







 本文深入探讨了联邦学习的三种主要类型:横向联邦学习、纵向联邦学习和联邦迁移学习。横向联邦学习关注不同样本空间但相同特征空间的数据,采用客户-服务器或对等网络架构。纵向联邦学习处理不同特征空间但共享用户群体的数据,通过协调器确保数据隐私。联邦迁移学习则将迁移学习理念应用于联邦设置,包括基于实例、特征和模型的迁移。文章还讨论了各类联邦学习面临的挑战,如通信效率、模型选择和隐私保护。
本文深入探讨了联邦学习的三种主要类型:横向联邦学习、纵向联邦学习和联邦迁移学习。横向联邦学习关注不同样本空间但相同特征空间的数据,采用客户-服务器或对等网络架构。纵向联邦学习处理不同特征空间但共享用户群体的数据,通过协调器确保数据隐私。联邦迁移学习则将迁移学习理念应用于联邦设置,包括基于实例、特征和模型的迁移。文章还讨论了各类联邦学习面临的挑战,如通信效率、模型选择和隐私保护。
(一)横向联邦学习
1、定义
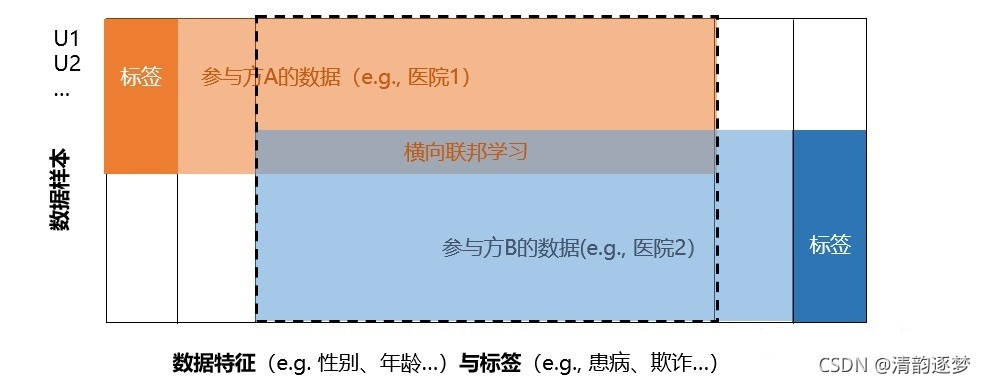
横向联邦学习也称为按样本划分的联邦学习,可以应用于联邦学习的 各个参与方的数据集有相同的特征空间和不同的样本空间的场景。
 2、横向联邦学习架构
2、横向联邦学习架构
常用的两个系统架构为:客户-服务器(client- server )架构和对等(Peer-to-Peer, P2P)网络架构。
1)客户-服务器架构
该架构也被称为主-从 (master-worker)架构或者轮辐式(hub-and-spoke)架构
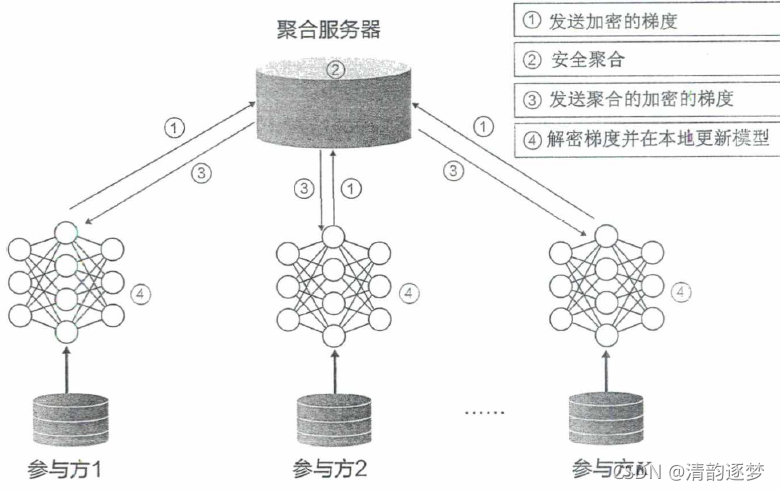
参与方将梯度信息发送给服务器,服务器将收到的梯度信息进行聚合(例如,计算加权平均),再将聚合的梯度信息发送给参与方。称这种方法为梯度平均。除了共享梯度信息,联邦学习的参与方还可以共享模型的参数。参与方在本地计算模型参数,并将它们发送至服务器。服务器对收到的模型参数进行聚合(例如,计算加权平均),再将聚合的模型参数发送给参与方。称这种方法为模型平均。这两种算法共称为联邦平均。
模型平均与梯度平均的比较如下:

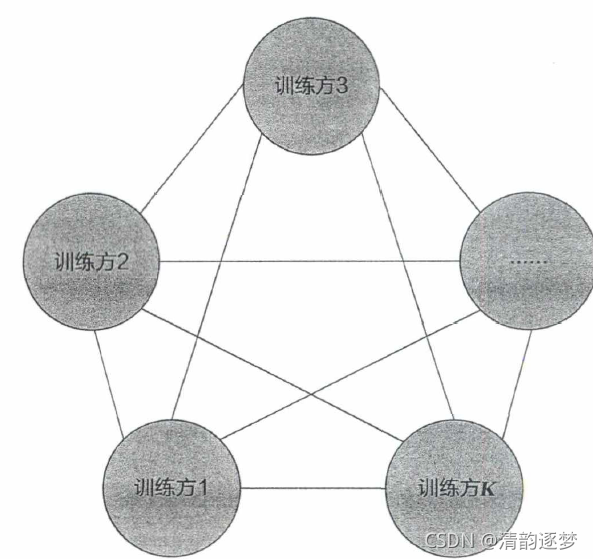
2)对等网络架构
对等网络架构中不存在中央服务器,训练方们必须提前商定发送和接收模型 参数信息的顺序。有两种方法可以达到目的:循环传输和随机传输。
对等网络架构的示例如下:
3、全局模型评估
在横向联邦学习中,模型训练和评估是在每个参与方中分布执行的,且任意方都不能获取其他方的数据集。所以,每个参与方都能轻易地使用自己的本地测试数据集来测试本地模型的性能,但全局模型的性能评价需要耗费更多资源。全局模型性能表示所有参与方在测试数据集上对横向联邦学习模型进行测试 得出的模型性能。
对于对等网络架构,由于不存在中央协调方或者中央服务器,要得到全局模型性 能将会更为复杂。一种可能的方式是选取某一个参与方来充当一个临时的协调方。
4、联邦平均算法介绍
1)联邦优化
联邦学习中的优化算法与传统机器学习中的优化算法有区别的,区别如下
a)数据集的非独立同分布
b)不平衡的数据量
c)数据量很大的参与方
d)慢速且不稳定的通信连接
2) 联邦平均算法
联邦平均啥孙发的计算量由三个关键参数控制:
a )参数P。指在每一轮中进行计算的客户的占比。
b )参数S。指在每一轮中,每一个客户在本地数据集上进行训练的步骤数。
c )参数M。指客户更新时使用的mini-batch的大小。我们使用M = oo 表示完整的本地数据集被作为一个批量来处理。
3)安全的联邦平均算法
在2)的算法阿基础上加入隐私保护技术,如用加法同态加密,差分隐私保护等。
5、联邦平均算法的改进
1、通信效率的提升
发送更新模型参数的策略提升通信效率
a)压缩的模型参数更新,
压缩的模型参数更新通常是真正 更新的无偏估计值
b)结构化的模型参数更新
模型参数可能被强制要求是稀疏的或者是低阶
2、参与方选择
参与方选择的方法被推荐用来降低联邦学习系统的通信开销和每 -轮全局联邦模型训练所需的时间。例如对随机挑选出来的参与方提供资源查询,协调方进行判断数据规模以及使用该数据能够实现
6、面临的挑战与展望
第一个主要挑战是在横向联邦学习系统里,无法查看或者检查分布式的训练 数据。这导致了我们难选择机器学习模型的超参数以及设定优化器,尤其是在训练DNN模型;第二个主要挑战是如何有效地激励公司和机构参与到横向联邦学习系统中来;第三个主要挑战是如何防止参与方的欺骗行为。
(二)纵向联邦学习
1、纵向联邦学习的定义
出于不同的商业目的,不同组织拥有的数据集通常具有不同的特征空间,但这些 组织可能共享一个巨大的用户群体,基于这种异构的数据我们搭建的模型为纵向联邦学习模型。
2、纵向联邦学习模型的架构
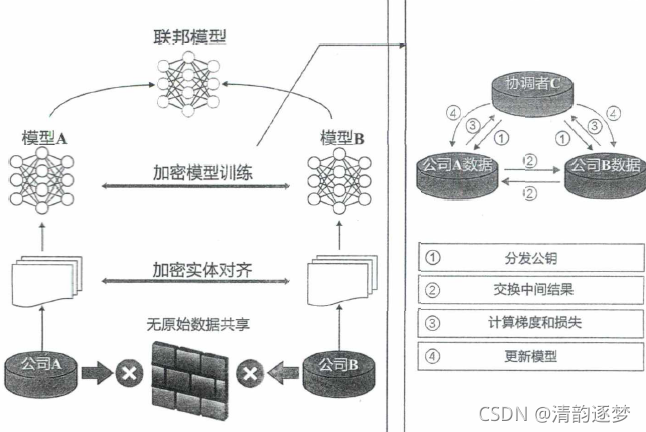
A方和B方 不能直接交换数据。为了保证训练过程中的数据保密性,加入第三方的协调者,假设C方是诚实且不与A或B方共谋,但A方和B方都是诚 实但好奇的。
3、纵向联邦学习算法
1)、安全联邦线性回归
2)、安全联邦提升树((Secure federated tree-boosting, SecureBoost)
4、纵向联邦学习面临的挑战
纵向联邦学习能够利用样本分散于多个参与方的多样化特征来建立一个健壮的共享模型。但与横向联邦学习中所有参与方共享一个共有模型不同,在纵向联邦学习体系中,每个参与方都拥有与其特征相关联的共享模型中的一部分。因此,学习中各参与方彼此间有更紧密的共生关系。对于分散在参与方的模型各部分的训练,也通常需要按照纵向联邦学习算法所给出的特定计算顺序来执行。换言之,参与方之间的讦算具有依赖关系,从而需要频繁地互动以交换模型训练中间结果。
因此,纵向联邦学习的训练很容易受到通信故障的影响,从而需要可靠并且高效的通信机制。在物理距离比较长的参与方之间传输模型训练中间结果是比较耗时的。长时间的数据传输会降低计算资源利用的效率,因为参与方必须等待必要的训练中间结果才能开始或继续本方的训练。为了解决这个问题,我们需要设计一种流式的通信机制,可高效地安排每个参与方进行训练和通信的时机,以抵消数据传输的延迟。同时,对于能够容忍在纵向联邦学习过程中发生崩溃的容错机制,也是我们实现 纵向联邦学习系统所必须考虑的。
(三)联邦迁移学习
1、联邦迁移学习的定义和分类
迁移学习的本质是发现资源丰富的源域(source domain)和资源稀缺的目标域 (target domain)之间的不变性(或相似性),并利用该不变性在两个领域之间传输知识。迁移学习主要分为三类:基于实例的迁移、基于特征的迁移和基于模型的迁移。联邦迁移学习将传统的迁移学习扩展到了面向隐私保护的分布式机器学习范式中。下面将概要地描述如何将这三类迁移学习技术分别应用于横向联邦学习和纵向联邦学习。
1)基于实例的联邦迁移学习
不论是在横向联邦学习还是纵向联邦学习中,都会因为实例选择及加权问题导致模型的训练结果不如人意,有选择地挑选用于训练的特征和样本的技术的应用被称为基于实例的联邦迁移学习。
2)基于特征的联邦迁移学习
参与方协同学习一个共同的表征(representation)空间。在该空间中,可以缓解从原始数据转换而来的表征之间的分布和语义差异,从而使知识可以在不同领域之间传递。对于横向联邦学习,可以通过最小化参与方样本之间的最大平均差异(Maximum Mean Discrepancy, MMD )列来学习共同的表征空间。对于纵向联邦学习,可以通过最小化对齐样本中属于不同参与方的表征之间的距离,来学习共同的表征空间。
3)基于模型的联邦迁移学习
参与方协同学习可以用于迁移学习的共享模型,或者参与方利用预训练模型作为联邦学习任务的全部或部分初始模型。横向联邦学习本身就是一种基于模型的联邦迁移学习。因为在每个通信回合中,各参与方会协同训练一个全局模型(基于所有数据),并且各参与方把该全局模型作为初始模型进行微调(基于本地数据)对于纵向联邦学习,可以从对齐的样本中学习预测模型或者利用半监督学习技术,以推断缺失的特征和标签。然后,可以使用扩大的训练样本训练更准确的共享模型。
2、挑战和展望
1)联邦迁移学习中的迁移知识由各参与方的本地模型共同学习得到。每一个参与方都对各自本地模型的设计和训练拥有完全的控制权。我们面临的一个挑战就是在联邦迁移学习模型的自主性和泛化性能之间寻求一种平衡。
2)如何在保证参与方共享表征的隐私安全下确定分布式环境中学习迁移知识的表征方法。
3)设计出可以部署在联邦迁移学习中的高效安全协议。


















 1384
1384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











