







一.字典树的引入与效率分析
1. Trie 也叫做字典树、前缀树(Prefix Tree)、单词查找树
2. Trie 搜索字符串的效率主要跟字符串的长度有关
假设使用 Trie 存储 cat、dog、doggy、does、cast、add 六个单词,用Trie结构和二叉树结构存储分别为:
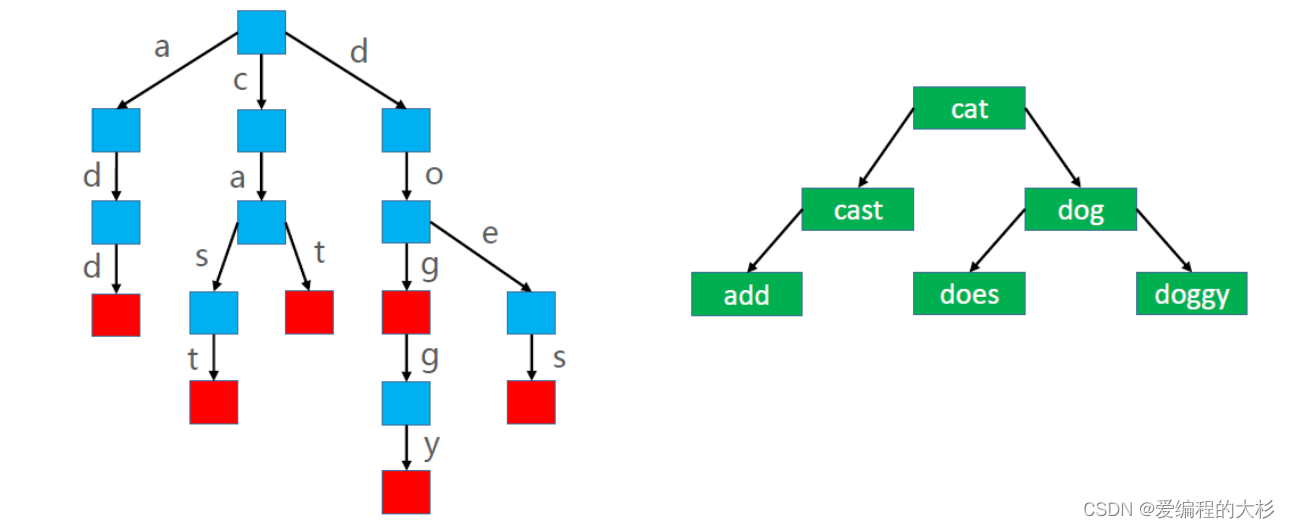
由上图可以得出Trie(字典树)的优缺点:
◼ Trie 的优点:搜索前缀的效率主要跟前缀的长度有关
◼ Trie 的缺点:需要耗费大量的内存,因此还有待改进
二、字典树的接口设计
int size();
boolean isEmpty();
void clear();
boolean contains(String str);
V add(String str, V value);
V remove(String str);
boolean starsWith(String prefix);
三.字典树的代码实现
import java.util.HashMap;
public class Trie <V>{
private int size;
private Node<V> root=new Node<>(null);
public int size(){
return size;
}
boolean isEmpty() {
return size==0;
}
public void clear(){
size=0;
root.getChildren().clear();
}
private Node<V> node(String str){
keyCheck(str);
int len =str.length();
Node<V> node=root;
for(int i=0;i<len;i++){
if(node==null||node.children==null)return null;
Character c=str.charAt(i);
node=node.getChildren().get(c);
}
return node.words?node:null;
}
boolean contains(String str){
return node(str)!=null;
}
private void keyCheck(String str){
if(str==null||str.length()==0){
throw new UnsupportedOperationException("不合法的添加");
}
}
public V add(String str, V value){
keyCheck(str);
Node<V> node=root;
int len=str.length();
for(int i=0;i<len;i++){
Character res=str.charAt(i);
Node<V> childrenNode=node.getChildren().get(res);
if(childrenNode==null) {
childrenNode=new Node<>(node);
childrenNode.character=res;
node.getChildren().put(res,childrenNode);
}
node=childrenNode;
}
//到这里不管是一开始没有这个字符串,一路创建到这
// 还是一开始有这个字符串一路遍历到这都到了字符串的末尾字母
if(node.words)//之前添加过节点则覆盖value值
{
V oldValue=node.value;
node.value=value;
return oldValue;
}
node.words=true;
node.value=value;
size++;
//新添加的value之前没有value返回null
return null;
}
public V get(String str){
Node<V> node=node(str);
return node==null?null:node.value;
}
public V remove(String str){
//找到字符串最后一个节点
Node<V> node=node(str);
//如果node是空,或者不是单词结尾(不是这个单词)
if(node==null||!node.words)return null;
size--;
V oldValue=node.value;
//从下往上找,如果找到节点还有另外分支或者遇到单词结尾,则直接结束删除
//下面这种情况:如果这个单词能找到而且是另外一个单词的一部分则只需将节点颜色改变即可
if(node.children!=null&&!node.children.isEmpty()){
node.value=null;
node.words=false;
return oldValue;
}
Node<V> parent=null;
while((parent=node.parent)!=null)
{
parent.children.remove(node.character);
//删除后还有其他的子节点说明遇到分叉的父节点直接结束向上扫描
if(!parent.children.isEmpty()) break;
node=parent;
}
return oldValue;
}
public boolean startsWith(String prefix){
keyCheck(prefix);
Node<V> node=root;
int len=prefix.length();
for(int i=0;i<len;i++){
Character res=prefix.charAt(i);
Node<V> childrenNode=node.getChildren().get(res);
if(childrenNode==null) {
return false;
}
node=childrenNode;
}
return true;
}
static class Node<V>{
//根据字符串的每一个字母将进行查找,需要知道每个节点对应字母,所以需要存入Character
//根据字母诸葛查找。没必要将字符串传入节点,因为在寻找的路径中就确定了字符串的组成
Node<V> parent;
public Node(Node<V> parent) {
this.parent = parent;
}
HashMap<Character,Node<V>> children;
V value;
Character character;
boolean words;//确定单词结尾
//children可能已经有值了
public HashMap<Character,Node<V>> getChildren (){
return children==null?children =new HashMap<>():children;
}
}
}
四.测试代码
/**
* 字典树又叫前缀树,主要用于单词的查找,和给定前缀查看是否有此前缀开头的单词
* 问:如何判断一堆不重复的字符串一破格前缀开头呢?
* Set Map实现的话需要遍历所有的字符串复杂度O(N),而用字典树则不用遍历所有的元素,它的查找只与字符串的长度有关
*/
public class Main {
static void test1() {
Trie<Integer> trie = new Trie<>();
trie.add("cat", 1);
trie.add("dog", 2);
trie.add("catalog", 3);
trie.add("cast", 4);
trie.add("小码哥", 5);
Asserts.test(trie.size() == 5);
Asserts.test(trie.startsWith("do"));
Asserts.test(trie.startsWith("c"));
Asserts.test(trie.startsWith("ca"));
Asserts.test(trie.startsWith("cat"));
Asserts.test(trie.startsWith("cata"));
Asserts.test(!trie.startsWith("hehe"));
int value=trie.get("小码哥");
Asserts.test(trie.get("小码哥") == 5);
Asserts.test(trie.remove("cat") == 1);
Asserts.test(trie.remove("catalog") == 3);
Asserts.test(trie.remove("cast") == 4);
Asserts.test(trie.size() == 2);
Asserts.test(trie.startsWith("do"));
Asserts.test(!trie.startsWith("c"));
}
public static void main(String[] args) {
test1();
}
}

















 6178
6178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











