







一、 Hadoop安装部署模式
单机模式 Standalone
- 一台机器,所有的角色在一个java进程中运行。 适合体验。
伪分布式
- 一台机器 每个角色单独的java进程。 适合测试
分布式 cluster
- 多台机器 每个角色运行在不同的机器上 生产测试都可以
- 高可用(持续可用)集群 HA
在分布式的模式下 给主角色设置备份角色 实现了容错的功能 解决了单点故障
保证集群持续可用性。
二、了解源码编译
Index of /dist![]() https://archive.apache.org/dist/
https://archive.apache.org/dist/
Apache软件基金会的所有软件所有版本的下载地址.
- 源码下载地址
https://archive.apache.org/dist/hadoop/common/
hadoop-3.3.0-src.tar.gz source 源码包
hadoop-3.3.0.tar.gz 官方编译后安装包对应java语言开发的项目软件来说,所谓的编译是什么?
- xxx.java(源码)---->xxx.class(字节码)---->jar包
- 正常来说,官方网站提供了安装包,可以直接使用,为什么要自己编译呢?
-
- 修改源码之后需要重新编译。
- 官方提供的最大化编译 满足在各个平台运行,但是不一定彻底兼容本地环境。
- 某些软件,官方只提供源码。
native library 本地库。
官方编译好的 Hadoop的安装包没有提供带 C程序访问的接口。主要是本地压缩支持、IO支持。
- 怎么编译?
在源码的根目录下有编译相关的文件BUILDING.txt 指导如何编译。
使用maven进行编译 联网jar.
可以使用课程提供编译好的安装包
- hadoop-3.3.0-Centos7-64-with-snappy.tar.gz
三、集群规划
- Hadoop集群的规划
-
- 根据软件和硬件的特性 合理的安排各个角色在不同的机器上。
-
-
- 有冲突的尽量不部署在一起
- 有工作依赖尽量部署在一起
- nodemanager 和datanode是基友
-
node1: namenode datanode | resourcemanager nodemanger
node2: datanode secondarynamenode| nodemanger
node3: datanode | nodemanger-
- Q:如果后续需要扩容hadoop集群,应该增加哪些角色呢?
node4: datanode nodemanger
node5: datanode nodemanger
node6: datanode nodemanger
.....四、服务器基础环境准备
8.1、服务器基础环境准备
ip、主机名
hosts映射 别忘了windows也配置
防火墙关闭
时间同步
免密登录 node1---->node1 node2 node3
JDK安装详细步骤:zk集群搭建-CSDN博客
8.2、安装包目录结构
#上传安装包到/export/server 解压
bin #hadoop核心脚本 最基础最底层脚本
etc #配置目录
include
lib
libexec
LICENSE.txt
NOTICE.txt
README.txt
sbin #服务启动 关闭 维护相关的脚本
share #官方自带实例 hadoop相关依赖jar五、配置文件详解
官网文档:https://hadoop.apache.org/docs/r3.3.0/
- 第一类 1个 hadoop-env.sh
- 第二类 4个 core|hdfs|mapred|yarn-site.xml
site表示的是用户定义的配置,会覆盖default中的默认配置。
-
- core-site.xml 核心模块配置
- hdfs-site.xml hdfs文件系统模块配置
- mapred-site.xml MapReduce模块配置
- yarn-site.xml yarn模块配置
- 第三类 1个 workers
配置
- hadoop-env.sh
#java home
export JAVA_HOME=/export/server/jdk1.8.0_241
#Hadoop各个组件启动运行身份
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root- core-site.xml
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<!-- 设置Hadoop本地保存数据路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.3.0</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 单位:分 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>- hdfs-site.xml
<!-- 设置SNN进程运行机器位置信息 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>- mapred-site.xml
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>- yarn-site.xml
<!-- 设置YARN集群主角色运行机器位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<!-- 日志保存的时间 7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>- workers
node1.itcast.cn
node2.itcast.cn
node3.itcast.cn六、scp同步、环境变量配置
- scp安装包到其他机器
cd /export/server
scp -r hadoop-3.3.0 root@node2:$PWD
scp -r hadoop-3.3.0 root@node3:$PWD- Hadoop环境变量配置
vim /etc/profile
export HADOOP_HOME=/export/server/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
#别忘了 scp环境变量给其他两台机器哦七、namenode format操作
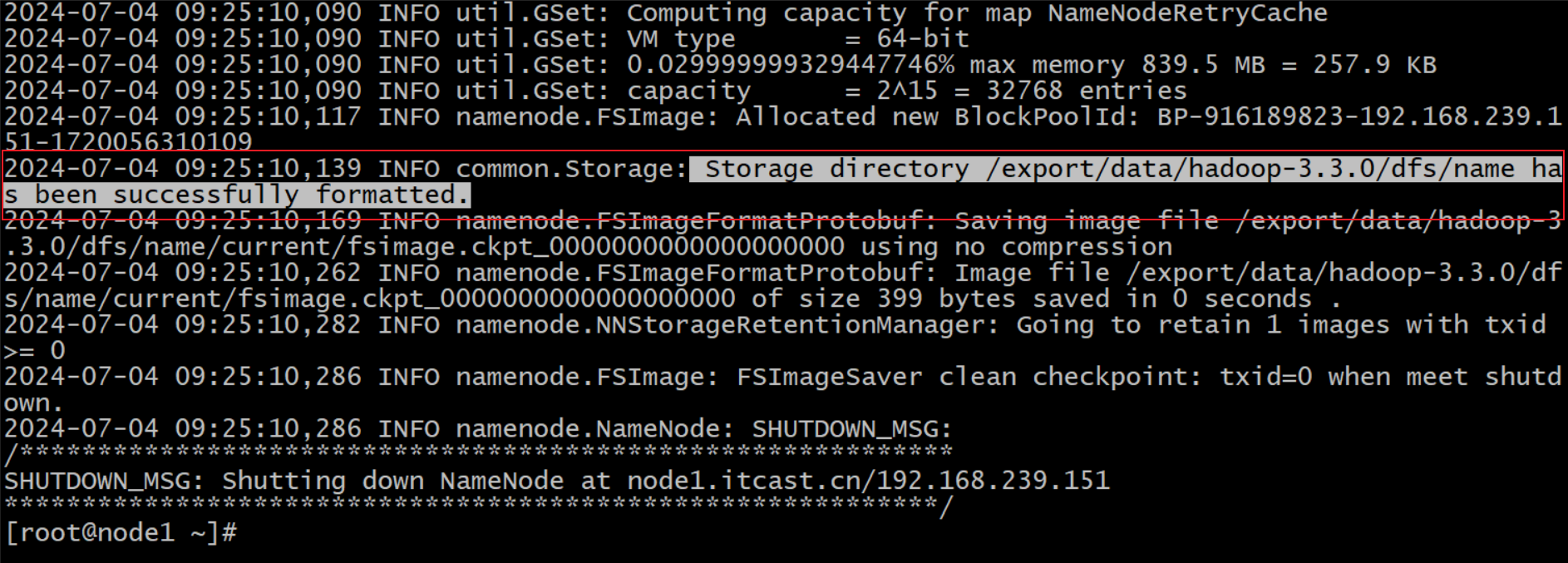
- format准确来说翻译成为初始化比较好。对namenode工作目录、初始文件进行生成。
- 通常在namenode所在的机器执行 执行一次。首次启动之前
#在node1 部署namenode的这台机器上执行
[root@node1 ~]# hadoop namenode -format
#执行成功 日志会有如下显示
21/05/23 15:38:19 INFO common.Storage: Storage directory /export/data/hadoopdata/dfs/name has been successfully formatted.
[root@node1 server]# ll /export/data/hadoopdata/dfs/name/current/
total 16
-rw-r--r-- 1 root root 321 May 23 15:38 fsimage_0000000000000000000
-rw-r--r-- 1 root root 62 May 23 15:38 fsimage_0000000000000000000.md5
-rw-r--r-- 1 root root 2 May 23 15:38 seen_txid
-rw-r--r-- 1 root root 207 May 23 15:38 VERSION- Q:如果不小心初始化了多次,如何?
-
- 现象:主从之间互相不识别。
- 解决
#企业真实环境中 枪毙
#学习环境
删除每台机器上hadoop.tmp.dir配置指定的文件夹/export/data/hadoop-3.3.0。
重新format。















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









