







📖 为什么需要非连续内存分配物理内存?
因为通过连续内存分配机制或多或少都会产生内、外部碎片,内存利用率较低,为了改善上述短板,提出来非连续内存分配机制。
📖 非连续分配的优点:
一个程序的物理地址空间是非连续的
更好的内存利用和管理【减少碎片化了、分开的地址应用不同的权限管理】
允许共享代码和数据【不同的地址块之间如果有需要可以相互访问】
支持动态加载和动态链接
📖 正文概述:
如果虚拟地址和物理地址的转换完全利用软件来完成会造成很大的开销,所以采用软硬件结合的方式
- 硬件方案:分段机制、分页机制【两种方法】
- 分段有段表完成逻辑与物理地址空间的映射,分页有页表完成逻辑与物理地址空间的映射
- 因为当下计算机采用分页机制的较多,所以后续再对页表(一种数据结构)展开讨论
一、分段
- 内存空间是怎么寻址的?【程序的分段地址空间】
- 实现分段寻址的机制

🐑 1. 逻辑地址空间到物理地址空间映射机制的实现
从应用程序的编写和运行来说,虚拟的逻辑地址空间是一个连续的地址空间,通过分段可以将它有效的隔离开来。
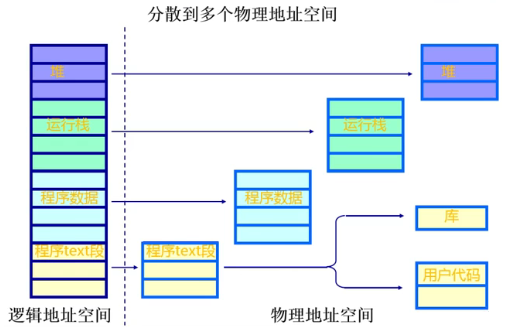
左边的程序将堆栈段放在某一个特定的地址,用特定的管理权限管理起来,把它运行的栈、数据、库、还有程序的代码段、以及其他的代码段都可以相应的分离出来。
分离开来的好处,共享,数据间相对隔离,处于不同的区域方便更有效的管理和分配,也可以方便保护机制的实现。

🐑 2. 分段机制地址的表示方法

通过段机制管理寻址的方式,将一维的地址分为两段:段的寻址、段内的偏移寻址
分为两种情况:一种是段与偏移是分开的,如上图的左边;另一种是段与段内偏移合在一起形成一个完整的地址,没有段寄存器的概念,把这个段的编号单独管理起来,属于单一地址的管理方式【以上讲的是硬件支持】
🐑 3. 具体的实现方案

在段表中通过段号去寻找实际的物理地址【逻辑地址段号和物理地址段号的映射关系】
在段表中也记录了每个段的大小【通过记录每个段的起始地址和长度限制】
CPU会去通过地址的限制判断访问的地址是否合法【因为段的大小是不固定的,可能找到的空间无法满足实际需求的大小】
段表是如何建立的呢?操作系统 在寻址前建立好了
二、分页
- 基于分页的地址空间
- 基于分页的硬件实现机制
“页号” “页的偏移”【页的大小是固定不变的】“页的大小”【逻辑与物理内存一样大】

要建立这个映射关系:页表、MMU/TLB【快表完成对页表的缓存】
🐸 1.页帧 —— 物理地址的布局
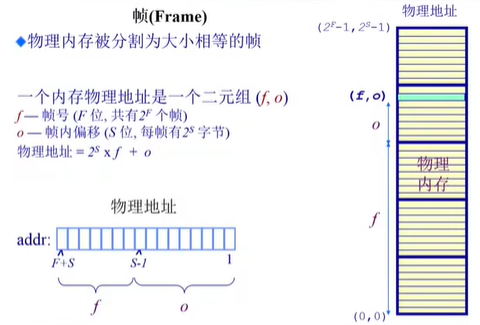
由页帧号和页帧偏移组成【F是页号占用的空间,f是页号;S是页帧占用的空间,o是页帧】
🐸 2.通过案例来分析页帧的设计

地址空间总共16位,页帧大小为9位,也就是说页帧偏移的大小为9位,那么剩余的七位为页号的大小。【S = 9、F = 7】
页帧号为3,页帧偏移为6【f = 3、o = 6】
🐸 3.页 —— 逻辑地址的寻址方式

由页号和页内偏移决定逻辑地址,偏移部分的大小逻辑地址与物理地址是相同的,但是页号的大小与页帧号的大小可能不相同。【页号偏大】
🐸 4.页寻址的实现机制
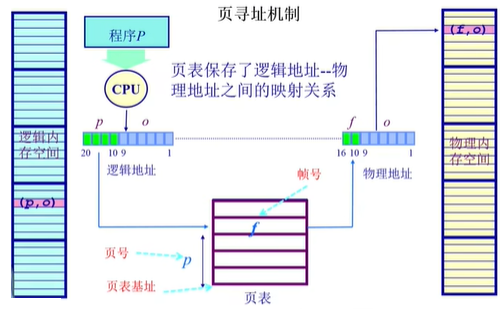
以页号为索引,对应实际物理地址的页号的映射关系
页表也是操作系统建立的
分页与分段的区别在于分页的大小是固定的,不用像分段一样去考虑空间大小是否满足应用程序的需求。
逻辑地址空间的页比对应物理地址空间的页要大【页号大于页帧号】

无论是连续地址空间机制还是不连续地址空间机制,它在逻辑地址层面都是连续的,通过这种不连续的地址分配机制解决了地址碎片化的问题
三、页表
概述:页表的结构、通过页表完成逻辑地址到物理地址的转换、当前页表存在的问题、解决办法(TLB)
🐲 1、页表的结构是什么样的呢?

页表由两部分组成:标志位 和 帧号
这个帧号对应物理地址起始位置,加上逻辑地址传来的偏移,就是实际物理地址
resident bit 代表当前页表项是否合法(即有没有对应的物理地址),1 代表合法,0 代表不合法
为什么会出现逻辑地址对不上物理地址的情况呢?【因为逻辑地址空间太大了,比如64位操作系统,寻址空间位 2^64】
🐲 2、如何通过页表寻址的呢?
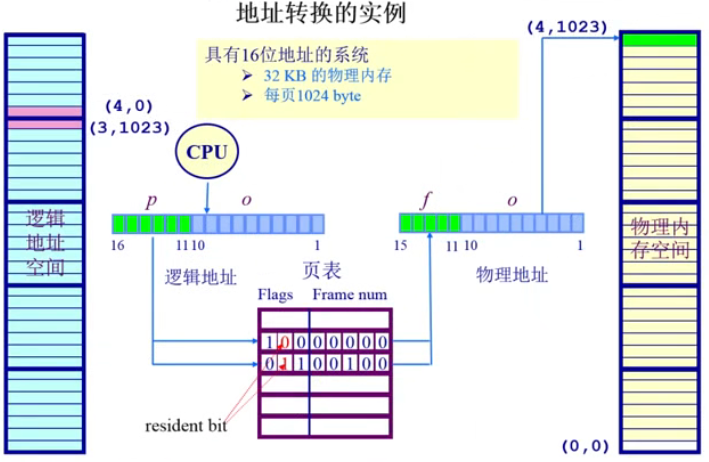 ,
,
(1)16bit (64KB)操作系统,但是物理内存只有32KB,说明有一部分对不上
(2)CPU会查到页表的起始地址,然后通过pagenumber算出其index,寻址到对应的页表项,把相应的Frame num取出来得加上偏移形成物理地址
(3)根据(4, 0)页号与页内偏移找到对应页表项,发现空间不合法,进程被杀死,全剧终
(4)页号为3,页内偏移为1023找到对应页表项,空间合法、帧号为4,就得到物理地址 (4, 1023)
🐲 3、如果只使用页表来完成地址映射,那么会带来一些问题
(1)空间代价问题
对于页的大小是固定的就是 1K,如果为64位操作系统,那么就需要页表的大小为 2^ 54;
每一个运行的程序都要创建一个页表辅助程序运行,如果每个页表都很大,那么就导致空间开销特别大
(2)时间开销问题
访问一个内存单元需要2次内存访问,一次用于获取页表项,一次用于访问数据
(3)那么如何缓解问题呢?
- 缓存:常用的内容缓存到离CPU很近的地方
- 间接访问:通过多级页表机制来解决,就不用一次访问那么大的页表了
🐲 4、利用快表来完成对经常访问的数据存储
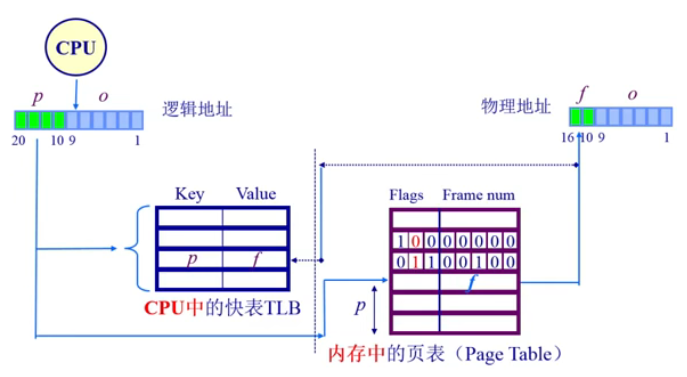
当CPU得到逻辑地址,首先根据 P去TLB中查找,如果命中了快表,那么根据 f 加上页内偏移就直接能得到物理地址,如果没有才去页表中寻找
通过这样的方法,将近期访问的页帧缓存下来,从而提升了查找物理地址的速度
🐲 5、采用多级页表的方式来节省空间
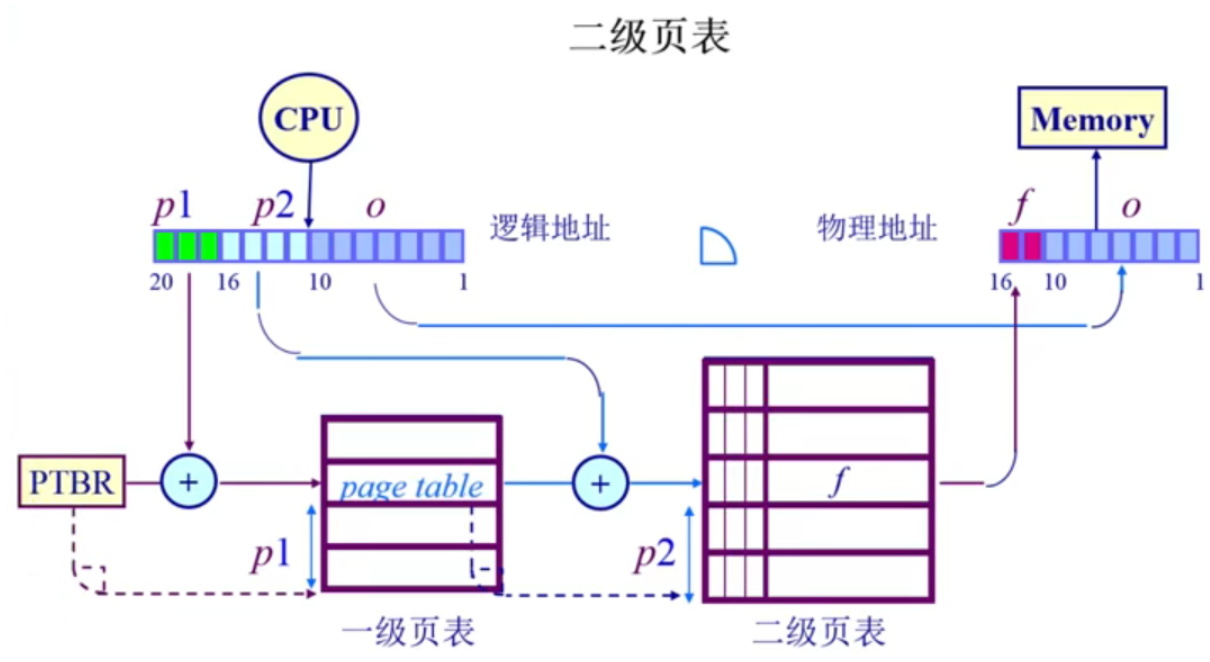
首先以二级页表为例,通过将页表号分为两部分
一级页表存储二级页表的起始地址,把p2的number作为二级页表的index
将其与p1的起始地址相加 >> 得到在二级页表中的一个页表项,这里面存储的是帧号
帧号加上偏移量就可以获得物理地址
- 那么是如何节省空间的呢?
p1指向的某一个页表项不存在的话,驻留位为0,那么二级页表就不用去存那个pagetable,节省了空间【如果只有一个页表即使映射关系不存在,对应的空间也要保留】
- 进而可以推广出多级页表:

🐲 6、有没有什么办法让页表与逻辑地址大小无关而与物理地址大小相关呢?
反向页表:通过页寄存器来完成,不过index是物理页号(页帧号),页表项的内容为页号

- 空间是省了,但是我们最终要找到的还是物理地址,那么从页帧号 >> 页号,我们最后如何得知页帧号呢?
我们可以使用关联内存的方式,并行去查找,从而获得物理地址
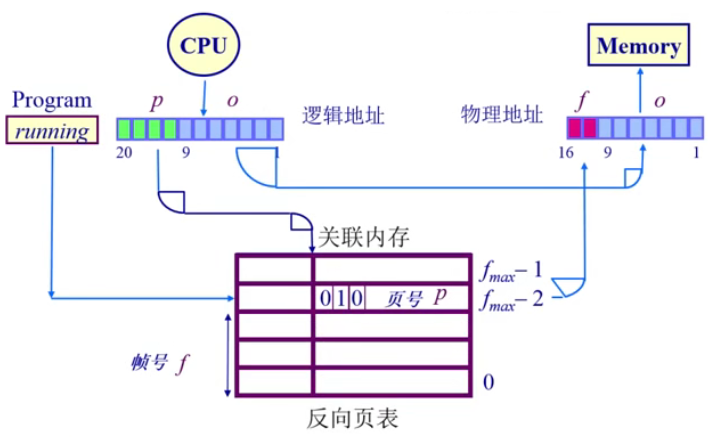
- 能找到了物理地址,但是又带来了新问题,这个关联内存寄存器空间下,并且得放在CPU里面使用,这就导致了很大的开销,如何降低开销呢?
我们可以采用哈希表的方式,利用哈希算法获得每个页对应的帧号
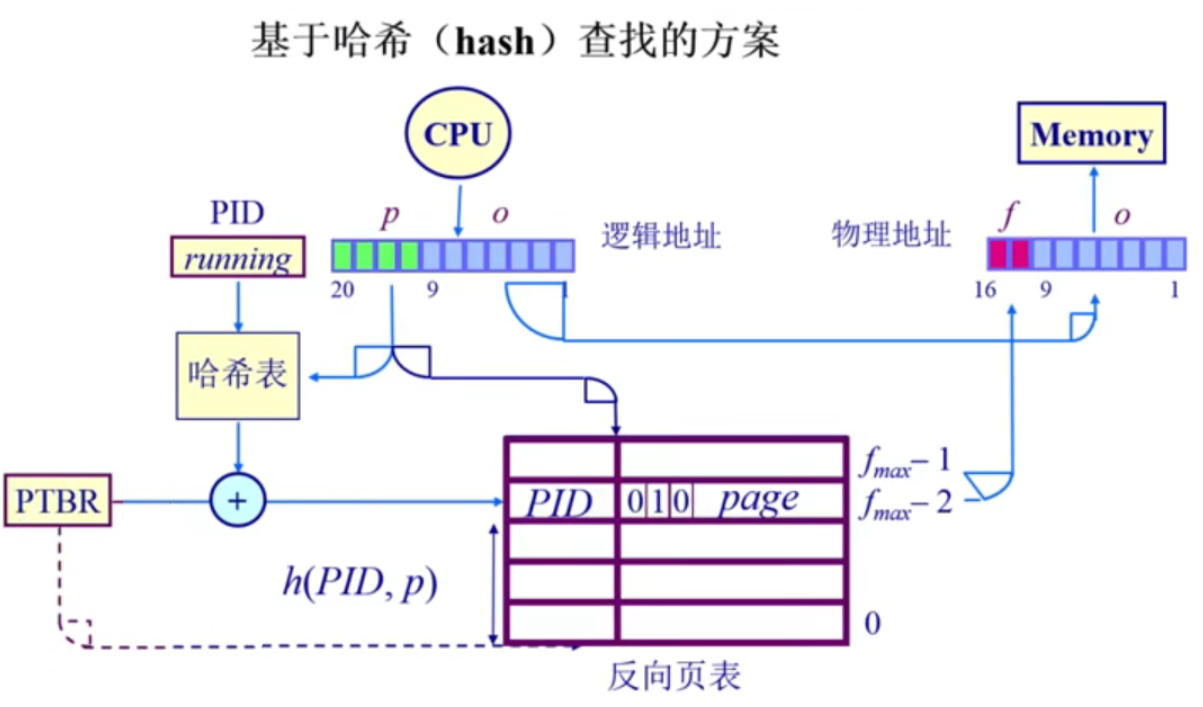
这种方式还是需要把反向页表放到内存中,做哈希计算时也需要到内存中取值,内存的开销还是很大,所以还需要有一个类似TLB的机制缓存起来,降低访问的时间。

















 309
309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











