






在散列中,函数“插入”和“查找”具有同样的时间复杂度。
在检索一个单词时,用哈希算法比用搜索树要快。
假定有K个关键字互为同义词,若用线性探测法把这K个关键字存入散列表中,至少要进行多少次探测:
链接:假定有k个关键字互为同义词,若用线性探测法把这k个关键字存入__牛客网由于K个关键字互为同义词,则可假设K个关键字均为1,即有K个1对于第一个1,散列表为空,探测一次,直接填入。
对于第二个1,这个1的位置被前一个1给占用了,所以要进行线性探测再散列,探测次数至少为2
对于第三个1,同理,探测次数至少为3。
对于第K个1,探测次数至少为K。
则总的探测次数至少为为1+2+。。+K=k(k+1)/2
若N个关键词被散列映射到同一个单元,并且用分离链接法解决冲突,则找到这N个关键词所用的比较次数为:N(N+1)/2
长度为n的顺序表L,其元素按关键字有序排列。若采用折半查找法找一个L中不存在的元素,则关键字的比较次数最多为[log2(n+1)]
给定散列表大小为11,散列函数为H(Key)=Key%11。按照线性探测冲突解决策略连续插入散列值相同的4个元素。问:此时该散列表的平均不成功查找次数是多少?
A.1
B.4/11
C.21/11
D.不确定答案:C
分析:
区别概念平均成功查找次数和平均不成功查找次数。
平均成功查找次数=每个关键词比较次数之和÷关键词的个数
平均不成功查找次数=每个位置不成功时的比较次数之和÷表长(所谓每个位置不成功时的比较次数就是在除余位置内,每个位置到第一个为空的比较次数,比如此题表长为11,散列函数为Key%11,除余的是11,那么除余位置就是0—10;如果表长为15,但散列函数为Key%13,那么除余位置就是0—12)
明确概念后做题:
连续插入散列值相同的4个元素,我们就假设它的散列值都为0,那么插入后的位置:其中位置0到第一个为空的位置4的比较次数为5,其余的位置以此类推。
平均不成功查找次数=(5+4+3+2+1+1+1+1+1+1+1)÷ 11 = 21/11
故选C
————————————————
版权声明:本文为CSDN博主「Rookie_聪」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_46678290/article/details/105970087
若N个关键词被散列映射到同一个单元,并且用分离链接法解决冲突,则找到这N个关键词所用的比较次数为:N(N+1)/2
解析:查找第一个1次,第二个2次,…,第N个N次,共N(N+1)/2次。
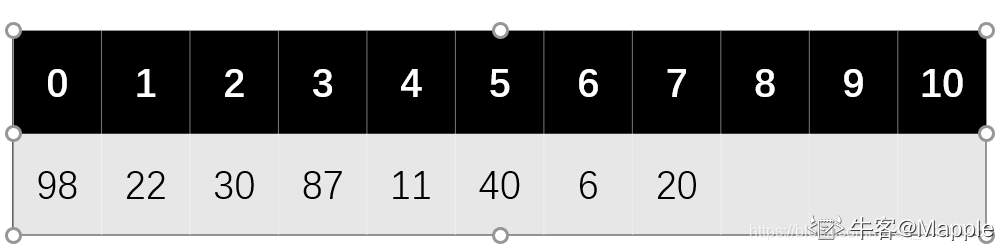
现有长度为 11 且初始为空的散列表 HT,散列函数是 H(key)=key%7,采用线性探查(线性探测再散列)法解决冲突。将关键字序列 87,40,30,6,11,22,98,20 依次插入到 HT 后,HT 查找失败的平均查找长度是:
链接:现有长度为11且初始为空的散列表HT,散列函数是H(key)__牛客网
来源:牛客网
1. 构造散列表
根据散列函数 H(key) = key %7 以及线性再探测,我们可以构造出散列表,如下图
2. 计算失败的平均查找长度
计算失败,可以转换理解,就是在已经构造好的散列表上,我们再去插入一个新的值需要比较多少次。
比如,现在我再插入一个数 21,那么理论上应该存放在地址 0 的位置,但是地址 0 有 98 了,则我们线性再探测(就是依次增加一个地址,看是否为空,空则可以插入),同理地址 1 也存在元素。以此类推,我们一共要比较地址 0~7,发现都有值,直到比较地址 8 才为空。所以一共比较了 9 次。
对其他地址(0~6)用同样的方式去理解,则一共比较的次数是 9+8+7+6+5+4+3 = 42
这里要注意,因为我们的模是 7,所以计算的地址只可能在(0~6)这个范围,所以最后的结果是 42/7 =6
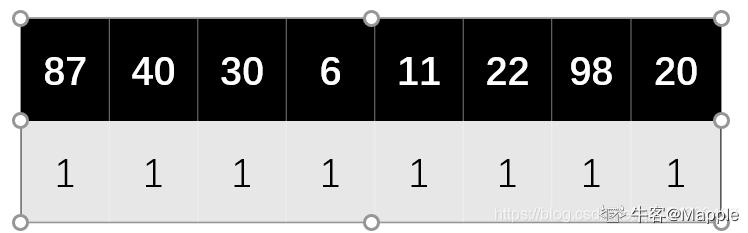
3.计算成功的平均查找长度
计算成功的长度,就是记录下每个数值比较了几次找到可存储的空间。
比如,本题每个数值比较(并存入)对应地址的次数如下图。
所以其 ASL = 1+1+1+1+1+1+1+1/8=1
note
1.注意失败与成功的查找长度的分母意义是不同的,失败时,分母是模的值;成功时,分母是元素个数。
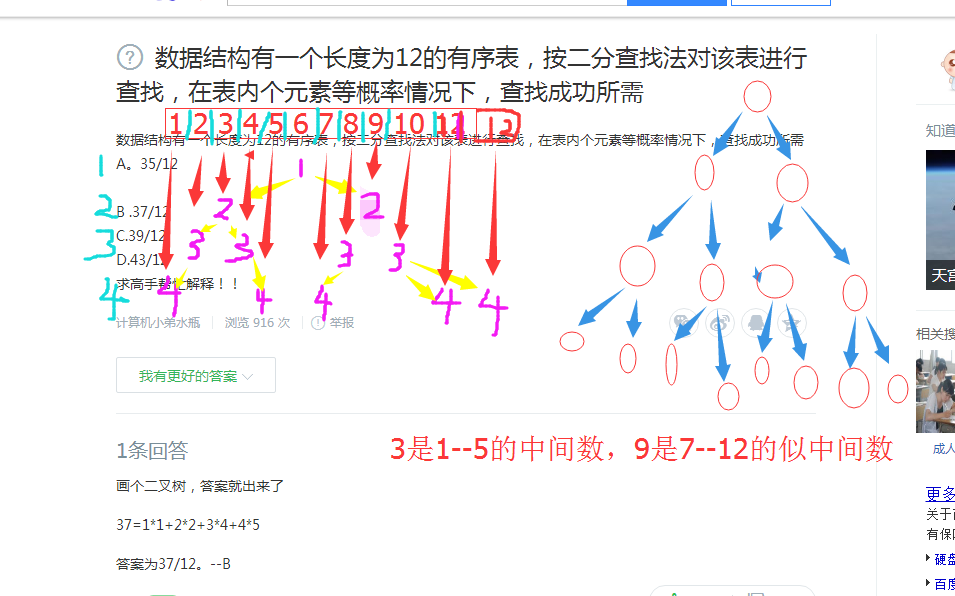
已知一个长度为16的顺序表L,其元素按关键字有序排列,若采用折半查找法查找一个 L中 不存在的元素,则 关键字的 比较次数最多是()
链接:已知一个长度为16的顺序表L,其元素按关键字有序排列,若采用__牛客网
来源:牛客网
找的是第16个数(0+15)/2 7 第1次
(8+15)/2 11 第2次
(12+15)/2 13 第3次
(14+15)/2 14 第4次
(15+15)/2 15 第5次
假定查找有序表A[1..12]中每个元素的概率相等,则进行二分查找时的平均查找长度为37/12
对一组包含10个元素的非递减有序序列,采用直接插入排序排成非递增序列,其可能的比较次数和移动次数分别是:
A.100, 100
B.100, 54
C.54, 63
D.45, 44
原因:非递减到非递增,有相同情况都是可能,首先考虑正常情况是从第一块数组比较,到最后插入也要比较完所有的数列并且交换,因此从1+…+n -1= (1+n-1)因为直接插入算法是从数组第二位开始比较,因此减少一位 (1+9)*9/2 = 45
————————————————
版权声明:本文为CSDN博主「浮而不实」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_40989066/article/details/117875381
对N个元素采用简单选择排序,比较次数和移动次数分别为:O(N2), O(N)
稳定性:
- 稳定的排序方法:直接插入,折半插入,冒泡排序,基数排序,归并排序
- 不稳定:简单选择排序,快速排序, 希尔排序,堆排序
就平均性能而言,目前最好的内排序方法是( 快速 )排序法
归并排序 是稳定的排序方法。
( 直接插入排序)不能保证每趟排序至少能将一个元素放到其最终的位置上。














 1372
1372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









