










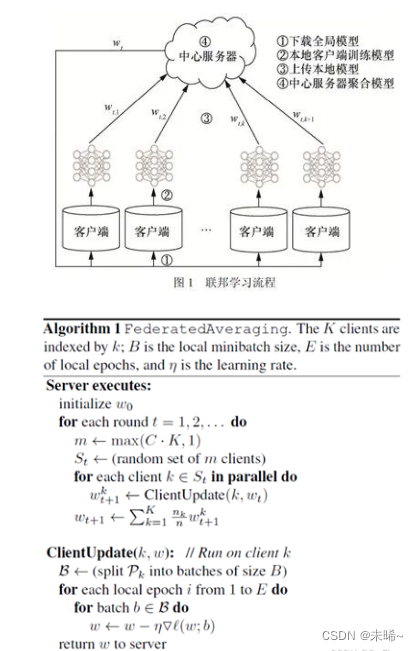
联邦学习是一种带有 隐私保护、安全加密技术的分布式机器学习框架,目的是让分散的各参与方在满足不向其他参与者披露隐私数据的前提下,协作进行机器学习的模型训练。实现数据可用不可见,数据不跑模型跑。
1、横向联邦学习
在两个数据集的用户特征重叠较多而用户重叠较少的情况下,我们把数据集按照横向(即用户维度)切分,并取出双方用户特征相同而用户不完全相同的那部分数据进行训练。这种方法叫做横向联邦学习。比如有两家不同地区银行,他们的用户群体分别来自各自所在的地区,相互的交集很小。但是,它们的业务很相似,因此,记录的用户特征是相同的。此时,就可以使用横向联邦学习来构建联合模型。
Google在2017年提出了一个针对安卓手机横型更新的数据联合建模方案;在单个用户使用安卓手机时,不断在本地更新模型参数并将参数上传到安卓云上,从而使特征维度相同的各数据拥有方建立联合模型的一种联邦学习方案。
2、纵向联邦学习
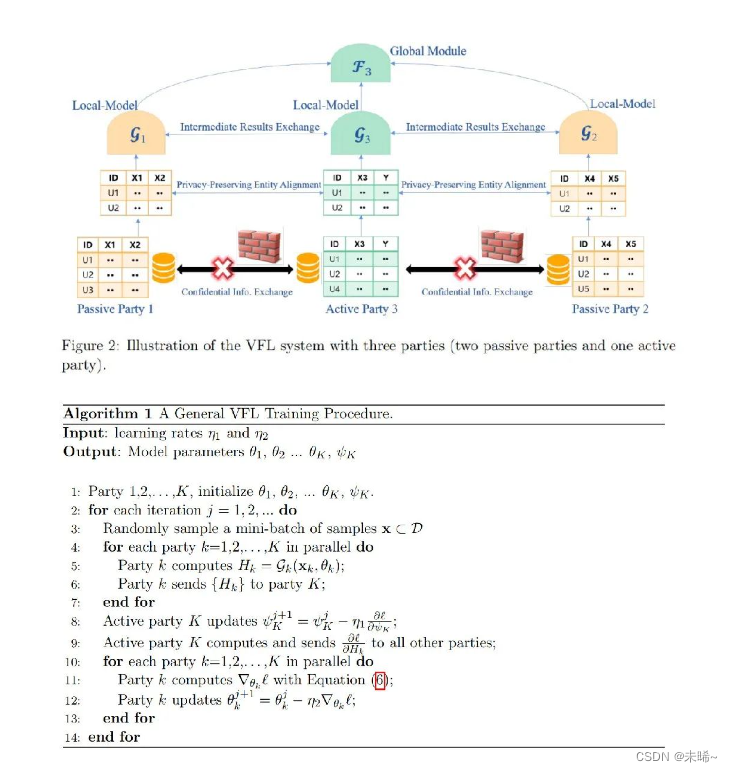
在两个数据集的用户重叠较多而用户重叠较少的情况下,我们把数据集按照纵向(即特征维度)切分,并取出双方用户相同而用户特征不完全相同的那部分数据进行训练,这种方法叫做纵向联邦学习。比如有两个不同机构,一家是某地的银行,另一家是同一地方的电商,他们的用户群体有可能包含该地的大部分居民,因此用户的交集较大。但是,由于银行记录的都是用户的收支行为和信用评级,而电商则保有用户的浏览与购买历史,因此它们的用户特征交集较小。纵向联邦学习就是将这些不同特征在加密的状态下加以聚合,以增强模型能力的联邦学习。
目前,回归模型、神经网络模型等众多机器学习模型已经逐渐被证实能够建立在这个联邦体系上。
3、联邦迁移学习
迁移学习,是指利用数据、任务或模型之间的相似性,将在源领域学习过的模型,应用于目标领域的一种学习过程。
比如“举一反三”,“照猫画虎”等
迁移学习的核心就是, 找到源领域和目标领域之间的相似性(不变量)。
联邦迁移学习的步骤与纵向联邦学习相似,只是中间传递结果不同(实际上每个模型的中间传递结果都不同)。

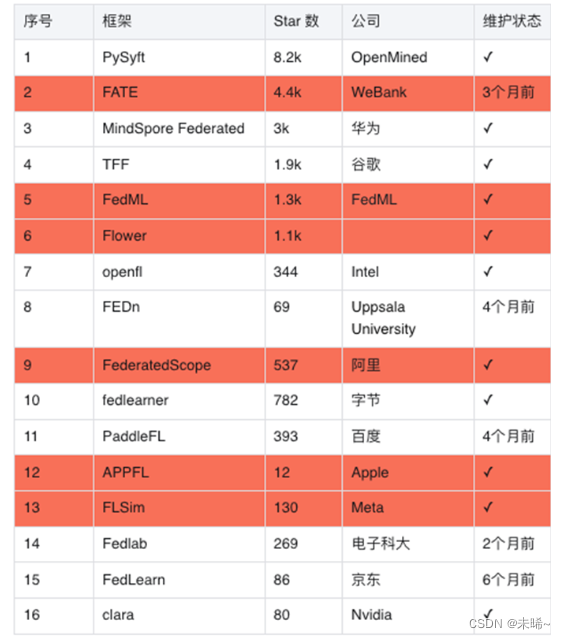
4、联邦学习的开源框架
















 22万+
22万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









