






目录
在学习了单链表之后,我们发现单链表弥补了了顺序表的一些缺点,同时链表的结构体繁多,仔细计算链表的结构总共有8种,分为单链表与双链表,带头结点与不带头结点,循环与非循环。对于单链表,我们发现其自身也存在了一些问题
1.无法从后往前走
2.数据操作时间复杂度较高
3.无法找到结点的前驱
为了解决单链表的不足,我们引入的双链表的学习。
对于单向不带头不循环链表:结构简单,一般不会单独用来存放数据。实际中更多是用作其他数据结构的子结构,,如哈希桶,图的邻接表等等,另外这种结构在笔试面试中更多。
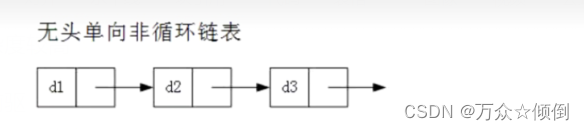
对于双向带头循环链表:结构最复杂,一般用于单独存放数据。实际中使用的链表数据结构都是带头双向循环链表。另外这个结构索然复杂,但是用代码实现起来会发现其结构有更大的优势,实现反而简单。
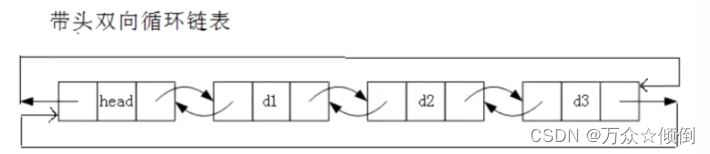
因为双向带头循环链表更适合我们实际中保存数据,所以我们今天就来学一下带头循环双向链表。
1.何为双链表?
顾名思义,在单链表的基础上又添加了一个指针,与单链表中的next指针效果一样,对于链表的物理模型不同的是,这里的指针与next是反向的。双链表完善了单链表的一些缺陷,在数据操作的时候也大大节省了时间。
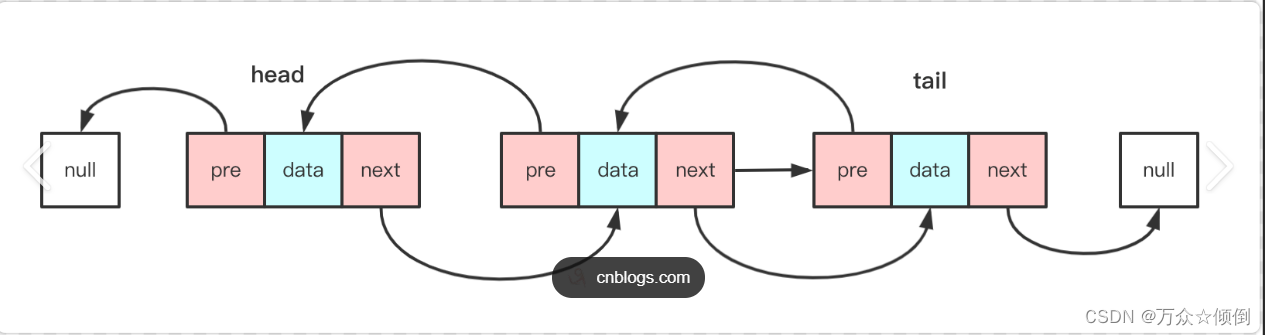
2.带头循环双向链表
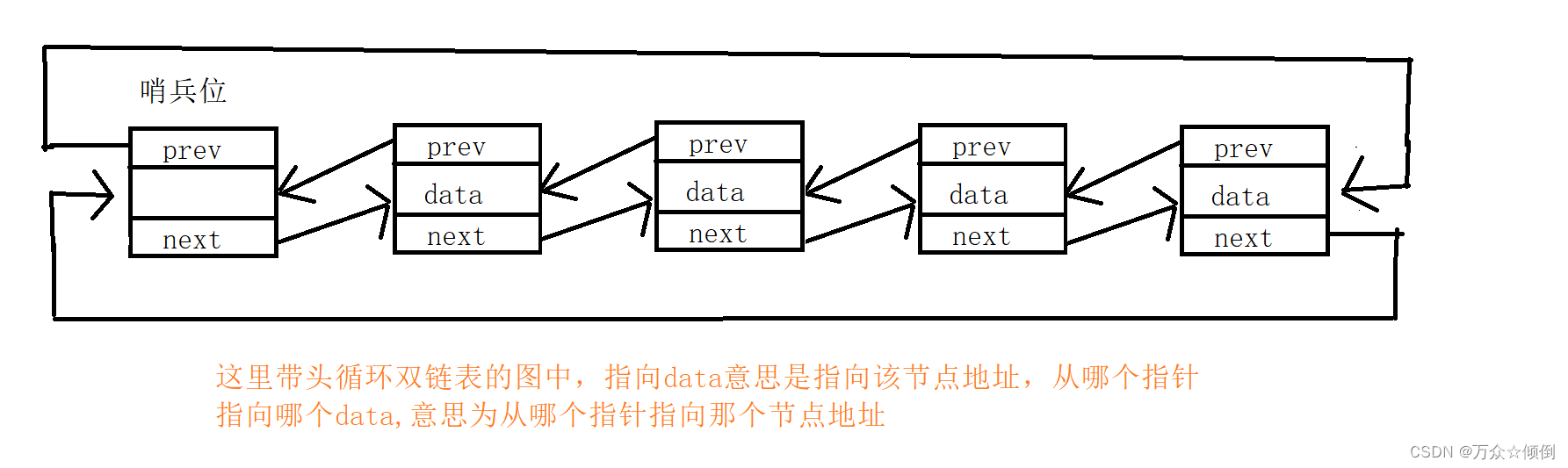
所谓带头循环双向链表就是在双链表的基础上添加了哨兵位,且尾节点的next->头节点,头结点的prev->指向尾节点,形成循环。此链表的结构看似复杂,但设计巧妙,我们在实现数据的一些操作功能时,巧妙的避免了许多麻烦,其次,不在考虑头节点为空的情况,省去了很多步骤。
1.函数接口与结构体
结构体的定义还是与双链表一样,其数据操作的函数接口也是一样的。
typedef int ST;
typedef struct ListNode
{
struct ListNode* prev;
ST data;
struct ListNode* next;
}ListNode,*List;
ListNode* Listinit();//初始化
void Listdestroy(ListNode* phead);//销毁链表
void printlist(ListNode* phead);//打印链表
void pushback(ListNode* phead, int x);//尾插
void popback(ListNode* phead);//尾删
void pushfront(ListNode* phead, int x);//头插
void popfront(ListNode* phead);//头删
ListNode* findNode(ListNode* phead, ST x);//查找
void insertNode(ListNode* pos, ST x);//pos位置前插入
void EraseNode(ListNode* pos);//删除pos位置的值2.初始化链表
因为我们需要的是带头循环双向链表,故初始化时,我们给定义的空链表初始化一个哨兵位,这里我们也不会用到哨兵位的数据,直接置为0.
ListNode*Listinit()
{
//初始化给一个哨兵节点
struct ListNode*phead = creatNode(0);
phead->next =phead;
phead->prev = phead;
return phead;
}3.销毁链表
销毁链表时都要删除包括哨兵位,所以我们直接从哨兵位开始遍历:
void Listdestroy(ListNode* phead)
{
assert(phead);
while (phead)
{
ListNode* cur = phead->next;
free(phead);
phead = cur;
}
}4.打印链表
还是很简单,这里需要注意的是在遍历链表时,循环中,phead->next==phead就结束。
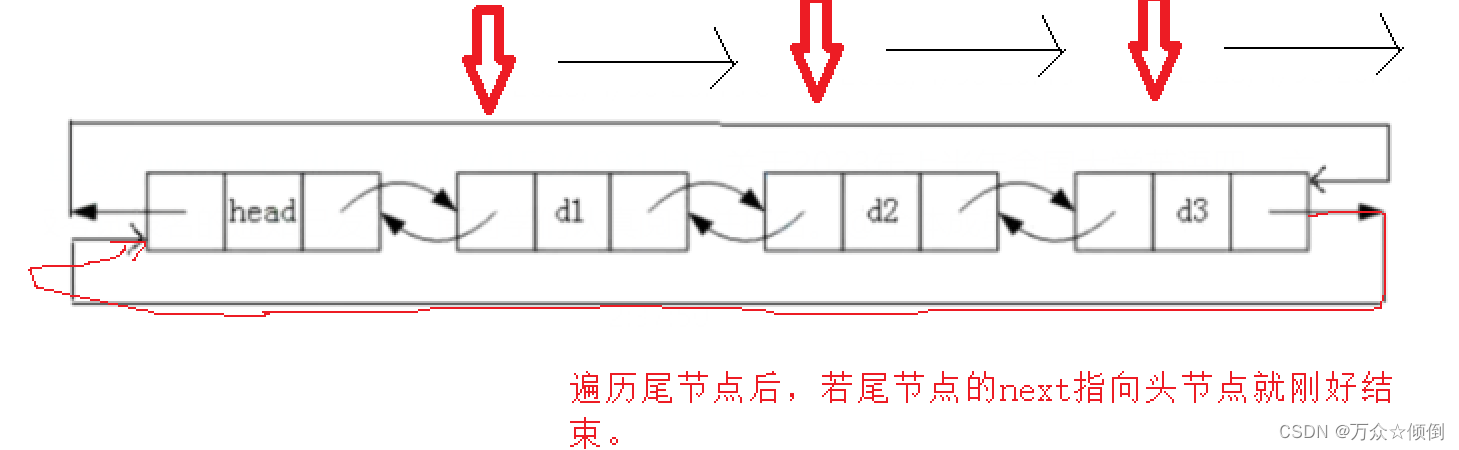
void printlist(ListNode* phead)
{
ListNode* cur = phead->next;
while (cur != phead)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("\n");
}5.创建节点
该步骤只是为了后续操作方便。
ListNode* creatNode(ST x)//创建新节点
{
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));
if (newnode == NULL)
{
return NULL;
}
else
{
newnode->next = NULL;
newnode->prev = NULL;
newnode->data = x;
return newnode;
}
}6.尾插
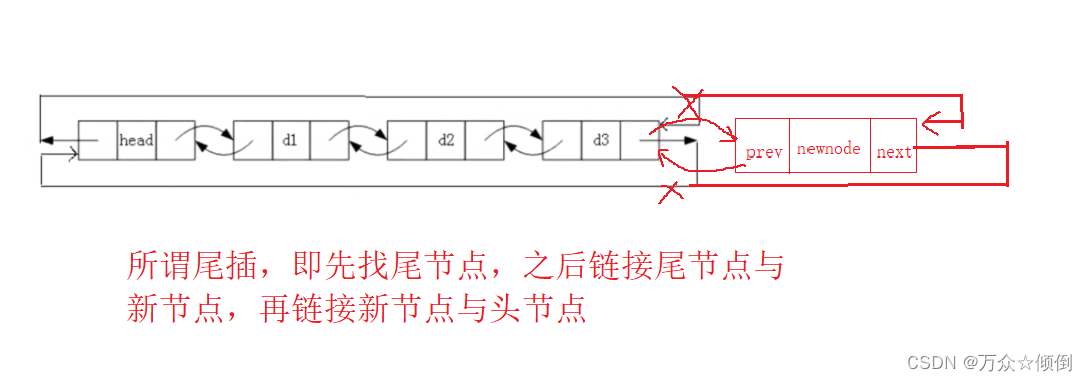
需要注意的一点是某个操作若与某些节点有关,我们可以先找到并保存这些节点,之后再惊醒操作,思路会更加清晰一些。
void pushback(ListNode* phead, int x)
{
//先保存尾节点
ListNode* tail = phead->prev;
ListNode* newnode = creatNode(x);
//链接
tail->next = newnode;
newnode->prev = tail;
newnode->next = phead;
phead->prev = newnode;
}7.尾删
尾删需要注意的是链表传过来除了哨兵位,还有其它节点。
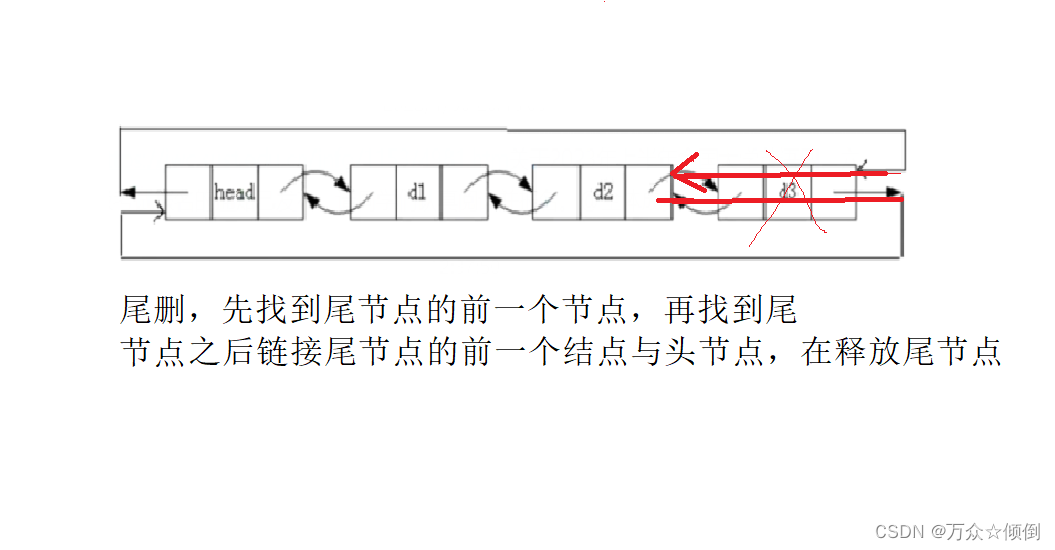
void popback(ListNode* phead)
{
assert(phead);
assert(phead->next);
ListNode* oldtail = phead -> prev;
ListNode* newtail = oldtail->prev;
newtail->next = phead;
phead->prev = newtail;
free(oldtail);
oldtail = NULL;
}8.头插
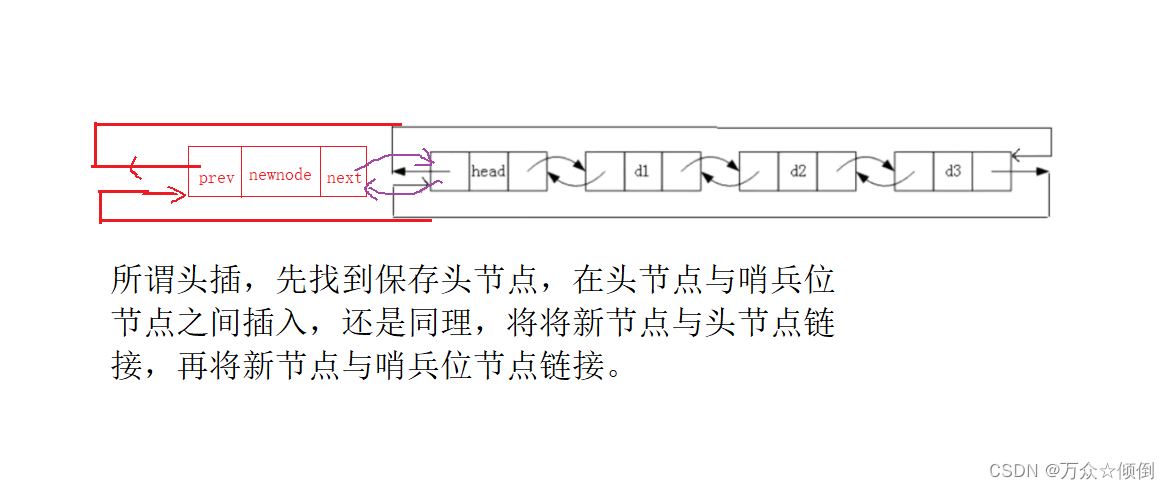
void pushfront(ListNode* phead, int x)
{
assert(phead);
/*保存头节点地址*/
ListNode* first = phead->next;
ListNode* newnode = creatNode(x);
newnode->next = first;
first->prev = newnode;
phead->next = newnode;
newnode->prev = phead;
//若没有保存头节点,在头插时应注意连接顺序。
//先链接newnode与phead->next的节点
/*ListNode* newnode = creatNode(x);
phead->next->prev = newnode;
newnode->next = phead->next;
phead->next = newnode;
newnode->prev = phead;*/
}我们可以发现,根据连接顺序的不同,我们可以选择是否保存需要链接的哪些节点,否则就要注意链接的顺序,比如说在头插时,不保存头结点时,先与头节点链接,在与哨兵位节点链接,否则先与哨兵位链接,我们就会丢失头节点,找不到头结点。
9.头删
所谓头删原理与之前的一样,先保存哨兵位节点与头节点的下一个节点,之后链接哨兵位节点与头结点的下一个节点,之后再free掉头节点。
void popfront(ListNode* phead)
{
assert(phead);
if (phead->next==NULL)
{
printf("无元素可删\n");
assert(phead);
}
ListNode* newhead = phead->next->next;
ListNode* oldhead = phead->next;
phead->next = newhead;
newhead->prev = phead;
free(oldhead);
oldhead= NULL;
}10 查找节点
查找节点与打印链表的遍历方式相同,也很简单
ListNode* findNode(ListNode* phead, ST x)
{
assert(phead);
ListNode* cur = phead->next;
while (phead != cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}11.在pos前插入x
在这里,我们可以通过查找函数找到pos节点,之后在插入函数里传入pos节点。
插入的思路与之前的一样,先保存pos节点与pos前的节点,再链接新节点与pos,链接新节点与pos前的节点,比如插到d2前:
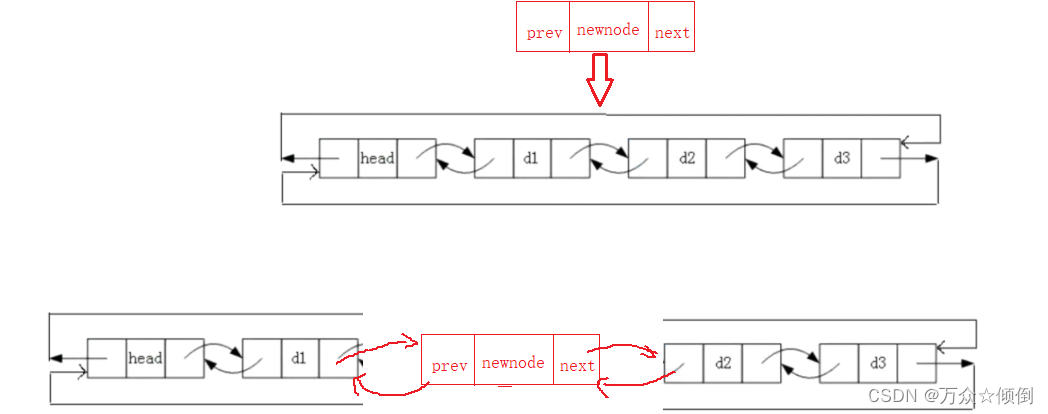
void insertNode(ListNode* pos, ST x)
{
ListNode* newnode = creatNode(x);
ListNode* front = pos->prev;
ListNode* cur = pos;
newnode->next = cur;
cur->prev = newnode;
front->next = newnode;
newnode->prev = front;
}在调用时:
int main()
{
ListNode* p = NULL;
p=Listinit();
pushback(p, 1);
pushback(p, 2);
pushfront(p,4);
ListNode* pos = findNode(p, 2);
if (pos)
{
printf("找到了\n");
}
else
{
printf("未找到");
}
insertNode(pos, 3);
return 0;
}12.删除pos位置的值
还是一样,找到pos前后位置的两个节点,连接pos前后两个节点,在释放pos处的节点,完成删除。
void EraseNode(ListNode* pos)
{
assert(pos);
ListNode* tmp = pos;
ListNode* cur = pos->next;
ListNode* front = pos->prev;
front->next = cur;
cur->prev = front;
free(tmp);
tmp = NULL;
}总结:带头循环双向链表,因为其独特的结构,使得我们在编译代码时省去了很多麻烦,在插入时不用判断头节点是否为空,在删除时,不用判断当只有一个节点时,是否是尾删。因为其循环的特性,判断也很方便/
















 684
684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











