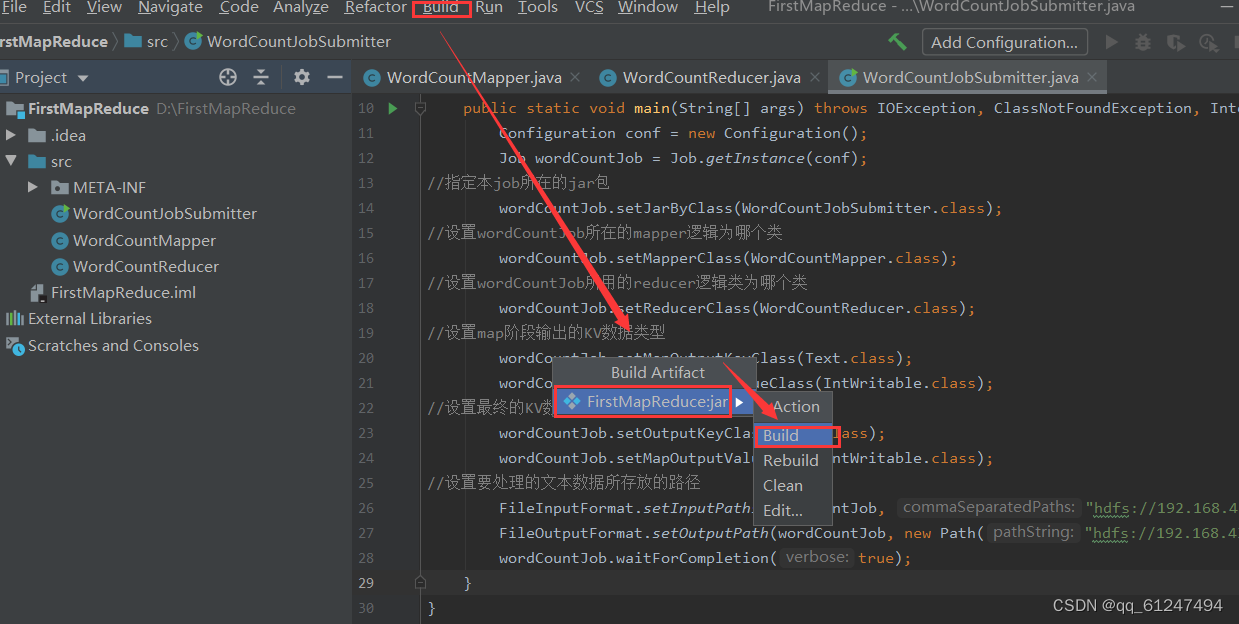
4、点击Build生成jar包
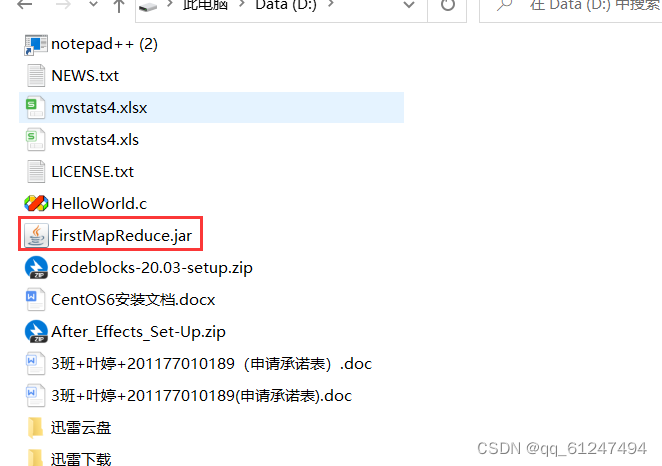
5、此时就会生成一个jar包
6、将生成的jar包传输到虚拟机上,在虚拟机上创建一个mydata02文件(里面输入一些单词)再启动Hadoop全分布集群后将本地文件mydata02上传到集群
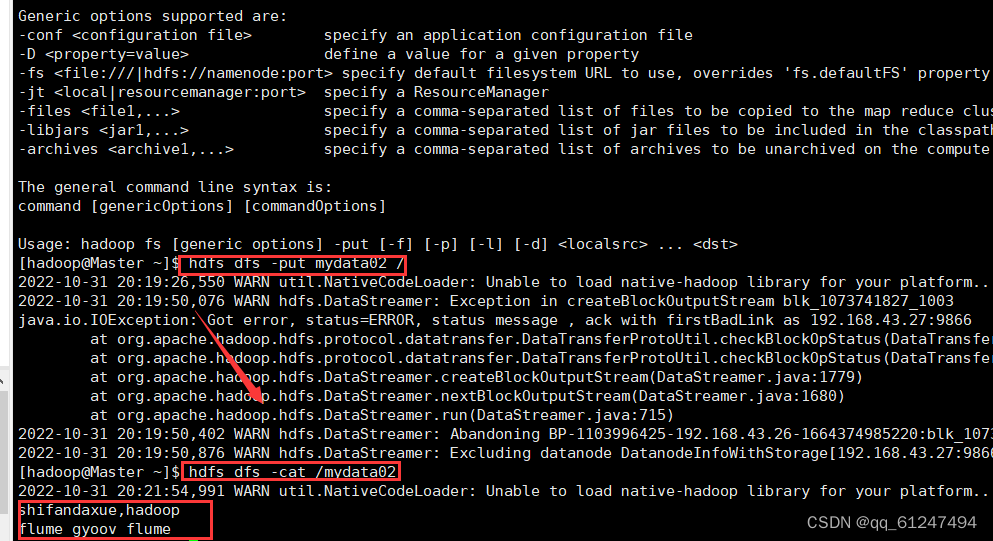
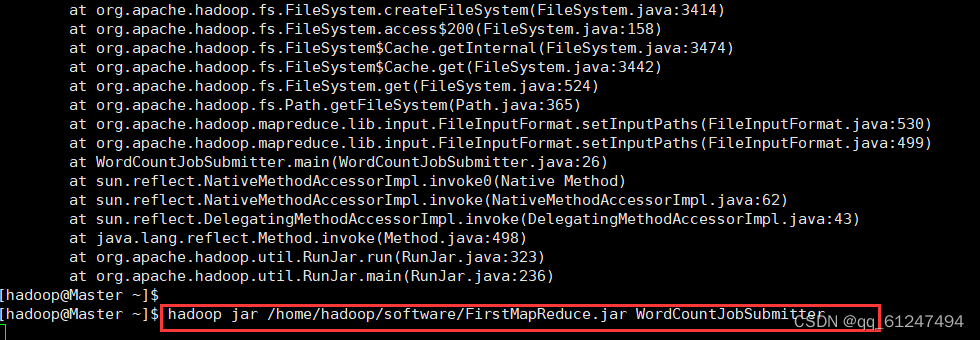
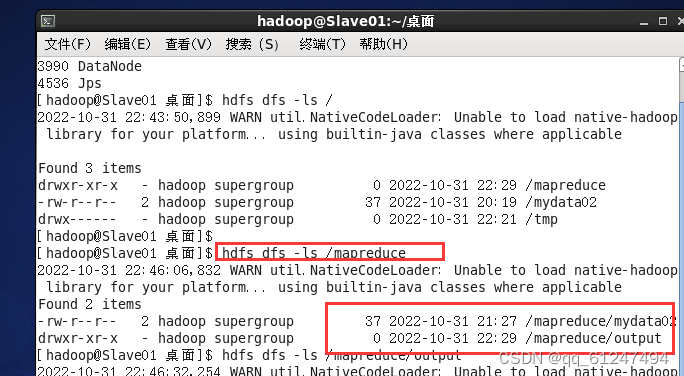
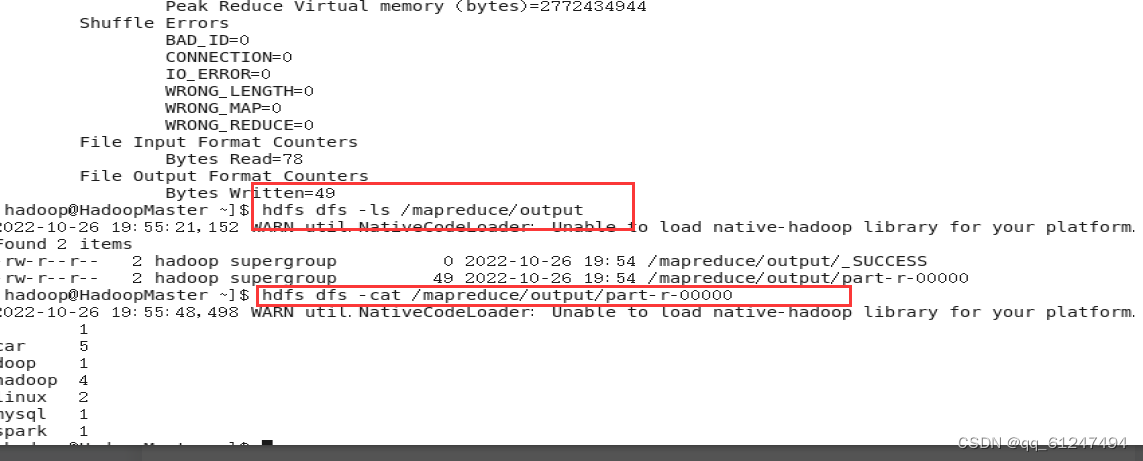
三、运行结果















 630
630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











