






超市电商数据分析
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
一、数据源概况:
Row ID:行编号;
Order ID:订单ID;
Order Date:订单日期;
Ship Date:发货日期;
Ship Mode:发货模式;
Customer ID:客户ID;
Customer Name:客户姓名;
Segment:客户类别;
City:客户所在城市;
State:客户城市所在州;
Country:客户所在国家;
Postal Code:邮编;
Market:商店所属区域;
Region:商店所属州;
Product ID:产品ID;
Category:产品类别;
Sub-Category:产品子类别;
Product Name:产品名称;
Sales:销售额;
Quantity:销售量;
Discount:折扣;
Profit:利润;
Shipping Cost:发货成本;
Order Priority:订单优先级;

提示:以下是本篇文章正文内容,下面案例可供参考
二、读取、清洗数据:
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
1. 使用pandas的read_csv读取数据后,查看各列数据的空值情况,发现Postal Code字段(邮编字段)有空值,而且这一列不重要,所以首先删除掉Postal Code列;
# 加载零售数据集,使用'ISO-8859-1'编码方式
df = pd.read_csv('D:\生产实习\项目\项目一:Python超市电商数据分析\market.csv',encoding='ISO-8859-1')
df.head(10)
#数据清洗
#查看缺失值
df.isnull().sum(axis=0)
#删除邮编信息列
df.drop(["Postal Code"],axis=1, inplace=True)
2. 使用DataFrame对象的describe()方法,没有发现异常数据,所以,不必处理;
#数据分布情况
df.describe()
3. 将Order Date订单日期字段的数据修改为datetime类型;
#将Order Date订单日期字段的数据修改为datetime类型
df["Order Date"] = pd.to_datetime(df["Order Date"])
4. 为了后续分析方便,从订单日期中分别提取年、月、季度数据,并添加三个列用来存取年、月、季度信息,分别为:’Order-year’,’Order-month’,’quarter’
#从订单日期中分别提取年、月、季度数据,并添加三个列用来存取年、月、季度信息,分别为:’Order-year’,’Order-month’,’quarter’
df['Order-year'] = df["Order Date"].dt.year
df['Order-month'] = df['Order Date'].dt.month
# quarter()函数会将一年分为四个季度,1-3月为第一季度,以此类推
df['Quarter'] = df['Order Date'].dt.quarter
思考题:还有哪些情况可以进行数据清洗?
1、缺失值处理:对缺失数据进行填充或删除操作,使得数据集中不存在缺失值。
2、异常值处理:对数据集中异常值进行判断和处理,以避免对后续分析产生影响。
3、重复值处理:删除数据集中的重复记录,避免造成冗余和浪费。
4、数据类型转换:将数据中的字符串等类型转换为数值类型,以便能够进行更多的统计分析。
5、数据归一化:将不同维度的数据进行标准化,以避免由于数据单位等差异导致的分析误差。
通过数据清洗,我们可以把原始数据中的噪声和冗余信息清除,提升数据质量,更好地完成后续的数据分析和建模任务。
二、数据分析:
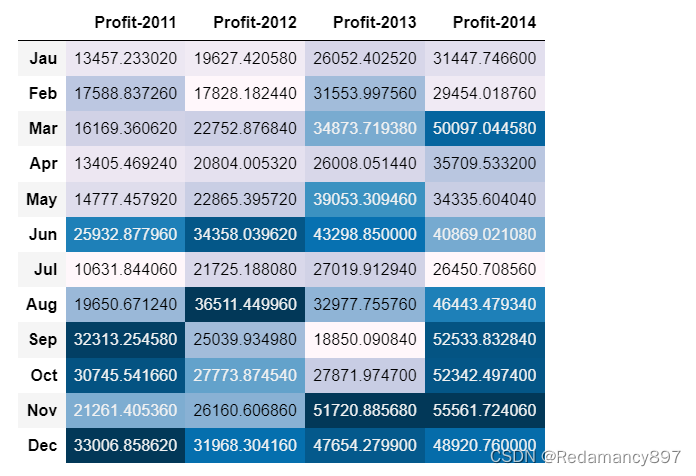
1.利润分析
先根据年和月进行分组,再分别提取各年份(2011-2014
年)的数据,分析各年份对应月的利润情况。
#根据年和月进行分组求和
sales_year = df.groupby(['Order-year','Order-month']).sum()
#取各年份(2011-2014年)的数据
year_2011 = sales_year.loc[(2011,slice(None)),:].reset_index()
year_2012 = sales_year.loc[(2012,slice(None)),:].reset_index()
year_2013 = sales_year.loc[(2013,slice(None)),:].reset_index()
year_2014 = sales_year.loc[(2014,slice(None)),:].reset_index()
#分析各年份对应月的利润情况
#利润分析
#将四个年份表合并为一个
profit=pd.concat([year_2011['Profit'],year_2012['Profit'],
year_2013['Profit'],year_2014['Profit']],axis=1)
profit.columns=['Profit-2011','Profit-2012','Profit-2013','Profit-2014']
profit.index=['Jau','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec']
profit.style.background_gradient()
思考题:如何对DataFrame进行分组,并进行聚合运算?如何
将多个Series对象合并成一个DataFrame?
-
对DataFrame进行分组并进行聚合运算
1.使用groupby()方法: 首先,你需要确定用于分组的列名或一个函数。然后,调用DataFrame的groupby()方法。然后对每个组计算相关操作import pandas as pd # 假设df是一个DataFrame,你想要根据'city'列进行分组,并计算'age'列的平均值 grouped_df = df.groupby('city') mean_age = grouped_df['age'].mean()2. 多种聚合函数: 如果你想在一个操作中应用多个聚合函数,可以传递一个函数列表或字典给agg()方法。agg_results = grouped_df.agg(['mean', 'sum', 'count']) -
将多个Series对象合并成一个DataFrame
1. 使用字典构造DataFrame:如果Series有共同的索引,你可以直接将它们放在一个字典里,然后传递给DataFrame构造器。
series1 = pd.Series([1, 2, 3], name='Series1') series2 = pd.Series([4, 5, 6], name='Series2') df_merged = pd.DataFrame({'Series1': series1, 'Series2': series2})2. 使用pd.concat():如果Series的索引不同,或者你希望以特定的方式(例如,行或列)合并它们,可以使用pd.concat()函数。df_merged = pd.concat([series1, series2], axis=1)
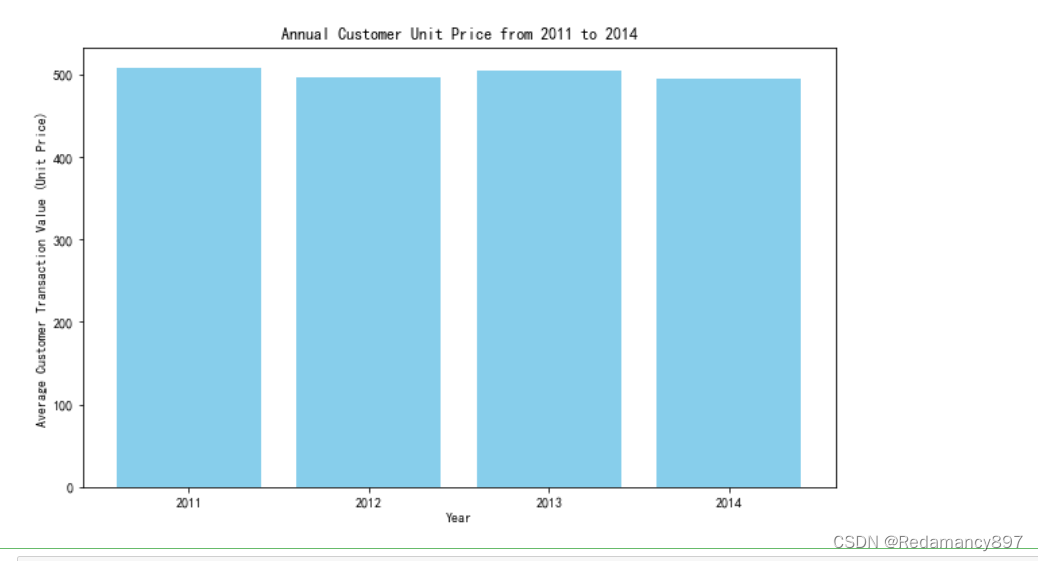
2.客单价分析
客单价指商场(超市)每一个顾客平均购买商品的金额,客单
价反映顾客的购买水平;
客单价=销售额÷成交顾客数
#客单价分析
#客单价指商场(超市)每一个顾客平均购买商品的金额,客单价反映顾客的购买水平;客单价=销售额÷成交顾客数
# 2011-2014年客单价
# 创建一个字典来存储每年的客单价
year_unit_price = {}
for i in range(2011, 2015):
data = df[df['Order-year'] == i]
price = data[['Order Date', 'Customer ID', 'Sales']]
#删除重复数据
price_dr = price.drop_duplicates(subset=['Order Date', 'Customer ID'])
#得到pprice_dr的总行数
total_num = price_dr.shape[0]
unit_price = price['Sales'].sum() / total_num
year_unit_price[i] = unit_price
print('{}年总消费次数='.format(i), total_num)
print('{}年客单价='.format(i), unit_price, '\n')
#展示每年的客单价数据
# 使用matplotlib绘制柱状图展示每年的客单价
plt.figure(figsize=(10, 6))
plt.bar(year_unit_price.keys(), year_unit_price.values(), color='skyblue')
plt.xlabel('Year')
plt.ylabel('Average Customer Transaction Value (Unit Price)')
plt.title('Annual Customer Unit Price from 2011 to 2014')
plt.xticks(range(2011, 2015)) # 确保x轴标签显示为具体的年份
plt.show()
思考题:DataFrame如何去除重复行?
使用drop_duplicates()方法。
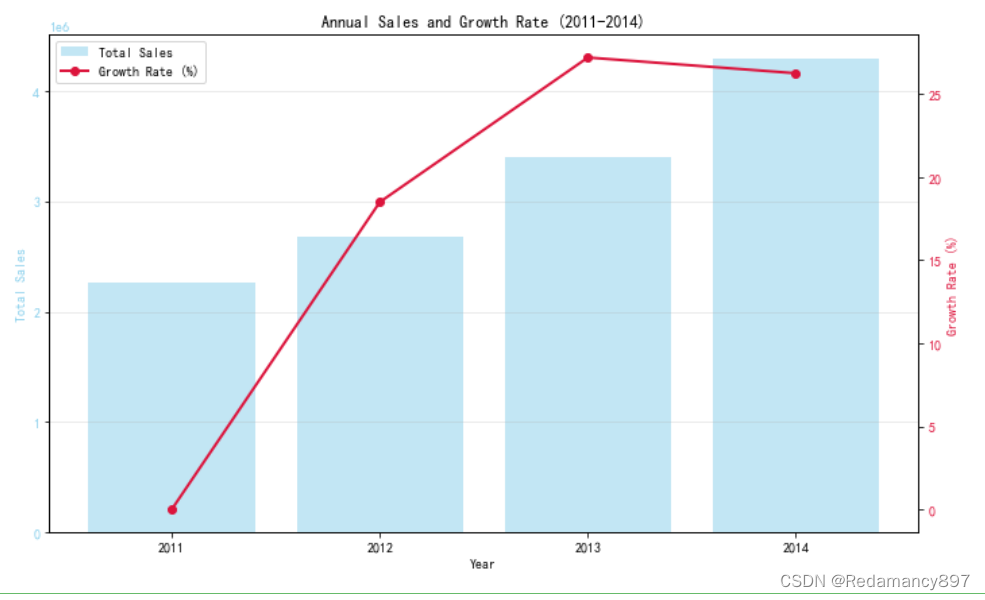
3. 每年销售额与销售额的增长率分析
通过年份分组,计算每年的销售额总和
销售额增长率 = (本年销售额-上年销售额) / 上年销售额 * 100%
= 本年销售额 / 上年销售额 - 1
#每年销售额与销售额的增长率分析
#通过年份分组,计算每年的销售额总和,销售额增长率 = (本年销售额-上年销售额) / 上年销售额 * 100%= 本年销售额 / 上年销售额 - 1
#销售额分析
sales=pd.concat([year_2011['Sales'],year_2012['Sales'],
year_2013['Sales'],year_2014['Sales']],axis=1)
# 对列名进行重命名
sales.columns=['2011','2012','2013','2014']
sales.index=['Jau','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec']
sales_sum=sales.sum()
# 计算每年增长率
rise_12=sales_sum[1]/sales_sum[0]-1
rise_13=sales_sum[2]/sales_sum[1]-1
rise_14=sales_sum[3]/sales_sum[2]-1
rise_rate=[0,rise_12,rise_13,rise_14]
# 显示增长率
sales_sum=pd.DataFrame({'sales_sum':sales_sum})
sales_sum['rise_rate']=rise_rate
# 绘制销售额柱状图
fig, ax1 = plt.subplots(figsize=(10, 6))
color = 'skyblue'
ax1.bar(sales_sum.index, sales_sum['sales_sum'], alpha=0.5, color=color, label='Total Sales')
ax1.set_xlabel('Year')
ax1.set_ylabel('Total Sales', color=color)
#对销售额设置y轴
ax1.tick_params(axis='y', labelcolor=color)
ax1.set_title('Annual Sales and Growth Rate (2011-2014)')
# 绘制增长率折线图
#创建一个与ax1共享相同x轴的新坐标轴ax2,但是拥有自己的y轴。
ax2 = ax1.twinx()
color = 'crimson'
ax2.plot(sales_sum.index, sales_sum['rise_rate']*100, color=color, marker='o', linestyle='-', linewidth=2, label='Growth Rate (%)')
ax2.set_ylabel('Growth Rate (%)', color=color)
ax2.tick_params(axis='y', labelcolor=color)
# 合并两个坐标轴的图例柄(即图表中的线条、标记等图形元素)和标签,然后在一个图例中显示它们。
h1, l1 = ax1.get_legend_handles_labels()
h2, l2 = ax2.get_legend_handles_labels()
ax1.legend(h1+h2, l1+l2, loc='upper left')
# 显示网格
ax1.grid(axis='y', alpha=0.3)
plt.tight_layout()
plt.show()
思考题:如何将条形图与折线图在一幅图上展示?
通过调用twinx()方法,为折线图创建了第二个y轴。接着,分别为两个图设置了不同的颜色、标签和样式,# 合并两个坐标轴的图例柄(即图表中的线条、标记等图形元素)和标签,然后在一个图例中显示它们。
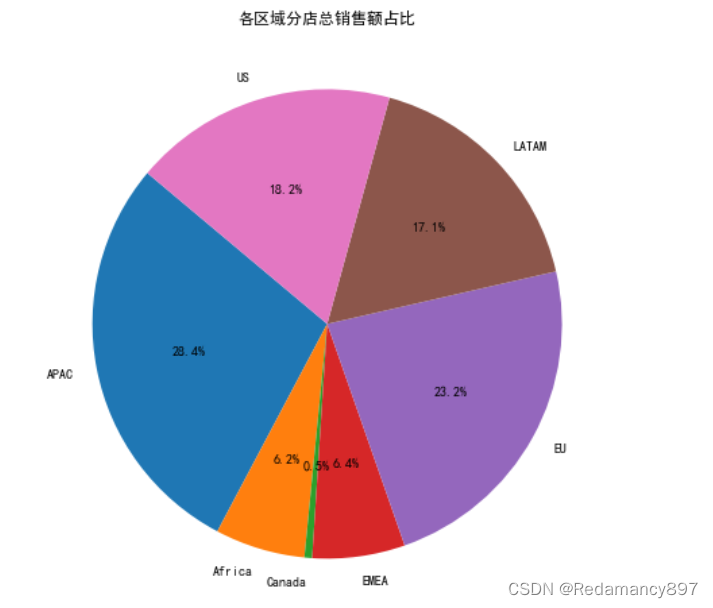
4.分析各个地区分店的销售额
查看不同区域分店的总销售额占比
#分析各个地区分店的销售额
#查看不同区域分店的总销售额占比
Market_Sales = df.groupby(['Market']).agg({'Sales':'sum'})
Market_Sales["percent"] = Market_Sales["Sales"] / df["Sales"].sum()
import matplotlib.pyplot as plt
# 绘制饼图
plt.figure(figsize=(8, 8))
plt.pie(Market_Sales['percent'], labels=Market_Sales.index, autopct='%1.1f%%', startangle=140)
plt.title('各区域分店总销售额占比')
plt.show()
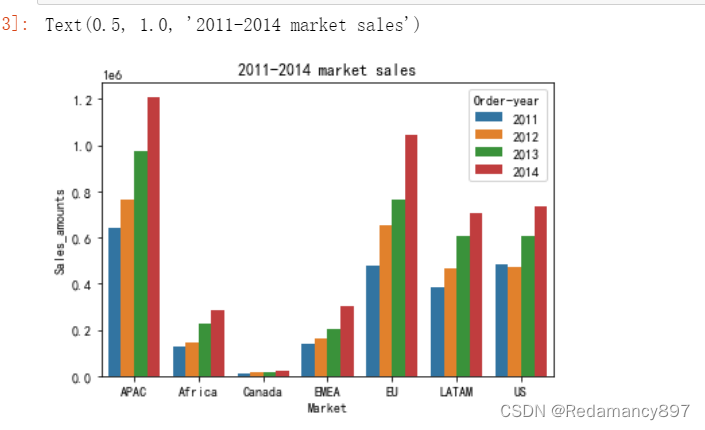
分别对各个区域每年销售额分析
#分别对各个区域每年销售额分析
Market_Year_Sales = df.groupby(['Market', 'Order-year']).agg({'Sales':'sum'}).reset_index().rename(columns={'Sales':'Sales_amounts'})
Market_Year_Sales.head()
sns.barplot(x='Market', y='Sales_amounts', hue='Order-year', data = Market_Year_Sales)
plt.title('2011-2014 market sales')
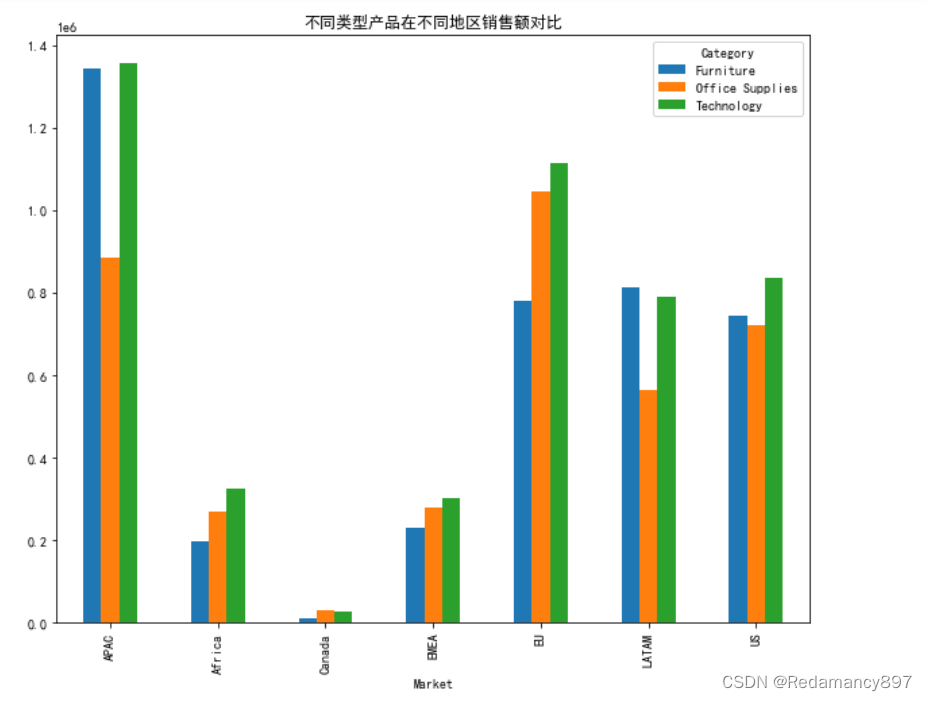
分别对各个区域的不同类型产品销售额分析
#分别对各个区域的不同类型产品销售额分析
category_sales_area = df.groupby(by=['Market','Category'])['Sales'].sum()
# 将分组后的多层索引设置成列数据
category_sales_area = category_sales_area.reset_index(level=[0,1])
# 使用数据透视表重新整理数据
category_sales_area = pd.pivot_table(category_sales_area,
index='Market',
columns='Category',
values='Sales')
# 绘制图形
category_sales_area.plot(kind = 'bar',title = '不同类型产品在不同地区销售额对比',figsize= (10,8))
思考题:透视表如何创建?它的作用是什么?
创建透视表通常使用pandas库中的pivot_table函数
pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False)
data: 必需。这是要进行透视操作的DataFrame。
values: 可选。指定要进行聚合操作的列名。默认为None,此时会尝试使用所有数值类型的列。
index: 可选。作为透视表行分组的列名或列名列表。这些列的值会被作为行标签。
columns: 可选。作为透视表列分组的列名或列名列表。这些列的值会被作为列标签。
aggfunc: 可选。聚合函数或函数列表,用于计算每个分组的值。默认为’np.mean’,即求平均值。可以是’nunique’, ‘sum’, ‘mean’, ‘median’, ‘count’, ‘min’, 'max’等,或者自定义函数,甚至是这些函数的字典,比如{column1: np.sum, column2: np.mean}针对不同列应用不同函数。
fill_value: 可选。用于填充缺失值的值,默认为None,表示不填充。
margins: 可选。布尔值,默认为False。如果为True,则会在结果中添加行/列边缘总计(总体汇总)。
dropna: 可选。布尔值,默认为True。决定是否删除包含NaN值的行或列。
margins_name: 可选。当margins=True时,此参数指定边缘总计的列或行标签,默认为"All"。
observed: 可选。仅在使用categoricals时相关,控制是否只显示已观察到的类别,默认为False。
它的主要作用包括:
数据汇总:能够快速地对大量数据进行分组和聚合运算(如求和、平均值、最大值、最小值等)。
数据分析:便于发现数据中的模式、趋势和异常,帮助做出决策。
报告生成:以表格形式清晰展示数据摘要,适合制作报告和仪表板
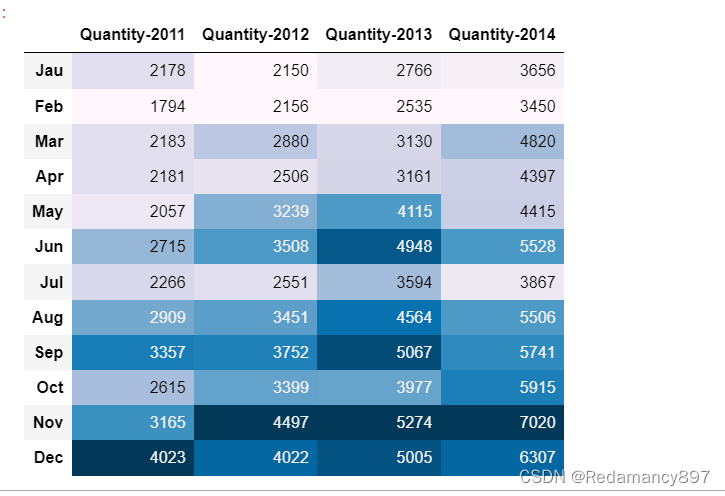
5.销量分析与销售淡旺季分析
- 销量分析
通过表格展示,2011-2014年各月份的详细销量数据
#销量分析与销售淡旺季分析
#通过表格展示,2011-2014年各月份的详细销量数据
quantity = pd.concat([year_2011['Quantity'],year_2012['Quantity'],
year_2013['Quantity'],year_2014['Quantity']],axis=1)
# 对行名和列名进行重命名
quantity.columns=['Quantity-2011','Quantity-2012','Quantity-2013','Quantity-2014']
quantity.index=['Jau','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec']
# 颜色越深,销量越高
quantity.style.background_gradient()
- 淡旺季分析(通过销售额分析)
通过年月销售额的变化趋势分析淡旺季
#销售淡旺季分析
# 为了方便观察数据,我们需要将数据根据年和月进行分组,并计算出每年每月的销售总额,再将其制作成年、月、销售额的数据透视表,最后我们折线图进行展示。
year_month = df.groupby(by=['Order-year','Order-month'])['Sales'].sum()
#按照两列变成多层索引,
# 将索引订单年转为一列数据
sales_year_month = year_month.reset_index(level=[0,1])
# 利用透视表的确定销售额预览表
sales_year_month = pd.pivot_table(sales_year_month,
index='Order-month',
columns='Order-year',
values='Sales')
# 绘制图形
sales_year_month.plot()

思考题:如何提取符合相应条件的行
-
使用布尔索引
布尔索引是直接在DataFrame上应用一个布尔数组,该数组的长度与DataFrame的行数相同,其值为True或False,指示是否选择对应的行。 -
使用.loc[]
.loc[] 是一个基于标签的索引器,允许你通过标签名而不是整数位置来选择行和列。它支持更复杂的逻辑,如切片和布尔数组。 -
使用 .query()
.query() 方法提供了一种更简洁的方式来过滤DataFrame,它接受一个字符串参数,该参数是一个表达式,用于指定筛选条件。
思考题:如何通过透视表绘制折线图?
直接调用plot方法(由于pandas的数据框和系列都有内置的plot方法,这里是针对DataFrame调用的)绘制折线图。由于透视表的结构(月份为索引,年份为列),pandas会自动为每一列(即每个年份)绘制一条折线,横轴为月份,纵轴为销售额,从而直观展示不同年份每月销售额的变化趋势。
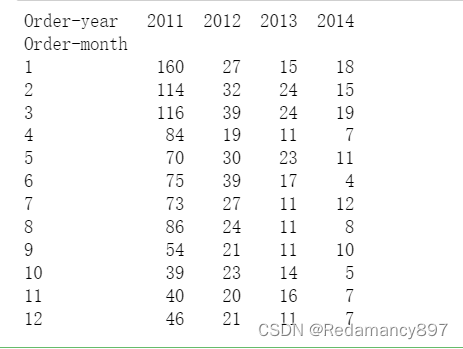
6.分析新老客户数
新老客户的定义:将只要消费过的客户定义为老客户,否则就
是新客户
根据Customer ID列数据进行重复行的删除, 保证数据集中所
有的客户ID都是唯一的,根据此数据再通过年、月进行分组,
通过透视表分析新老客户数
#分析新老客户数
#根据Customer ID列数据进行重复行的删除, 保证数据集中所有的客户ID都是唯一的
data = df.drop_duplicates(subset=['Customer ID'])
#根据此数据再通过年、月进行分组,并使用size()函数对每个分组进行计数
new_consumer = data.groupby(by=['Order-year','Order-month']).size()
#重新设置index
#多层索引,变成单层索引,将索引转化成数据列。
new_consumer2 = new_consumer.reset_index(level=[0,1])
#通过透视表分析新老客户数
sales_year_month = pd.pivot_table(new_consumer2,
index='Order-month',
columns='Order-year',
values=0)
print(sales_year_month)
7.用户数据分析
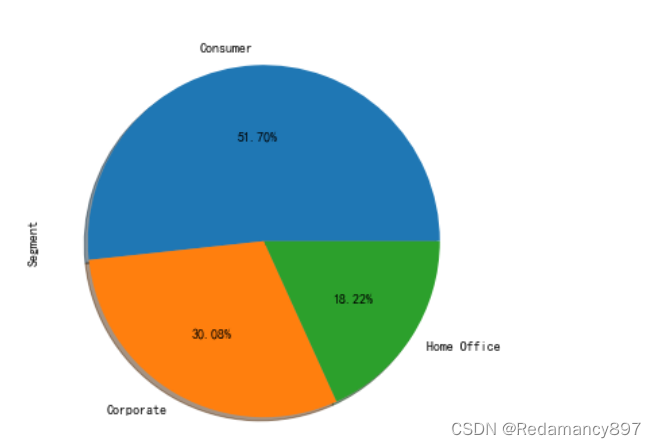
- 客户类型占比分析
绘制饼图查看不同客户的类型占比,其中,'Segment’字段
代表客户类别
#用户数据分析
#客户类型占比分析绘制饼图查看不同客户的类型占比,其中,'Segment'字段代表客户类别
df["Segment"].value_counts().plot(kind='pie', autopct='%.2f%%', shadow=True, figsize=(14, 6))
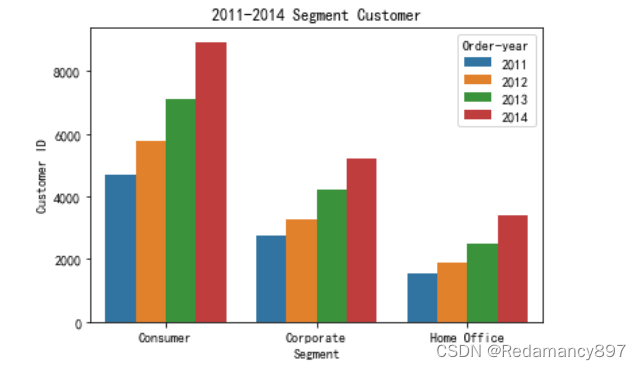
- 各年不同类型消费者数量分析
#各年不同类型消费者数量分析
Segment_Year = df.groupby(["Segment", 'Order-year']).agg({'Customer ID':'count'}).reset_index()
sns.barplot(x='Segment', y='Customer ID', hue='Order-year', data = Segment_Year)
plt.title('2011-2014 Segment Customer')
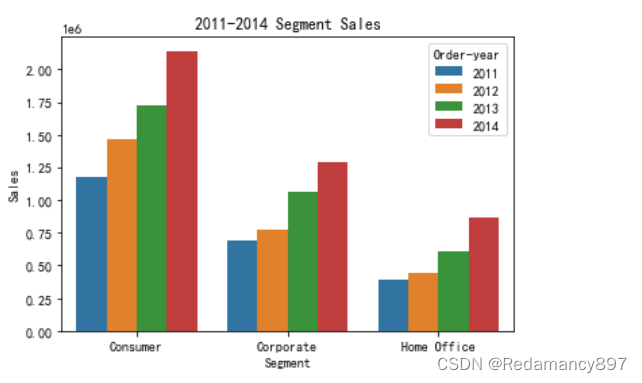
- 不同类型的客户每年的销售额分析
#各年不同类型消费者数量分析
#不同类型的客户每年的销售额分析
Segment_sales = df.groupby(["Segment", 'Order-year']).agg({'Sales':'sum'}).reset_index()
sns.barplot(x='Segment', y='Sales', hue='Order-year', data = Segment_sales)
plt.title('2011-2014 Segment Sales')
思考题:你能想到的对分组数据进行聚合的方法?
sum(): 计算每组的总和。
mean(): 计算每组的平均值。
median(): 计算每组的中位数。
min(): 计算每组的最小值。
max(): 计算每组的最大值。
count(): 计算每组非NaN元素的数量。
std(): 计算每组的标准差。
var(): 计算每组的方差。
quantile(): 计算每组的分位数,如四分位数(0.25, 0.5, 0.75)等。
first(): 返回每组的第一个元素。
last(): 返回每组的最后一个元素。
nunique(): 计算每组中唯一值的数量。
apply(): 应用自定义函数到每组数据上,可以用于更复杂的聚合操作。
8.用户价值度RFM模型分析
#用户价值度RFM模型分析
#不同价值的客户类型进行占比分析
rfm = df.pivot_table(index='Customer ID',
values = ["Quantity","Sales","Order Date"],
aggfunc={"Quantity":"sum","Sales":"sum","Order Date":"max"})
print(rfm)
# 所有用户最大的交易日期为标准,求每笔交易的时间间隔即为R
rfm['R'] = (rfm['Order Date'].max() - rfm['Order Date']) / np.timedelta64(1, 'D')
# 每个客户的总销量即为F,总销售额即为M
rfm.rename(columns={'Quantity':'F','Sales':'M'},inplace = True)
# 基于平均值做比较,超过均值为1,否则为0
rfm[['R','F','M']].apply(lambda x:x-x.mean())
def rfm_func(x):
level =x.apply(lambda x:'1'if x>0 else '0')
level =level.R +level.F +level.M
d = {
"111":"重要价值客户",
"011":"重要保持客户",
"101":"重要挽留客户",
"001":"重要发展客户",
"110":"一般价值客户",
"010":"一般保持客户",
"100":"一般挽留客户",
"000":"一般发展客户"
}
result = d[level]
return result
rfm['label']= rfm[['R','F','M']].apply(lambda x:x-x.mean()).apply(rfm_func,axis =1)
rfm.head()
rfm["label"].value_counts().plot(kind='pie', autopct='%.2f%%', shadow=True, figsize=(14, 6))
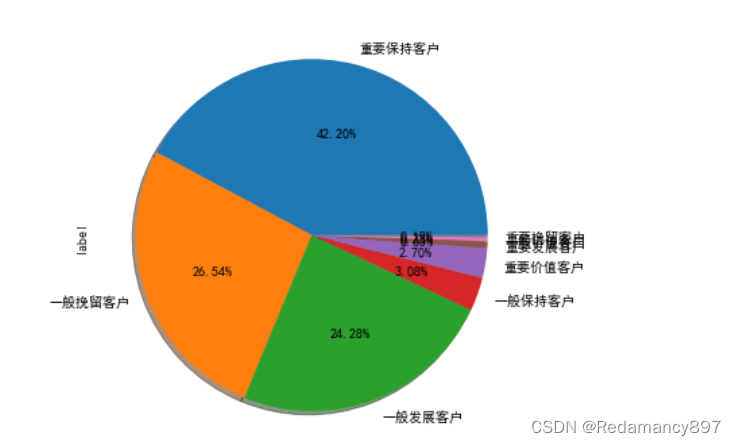
思考题:分组对象的apply()方法如何使用?
result = df.groupby(by=<列名>).apply(<函数>)
- df 是你的DataFrame。
- by=<列名> 指定你想要根据哪一列或多列进行分组。
- <函数> 是你自定义的函数或者内建函数,这个函数将会应用于每一个分组上。该函数可以接收一个DataFrame作为输入,并返回一个Series、DataFrame或标量值。
9.客户群体与产品种类的关系分析
通过客户群体类别(Segment字段)与产品类别(Category字
段)分组,对销售额数据进行分析
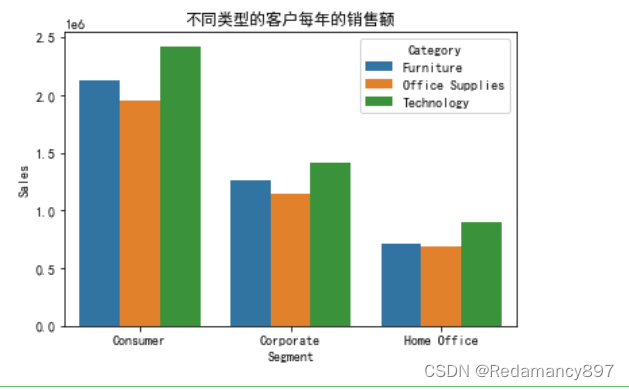
#客户群体与产品种类的关系分析
#通过客户群体类别(Segment字段)与产品类别(Category字段)分组,对销售额数据进行分析
Segment_category= df.groupby(['Segment','Category']).agg({'Sales':'sum'}).reset_index()
sns.barplot(x='Segment', y='Sales', hue='Category', data = Segment_category)
plt.title('不同类型的客户每年的销售额')
plt.show
思考题:如何通过多个字段分组并进行聚合运算、重置索引?
- 分组与聚合运算:
主要使用groupby方法来根据一个或多个列进行数据分组。
跟随groupby之后,可以使用聚合函数如sum, mean, count, max, min等直接进行计算,或者使用agg函数应用自定义的聚合操作。
2.重置索引:
分组聚合后,结果通常会生成一个多级索引。如果需要,可以使用reset_index方法将多级索引转换为常规列,以便于进一步处理或查看。
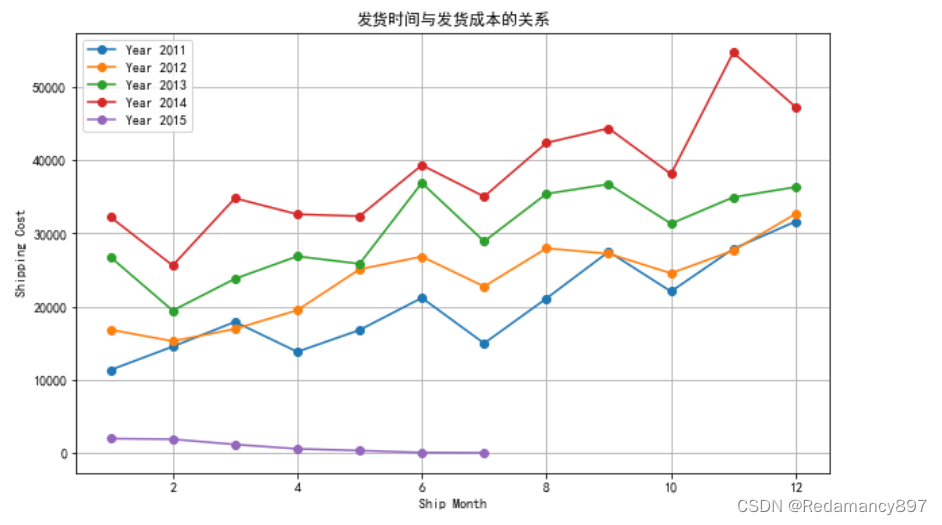
10.发货时间与发货成本分析
提取发货日期字段(Ship Date字段)的年、月信息,并整理发货
年、发货月的销售总额,分析发货成本,并预测进货成本
#发货时间与发货成本分析
#提取发货日期字段(Ship Date字段)的年、月信息,并整理发货年、发货月的销售总额,分析发货成本,并预测进货成本
df['Ship Date'] = pd.to_datetime(df['Ship Date'])
df['Year'] = df['Ship Date'].dt.year
df['Month'] = df['Ship Date'].dt.month
# 整理发货年、发货月的销售总额
sales_summary = df.groupby(['Year', 'Month'])['Sales'].sum().reset_index()
# 分析发货成本
shipping_cost_summary = df.groupby(['Year', 'Month'])['Shipping Cost'].sum().reset_index()
shipping_cost_pivot = shipping_cost_summary.pivot(index='Month', columns='Year', values='Shipping Cost')
# 绘制折线图
plt.figure(figsize=(10, 6))
for year, data in shipping_cost_pivot.iteritems():
plt.plot(data.index, data.values, marker='o', label=f'Year {year}')
plt.xlabel('Ship Month')
plt.ylabel('Shipping Cost')
plt.title('发货时间与发货成本的关系')
plt.legend()
plt.grid(True)
plt.show()
思考题:透视表的好处有哪些?
透视表是一种强大的数据分析工具,它能够快速汇总、组织、分析和比较大量数据。透视表的好处包括但不限于以下几点:
-
数据汇总简化:透视表能够轻松地对数据进行求和、平均、最大值、最小值等汇总运算,使得复杂的数据集变得易于理解和分析。
-
多维度分析:用户可以根据需要选择一个或多个字段作为行标签、列标签,以及值进行分析,这种灵活性让透视表成为探索数据不同维度间关系的强大工具。
-
快速发现趋势和模式:通过拖放字段,透视表能立即展示数据中的关键信息和趋势,帮助用户快速识别数据中的模式、异常和关联性。
-
过滤和排序:透视表提供了强大的过滤和排序功能,允许用户根据特定条件查看数据子集,或按重要性对数据进行排序,从而聚焦于最关键的信息。
-
数据透视和重构:名字来源,透视表可以“透视”数据,即动态地改变数据的视图,无需重新配置表格或编写复杂的查询语句,即可从不同角度审视数据。
-
可视化增强理解:大多数透视表工具集成图表功能,可以将汇总后的数据转换成图表形式,如柱状图、饼图或折线图,使数据趋势和分布更加直观。
-
高效决策支持:由于透视表能快速提供关键指标的概览,因此对于管理层和决策者而言,它是制定策略和做决策时不可或缺的辅助工具。
-
减少手动计算错误:通过自动执行计算任务,透视表显著降低了人为错误的风险,确保了分析结果的准确性和可靠性。
综上所述,透视表通过简化复杂数据的处理流程,增强了数据分析的效率、准确性和洞察力,是数据分析工作中的一个强有力助手。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









