






AI大语言模型原理
AI大语言模型的理论基础是机器学习,即通过数据训练,调整人工神经网络的连接参数,从而提升输出结果的正确概率。人工神经网络模拟了人脑对信息的多级抽象处理,可以将其用于多种任务,例如自然语言处理(NLP)。自然语言是上下文有关文法(与之相对的,程序语言是上下文无关文法),传统自然语言处理采用的人工神经网络主要是卷积神经网络(RNN)或长短期记忆网络(LSTM),二者均无法并行计算,训练效率低,并且不擅长处理长序列文本,难以联系上下文。
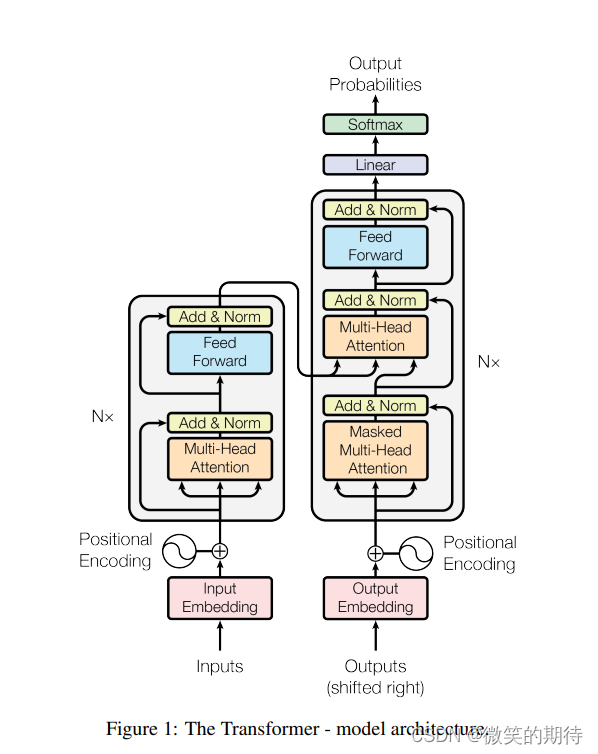
AI大语言模型采用了Transformer架构,如下图所示[1]。在前馈神经网络的基础上引入位置向量编码(Positional Encoding)与自注意力机制(Self-Attention),位置向量编码使得AI能够获取每个词(token)的位置信息,使得并行训练成为可能;自注意力机制使得AI在处理每个词时,不仅会注意每个词本身,还会注意输入序列中的所有其他词,使得AI可以联系上下文。
AI大语言模型之所以谓之“大”,是指模型的参数量大,例如GPT-3的参数有1750亿个[2]。通过大量的数据与大量的算力训练出具有大量参数的模型(期间采用了多种训练方法,包括无监督学习,监督学习,强化学习),从而获得了”涌现能力“(Emergent abilities)[3]。
AI大语言模型的局限性
AI大语言模型将出现概率最大的下一个词作为输出结果,使它更像是一个“平均人“,而非作为一个拥有自我特色的人类个体,即便它这个“平均人”可以根据AI提示词(Prompt)[4]获得某种偏向,但也是拥有这种偏向的人的平均。
通过概率生成与通过逻辑推理生成有着本质区别,打个比方,让AI大语言模型去做数学题,它不是算出来的,而是“猜”出来的,这种“猜”更像是人类没有经过思考的经验直觉,是无法理解的“黑箱”。当然这是有解决办法的,如果能将以符号主义为核心的逻辑推理与数据驱动为核心的机器学习相结合,可能会有意想不到的效果。同理也可以将以问题求解为核心的探寻搜索结合进来,用以解决AI训练的数据不足或过时的问题,事实上目前这些方向已经取得一定进展,如思维链(Chain-of-thought)[5],程序辅助语言模型(PAL)[6],增强检索生成模型(RAG)[7],协同推理与行动模型(ReAct)[8]等。
通过概率生成意味着需要通过大量的数据训练获得概率,这个过程会消耗大量的数据与算力,据估计高质量文本在2026年就会枯竭[9],与之相比人脑所消耗的数据与算力几乎可以忽略不计,也就是说,AI大语言模型通过更多数据更多算力获得更好的生成结果的发展方向是不可持续的,并且也与人脑的作用机理相悖。结构决定功能,AI大语言模型的真正发展方向应该是去模拟人脑,现在的人工神经网络对人脑的模拟相当粗糙,人工智能要逼近人脑功能,就要从结构、规模和信号加工机理上进一步逼近人类大脑[10]。
参考文献[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[2] Brown T, Mann B, Ryder N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901.
[3] Wei J, Tay Y, Bommasani R, et al. Emergent abilities of large language models[J]. arxiv preprint arxiv:2206.07682, 2022.
[4]Liu P, Yuan W, Fu J, et al. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing[J]. ACM Computing Surveys, 2023, 55(9): 1-35.
[5]Wei J, Wang X, Schuurmans D, et al. Chain-of-thought prompting elicits reasoning in large language models[J]. Advances in neural information processing systems, 2022, 35: 24824-24837.
[6]Gao L, Madaan A, Zhou S, et al. Pal: Program-aided language models[C]//International Conference on Machine Learning. PMLR, 2023: 10764-10799.
[7]Lewis P, Perez E, Piktus A, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks[J]. Advances in Neural Information Processing Systems, 2020, 33: 9459-9474.
[8]Yao S, Zhao J, Yu D, et al. React: Synergizing reasoning and acting in language models[J]. arxiv preprint [arxiv:2210.03629], 2022.
[9] Villalobos P, Sevilla J, Heim L, et al. Will we run out of data? an analysis of the limits of scaling datasets in machine learning[J]. arxiv preprint [arxiv:2211.04325], 2022.
[10]Zhang Y, He G, Ma L, et al. A GPU-based computational framework that bridges Neuron simulation and Artificial Intelligence[J]. Nature Communications, 2023, 14(1): 5798.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









