









文章目录
前言
在学习python之前,我们应该要了解一些关于计算机的相关知识和程序的执行原理。
1. 计算机中的三大件
计算机中三大件分别指的是: cpu,内存,硬盘。
cpu: 一块大规模的集成电路,负责处理数据/计算。
内存: 临时存储数据 ,速度快空间小。
硬盘:永久存处数据,速度慢,空间大。
2. 程序的执行原理
- 在程序执行之前,是保留在
硬盘上。 - 程序要执行,首先要被加载到
内存。 - 执行时,
cpu把程序复制到内存中,执行内存中的程序代码。
3. Python执行原理
-
操作系统让
cpu把python解释器的程序复制到内存。 -
python解释器根据语法规则,从上到下让
cpu翻译python程序中的代码。 -
cpu负责执行翻译完成的代码。
一. Python简介
1. 了解Python
Python是一种解释型(开发过程中无编译环节)、面向对象(支持面向对象的风格或代码封装在对象的编程技术)、动态数据类型交互式(可在命令中通过Python提示符以及之间代码执行程序)的高级程序设计语言。
2. Python特点
-
易于学习: 相对较少的关键字,结构简单,明确的语法。
-
易于阅读:代码定义的更清晰。
-
易于维护: 源代码相当容易维护。
-
一个广泛的标准库: 丰富的库,且跨平台,在
Unix,Windows和Mac兼容很好。 -
交互模式: 可以从终端输入执行代码并且获得结果的语言。
-
可移植性: 具有开源特性,被移植到许多平台。
-
可扩展性: 如果需要运行一段很快的关键代码,或者是想要编写一些不愿意开放的算法,可以使用
C或者C++完成那部分程序,然后从Python程序中调用。 -
嵌入性: 可以将
Python嵌入到C/C++程序,让我们的程序获得脚本化的能力。
3. Python版本
- Python2.x
- Python3.x
二. 注释和转义字符
- python中的注释有单行注释和多行注释。
- 单行注释使用
#,多行注释使用三个单引号''' '''或者三个双引号""" """
1. 单行注释
#注释内容
2. 多行注释
方式1:
'''
注释1
注释2
注释3
'''
方式2:
"""
注释1
注释2
注释3
"""
3. 转义字符
\n: 换行符。
\t: 制表符。使垂直方向对齐
\\: 反斜杠符号
\': 单引号
\":双引号
\r: 回车
#\t 制表
print("1\t2\t3\t4\t5")
print("10\t11\t12\t13\t14\t15")
#\n 换行
print("hello\npython")
#\\ 反斜杠
print('hello\\world') # hello\python
#\' 单引号
print("I\'m fine") # I'm fine
#\"" 双引号
print('pyton\"胶水语言"') # python"胶水语言"
#\r 回车
print('hello\rhi') # hi
三. python中的变量
- 程序的作用: 用来处理数据。
- 变量: 程序内部为了保存数据而开辟了空间 (保存数据)。
1. 变量的定义
变量名 = 值,如:
name = "关羽"
age = 18
-
变量名第一次出现: 定义变量
-
再次出现的话还是这个变量,变量的值可以改变。
2. 变量的命名
变量名的定义,要满足标识符的命名规则。
由数字、字母、下划线组成。
- 不能数字开头
- 不能使用内置关键字
- 严格区分大小写
命名习惯:大驼峰、小驼峰、下划线。
大驼峰: MyName = ‘张三’
小驼峰: myName = ‘张三’
下划线: my_name = ‘张三’
3. 变量的特点
-
变量在程序执行的时候创建,在执行结束之后销毁。
-
python中不需要定义变量的类型,python自动会推导出保存的数据的类型。
-
一个变量中内存保存有变量名称
id,变量类型type,数据值value。 -
变量定义时,内存会为其开辟一份空间。
-
python2.0中有
Long类型,python3中无Long类型。
4. 变量的类型
-
变量的类型分为数字型和非数字型。
-
数字型:
int(整型),float(浮点型),bool(布尔型)。 -
非数字型:
str(字符串),list(列表),tupple(元组),dict(字典)。 -
Python中不需要关心变量的类型,python会自动推导出变量的类型。
检测数据类型的方法: type(变量名或者数值)
'''整型'''
a = 100
print(type(a)) #<class 'int'>
'''浮点型'''
b = 1.2
print(type(b)) # <class 'float'>
'''布尔型'''
c = True
print(type(c)) # <class 'bool'>
'''字符串'''
d = '010101'
print(type(d)) # <class 'str'>
'''列表'''
e = [1,2,3]
print(type(e)) # <class 'list'>
'''元组'''
f = (1,2,3)
print(type(f)) # <class 'tuple'>
'''字典'''
g = {"name":"张三","age":18}
print(type(g)) # <class 'dict'>
5. 变量的计算
在python中,数字类型的变量是可以直接进行算术运算的。
1.数字类型的算术运算
i = 100
f = 1.5
b = True
b2 = False
print(i + f) #101.5
print(i + b) #101
print(f + b) #2.5
print(i + b2) #100
- 计算时
bool型的True相当于 1。 bool型的False相当于 0。
2.字符串类型的运算
#字符串的拼接
str1 = 'hello'
str2 = 'world'
print(str1 + str2) #helloworld
#字符串的重复使用
str3 = '-'
print(str3 * 10) #----------
- 字符串除了拼接以及重复使用外,不能再与数字型的变量进行计算
6. 变量的输入
使用input()函数,可以获取用户通过键盘输入的信息。
ipt = input("请输入您的账号")
print(ipt) #请输入您的账号
input()函数输入的信息python都默认为是字符串类型。
ipt = input("12345")
print(type(ipt)) #12345 <class 'str'>
7. 变量类型的转换
1.数字类型间的转换
#float() --转换成浮点型
a = 100
print(a,type(a)) #100 <class 'int'>
b = float(a)
print(b,type(b)) #100.0 <class 'float'>
#int() --转换成int型
a = 66.6
print(a,type(a)) #66.6 <class 'float'>
b = int(a)
print(b,type(b)) #66 <class 'int'>
2.非数字类型间的转换
#str() --转换成字符串型
a = 1314
print(a,type(a)) #1314 <class 'int'>
b = str(a)
print(b,type(b)) #1314 <class 'str'>
#list() --将一个序列转换成列表
s = 'hello'
print(s,type(s)) #hello <class 'str'>
l = list(s)
print(l,type(l)) #['h', 'e', 'l', 'l', 'o'] <class 'list'>
#tuple() --将一个序列转换为元组
s = 'hello'
print(s,type(s)) #hello <class 'str'>
t = tuple(s)
print(t,type(t)) #('h', 'e', 'l', 'l', 'o') <class 'tuple'>
#eval() --eval()函数将字符串中的数据转换为python表达式的原本类型
str1 = '110'
str2 = '[0,0,0,1]'
str3 = '(99,88,77)'
a = eval(str1)
b = eval(str2)
c = eval(str3)
print(type(a)) #<class 'int'>
print(type(b)) #<class 'list'>
print(type(c)) #<class 'tuple'>
8. 变量的格式化输出
如果希望输出字符串的同时,一起输出数据,则用格式化操作符(用于处理字符串中的格式)。
1. 格式化输出
| 占位符 | 类型 |
|---|---|
| %s | 字符串 |
| %d | 有符号十进制整数 |
| %f | 浮点数 |
| %c | 字符 |
| %u | 无符号十进制整数 |
| %o | 八进制整数 |
| %x | 十六进制整数 |
| %e | 小写’e’ |
| %E | 大写’E’ |
| %g | %f和%e的简写 |
| %G | %f和%E的简写 |
-
%06d表示显示6位,不足的地方补0。 -
%.2f表示显示两位小数。
2. format()内置函数
-
format()用于字符串格式化,功能非常强大。 -
format()函数可以接受不限个参数,位置可以不按顺序。 -
使用方式:
str.format()。
3. f-格式化字符串
-
f-string是一种很好的格式化字符串的方法。 -
特点:简洁,速度快,不易出错。
-
使用方式:
f' {表达式} '
4. 格式化字符串的使用
name = '艾克'
age = 18
weight = 60.5
id = 2
print('%s来自祖安' %name) #艾克来自祖安
print('他的id是%08d' %id) #他的id是00000002
print('他的体重是%.1f' %weight) #他的体重是60.5
print("他的名字是%s,今年%d岁了" %(name,age)) #他的名字是艾克,今年18岁了
print("他的名字是%s,明年%d岁了" %(name,age + 1)) #他的名字是艾克,明年19岁了
#str.format()
print('他的名字是{0},明年{1}岁了'.format(name,age + 1)) #他的名字是艾克,明年19岁了
print('他的名字是{0},明年{1}岁了'.format('蔚',24)) #他的名字是蔚,明年24岁了
#f'{表达式}'
print(f'他的名字是{name},明年{age + 1}岁了') #他的名字是艾克,明年19岁了
四. Python中的运算符
Python中的运算符有: 算术运算符、赋值运算符、复合运算符、比较运算符、逻辑运算符。
1. 算术运算符
| 运算符 | 描述 | 例子 |
|---|---|---|
| + | 加 | 1+1 输出结果为 2 |
| - | 减 | 1-2 输出结果为 0 |
| * | 乘 | 3*3 输出结果为 9 |
| / | 除 | 4/2 输出结果为 2.0 |
| // | 整除 | 11//2 输出结果为 5 |
| % | 取余数 | 5%2 输出结果为 1 |
| ** | 指数 | 2**3 输出结果为 8 |
| () | 小括号 | (2+3)*4 输出结果为 20 |
print(1+1) # 2
print(1-1) # 0
print(2*2) # 4
print(4/2) # 2.0
print(11//2)# 5 --取整
print(5%2) # 1 --取余
print(2**3) # 8 --2的三次方
优先级顺序: () > ** > * 、/、//、% > +、-
2. 赋值运算符
| 运算符 | 描述 | 例子 |
|---|---|---|
| = | 赋值 | 将 = 右边的结果赋值给等号左边的变量 |
单个变量赋值:
a = 100
print(a)
多个变量赋相同值:
# 链式运算(三个变量指向同一个对象)
a = b = c = 100
print(a,id(a)) #100 140707019725056
print(b,id(b)) #100 140707019725056
print(c,id(c)) #100 140707019725056
多变量赋不同值:
n1,f1,s1 = 10,20.0,'python'
print(n1) #10
print(f1) #20.0
print(s1) #python
交换两个变量的值:
a,b = 10,20
a,b = b,a
print(a) #20
print(b) #10
3. 复合运算符
| 运算符 | 描述 | 例子 |
|---|---|---|
| += | 加法赋值运算符 | c += 1 等价 c = c+1 |
| -= | 减法赋值运算符 | c -= 1 等价 c = c-1 |
| *= | 乘法赋值运算符 | c *= 1 等价 c = c*1 |
| /= | 除法赋值运算符 | c /= 1 等价 c = c /1 |
| //= | 整除赋值运算符 | c /= 1 等价 c= c // 1 |
| %= | 取余赋值运算符 | c %=1 等价 c = c%1 |
| **= | 幂赋值运算符 | c **=1 等价 c = c**1 |
a = 10
a += 1 # 11 a = 10 + 1
a -= 1 # 9 a = 10 - 1
a *= 2 # 20 a = 10 * 2
a /= 2 # 5.0 a = 10 / 2
a //= 2 # 5 a = 10 // 2
a %= 2 # 0 a = 10 % 2
a **= 2 #100 a = 10 ** 2
print(a)
4. 比较运算符
| 运算符 | 描述 | 例子 |
|---|---|---|
| == | 相等,如果两个操作数的结果相等,则条件结果为True,否则为False | a=5,b=5,则(a==b),为True |
| != | 不等于,如果两个操作数的结果不相等,则条件结果为True,否则为False | a=5,b=5,则(a!=b),为False |
| > | 大于,左侧大于右侧,则条件结果为True,否则为False | a=1,b=6,则(a>b),为False |
| < | 小于,左侧小于右侧,则条件结果为True,否则为False | a=1,b=6,则(a<b),为True |
| >= | 大于等于,左侧大于等于右侧,则条件结果为True,否则为False | a=5,b=5,则(a>=b),为True |
| <= | 小于等于,左侧小于右侧,则条件结果为True,否则为False | a=5,b=5,则(a!=b),为True |
a = 10
b = 5
print(a == b) #False
print(a != b) #True
print(a > b) #True
print(a < b) #False
print(a >= b) #True
print(a <= b) #False
5. 逻辑运算符
| 运算符 | 表达式 | 描述 | 例子 |
|---|---|---|---|
| and | x and y | 与运算,全部相同则为True,否则为False | True and True,为True |
| or | x or y | 或运算,有True为True,否则为False | False or False,为False |
| not | not x | 非运算,非真即假 | not True,为False。not False,为True |
#and
a,b = 1,2
print(a==1 and b==2) #true and true --->True
print(a!=1 and b==2) #false and true --->False
print(a==1 and b!=2) #true and false --->False
print(a!=1 and b!=2) #false and false --->False
#or
b,c = 3,4
print(b==3 or c==4) #true or true --->True
print(b!=3 or c==4) #false or true --->True
print(b==3 or c!=4) #true or false --->True
print(b!=3 or c!=4) #false or false --->False
#not 希望某个条件不满足时,执行一些代码,则使用not
f1=True
f2=False
print(not f1) #False
print(not f2) #True
五. Python中的流程控制
流程控制分为: 顺序结构、选择结构、循环结构。
1. 顺序结构
代码从上到下依次执行。
# 把猪蹄装进冰箱
print('---------程序开始--------')
print('1.打开冰箱门')
print('2.把猪蹄装进冰箱')
print('3.关闭冰箱门')
print('--------程序结束---------')
2. 选择结构
代码执行的时候需求不同则有不同的执行方式,让程序适应更多场景。
1. if条件语句
if 条件:
条件成立执行的代码1
条件成立执行的代码2
...
2. if单分支
#实例: 银行取款
money = 1000
get_money = int(input("请输入取款金额:"))
if get_money >= 1000 :
money = money - get_money
print("取款成功,余额为:",money)
print("无论如何都会执行的语句,因为不在if语句块里")
3. if多分支(if else)
if 条件:
条件成立执行的代码1
条件成立执行的代码2
...
else:
条件不成立执行的代码1
条件不成立执行的代码2
...
- 条件成立,执行
if语句块里的代码 - 条件不成立,执行
else语句块里的代码 - 2选1
#实例: 银行取款
money = 1000
get_money = int(input("请输入取款金额:"))
if get_money >= 1000 :
money = money - get_money
print("取款成功,余额为:",money)
else :
print("取款失败")
4. if多重判断
if 条件1:
条件1成立执行的代码1
条件1成立执行的代码2
...
elif 条件2:
条件2成立执行的代码1
条件2成立执行的代码2
...
...
else:
以上条件都不成立时执行的代码
- 多条件使用
elif,所有条件都是平级的 elif和else都必须和if联合使用,不能单独使用- 可以将
if、elif、else以及各自增加的代码,看成一个完整的代码块 - 如果某条件成立,则执行某条件里的代码,其他情况的代码将不会执行
- 如果条件都不成立,则执行
else里边的代码
#实例:工龄判断
age = int(input("请输入您的年龄:"))
if age < 18:
print(f'您的年龄是{age},童工一枚')
elif (age >= 18 and age <=60):
print(f'您的年龄是{age},合法工龄')
elif age > 60:
print(f'您的年龄是{age},可以退休')
else:
print("输入有误")
5. if嵌套
if 条件1:
条件1成立执行的代码1
条件1成立执行的代码2
...
if 条件2:
条件2成立执行的代码1
条件2成立执行的代码2
...
- 条件2的
if是在条件1的缩进关系内部 - 只有满足了条件1才有可能进入到条件2的内部
#实例: 购物
anser = input("请问您是会员么y/n:")
money = float(input("您的购物金额为:"))
#判断是否是会员(外层)
if anser == 'y': #会员
#判断购物金额(内层)
if money >= 2000 :
print("打八折,实付金额为:",money * 0.8)
elif money >= 1000 :
print("打八折,实付金额为:",money * 0.9)
else:
print("不打折,实付金额为:",money)
else: #非会员
print("不打折,实付金额为",money)
6. 三目运算符
三目运算符也叫三元运算符。
值1 if 条件 else 值2 # 条件满足返回值1 否则 值2
a = 10
b = 20
c = a if a > b else b #20
- 条件满足则返回前面的a,条件不满足则返回后面的b
7.应用: 猜拳游戏
需求分析:
-
参与游戏的角色
随机出拳
手动出拳
玩家
电脑
-
判断输赢
玩家 电脑 石头 剪刀 剪刀 布 布 石头 电脑获胜
玩家获胜
平局(玩家出拳和电脑出拳相同)
随机做法:
1.导出random模块:
import 模块名
2.使用random模块中的随机整数功能:
random.randint(开始,结束)
#猜拳游戏
"""
提示: 0-石头,1-剪刀,2-布
1.出拳
玩家输入出拳
电脑随机出拳
2.判断输赢
玩家获胜
电脑获胜
平局
"""
import random
#玩家输入出拳出拳
player = int(input("请出拳:0-石头,1-剪刀,2-布:"))
#电脑随机出拳
computer = random.randint(0,2)
if (player == 0 and computer == 1) or (player == 1 and computer == 2) or (player == 2 and computer == 0):
print('玩家获胜!')
elif player == computer:
print('平局!')
else:
print('电脑获胜!')
3.循环结构
让特定的代码更高效的重复执行。
在Python中,有while和for两种循环,最终实现的效果都是相同的。
1. while循环
初始条件
while 条件:
条件成立重复执行的代码1
条件成立重复执行的代码2
...
处理条件
- 如果忘记加处理条件,则会使程序进入到死循环
#while循环
# 1.打印小于10的整数
a=1
while a < 10 :
print(a) #1,2,...9
a +=1
# 2.计算1~100累加和 (1+2+3+4+5+...+100) 即前两个数字相加的结果 + 下一个数字
sum = 0
i = 1
while i <= 100:
sum += i #sum = sum + i (0+1+2+3+...+100)
i += 1
print(sum) #5050
# 3.计算1~100之间的所有偶数和 (0+2+4+...+100)
#方法1:条件判断和2取余为0的则进行累加
sum = 0
i = 1
while i <= 100:
if i % 2==0:
sum += i
i += 1
print(sum)
#方法2:计数器控制增量为2
sum = 0
i = 0
while i <= 100:
if i % 2 == 0:
sum += i
i += 2
print(sum) #2550
1. break
在循环内部当某一条件满足时,跳出整个循环,不再执行后续重复的代码。
'''
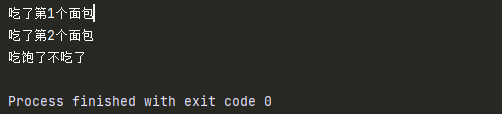
一共吃5个面包,吃完第一个吃第二个,吃完第2个吃饱了,就不吃了。
'''
i = 1
while i <= 5:
if i == 3:
print('吃饱了不吃了')
break
print(f'吃了第{i}个面包')
i +=1
2. continue
当满足某个特定条件时,continue后面的重复代码不执行,直接跳回到条件判断,继续执行其他。
只是排除某个特定的条件,跳出当前的条件判断
'''
一共吃5个面包,吃完第一个吃第二个,吃到第3个有虫,开始吃第4个。
'''
i = 1
while i <= 5:
if i == 3:
print('面包有虫,不吃了,吃下一个')
i += 1 #在continue之前一定要修改计数器,否则会陷入死循环
continue
print(f'吃了第{i}个面包')
i += 1

3. break和continue的区别
break和continue都是循环满足一定条件退出循环,只是方式不同break跳出整个循环,continue跳出当前循环(继续下一个判断)
4. while嵌套循环
while嵌套循环: 一个while语句里面嵌套另一个while语句。
while 条件1:
条件1成立执行的代码
...
while 条件2:
条件2成立执行的代码
...
- 外层循环执行一次,内层循环执行一遍
#打印5行星星
i = 0
while i <= 4: #外层控制行数
j = 0
while j <= 4: #内层控制列数
print('*',end='')
j += 1
print() #每行打印结束后,需要换行
i += 1

print()默认输出完成以后进行换行- 如果不希望末尾增加换行,可以在
print()函数输出内容的后面增加end=' '
#打印直角三角形
i = 1
while i <= 5:
j = 1
while j <= i:
print('*',end='')
j += 1
print()
i += 1

#九九乘法表
i = 1
while i <= 9:
j = 1
while j <= i:
print(f'{i} * {j} = {i*j}',end='\t')
j += 1
print()
i += 1

5. while循环配合else使用
while 条件:
条件成立重复执行的代码
else:
循环结束后要执行的代码
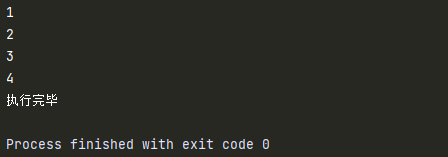
else在循环中使用,表示当前循环正常结束之后要执行的代码。
a=1
while a < 5 :
print(a) # 1,2,...5
a +=1
else:
print('执行完毕')
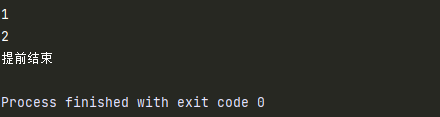
若循环不是正常结束,如果是break终止循环,则else语句块的代码不执行:
a=1
while a < 5 :
if a == 3:
print('提前结束')
break
print(a) # 1,2,...5
a +=1
else:
print('执行完毕')
continue只是退出当前循环一次,并不是终止循环,所以是可以正常结束的:
a=1
while a < 5 :
if a == 3:
print('跳过3')
a += 1
continue
print(a) # 1,2,...5
a +=1
else:
print('执行完毕')

- 使用
continue可以正常结束,else语句的代码能够执行。
2. for循环
for 临时变量 in 序列 :
重复执行的代码1
重复执行的代码2
...
for循环在python中经常使用
str = 'Hello Python'
for i in str :
print(i)

1. break
str = 'Hello Python'
for i in str :
if i == 'P' :
print("遍历到P,不打印")
break
print(i)

2. continue
str = 'Hello Python'
for i in str :
if i == 'y' :
print("不打印y")
continue
print(i)

3. for配合else使用
for 临时变量 in 序列 :
重复执行的代码
...
else:
循环正常结束之后要执行的代码
str = 'Hello Python'
for i in str :
print(i)
else :
print('执行完毕')

break终止循环,else代码不执行:
str = 'Hello Python'
for i in str :
if i == 'P' :
print("遍历到P,不打印")
break
print(i)
else :
print('else不执行')

continue控制循环,else代码正常执行:
str = 'Hello Python'
for i in str :
if i == 'y' :
print("不打印y")
continue
print(i)
else :
print('else执行')

4. for…else的应用场景
在迭代遍历嵌套的数据类型时,例如一个列表包含了多个字典。
需求:需要判断某一个字典中是否存在指定的值
name="张辽"
name_dict = [{"name":"关羽"},
{"name":"张飞"},
{"name":"赵云"},
{"name":"马超"},
{"name":"黄忠"}
]
for wh_name in name_dict:
print(wh_name)
if name == wh_name["name"]:
print("%s在五虎上将之列" %name)
break
else:
print('很遗憾,五虎上将名将册中无"%s"这位将领' %name)
print("遍历结束")

- 如果存在,提示并且退出循环
- 如果不存在,等循环整体结束后,希望得到一个统一的提示
- 如果希望在搜索列表时所有的字典检查之后,都没有发现需要搜索的目标,还希望得到一个提示那就用
for...else。
六. 函数的概念
所谓函数,就是把具有独立功能的代码块组织成一个小模块,在需要的时候调用。
使用函数可以实现代码的复用。
函数使用时,包括两个步骤:
1.定义函数
def 函数名():
函数封装的代码
...
- 定义函数时,就是把代码封装到了函数内部,函数具有独立的功能
2.调用函数
函数名()
- 当我们对函数进行调用时,就可以享受函数封装的代码,使用其功能。
1. 函数的定义
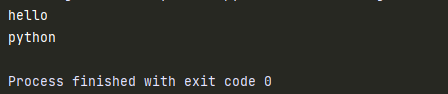
#1.定义函数
def test():
print('hello')
print('python')
#2.调用函数
test()
2. 函数的执行时机
name = 'hello wolrd'
#test() NameError: name 'test' is not defined
def test():
print('hello')
print('python')
print(name)
test()
print(name)

-
函数需要在前面先定义后,在后面可以执行,否则会报错(函数调用不能在函数定义的上面)
-
函数在调用时,才会执行。
函数的文档注释:
def test(): """注释内容""" print('hello') print('python') test()Pycharm查看函数的文档: Ctrl + Q
3. 函数的参数
- 增加了函数的通用性,针对相同的数据处理逻辑,能够适应更多的数据
函数参数的使用:
def 函数名(参数1,参数2): #形参
函数封装的代码
...
函数名(参数1,参数2) #实参
- 定义函数时括号里的参数是形参
- 调用函数时括号里的参数是实参
- 函数在调用的时候把外部的数据以参数的形式传递给函数,函数接收到以后就可以在内部使用了
#使用函数完成两个数的求和
def num_sum(num1,num2):
sum = num1 + num2
print(sum)
num_sum(10,20) #30
4. 函数的返回值
-
要使用函数的返回值,使用
return关键字 -
返回值就是函数执行结束后,给调用者的一个结果
def sum_str(str1,str2):
sum = str1 + str2
return sum
result = sum_str('赵丽颖','真美')
print(result) # 赵丽颖真美
- 可以使用变量,来接收函数执行的返回结果
return表示函数返回的结果了,如果还在return下边写代码,则写的代码是无效的
5. 函数的嵌套
函数的嵌套就是一个函数中调用另一个函数。
def 函数1():
函数1封装的代码
...
函数2()
...
def test1():
print('*' * 5)
test2() #函数1中调用了函数2
print('-' * 5)
def test2():
print('M' * 5)
test1()
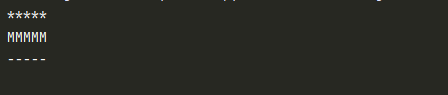
- 当函数开始调用时,若函数中调用了另一个函数,则从当前位置开始调用,执行结束之后,再由当前位置向下执行后面的代码
七. 模块的概念
Python中的模块好似一个工具包,要想使用这个工具包中的工具,就需要导入import这个模块。
每一个以扩展名.py结尾的python源代码文件都是一个模块。
在模块中定义的全局变量、函数都是模块能够提供给外界直接使用的工具。
1. 模块的使用
1.定义一个demo1.py
name = '鸣人'
def test1():
print('P' * 5)
def test2():
print('Y' * 5)
test1()
2.导入demo1.py,并且使用里边的工具(test2()、name变量)
import demo1
demo1.test2()
print(demo1.name)

- 导入之后,就可以使用
模块名.变量/模块名.函数的方式,使用这个模块中定义的变量或者函数 - 使用模块,可以让曾经编写过的代码方便的被复用
八. Python高级数据类型
Python中高级数据类型有: 字符串(string)、列表(list)、元组(tuple)、字典(dict)
1. 列表
-
列表(
list)是python中使用最频繁的数据类型,在其他语言中通常叫做数组。 -
可以存储不同类型的数据,数据可重复。
-
列表是有序的对象集合,有索引。
1.列表的定义
#定义一个空列表
list = []
name = ['刘备','关羽','张飞']
print(name[0]) # 刘备
print(name) # ['刘备', '关羽', '张飞']
2.列表的常用操作
1. 获取数据
name_list = ['关羽','张飞','赵云','马超','黄忠']
print(name_list[0]) # 关羽
print(name_list.index('黄忠')) # 4
list[i]取值,list.index('元素')取索引- 列表中取数据可以直接取列表中的值,也可以通过
index()方法取索引
2. 修改数据
name_list = ['关羽','张飞']
name_list[0] = '赵云'
print(name_list) # ['赵云', '张飞']
list[i] = 值
3. 添加数据
#1.insert()
name_list = ['关羽','张飞']
name_list.insert(1,'赵云')
print(name_list) #['关羽', '赵云', '张飞']
#2.append()
name_list = ['关羽','张飞']
name_list.append('赵云')
print(name_list) #['关羽', '张飞', '赵云']
#3.extend()
name_list = ['关羽','张飞']
name_list.extend('赵云') #['关羽', '张飞', '赵', '云']
-
list.inset(位置,值),指定位置插入数据 -
list.append(值),末尾添加一个数据 -
list.extend(序列),末尾追加一串数据append和extend的区别:list1 = [1,2,3] list1.append([4,5]) print(list1) # [1, 2, 3, [4, 5]] list2 = [1,2,3] list2.extend([4,5]) print(list2) # [1, 2, 3, 4, 5]append把加入的数据当成一个元素看,extend把加入的数据拆分成一个一个元素。
4. 删除数据
#1.remove()
name_list = ['关羽','张飞']
name_list.remove('张飞')
print(name_list) # ['关羽']
#2.pop()
name_list = ['关羽','张飞']
name_list.pop()
print(name_list) # ['关羽']
name_list = ['关羽','张飞']
name_list.pop(1)
print(name_list) # ['关羽']
#3.clear
name_list = ['关羽','张飞']
name_list.clear()
print(name_list) # []
list.remove(值),指定删除一个数据,若有重复数据,则删除的是第一个数据list.pop(),默认在末尾删除数据,也可以指定位置删除数据list.clear(),清空列表数据
5. del关键字
name_list = ['关羽','张飞']
del name_list
print(name_list) #NameError: name 'name_list' is not defined
- del 变量,删除变量的内存空间
6. 统计
#1.len()
name_list = ['孙策','孙权','孙权']
l = len(name_list)
print(l) # 3
#2.count()
name_list = ['孙策','孙权','孙权']
c = name_list.count('孙权')
print(c) # 2
len(对象),len()函数统计用来统计总数list.count(),count()函数统计列表中元素出现的次数
7. 列表的遍历
list = [0,1,2,3]
for i in list :
print(i)

- 使用
for...in,顺序的从列表中依次获取数据,在每一次循环中,数据都会保留在临时变量i中
8. 列表的应用场景
- 列表可以存储不同类型的数据,但开发中,更多应用场景是存储相同类型的数据
- 通过迭代遍历,在循环体内部,针对列表中的每一项元素,执行相同的操作
2. 元组
-
tuple(元组)与列表类似,不同之处在于元组不能增删改,只能获取数据(可以说是常量的列表)。 -
元组是是有序的,也有索引。
1. 元组的定义
#定义空元组
t = ()
print(t) #()
#定义一个元组
t = (3,)
print(t) #(3,)
#定义元组
t= (1,2,3,4,5)
print(t) #(1,2,3,4,5)
-
元组用
()定义 -
当元组中只有一个元素时要加,号
2. 元组的常用操作
1. 取数据
t = (1,24,3)
print(t[0]) # 1
print(t.index(24)) # 1
- 可以直接取得元素,也可以取元素的索引
2. 统计
#len()
t = (1,2,3,4)
l = len(t)
print(l) # 4
#count()
t = (1,2,2,2,3)
print(t.count(2)) # 3
3. 元组的遍历
t = (1,2,3,4,5)
for i in t:
print(i)

- 元组中通常保存的数据类型是不同的,所以
for...in遍历需求并不多
4. 列表和元组的相互转换
#tuple()
list1 = [1,2,3]
t1 = tuple(list1)
print(t1) # (1,2,3)
#list()
t2 = (2,4,6)
list2 = list(t2)
print(list2) #[2,4,6]
tuple()函数,将序列转换成tuple类型list()函数,将序列转换成list类型
5.元组的应用场景
- 函数的参数和返回值。一个函数可以接受任意多个参数,或者一次返回多个数据
- 格式化字符串,格式化字符串后面的()本质上就是一个元组
- 让列表不可以被修改,以保护数据安全
- 在实际开发中,除非能确认元组中的数据类型都是一样的,否则针对元组的循环遍历需求并不是很多
3. 字典
-
字典同样可以用来存储多个数据,通常用于存储描述一个物体的相关信息。
-
字典是无序的对象集合。
1. 字典的定义
#定义空字典
d = {}
print(d) # {}
#定义字典
dict = {"name":"周杰伦","age":43,"work":"歌手"}
print(dict) #{'name': '周杰伦', 'age': 43, 'work': '歌手'}
- 字典使用键值对(key:value)存储数据,键值以,分隔
2. 字典的常用操作
1. 取数据
dict = { "name":"赵丽颖",
"age":34}
print(dict["name"]) # 赵丽颖
print(dict['age']) # 34
dict[key]- 取数据时,
[ ]中写入字典的key,得到对应的值
2. 添加数据
dict = { "name":"赵丽颖","age":34}
dict["height"] = 166
print(dict) # {'name': '赵丽颖', 'age': 34, 'height': 166}
dict[key]=value- 添加数据时,若字典中没有相同的
key,则数据在后面添加
3. 修改数据
dict = { "name":"赵丽颖","age":34}
dict['age'] = 18
print(dict) #{'name': '赵丽颖', 'age': 18}
dict[key]=value- 修改数据和添加数据方式本质上是相同的,就看字典中有没有相同的
key,有的话则是修改
4. 删除数据
#1. pop()
dict = { "name":"赵丽颖","age":34,"work":"演员"}
dict.pop('work')
print(dict) # {'name': '赵丽颖', 'age': 34}
#2. clear()
dict = { "name":"赵丽颖","age":34,"work":"演员"}
dict.clear()
print(dict) # {}
dict.pop(key),删除字典中的某个键值对dict.clear(),删除字典中所有键值对
5. 统计
#len()
dict = { "name":"赵丽颖","age":34,"work":"演员"}
l = len(dict)
print(l) # 3
6. 字典的合并
#update()
dict1 = { "name":"赵丽颖","age":34}
dict2 = {"height":165,"work":"演员"}
dict1.update(dict2)
print(dict1) #{'name': '赵丽颖', 'age': 34, 'height': 165, 'work': '演员'}
dict1.uppdate(dict2),表示dict2合并到dict1中- 若dict1字典中有和dict2字典相同的
key,则合并后是合并的数据
7. 字典的遍历
dict = { "name":"赵丽颖","age":34,"work":"演员"}
for k in dict:
print(k)

- 变量
k是每一次循环中,获取到的键值对key - 开发中由于每一个键值对保存的数据类型是不同的,所以针对字典的遍历并不太多
8. 字典的应用场景
info_dict = [
{"name":"赵丽颖",
"age":34,
"work":"演员"},
{"name":"周杰伦",
"age":42,
"work":"歌手"}
]
for i in info_dict:
print(i)
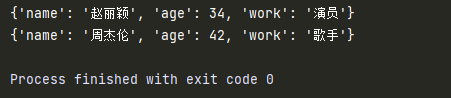
- 开发中,更多的应用场景是使用多个键值对,存储描述一个物体的相关信息
- 将多个字典放在一个列表中,再进行遍历,在循环体内部针对每一个字典进行相同的处理
4.字符串
- 字符串就是一串字符,是编程语言中表示文本的数据类型
1. 字符串的定义
str = 'hello world'
print(str) #hello world
- 后边也可以是
""号
2. 字符串的常用操作
1. 取数据
str = 'hello world'
print(str[0]) # h
print(str.index('l')) # 2
- 使用
index()方法传递的子字符串不存在时,则会报错
2. 统计
#len()
str = 'hello world'
l =len(str)
print(l) # 11
#count()
str = 'hello world'
print(str.count('l')) # 3
3.字符串的判断类型方法
1. 判断是否是空格、空白字符
# isspace()
str = " "
print(str.isspace()) #True
str = " \t\n\r"
print(str.isspace()) # True
2. 判断字符串是否只包含数字
# isdecimal()、isdigit()、isnumeric()
str1 = '1'
str2 = '1.1'
str3 = '\u00n2'
str4 = '(1)'
str5 = '一百一十'
print(str1.isdecimal()) #True
print(str2.isdecimal()) #False
print(str3.isdecimal()) #False
print(str4.isdecimal()) #False
print(str5.isdecimal()) #False
# isdigit() 除了中文数字不行
# isnumeric() 阿拉伯数字,unicode,中文数字都可以判断
isdecimal()、isdigit()、isnumeric()都不能判断小数- 开发中最常用的是
isdecimal()
3. 判断是否以指定字符串开始
# startswith()
str = "hello world"
print(str.startswith('hel')) # True
4. 判断是否以指定字符串结束
# endswith()
str = "hello world"
print(str.endswith('ld')) # True
5. 查找指定位置的子字符串
# index()
str = "hello world"
print(str.index('ell')) # 1
# find()
str = "hello world"
print(str.find('ell')) # 1
- 使用
index()查找子字符串时,不存在则会报错,"ValueError: substring not found" - 使用
find()查找子字符串时,不存在不会报错,返回-1 - 开发中常用
find()查找
6. 替换字符串
# replace()
str = "hello world"
print(str.replace('world','python'))
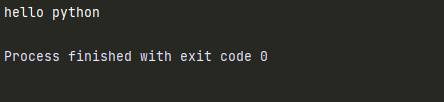
replace(旧子串,新子串)
7. 字符串的文本对齐
# ljust()、rjust()、center()
str=["人","生","苦","短"]
for s in str:
print("|%s|" %s.center(10," "))

ljust(): 左对齐rjust(): 右对齐center(): 居中对齐
8. 去除空白字符
# strip()、lstrip()、rstrip()
str=["\n人","生","苦","短\t"]
for s in str:
print("|%s|" %s.strip().center(10," ")) #去除两边空白并居中对齐

strip(): 去除两边空白lstrip(): 去除前导空白rstrip(): 去除后导空白
9. 字符串的拆分
# split()
str="人生苦短,我用python"
print(str.split()) # ['人生苦短,我用python']
split(): 拆分字符串为一个列表,没有参数默认为以空格分隔。
10. 字符串的连接
# .join()
str = "人生苦短我用python"
print('_'.join(str)) # 人_生_苦_短_我_用_p_y_t_h_o_n
str1 = ['人','生','苦','短']
print('_'.join(str1)) # 人_生_苦_短
join(seq): 将一个序列作为参数转换成字符串。- 用什么作为分隔就用什么来
.join()
11. 字符串切片
# [::]
str = '0123456789'
#2~5
print(str[2:6]) # 2345
#2~末尾
print(str[2:]) # 23456789
#0~5
print(str[:6]) # 012345
#0~9
print(str[::]) # 0123456789
#0~9 隔一个字符取
print(str[::2]) # 02468
#1~9 隔一个字符取
print(str[1::2]) # 13579
#2~8
print(str[2:-1]) # 2345678
#逆序
print(str[::-1]) # 9876543210
[开始索引:结束索引:步长]左闭右开- 切片方法适用于字符串、列表、元组(有索引的数据类型)
- 切片使用索引值来限定范围,从一个大的字符串中切取小的字符串
5.公共方法
公共的内置函数:
#1. len()
str="10086"
print(len(str)) #5
#2.del()
a=[1,2,3]
del a[0]
del(a[1])
#3.max()
b = '1859509'
print(max(b)) # 9
c = [1,8,5,9,5,0,9]
print(max(c)) # 9
d = (1,8,5,9,5,0,9)
print(max(d)) # 9
e={"a":1,"b":8,"c":5}
print(max(e)) # c
#4.min()
b = '1859509'
print(min(b)) # 0
c = [1,8,5,9,5,0,9]
print(min(c)) # 0
d = (1,8,5,9,5,0,9)
print(min(d)) # 0
e={"a":1,"b":8,"c":5}
print(min(e)) # a
#5.cmp() python3中取消了cmp() 直接比较大小
f = [1,1,1]
g = [2,2,2]
print(f<g) # True
f1=(1,1,1)
f2=(2,2,2)
print(f1<f2) # True
f3="abc"
f4="lol"
print(f3 < f4) # True
del删除有两种方式,一种是del关键字,一种是del()函数- python3中取消了
cmp()直接用比较运算符比较大小 - 字典和字典不能比较大小
- 字典不能用切片
# 运算符 + * in not in > >= == <=
# +
a = [1,3,5,7]
b = [2,4,6,8]
print(a + b) # [1, 3, 5, 7, 2, 4, 6, 8]
c = (1,3,5,7)
d = (2,4,6,8)
print(c + d) # (1,3,5,7,2,4,6,8)
# *
a = [0,0,1] *2
print(a) # [0, 0, 1, 0, 0, 1]
b = (0,0,1) *2
print(b) # (0, 0, 1, 0, 0, 1)
# in
a = [0,1]
b = (0,1)
c = "0,1"
d = {"0":"1"}
print(0 in a) True
...
+号与append()的区别:+返回的是一个新的列表,而append()只是在原列表追加
九. 变量的进阶
引用的概念: 在python中,变量和数据是分开存储的,数据保存在内存中的一个位置,变量保存数据在内存中的地址,变量中记录数据的地址,叫做引用。
1.变量的引用
num1 = 10
print(num1,id(num1)) # 10 140722922035136
num2 = num1
print(num2,id(num2)) # 10 140722922035136
num1 = 20
print(num1,id(num1)) # 20 140722922035456
-
num1引用的地址赋值给了num2,num1重新定义时,引用了新的地址。 -
使用
id()函数可以查看变量中存数据所在的内存地址。 -
如果变量已经被定义,当给一个变量赋值的时候,本质上是修改了数据的引用
-
变量改为对新赋值的数据引用
2.函数的参数传递
def test(num):
print(num,id(num)) # 10 140731223480256
a = 10
print(a,id(a)) # 10 140731223480256
test(a)
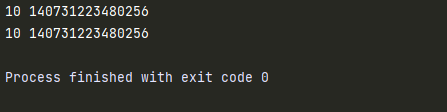
- 调用test()函数,本质上传递的是实参保存数据的引用,而不是实参的数据。
3.函数的返回值传递
def test(num):
str = 'hello'
return str # 31824
a = 10
print(id(a)) # 12416
s = test(a)
print(id(s)) # 31824
- 将字符串变量返回,返回的是数据的引用,而不是数据本身
4.可变和不可变数据类型
可变类型中,内存中的数据可以修改。而不可变类型,内存中的数据不可以修改。
可变数据类型: 列表(list),字典(dict)。
不可变数据类型: 数字类型, 字符串(str),元组(tuple)。
1. 可变类型
list = [1,2,3,4,5]
print(list,id(list)) # [ 1, 2, 3, 4, 5] xxx1440
list.append(6)
print(list,id(list)) # [1, 2, 3, 4, 5, 6] xxx1440
#重新赋值
list = []
print(list,id(list)) # [] xxx8592
- 对数据进行修改不会改变列表变量的引用
- 重新赋值引用的地址就会发生改变
dict = {"name":"关羽","age": 18}
print(dict,id(dict)) # {'name': '关羽', 'age': 18} 4192
dict["name"] = "张飞"
print(dict,id(dict)) # {'name': '张飞', 'age': 18} 4192
#重新赋值
dict = {}
print(dict,id(dict)) # {} 2010639576256
-
对数据进行修改不会改变字典变量的引用
-
重新赋值引用的地址就会发生改变
字典的key只能使用不可变类型,键值对的
value可以是任意类型的数据:#1.数字 a = {} a[1] = "255" print(a) # {1: '255'} #2.元组 b = {} b[(2,)] = "250" print(b) # {(2,): '250'} #3.字符串 c = {} c['name'] = '关羽' # {'name': '关羽'} print(c) #4.列表 d = {} d[[1]] = '99' print(d) #TypeError: unhashable type: 'list' #5.字典 e = {} e[{1}] = '98' print(e) # TypeError: unhashable type: 'set'字典key的底层其实是hash()算法:
a = hash(1) # 地址值 print(a) b = hash(2,) # 地址值 print(a) c = hash("3") # 地址值 print(c) d = hash([4]) # TypeError: unhashable type: 'list' print(d) e = hash({5}) print(e) # TypeError: unhashable type: 'set'
2. 不可变类型
#对字符串进行修改
str1 = '123'
list = list(str)
print(str1) # 123
str2 = str1.replace('3','15')
print(str1) # 123
str3 = '4,5'
new_str = str1[1:]
str4 = str3 + new_str
print(str1) # 123
5.全局变量和局部变量
局部变量是在函数内部定义的变量,只能在函数内部使用。
全局变量是在函数外部定义的变量,所有函数内部都可以使用这个变量。
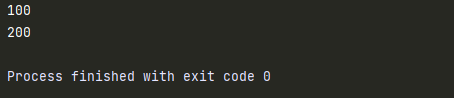
1. 局部变量
def test1():
num = 100
print(num)
def test2():
num = 200
print(num)
test1()
test2()
#print(num) # NameError: name 'num' is not defined
-
局部变量在函数内部定义,不同函数之间定义相同的变量名,互不影响
-
局部变量的作用域范围就是当前的函数,不能在外部使用到
局部变量的生命周期:
def test1(): num = 100 #创建: 在执行第3行代码的时创建 print(num) #消亡: 在函数执行结束后消亡 test1() 函数执行结束,局部变量也随之销毁。
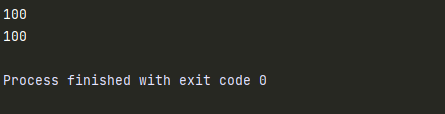
2. 全局变量
num = 100
def test1():
print(num) #100
def test2():
print(num) #100
test1()
test2()
-
所有函数内部都可以使用这个变量
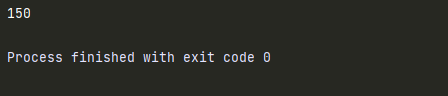
函数处理变量的过程:
1.首先查找函数内部是否存在指定名称的局部变量,如果有,直接用。
2.如果没有,查找函数外部是否存在指定名称的全局变量,如果有,直接用。
num = 100 def test1(): num = 150 print(num) #150 test1()
函数内部修改全局变量:
num = 100
def test1():
global num
num = 99
print(num) #99
test1()
print(num) #99
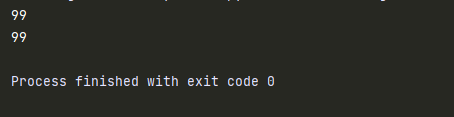
函数内部想要修改全局变量时,要使用到关键字global。
全局变量定义的位置:
num1 = 100
num2 = 200
num3 = 300
def test():
print(num1,num2,num3) # 100 200 300
test()
定义在所有函数的上方。
全局变量起名规则:
gl_num1 = 100
gl_num2 = 200
def test():
num1 = 1
print(num1,gl_num1,gl_num2) #1 100 200
test()
全局变量名前应该加g_或者gl_的前缀。
十. 函数的返回值和参数的进阶
函数参数的使用:函数内部处理的数据无法确定时,就可以根据外界的数据以参数传递到函数内部。
函数返回值的使用: 当一个函数执行完成以后,要向外提供执行结果,就可以增加函数的返回值 。
1. 函数的返回值
# 测量温度和湿度
def measure():
temp = 28
wetness = 15.0
return temp,wetness
#1.单变量
result = measure()
print(result) # (28, 15.0)
#处理返回的数据
print(result[0])
print(result[1])
#2.多变量
gl_temp,gl_wetness = measure()
print(gl_temp) # 28
print(gl_wetness) # 15.0
-
函数的返回值,其实就是元组的形式
-
可以使用多变量,一次的接收函数返回的结果
-
变量的个数和元组的个数保持一致
python中交换两个数字的应用:
# 1.使用临时变量 a = 20 b = 10 temp = a a = b b = temp print(a,b) # 10,20 #2.不使用临时变量 a = a + b # a 20+10 b = a - b # b 30-10 a = a - b # a 30-20 print(a,b) # 10,20 #3.利用元组(python特有) a,b = b,a print(a,b) # 10,20
2. 函数的参数
gl_num = 100
gl_list = [1,2,3]
def test(num,list):
num = 10
list = [2,4,6]
print(num,list)
test(gl_num,gl_list) #10 [2,4,6]
print(gl_num,gl_list) #100 [1,2,3]
-
在函数内部,针对参数赋值,不会影响实参变量。
-
无论传递的参数是可变还是不可变,都不会影响。
但是,如果参数是可变类型,在函数内部,使用方法修改了数据内容,会影响到外部的数据:
gl_list = [1,2,3] def test(list): list.append(99) print(list) test(gl_list) #[1, 2, 3, 99] print(gl_list) #[1, 2, 3, 99]对于可变类型的
+=号不是赋值操作,相当于extend()方法:gl_num = 1 gl_list = [1,2,3] def test(num,list): #不可变类型的 +=是赋值 num += num list += list #可变类型的+=: 相当于 list.extend(list) print(num,list) test(gl_num,gl_list) # 2 [1,2,3,1,2,3] print(gl_num,gl_list) # 1 [1,2,3,1,2,3]所以,如果参数是可变类型,在函数内部使用方法,外部的数据会受到影响。
3. 函数的缺省值
定义函数时,可以给某个参数指定一个默认值,具有默认值的参数就叫做缺省参数。
def test(name,sex=True):
student = '男'
if not sex :
student = '女'
print(f'{name}是{student}')
test('小明') # 小明是男
test('小王',False) # 小王是女
sex为缺省参数,默认是True(男)- 在定义缺省参数时,应该使用最常见的值作为默认值
缺省参数的注意事项:
def test(name,title="",sex=True):
student = '男'
if not sex :
student = '女'
print(f'{title}:{name}是{student}')
test('小明') # :小明是男
test('小王',sex=False) # :小王是女
-
缺省参数放在参数列表的末尾
-
调用函数时,有多个缺省参数,需要指定参数名
接触过的缺省参数:
list = [2,1,3] list.sort() print(list) # [1,2,3] list.sort(reverse=True) print(list) # [3,2,1]
4. 函数的多值参数
当函数能够处理的参数个数不确定时,可以使用多值参数。
多指参数的定义:
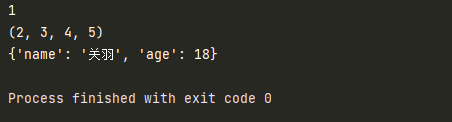
def test(num,*tup,**person):
print(num)
print(tup)
print(person)
test(1,2,3,4,5,name="关羽",age=18)
- 一个* 表示可以接收元组
- 两个* 表示可以接收字典
- 一般命名用
*arge,**kwargs
多值参数的应用:
# 累加
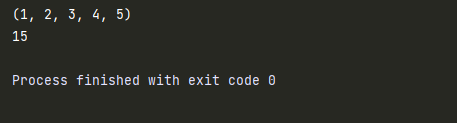
def test(*args):
num = 0
print(args)
for i in args :
num += i
return num
result = test(1,2,3,4,5)
print(result)
- 如果不用
*args代表多值参数接收的是元组,则要在调用的时候加括号。
多值参数的拆包:
a = (1,2,3)
b = {"name":"关羽","age":18}
def test(*args,**kwargs):
print(args)
print(kwargs)
#1.使用拆包
test(*a,**b) # (1,2,3) {'name': '关羽', 'age': 18}
#2.不使用拆包
test(a,b) # (1,2,3,{'name': '关羽', 'age': 18}) {}
- 将一个元组变量传递给
args,字典变量传递给kwargs。 - 使用拆包简化了参数的传递
- 如果不使用拆包,默认多值参数是
*args
5. 函数的递归
函数内部可以调用其他函数,也可以调用自己,一个函数调用自身称为递归。
递归语法:
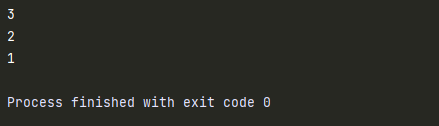
def test(num):
print(num)
if num == 1: #递归的出口(判断)
return
test(num-1) #调自身
test(3)
- 函数内部的代码是相同的,只是针对参数不同,处理的结果不同。
- 当参数满足一个条件时,函数不再执行。
- 一定要针对参数进行判断,这样递归才有意义。
利用递归求和:
#计算1+2+3...num的结果
def test(num):
if num == 1:
return 1
temp = test(num-1)
return temp + num
result = test(3)
print(result) #6
十一. 面向对象
1. 类
类是对一群具有相同特征或行为的事务的一个统称,是抽象的。
特征被称为属性,行为被称为方法。
类就相当于是制造飞机时的图纸,是一个模板,是负责创建对象的。
2. 对象
对象是由类创建出来的一个具体存在。
由哪一个类创建出来的对象,就拥有哪一个类中定义的属性和方法。
对象就相当于用图纸制造出来的飞机。
3. 类和对象的关系
类是模板,对象是根据类这个模板创建出来的,应该先有类再有对象。
类只有一个,而对象可以有很多个。
类中定义了什么属性和方法,对象就有什么属性和方法。
(一)面向对象的基本概念
1.在完成某一个需求前,首先确定职责。
2.根据职责确定不同的对象,在对象内部封装不同的方法。
3.最后完成的代码,就是顺序的让不同的对象调用不同的方法。
- 特点: 注重对象和职责,不同的对象承担不同的职责
1. 对象的创建
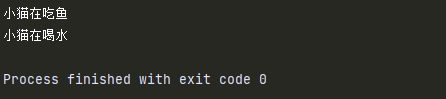
class Cat():
def eat(self):
print('小猫在吃鱼')
def drink(self):
print('小猫在喝水')
c = Cat()
c.eat() # 小猫在吃鱼
c.drink() # 小猫在喝水
- 对象创建后,就能够使用类中定义的属性和方法
对象可以有多个:
class Cat():
def eat(self):
print('小猫在吃鱼')
def drink(self):
print('小猫在喝水')
#猫1
cat1 = Cat()
cat1.eat()
cat1.drink()
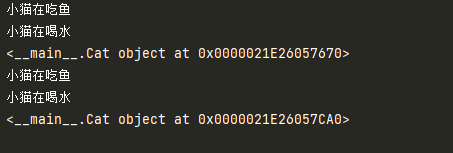
print(cat1)
#猫2
cat2 = Cat()
cat2.eat()
cat2.drink()
print(cat2)
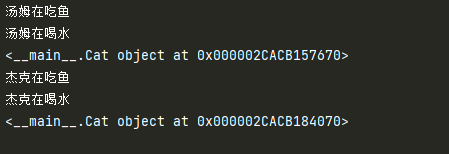
设置对象的属性:
class Cat():
def eat(self):
print('%s在吃鱼' %self.name)
def drink(self):
print('%s在喝水' %self.name)
cat1 = Cat()
cat1.name = '汤姆' #
cat1.eat()
cat1.drink()
print(cat1)
cat2 = Cat()
cat2.name = '杰克' #
cat2.eat()
cat2.drink()
print(cat2)
self表示当前对象- 哪一个对象调用的,
self就是哪一个对象的引用 - 对象属性应该封装在类的内部
2. 类的内置方法
当使用类名()创建对象时,会自动执行以下操作:
1.为对象在内存中分配空间(创建对象)。
2.为对象的属性设置初始值(初始化方法)。
1. 初始化方法
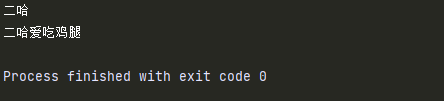
使用类()创建对象,会自动调用初始化方法__init__()
__init()__方法:
class Dog():
def __init__(self,name): # 定义一个形参,接收外部传进来的数据
self.name = name
def eat(self):
print('%s爱吃鸡腿' %self.name)
dog = Dog('二哈') # 创建对象时,设置属性传递给函数
print(dog.name)
dog.eat()
self.属性名 = 属性值,定义属性
2. 对象的销毁
当一个对象被从内存中销毁前,会自动调用__del__()方法。
__del__()方法:
class Dog():
def __init__(self,name):
self.name = name
print('%s出生了'%self.name)
def __del__(self):
print("%s离开了"%self.name)
dog = Dog('二狗')
print('------------')
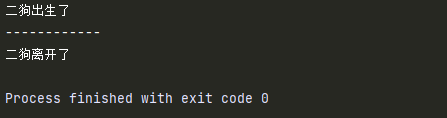
-
如果希望在对象被销毁前,再做一些事情,可以使用一下
__del__()方法 -
一个对象从调用类名
()创建时,生命周期开始 -
一个对象的
__del__()方法一旦被调用,生命周期结束
3. 输出对象变量
想要修改print()输出对象变量的内容时,定义__str__()。
__str()__方法:
class Dog():
def __init__(self,name):
self.name = name
print('%s出生了' %self.name)
def __del__(self):
print("%s消亡了" %self.name)
def __str__(self):
return '[%s]是真的狗' %self.name
dog = Dog('二狗')
print(dog)
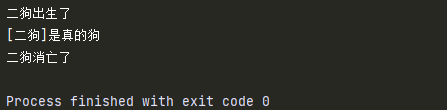
__str__()必须返回的是字符串- 若没有定义
__str__(),当print对象时,输出的是对象的信息以及对象的地址
(二).面向对象的三大特性
面向对象的三大特性: 封装、继承、多态。
封装: 根据职责将属性和方法封装到一个抽象的类中继承: 实现代码的复用,相同的代码不需重复的编写,提升效率多态: 不同的对象调用相同的方法,产生不同的执行结果,增加代码的灵活度
1.封装
-
封装是面向对象编程的一大特性
-
所谓封装,就是将属性和方法封装到一个类中
-
外界使用类创建对象,然后让对象调用方法
-
对象方法的细节都被封装在类的内部
class Person():
def __init__(self,name,weight):
self.name = name
self.weight = weight
def __str__(self):
return f'{self.name},体重{self.weight}kg'
def run(self):
print(f'{self.name}开始跑步,体重减少了1kg')
self.weight -= 1
def eat(self):
print(f'{self.name}开始吃东西,体重增加了0.5kg')
self.weight += 0.5
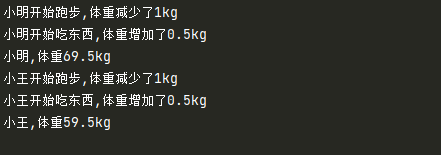
xiaoming = Person('小明',70)
xiaoming.run()
xiaoming.eat()
print(xiaoming)
xiaowang = Person('小王',60)
xiaowang.run()
xiaowang.eat()
print(xiaowang)
- 对象的属性、跑步和吃的方法细节都封装在了类的内部
- 在外界直接用对象调用类中的属性、方法
1. 封装的案例
(1)摆放家具
- 需求分析
1.房子(House)有户型,总面积和家具名称列表
2.家具(HouseItem)有家具名称和占地面积
3.将家具添加到房子中
4.打印房子: 户型、总面积、剩余面积、家具名称列表
#1.定义家具类
class HouseItem():
#属性: 家具名称 占地面积
def __init__(self,name,area):
self.name = name
self.area = area
def __str__(self):
return f'[{self.name}] 占地面积: {self.area}'
#2.定义房子类
class House():
#属性: 户型 总面积 剩余面积 家具列表
def __init__(self,house_type,area):
self.house_type = house_type
self.area = area
self.free_area = area
self.item_list = []
def __str__(self):
return f'户型: [{self.house_type}],总面积: {self.area},剩余面积: {self.free_area}'
# 添加家具的方法
def add_item(self,item):
print(f'要添加的家具是{item}')
#1. 判断家具面积
if item.area > self.free_area :
print(f'{item.name}面积过大,该房子无法容纳')
return
#2. 将家具添加到家具列表
self.item_list.append(item.name)
#3. 计算剩余房子面积
self.free_area -= item.area
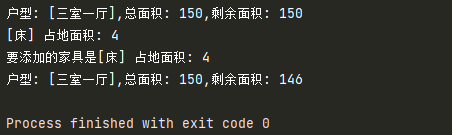
house1 = House('三室一厅',150)
print(house1)
bed = HouseItem('床',4)
print(bed)
#房子对象调用添加家具方法,家具对象作为参数传递给item
house1.add_item(bed)
print(house1)
- 主程序只负责创建房子对象和家具对象
- 让房子对象调用
add_item()方法将家具添加到房子中 - 面积计算、剩余面积、家具列表等处理都被封装到房子类的内部
(2)士兵射击:
- 需求分析
1.士兵有一把ak47
2.士兵可以开火
3.枪能发射子弹
4.枪能装填子弹
#1.定义枪类
class Gun():
# 属性: 枪种类 子弹数
def __init__(self,model):
self.model = model
self.bullet_count = 0
# 装填子弹
def add_bullet(self,count):
self.bullet_count += count
# 发射子弹
def shoot(self):
# 判断子弹数 < 0
if self.bullet_count < 0:
print(f'{self.model}子弹数量不足')
return
self.bullet_count -= 1
print(f'{self.model}突突突...子弹数量: {self.bullet_count}')
#2.定义士兵类
class Solder():
# 属性: 名字 枪
def __init__(self,name):
self.name = name
self.gun = None
# 射击
def fire(self):
# 判断是否有枪
if self.gun is None :
print(f'{self.name}的枪为{self.gun},不能开火')
print(f'{self.name}: 开火')
self.gun.add_bullet(10)
self.gun.shoot()
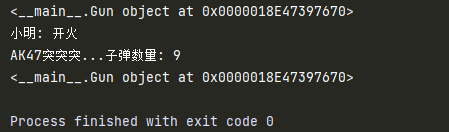
ak = Gun('AK47')
print(ak)
xiaoming = Solder('小明')
# 一个对象的属性可以是另一个类创建的对象
xiaoming.gun = ak
xiaoming.fire()
print(xiaoming.gun)
-
在这个案例中,装填子弹、发动射击这个动作是由士兵来完成的,而这两个动作是枪类里封装的方法,士兵类如何使用到枪类封装的方法呢?
让枪类创建的对象作为士兵的属性,这个属性就拥有了枪类里边封装的属性和方法,这样就可以在士兵类里面使用枪属性.方法了。(可以把这个属性看成是对象,对象拥有类里边封装的属性和方法) -
None关键字,是一个特殊的常量,表示什么都没有。 -
可以将
None赋值给任何一个变量python中的身份运算符:
is、is notx = [1, 2, 3] y = [1, 2, 3] print( x is y) # False print( x == y) # Trueis 和 == 的区别: 1. is用于判断两个变量引用对象是否为同一个 2. ==用于判断值是否相等
2. 私有属性和私有方法
定义私有属性和私有方法: __属性名/__方法名
class Women():
def __init__(self,name):
self.name = name
#私有属性
self.__age = 18
def secret(self):
#对象方法内部
print(f'{self.name}的年龄是{self.__age}')
#私有方法
def __secret(self):
print(f'{self.name}的年龄是{self.__age}')
xiaohong = Women('小红')
print(xiaohong.name) # 小红
print(xiaohong.__age) # AttributeError: 'Women' object has no attribute
xiaohong.secret() # 小红的年龄是18
xiaogong.__secret() # name 'xiaogong' is not defined
- 私有属性和私有方法不对外暴露,外部不能直接进行访问
- 在对象的方法内部,是可以直接访问对象的私有属性的
2.继承
-
拥有父类封装的所有属性和方法(传递性)
-
可以直接使用父类中已经封装好的属性/方法
-
子类可以对父类的方法进行重写
1. 继承的使用
class Animal:
def eat(self):
print('吃')
def sleep(self):
print('睡')
#鸟类继承动物类
class Bird(Animal):
def fly(self):
print('飞')
animal = Animal()
animal.eat()
animal.sleep()
print('-----------')
bird = Bird()
bird.fly()
bird.eat()
bird.sleep()

-
子类可以有自己独有的属性和方法
-
继承父类后,子类拥有了父类的所有属性和方法
2. 方法的重写
class Animal:
def eat(self):
print('吃')
def run(self):
print('跑')
def sleep(self):
print('睡')
class Dog(Animal):
def bark(self):
print('汪汪叫')
class Goutou(Dog):
def eat(self):
print('狗头: 吃兵叠Q')
def bark(self):
print('狗头: 软弱无力')
def run(self):
super().run()
print('狗头开的是疾跑')
print('#@$%#@##$%$#')
goutou = Goutou()
goutou.eat()
goutou.bark()
goutou.run()
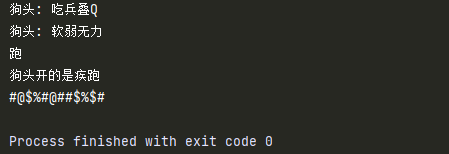
-
子类重写父类的方法时,若和方法实现的完全不同,使用的是覆盖的方式,调用的是子类重写的方法
-
子类重写父类方法时,若父类原来封装的方法实现是子类方法的一部分,使用的是扩展的方式
-
要对重写的方法进行扩展时,使用
super().父类方法。关于
super:super()是super类创建出来的对象一般使用场景就是在重写父类方法时,用
super()来调用父类中封装的方法
3. 访问父类的私有方法和属性
class A:
def __init__(self):
self.num1 = 100
self.__num2 = 200
def __test(self):
print('这是一个私有方法')
class B(A):
def demo(self):
self.__test() # AttributeError: 'B' object has no attribute '_B__test'
pass
b = B()
print(b.num1) # 100
print(b.__num2) # AttributeError: 'B' object has no attribute '__num2'
b.__test() # AttributeError: 'B' object has no attribute '__test'
-
子类对象在外部不能访问父类中的私有属性和私有方法
-
子类对象方法中不能访问父类的私有属性以和私有方法
4. 访问父类的公有方法和属性
class A:
def __init__(self):
self.num1 = 100
self.__num2 = 200
def __test(self):
print('父类的私有方法')
def test(self):
print('父类的公有方法:%d' %self.__num2)
self.__test()
class B(A):
def demo(self):
self.test()
b = B()
b.test()
print(b.num1)
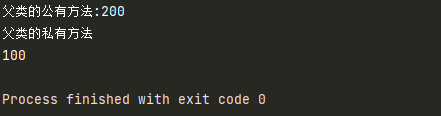
- 子类对象可以通过父类的公有方法间接访问到私有属性和私有方法
5. 多继承
- 在python中,可以使用多继承,一个子类可以继承多个父类
class A:
def test1(self):
print('类A的方法')
class B:
def test2(self):
print('类B的方法')
class C(B,A):
pass
c = C()
c.test1() # 类A的方法
c.test2() # 类B的方法
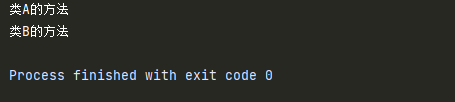
- 子类拥有各个父类中的属性和方法
多继承使用注意事项:
class A:
def test(self):
print('类A的方法')
class B:
def test(self):
print('类B中的方法')
class C(B,A):
pass
c = C()
c.test()
c.test()
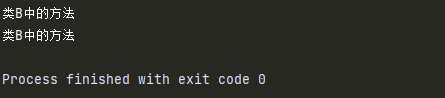
-
如果不同的父类中存在同名的属性或方法,子类对象在调用方法时,产生
混淆 -
如果父类之间存在这同名的属性或方法,这时应该避免使用多继承
__mro__的应用:在搜索方法时,是按照
__mro__的输出结果从左到右的顺序查找的,直到找到基类。class A: def test1(self): print('类A的方法') class B: def test2(self): print('类B中的方法') class C(B,A): pass c = C() c.test1() # 类A的方法 c.test2() # 类B的方法 print(C.__mro__)

确定C类对象调用方法的顺序(先从自身查找,再到父类,再到基类)
6. 新式类和旧式类
# 1.旧式类
class A:
def test(self):
print('旧式类')
pass
pass
a = A()
# 2.新式类
class A(object):
def test(self):
print('新式类')
pass
pass
a = A()
print(dir(a)) #[...,'__str__', '__subclasshook__', '__weakref__', 'test']
object是python中所有对象提供的基类,提供有一些内置的属性和方法,可以使用dir()查看。- 在python2.x中定义类时,如果没有指定父类,则不会以
object作为基类。 - 定义类时,使用第二种定义方式最佳。
3.多态
- 不同的子类对象调用相同的父类方法,产生不同的执行结果
- 多态可以增加代码的灵活度
1. 多态的使用
class Person(object):
def __init__(self,name):
self.name = name
def work(self):
print(f'{self.name}在工作中实现自我价值')
class Programmer(Person):
def work(self):
print(f'{self.name}的工作是写代码')
class Tercher(Person):
def work(self):
print(f'{self.name}的工作是教书育人')
p1 = Programmer('程序员')
p1.work() # 程序员的工作是写代码
t1 = Tercher('老师')
t1.work() # 老师的工作是教书育人
- 程序员类和老师类都继承同一个类(人类),拥有人类的
name属性和work()方法 - 都调用父类相同的
work()方法,实现的却结果并不同 - 多态: 不同的子类对象调用相同的父类方法,实现的结果不同
- 前提: 多态是以继承和重写父类方法下为前提
2. 类属性和实例属性
class Tools(object):
count = 0 #类属性
def __init__(self,name):
self.name = name #实例属性
Tools.count += 1
tools1 = Tools('锅')
tools2 = Tools('碗')
tools3 = Tools('瓢')
tools4 = Tools('盆')
print(Tools.count) # 4
-
定义的count类属性记录了这个类创建了多少个实例(对象)
-
类属性: 用来记录与这个类相关的特征
-
实例属性: 对象的属性叫做实例属性
-
访问类属性: 使用
类名.属性名的方式使用对象名访问类属性:
class Tools(object): count = 0 #类属性 def __init__(self,name): self.name = name #实例属性 Tools.count += 1 tools1 = Tools('锅') tools2 = Tools('碗') tools3 = Tools('瓢') tools4 = Tools('盆') tools3.count = 99 print(tools3.count) # 99使用对象.类属性 = 值 赋值语句,只会给该对象添加一个实例属性,而不会影响到类属性的值。 所以开发中要访问类的属性,使用类名.属性的方式。
3. 类方法
class Tools(object):
# 类属性
count = 0
def __init__(self,name):
self.name = name
Tools.count += 1
# 定义类方法
@classmethod
def show_tools_count(cls):
print(f'这个类中的工具对象数量是{cls.count}')
t1 = Tools('扫把')
t2 = Tools('拖把')
Tools.show_tools_count() # 这个类中的工具对象数量是2
-
定义类方法: 在方法上面加
@classmethod修饰器,指定cls作为参数 -
使用类方法:
类名.方法名来调用类的方法 -
cls就是类的对象,可以把类看成是一个特殊的对象(非具体对象) -
通过
类名.类方法调用方法时,不需要传递cls参数(和self参数相似)
4. 静态方法
class Dog(object):
@staticmethod
def run(): # 这个方法中无实例属性,无实例方法
print('跑')
Dog.run() #跑 调用时,也无需创建对象
- 定义静态方法: 在方法上方加
@staticmethod修饰器 - 当某个方法不需要访问到实例属性/类属性或方法,就可以定义成静态方法
- 静态方法
()小括号不用定义参数 - 使用静态方法: 使用
类名.方法名
方法的综合案例:
"""
1.设计一个Game类
2.属性:
定义一个类属性total_count记录游戏的历史最高分
定义一个实例属性player_game记录当前玩家姓名
3.方法:
静态方法help()获取游戏帮助信息
类方法record()获取游戏最高分
实例方法play()开始玩游戏
4.主程序步骤:1.查看帮助信息-->2.查看历史最高分-->3.创建游戏对象,开始游戏
"""
class Game(object):
# 类属性
total_count = 999
def __init__(self,name):
self.player_name = name
# 类方法
@classmethod
def record(cls):
print(f'游戏最高分: {Game.total_count}')
# 静态方法
@staticmethod
def help():
print('游戏帮助: 1.种向日葵获取金币 2.使用金币购买工具 3.用工具抵御僵尸入侵')
# 实例方法
def play(self):
print(f'{self.player_name}开始了[游戏大战僵尸]')
Game.record()
Game.help()
p1 = Game('小明')
p1.play()
- 调用
record(),help()使用类名.方法名,无需使用到对象就可以调用
十二. 设计模式
不同的解决问题就有不同的套路,设计模式就是为了总结解决某问题而来的套路。
设计模式是前人工作的总结和提炼,通常,被人们广泛流传的设计模式都是针对某一特定问题的成熟的解。
使用设计模式是为了可重用代码、让代码更容易被他人理解,保证代码可靠性。
1. new方法
使用类名()创建对象时,python的解释器首先会调用__new__()方法为对象分配空间
class MusicPlayer(object):
def __new__(cls, *args, **kwargs):
print('为对象m 在内存中分配空间')
# 1.为对象分配空间
instans = super().__new__(cls)
# 2.返回对象引用
return instans
def __init__(self):
print('对m对象进行初始化')
m = MusicPlayer()
print(m)
-
使用类名
()创建对象时,python的解释器首先会调用__new__()方法为对象分配空间 -
__new__()在内存中为对象分配空间,返回instans引用 传递给__init__()的self参数 -
这样
__init__()就会接收到返回过来的对象引用,对象就能进行初始化了 -
重写
__new__()方法一定要return super().__new__(cls)
2. 单例设计模式
-
让类创建的对象,在内存中只有唯一的一个实例
-
每一次执行类名
()返回的对象,内存地址是相同的应用场景: 音乐播放的对象、回收站、打印机对象等
class MusicPlayer(object):
instance = None
def __new__(cls, *args, **kwargs):
# 1.判断对象是否为None
if cls.instance is None :
# 2.调用__new__()方法,让类属性记录对象的引用
cls.instance = super().__new__(cls)
# 3.返回对象的引用
return cls.instance
def __init__(self):
print('对象初始化')
m1 = MusicPlayer()
print(m1) # 100970
m2 = MusicPlayer() # 100970
print(m2)
-
定义一个类属性,初始值是
None,用于记录单例对象的引用 -
重写
__new__()方法 -
返回对象的引用
初始化动作只执行一次:
class MusicPlayer(object):
instance = None
# 标记是否执行初始化动作
init_flag = False
def __new__(cls, *args, **kwargs):
if cls.instance is None :
cls.instance = super().__new__(cls)
return cls.instance
def __init__(self):
# 1.判断是否执行初始化动作
if MusicPlayer.init_flag :
return
# 2.执行初始化动作
print('初始化播放器')
# 3.将标记改为True
MusicPlayer.init_flag = True
m1 = MusicPlayer()
print(m1)
m2 = MusicPlayer()
print(m2)
再次调用__init__()方法时,初始化动作就不会被再次执行了
十三. 异常处理
异常的的概念: 程序在运行时,如果python解释器遇到一个错误,会停止程序并提示一些错误信息。
程序停止执行并且提示错误信息这个动作,我们通常称之为:抛出(raise)异常。
通过异常捕获可以针对突发事件做集中的处理,从而保证程序的稳定性和健壮性。
1.异常的基本语法
1.简单的异常捕获
try:
ipt = int(input('请输入一个整数: '))
except:
print('请确定输入的是一个整数')

- 可能出现错误的代码放到
try块中 - 错误处理的代码放到
except块中
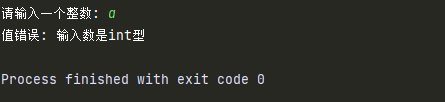
2.捕获的错误类型
try:
num = int(input('请输入一个整数: '))
result = 8 / num
print(result)
# 错误类型1
except ValueError:
print('值错误: 输入数是int型')
# 错误类型2
except ZeroDivisionError:
print('除0错误: 分母不能为0')
3.捕获未知错误
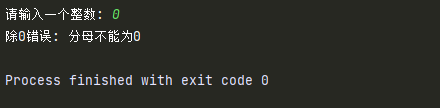
try:
num = int(input('请输入一个整数: '))
result = 8 / num
print(result)
except ValueError:
print('值错误: 输入的数必须是int类型')
except ZeroDivisionError:
print('除0错误: 分母不能为0')
except Exception as result:
print(f'未知错误{result}')
- 在开发时,要预判到所有可能出现的错误,还是有一定难度的
- 如果希望程序无论出现任何错误,都不会因为python解释器抛出异常而被终止,可以再增加一个
excep Exception as result
4.异常捕获的完整语法
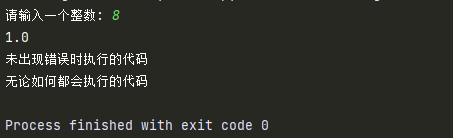
try:
num = int(input('请输入一个整数: '))
result = 8 / num
print(result)
except ValueError:
print('值错误: 输入的数必须是int类型')
except ZeroDivisionError:
print('除0错误: 分母不能为0')
except Exception as result:
print('未知错误%s' %result)
else:
print('未出现错误时执行的代码')
finally:
print('无论如何都会执行的代码')
-
错误类型可以一次写多个,使用
,号分隔 -
else块: 没有异常时执行的代码 -
finally块: 无论如何都会执行的代码
2.异常的传递性
当函数/方法执行出现异常,会将异常向上传递给调用一方。如果传递到主程序仍然没有异常处理,程序才会被终止。
def test1():
num = int(input('请输入一个整数: '))
return num
def test2():
return test1()
try:
print(test2())
except Exception as result:
print('未知错误: %s' %result)

-
利用异常的传递性,在主程序中捕获异常
-
这样就不需要在各个函数中都加上异常捕获的代码,保证了代码的整洁
3. raise抛出异常
除了代码执行出错python解释器会自动抛出异常之外,我们如何根据特有的业务需求主动抛出异常?
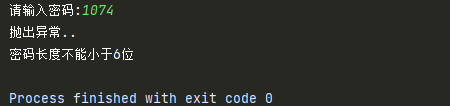
def test():
password = input('请输入密码:')
if len(password) >= 6:
return password
print('抛出异常..')
# 1.创建异常对象(可以使用错误信息字符串作为参数)
e = Exception('密码长度不能小于6位')
# 2.使用raise关键字主动抛出异常对象
raise e
try:
print(test())
except Exception as result:
# 3.输出错误信息
print(result)
- 创建异常对象
Exception(),使用raise将此对象抛出
十四. 模块和包
1. 模块(Module)
-
模块是python程序架构的一个核心概念
-
每一个以扩展名
.py结尾的Python源代码文件都是一个模块 -
模块名同样也算一个标识符,需要符合标识符的命名规范
-
在模块中定义的全局变量,函数,类都是提供给外界直接使用的工具
-
模块就好比是工具包,要想使用这个工具包中的工具,就需要先导入这个模块
1. import导入模块
1.import的使用
# 1.导入模块
import module01
import module02
# 2.使用模块中的全局变量
print(module01.temp)
print(module02.temp)
# 3.使用模块中的函数
module01.test()
module02.test()
# 4.使用模块中的类
dog = module01.Dog()
print(dog)
cat = module02.Dog()
print(cat)
-
使用
import 模块名导入模块 -
导入模块后,就能够使用到模块中的工具
-
使用
import 模块名,是一次性把模块中的所有工具全部导入
2.import模块起别名:
import module01 as Md1
import module02 as Md2
-
如果模块名太长,使用
as指定模块的别名 -
模块别名应符合大驼峰命名
2. from…import导入模块
1.from…import的使用
from module01 import Dog
from module02 import Cat
dog = Dog()
print(dog)
cat = Cat()
print(cat)
-
如果希望从某一个模块中,导入部分工具,就可以使用
from...import的方式 -
使用时,就不需要使用
模块名.工具名的方式了from...import注意事项: 两个模块导入的工具名相同时,则会执行后导入的模块
from module01 import test from module02 import test test()解决办法:
给工具名起上别名
from md_01_module01 import test as Md1_test() from md_02_module02 import test test() Md1_test()from...import一次导入全部工具:from module01 import * from module02 import *这种方式不推荐使用,因为多个模块中如果出现了同名的函数,并没有任何提示
模块的搜索顺序:
python的解释器在导入模块时:
1.搜索当前目录指定模块的文件,如果有就直接导入
2.如果没有,再搜索系统目录
import random
print(random.__file__) # C:\Program Files\Python38\lib\random.py
rand = random.randint(0,5)
print(rand)
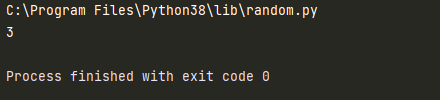
-
__file__内置函数: 查看模块的完整路径 -
如果当前目录下存在一个
random.py的文件,则程序的运行就会出现问题。 -
给文件起名,不要和系统的模块文件重名
3. 测试模块
1.测试模块的使用
def test():
print('you are best')
if __name__ == "__main__":
# 要测试的代码
print(__name__)
test()
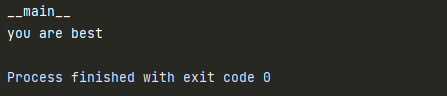
__name__属性可以做到,测试模块的代码只在测试情况下被运行,而被导入时不会被执行__name__是python中的内置属性,记录着一个字符串- 若在当前模块下执行,则
__name__的结果是__main__
2.测试模块规范写法
def test():
print('you are best')
# 要测试的代码写到main()函数中
def main():
print(__name__)
test()
pass
if __name__ == "__main__":
# 调用
main()
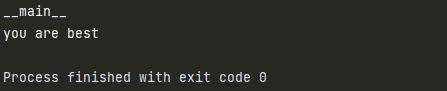
2.包(Package)
- 包是一个包含多个模块得到特殊目录
- 包的目录下有一个特殊的文件
__init__.py - 包的起名方式和变量名一样
1.__init__.py文件
# 从当前模块(包)导入模块列表(希望外界使用到的模块)
from . import module01
from . import module02
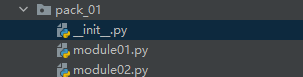
pack_01包中将外界要使用到的模块打包到__init__.py中
import pack_01
pack_01.module01.send('10086')
txt = pack_01.module02.recive()
print(txt)
- 这样在其他模块中导入包(
pack_01),就能使用到包(pack_01)下的模块列表了
3.模块发布
如果希望自己开发的模块,分享给其他人,就可以使用模块发布
1.模块发布的具体步骤
1.创建setup.py
from distutils.core import setup
#字典多值参数
setup(name="C", #包名
version="1.0", #版本
description="PanCc's 发送和接收消息模块", #描述信息
long_description="完整的发送和接收消息模块", #完整描述信息
author="PanCc", #作者
author_email="PanCc@PanCc.com", #作者邮箱
url="www.PanCc.com", #主页
py_modules=["pack_01.modole01", #指定压缩包中包含的模块名称
"pack_01.modole02"])
2.构建模块
python3 setup.py build # 得到准备文件
3.生成发布压缩包
python3 setup.py sdist # 得到要发布模块的压缩包文件
4.安装模块
tar -zxvf pack_01-1.0.tar.gz # 解压缩
sudo python3 setup.py install # 安装setup.py
- 别人拿到了我们分享出去的模块后,进行解压缩
- 安装该模块到自己的python环境中
- 然后就可以
import导入该模块了
5.卸载模块
(1).在ipython3中:
import pack_01
pack_01.__file__ # 找到这个模块的完整路径
(2).到路径下:
sudo rm -r pack_01
sudo rm -r pack_01-1.0.egg-info # 把安装过得模块从系统删除
6.安装第三方模块
# python2.x环境
sudo pip2 install pygame
# python3.x环境
sudo pip3 install pygame
# 在Mac下安装ipython
sudo pip install ipython
# 在linux下安装ipython
sudo apt install ipython
pip是一个现代的,通用的python包管理工具- 提供了对python包的查找、下载、安装、卸载等功能
十五. 文件操作
1.文件的概念: 计算机的文件,就是用来存储在磁盘上的数据。
2.文件的作用: 将数据长期保存下来,在需要的时候使用。
3.cpu获得磁盘中的文件方式: 将磁盘上的文件加载到内存中。
4.文件的存储方式: 在计算机中,文件以二进制的方式保存在磁盘上。
(一).文件的分类
1.文本文件
- 可以使用文本编辑器查看的文件,本质上还是二进制文件,例如python中的源程序
2.二进制文件
-
保存的内容是不可以直接阅读的,而是要提供给其他软件使用的
-
二进制文件不能使用文本编辑器查看
-
例如图片文件、音频文件、视频文件
(二).文件的基本操作
1.打开文件
2.读、写文件
- 读文件: 将文件内容读入内存
- 写文件: 将文件内容写入文件(写入磁盘)
3.关闭文件
(三).操作文件的函数/方法
| 函数/方法 | 描述 |
|---|---|
| open() | 打开文件,并且返回文件操作对象 |
| read() | 将文件内容读取到内容 |
| write() | 将指定内容写入到文件 |
| close() | 关闭文件 |
1.文件的基本操作
1.读取文件
# 1.打开文件
file = open('README01',encoding='utf-8')
# 2.读取文件
text = file.read()
print(text)
# 3.关闭文件
file.close()
open()函数返回一个文件操作对象- 用文件操作对象调用
read()方法 - 打开方式默认是
r
2.读取文件指针位置
file = open('README02',encoding='utf-8')
# 1.第一次读取
text = file.read()
print(text)
print(len(text))
print('------')
# 2.第二次读取
text = file.read()
print(text)
print(len(text))
file.close()
- 第一次打开文件时,通常文件指针指向文件的开始位置
- 当执行了
read()方法后,文件指针会移动到读取内容的末尾 - 第一次读取之后,文件指针移动到了文件末尾,再次调用不会读取到任何内容
3.逐行读取文件
file = open('README03',encoding='utf-8')
text = file.readline()
print(text)
file.close()
readline()方法可以一次读取一行内容readline()方法执行后,会把文件指针移动到下一行,准备再次读取
使用readline()读取文件的完整内容:
file = open('README03',encoding='utf-8')
while True:
text = file.readline()
print(text,end='')
if not text:
break
file.close()
- 加入
while循环,若指针指到下一个位置,没有内容,则跳出循环
4.写入文件
# 1.打开文件
file = open('README02','w',encoding='utf-8')
# 2.写入文件
file.write('断剑重铸之日,骑士归来之时')
# 3.关闭文件
file.close()
open()函数返回一个文件操作对象w指定文件可写入- 用文件操作对象调用
write()
5.文件的访问方式
| 访问方式 | 描述 |
|---|---|
| r | 以只读方式打开文件,文件的指针会放在文件的开头,默认模式,如文件不存在,抛出异常 |
| w | 以只写方式打开文件,如果文件存在则覆盖,不存在则创建 |
| a | 以追加方式打开文件,如果文件存在,指针会移动到文件末尾。如果文件不存在,创建新文件进行写入 |
| r+ | 以读写方式打开文件,文件的指针会放在文件的开头。文件不存在,抛出异常 |
| w+ | 以读写方式打开文件,如果文件存在会被覆盖,如果文件不存在,创建新文件 |
| a+ | 以读写方式打开文件,如果文件存在,文件指针会放到文件的末尾。如果文件不存在,创建新文件进行写入 |
- 后三种方式,频繁的移动文件指针会影响文件的读写效率,常用前三种
6.文件的复制
1.小文件复制
# 1.打开文件
file_read = open('README03') # 源文件
file_write = open('README03[附件1]','w') # 目标文件
# 2.读、写
text = file_read.read() # 读取所有内容
file_write.write(text) # 将读取到的内容写入
# 3.关闭文件
file_read.close()
file_write.close()
2.大文件复制
file_read = open('README03')
file_write = open('README03[附件1]','w')
while True:
# 逐行读取
text = file_read.readline()
# 判断是否读取到内容
if not text:
break
file_write.write(text)
file_read.close()
file_write.close()
2.os模块
导入os模块后,就可以对文件/目录进行常用的管理操作。
(一). 文件操作
1.文件重命名 ( os.rename('原文件名','目标文件名') )
import os
os.rename('README03','README03[复件1]')
2.文件删除 ( os. remove(文件名) )
import os
os.remove('text.txt')
(二). 目录操作
1.查看目录列表 ( os.listdir(path) )
import os
path = "./test"
files = os.listdir(path)
for file_name in files:
print(file_name)
2.创建目录 ( os.mkdir('目录名') )
import os
os.mkdir('test02')
3.删除目录 ( os.rmdir('目录名') )
import os
os.rmdir('test02')
4.获取当前目录 ( os.getcwd() )
import os
os.getcwd()
5.修改当前目录位置 ( os.chdir(path) )
import os
path = './test'
os.chdir(path)
6.判断是否是目录 ( os.path.isdir(文件路径) )
import os
file = os.path.isdir('test/01.py')
print(file) #False
- 文件或者目录操作都支持相对路径和绝对路径
编码格式
"""
python2.x默认使用的编码格式是ASCII
python3.x默认使用的编码格式是utf-8
"""
# *-* coding:utf-8 *-*
str = "python2.x中使用中文需要一个特别的注释"
print(str)
str2 = u"在python2中,即使指定了文件使用utf-8编码格式,但是在遍历或者切片字符串时,仍然会以字节为单位遍历字符串" \
"要能够正确的遍历字符串,在定义字符串时,增加u告诉解释器这是unicode字符串"
print(str2)
for item in str2:
print(item)
eval()函数
eval()函数十分强大,将字符串当成有效表达式来求值并且返回计算结果
a = eval('1+1')
print(a,type(a)) # 2 <class 'int'>
b = eval(" '*'*3 ")
print(b,type(b)) # *** <class 'str'>
c = eval('[1,2,3]')
print(c,type(c)) # [1, 2, 3] <class 'list'>
d = eval('(1,2,3)')
print(d,type(d)) # (1, 2, 3) <class 'tuple'>
f = eval('{"name":"关羽","age":18}')
print(f,type(f)) # {'name': '关羽', 'age': 18} <class 'dict'>
eval()函数可以将当前表达式数据类型转换为原本的数据类型
'''
千万不要使用eval()直接转换input的结果--太危险--用户直接可以输入命令来操作
'''
ipt = input('请输入结算结果: ')
print(eval(ipt))
'''
__import__('os').system('ls')
等价于
import os
os.system('ls')
'''
- 不要滥用
eval(),否则用户是可以通过直接输入相应的命令进行操作















 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









