






HashMap和Hashtable的区别
· 线程安全:HashMap是非线程安全的,Hashtable是线程安全的,因为Hashtble内部的方法基本上都经过synchronized修饰的。
· 对应Null key 和Null value的支持: HashMap是可以存储null的key和value,但是只能有一个null键,Hashtable是不支持null键和null值的,会抛出NullPointerException
· 初始化容量大小和每次扩容容量的大小的不同:1)如果没有初始化容量的大小,则Hashtable的默认初始化大小是11,之后每次扩容为原来容量的2n+1倍,HashMap的默认初始化大小是16,每次扩容为原来的2倍。2)如果给定了初始化大小,则Hashtable为给定的大小,HashMap则是为给定大小的2的幂次方
· 底层数据结构不同
HashMap和HashSet的区别
HashSet是基于HashMap实现的

HashSet如何检查重复?
当把对象加入到HashSet中,HashSet先会计算对象的HashCode值判断对象加入的位置以及判断对象有没有重复出现。如果重复出现,调用equals()方法来检查对象是否相同,如果相同则加入失败。
// Returns: true if this set did not already contain the specified element
// 返回值:当 set 中没有包含 add 的元素时返回真
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
// Returns : previous value, or null if none
// 返回值:如果插入位置没有元素返回null,否则返回上一个元素
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
...
}
也就是说,无论HashSet中是否存在相同的元素,HashSet都会执行add()方法,只是会在返回值处告诉我们该元素是否已经存在
HashMap的底层实现
·JDK1.8之前:
JDK1.8之前HashMap是由数组和链表实现的。HashMap 通过 key 的 hashcode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置。
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
// ^:按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}具体是采用了“拉链法”,也就是将链表和数组相结合,当创建一个链表数组时,数组的每一个就是一个链表。若遇到了冲突,则将冲突的值加入链表中即可。

·JDK1.8之前:
JDK1.8之后对解决冲突进行了优化。当链表长度大于阈值(8)时(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)),将链表转化为红黑树,以减少冲突的出现。

HashMap链表到红黑树转换的源码:
1)在putVal方法中判断链表长度是否大于8,满足则执行treeifybin(转换红黑树)
// 遍历链表
for (int binCount = 0; ; ++binCount) {
// 遍历到链表最后一个节点
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 如果链表元素个数大于等于TREEIFY_THRESHOLD(8)
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 红黑树转换(并不会直接转换成红黑树)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
2)treeifyBin方法中国判断数组长度并扩容转换成红黑树
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
// 判断当前数组的长度是否小于 64
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
// 如果当前数组的长度小于 64,那么会选择先进行数组扩容
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
// 否则才将列表转换为红黑树
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
ConcurrentHashMap
HashMap的线程安全的、支持高效并发的版本。在ConcurrentHashMap中,进行读操作的时几乎不加锁,而在写操作时通过锁分段技术只对所操作的段加锁而不影响客户端对其他段的访问。在理想状态下,ConCurrentHashMap可以支持16个线程执行并发写操作,及任意数量线程的读操作。
ConcurrentHashMap线程安全的具体实现方式/底层具体实现
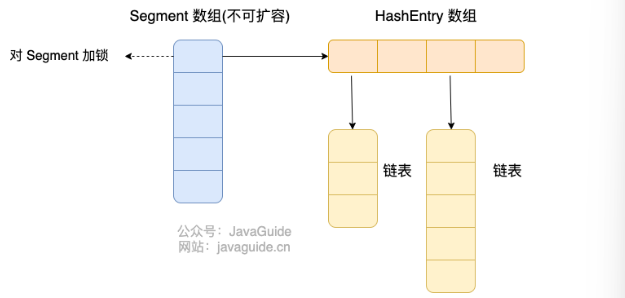
· jdk1.8之前,ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。
首先是把数据分为一段一段的存储。然后给每一段数据加上一把锁,当一个线程访问其中一个数据锁的时候,其他段的数据也能被其他线程访问。
Segment继承了ReentrantLock,所以Segment是一种可重入锁,扮演锁的角色,而HashEntry数组用于存储键值对数据。每个Segment守护一个HashEntry数组里的元素,
· jdk1.8后,取消了Segment分段锁,采用node+CAS+synchronized来保证并发安全。在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为 O(N))转换为红黑树(寻址时间复杂度为 O(log(N)))。
Java 8 中,锁粒度更细,synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,就不会影响其他 Node 的读写,效率大幅提升。















 1579
1579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









