







实验:开发MapReduce算法,实现统计分析(单词统计,或者关键词统计)。
一、前期准备:
1>环境准备:安装jdk
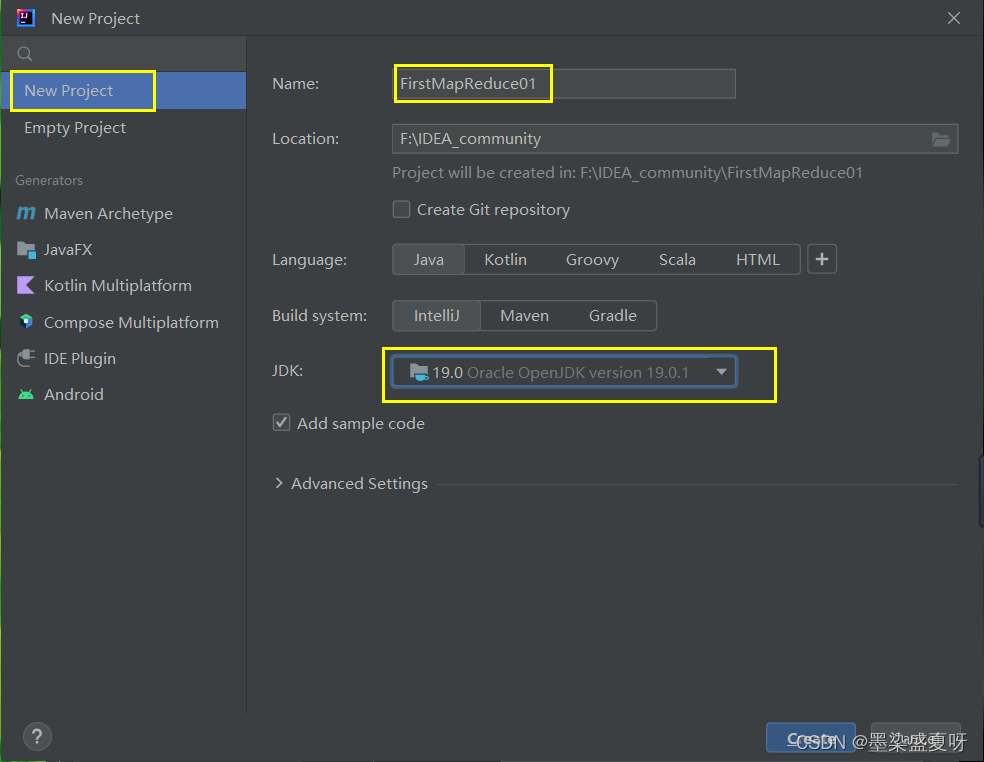
2>创建项目
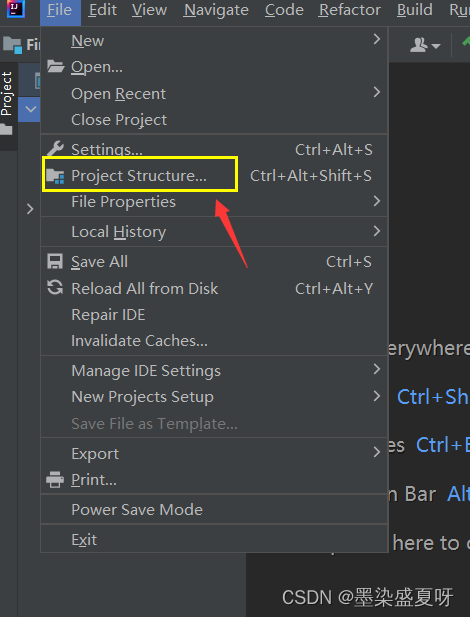
3>导包
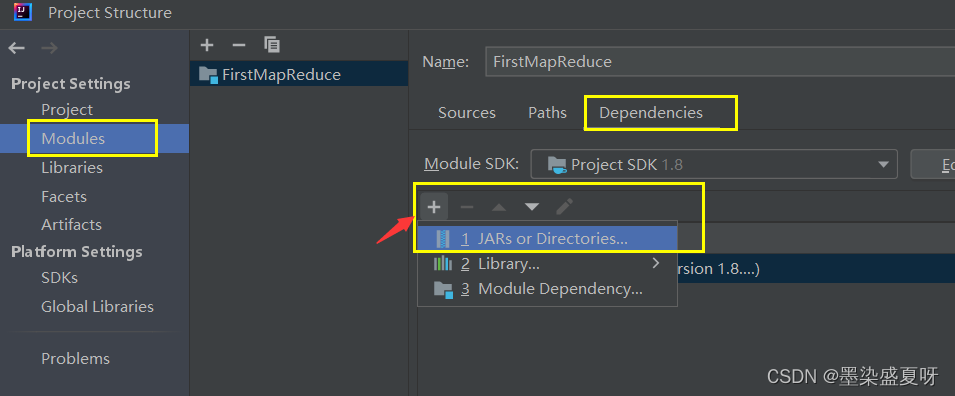
导入如下的包:

点击apply,然后OK即可。
二、开发过程:
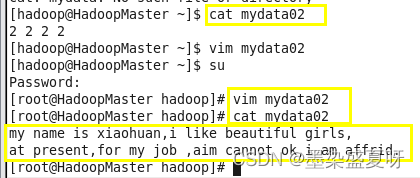
1>在虚拟机里编辑数据,如:
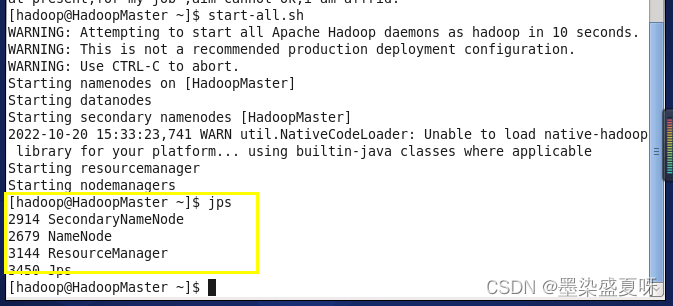
2>将集群启动一下:,start-all.sh。
三、在idea里编写代码:
1>编写WordCountMapper
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
@Override
public void map(LongWritable key,Text value,Context context)throws IOException, InterruptedException{
// 拿到一行文本内容,转换成
String String line=value.toString();
// 将这行文本切分成单词
String[] words=line.split(",");
// 输出单词
for(String word:words){
context.write(new Text(word),new IntWritable(1));
}
}
}2>编写WordCountReducer
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException,
InterruptedException {
// 定义一个计数器
int count = 0;
for (IntWritable value : values) {
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
3>编写WordCountJobSubmitteritable
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountJobSubmitter {
public static void main(String[] args) throws IOException,ClassNotFoundException,InterruptedException{
Configuration conf =new Configuration();
Job wordCountJob=Job.getInstance(conf);
// 指定本job所在的jar包
wordCountJob.setJarByClass(WordCountJobSubmitter.class);
// 设置wordCountJob所在的mapper逻辑为哪个类
wordCountJob.setMapperClass(WordCountMapper.class);
// 设置wordCountJob所用的reducer逻辑类为哪个类
wordCountJob.setReducerClass(WordCountReducer.class);
// 设置map阶段输出的KV数据类型
wordCountJob.setMapOutputKeyClass(Text.class);
wordCountJob.setMapOutputValueClass(IntWritable.class);
// 设置最终的KV数据类型
wordCountJob.setOutputKeyClass(Text.class);
wordCountJob.setMapOutputValueClass(IntWritable.class);
// 设置要处理的文本数据所存放的路径
FileInputFormat.setInputPaths(wordCountJob,"hdfs://192.168.43.50:9000/mapreduce/mydata02");
FileOutputFormat.setOutputPath(wordCountJob,newPath("hdfs://192.168.43.50:9000/mapreduce/output/"));
wordCountJob.waitForCompletion(true);
}
}
4>将其jar包建立并上传到虚拟机中:
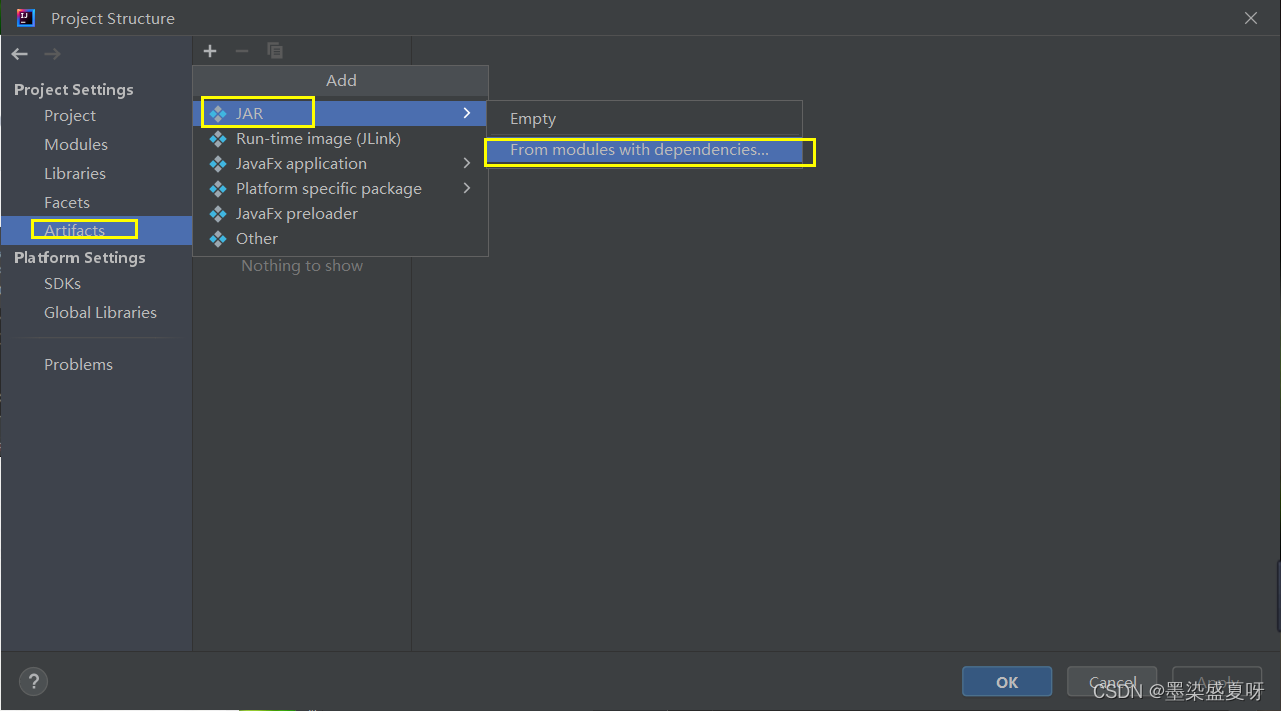
选择第二个:
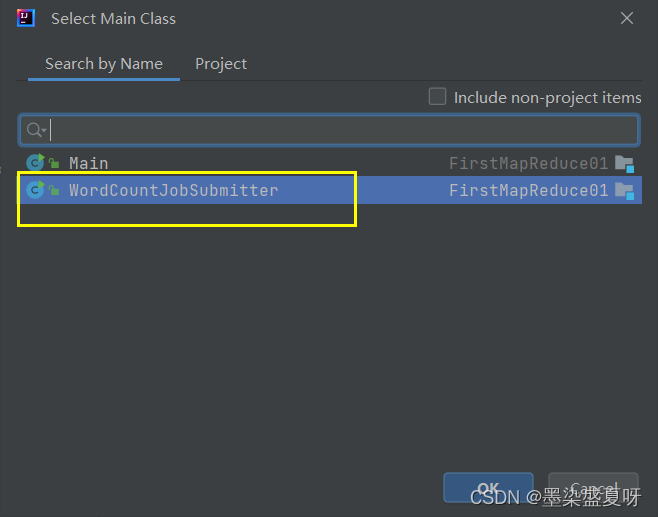
打jar包(导完后,要在其中build):
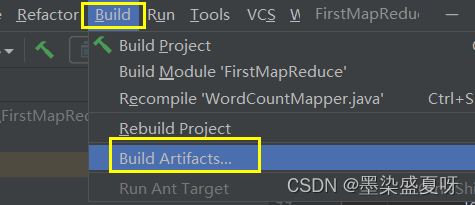
在本地文件夹中查看jar包:
上传到虚拟机中:
四、hadoop fs -ls /:查看是否有mapreduce
若没有,就创建一个:hadoop fs -mkdir /mapreduce
(在这里遇到了一个问题:
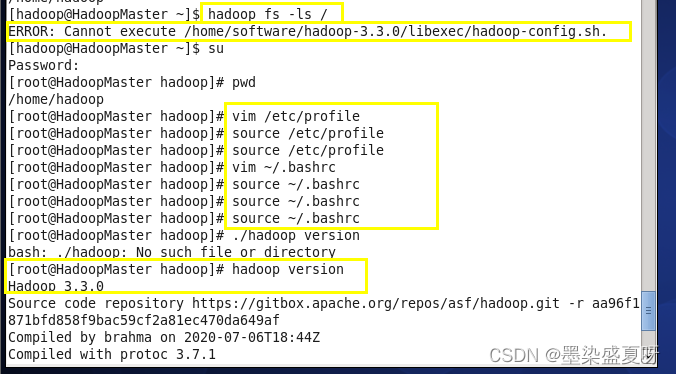
解决方法:在/etc/profile中找到了这个HADOOP_HOME全局变量,将其删除
运行source /etc/profile
在~/.bashrc最后一行输入unset HADOOP_HOME
source ~/.bashrc即可(这样就不用一开机就要输入unset HADOOP_HOME了)
原文链接:如何解决Cannot execute /home/hadoop/hadoop/libexec/hadoop-config.sh._北朽暖栀24的博客-CSDN博客
解决后,可以查看到:

五、将数据上传至MapReduce
1>在虚拟机上创建MapReduce。
创建:hadoop fs -mkdir /mapreduce
2>上传:hadoop fs -put mydata02 /mapreduce
查看mydata02内容:hdfs dfs -cat /mapreduce/mydata02

3>将jar包传至虚拟机中
4>输入:hadoop jar /home/hadoop/software/FirstMapReduce.jar WordCountJobSubmitter
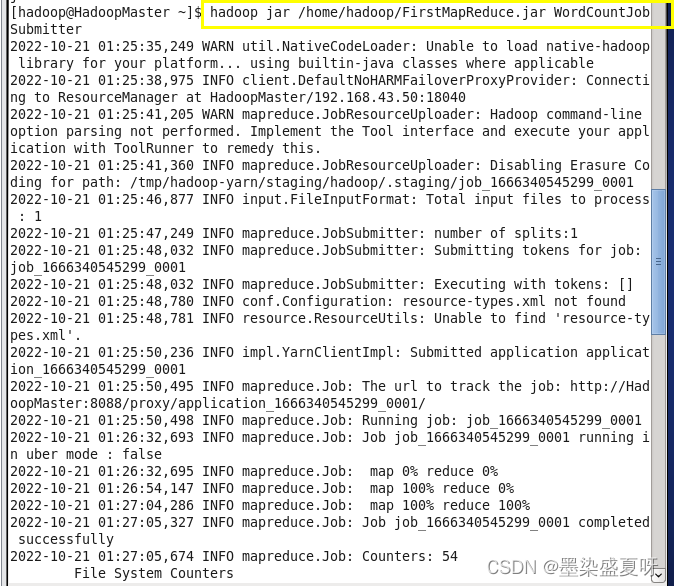
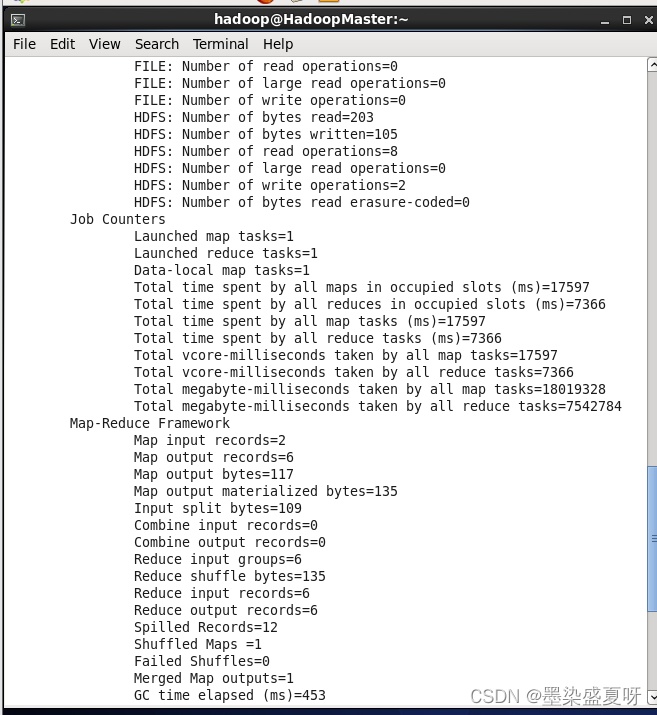
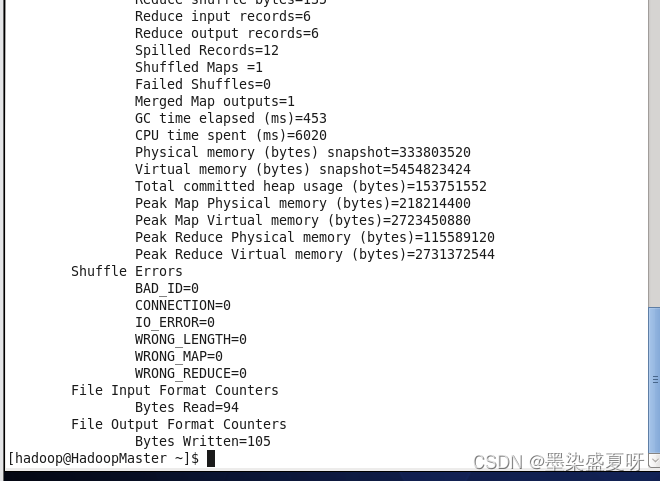
5>查看运行结果:
hadoop fs -ls /mapreduce/output
hadoop fs -cat /mapreduce/output/part-r-00000
//具体操作如下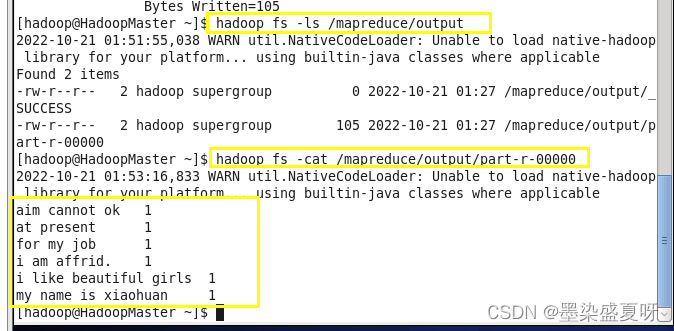 结束&&
结束&&
















 2679
2679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











